Data Modeling
This is not an academic assignment.
This question involves the logical design of a database (entities and attributes). Do you agree with the proposed model? Is the attribute for the text of the e-mail message body correct?
I am using the Oracle SQL Developer Data Modeler to learn how to create an ERD. The report is attached.
I am designing a database that will be used to track the emails that are contained in PDFs. Numerous emails are printed to a single PDF file. Each PDF contains numerous emails. The PDFs are not going to be stored in a database. Only the file path and file name will be tracked. This will be a single user database.
Sent e-mails. The following will be tracked:
1) The date and time the e-mails were sent.
2) The sender’s first and last name.
3) The text of the message body will be copied into a field.
E-mail Images. The following will be tracked:
1) An image of every e-mail. A multipage PDF will contain an image of every e-mail.
2) The e-mail image file path.
Here is a sample report:
Sender: Mary Smith
Date: 1-1-14
Time: 4:00 p.m.
File c:\email\file1.pdf
Email Contents: .. text from e-mail...
Proposed entities:
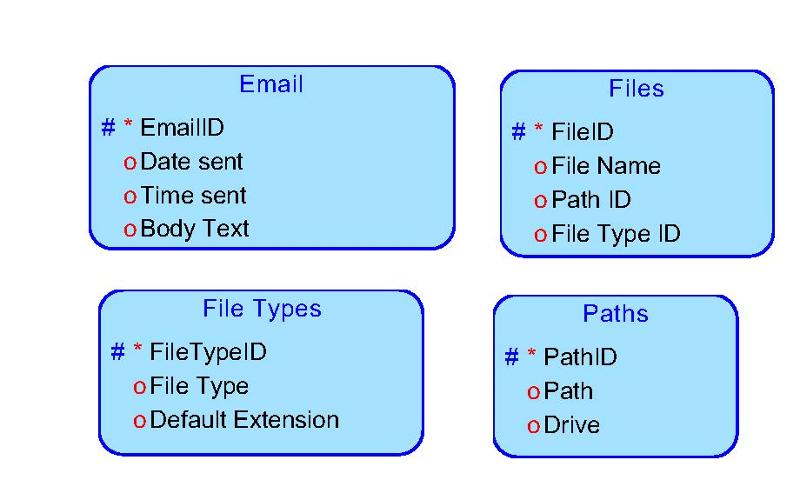
Entity: Email
Description: The particular email message that is being tracked.
Rules:
The text of the message body will be copied into a field. Attributes:
Email ID --An arbitrary unique sequential number assigned to every email. arbitrary unique sequential number assigned to every email.
Date sent --The date on which the email was sent.
Time sent --The time that the email was sent.
Body Text --The text contained in the email message.
Entity: Files
Description: A standard-format PDF file used to hold emails.
Rules:
Numerous emails are printed to a single PDF file.
PDFs are currently not stored in a database; they are stored as standard PDF files.
Attributes:
File Id --arbitrary unique sequential number assigned to every file name. File names alone may not be unique, since the same file name could be stored in different paths.
File Name --Physical name of the file, excluding file extension.
Path Id --identifier that specifies the drive and path to the file.
File Type Id --Physical file type; typically this will correlate to the file extension, but that’s not actually required. For example, a ‘[.]txt’ file could actually [.]csv-format data and vice-versa.
Entity: File Types
Description: Type of file details. Will include the default extension and a brief description of the file type.
File Type Id --arbitrary unique sequential number assigned to each unique File Type
Default Extension --default extension for this type of file: ‘PDF’ for pdf files.
File Type --standardized description of the the file type: ‘PDF’.
Entity: Paths
Description: The path of a file. Example: c:\email\. This does NOT include the file name, which is part of the file data.
Attributes:
Path Id --arbitrary unique sequential number assigned to each unique path.
Path --the remainder of the physical path to the file
Drive --The “drive” name; may be a single letter, a share, a volume mount point, etc.
Here is the ERD
 report.pdf
report.pdf
This question involves the logical design of a database (entities and attributes). Do you agree with the proposed model? Is the attribute for the text of the e-mail message body correct?
I am using the Oracle SQL Developer Data Modeler to learn how to create an ERD. The report is attached.
I am designing a database that will be used to track the emails that are contained in PDFs. Numerous emails are printed to a single PDF file. Each PDF contains numerous emails. The PDFs are not going to be stored in a database. Only the file path and file name will be tracked. This will be a single user database.
Sent e-mails. The following will be tracked:
1) The date and time the e-mails were sent.
2) The sender’s first and last name.
3) The text of the message body will be copied into a field.
E-mail Images. The following will be tracked:
1) An image of every e-mail. A multipage PDF will contain an image of every e-mail.
2) The e-mail image file path.
Here is a sample report:
Sender: Mary Smith
Date: 1-1-14
Time: 4:00 p.m.
File c:\email\file1.pdf
Email Contents: .. text from e-mail...
Proposed entities:
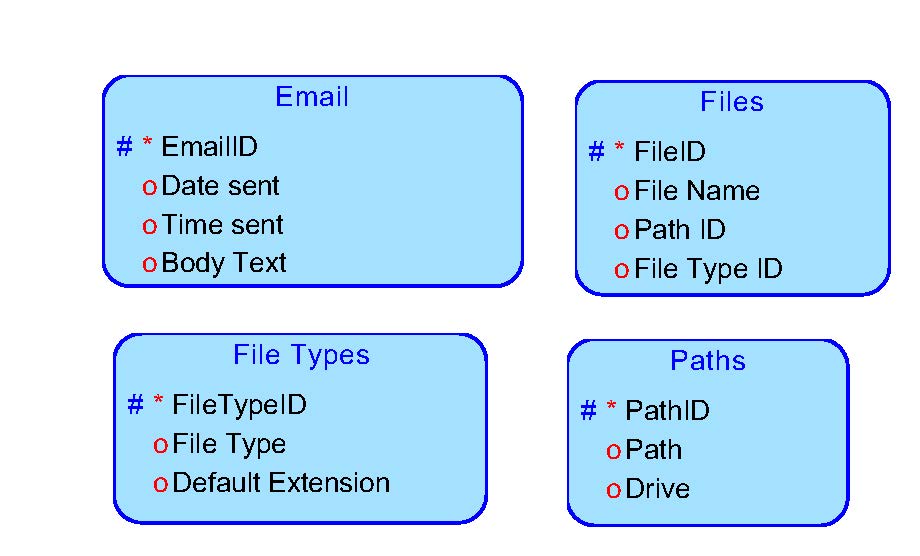
Entity: Email
Description: The particular email message that is being tracked.
Rules:
The text of the message body will be copied into a field. Attributes:
Email ID --An arbitrary unique sequential number assigned to every email. arbitrary unique sequential number assigned to every email.
Date sent --The date on which the email was sent.
Time sent --The time that the email was sent.
Body Text --The text contained in the email message.
Entity: Files
Description: A standard-format PDF file used to hold emails.
Rules:
Numerous emails are printed to a single PDF file.
PDFs are currently not stored in a database; they are stored as standard PDF files.
Attributes:
File Id --arbitrary unique sequential number assigned to every file name. File names alone may not be unique, since the same file name could be stored in different paths.
File Name --Physical name of the file, excluding file extension.
Path Id --identifier that specifies the drive and path to the file.
File Type Id --Physical file type; typically this will correlate to the file extension, but that’s not actually required. For example, a ‘[.]txt’ file could actually [.]csv-format data and vice-versa.
Entity: File Types
Description: Type of file details. Will include the default extension and a brief description of the file type.
File Type Id --arbitrary unique sequential number assigned to each unique File Type
Default Extension --default extension for this type of file: ‘PDF’ for pdf files.
File Type --standardized description of the the file type: ‘PDF’.
Entity: Paths
Description: The path of a file. Example: c:\email\. This does NOT include the file name, which is part of the file data.
Attributes:
Path Id --arbitrary unique sequential number assigned to each unique path.
Path --the remainder of the physical path to the file
Drive --The “drive” name; may be a single letter, a share, a volume mount point, etc.
Here is the ERD
 report.pdf
report.pdf
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
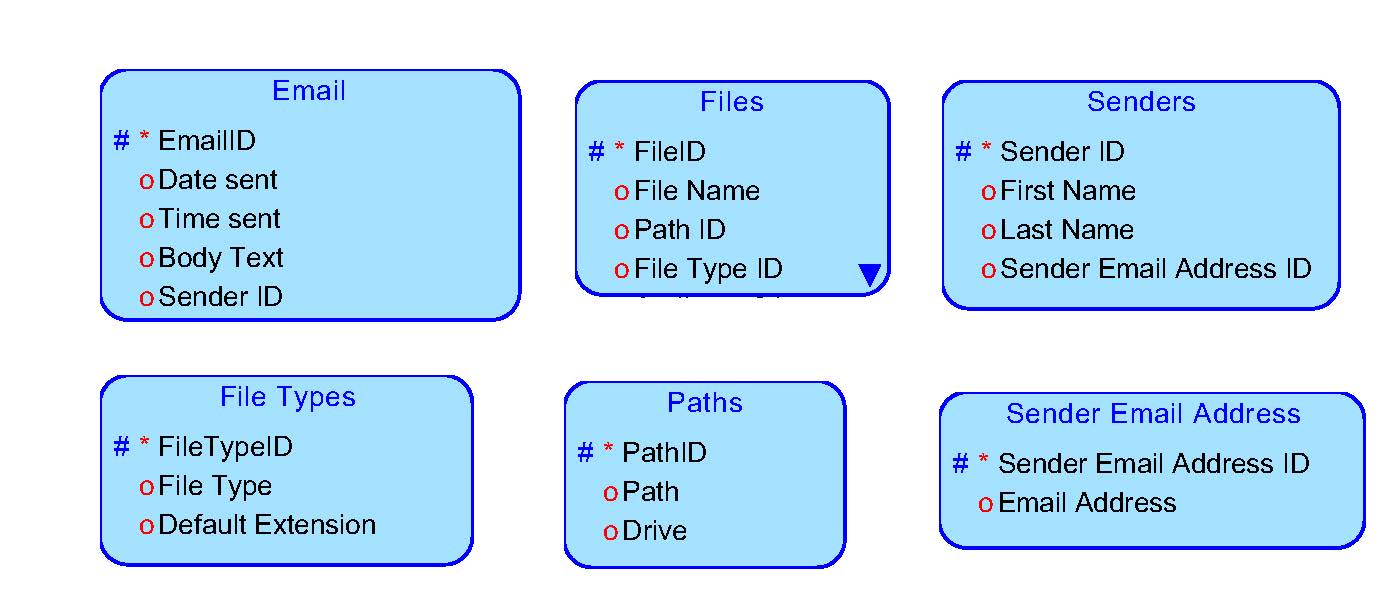
Your question "What if email addresses are re-used over time?" is excellent. They will be reused over time. Is an "email address" entity needed?
Regarding the new Senders entity, I can just add a new email address attribute to it.
Regarding the new Senders entity, I can just add a new email address attribute to it.
ASKER
I think in this question and the many on this same topic you have asked, you are starting to see the fact that there really isn't a 'correct' design and we'll NEVER be able to answer this question for you.
If you are contracting projects that require the skill of database design, maybe you should start reading up in the concepts. I suggest you pick up some books or read whatever you can find on the web on the rules of normalization. Once you understand the concepts this type of thing becomes much easier.
Every app/design is different and has different requirements that can greatly impact the database design. You just need to make sure your logical and physical design matches the system requirements.
That said, and continuing down the rabbit hole:
I didn't see where you addressed this:
What if there are two John Smiths? How do you know who is who?
Can one person not have more than one email address to upload files?
This will keep going and going and going as there is no 'final answer'.
If you are contracting projects that require the skill of database design, maybe you should start reading up in the concepts. I suggest you pick up some books or read whatever you can find on the web on the rules of normalization. Once you understand the concepts this type of thing becomes much easier.
Every app/design is different and has different requirements that can greatly impact the database design. You just need to make sure your logical and physical design matches the system requirements.
That said, and continuing down the rabbit hole:
I didn't see where you addressed this:
What if there are two John Smiths? How do you know who is who?
Can one person not have more than one email address to upload files?
This will keep going and going and going as there is no 'final answer'.
ASKER
Your Question: What if there are two John Smiths?
Answer: There will not be two John Smiths.
Your Question: Can one person not have more than one email address to upload files?
Answer: No. This will be a single user database. No one will be uploading files.
Your questions and comments are very helpful and they are helping me learn normalization. I am not contracting projects that require the skill of database design; it is one of the areas that I am studying (all self-study). EE, so far, is the only place where I can get answers to my questions. The different perspectives are very helpful. Yes, I have asked many questions on this topic but they are all different. The comments (answers) in each question are much different from one another and extremely helpful.
I have been using the following book to learn database design:
http://www.amazon.com/Database-Design-Mere-Mortals-Hands-/dp/B00DIKUOUA/ref=sr_1_11?s=books&ie=UTF8&qid=1408736146&sr=1-11&keywords=database+design+for+mere+mortals
It does not discuss the difference between logical and physical design.
Can you recommend any books/articles geared toward the beginner that discuss the difference between logical and physical design?
Answer: There will not be two John Smiths.
Your Question: Can one person not have more than one email address to upload files?
Answer: No. This will be a single user database. No one will be uploading files.
Your questions and comments are very helpful and they are helping me learn normalization. I am not contracting projects that require the skill of database design; it is one of the areas that I am studying (all self-study). EE, so far, is the only place where I can get answers to my questions. The different perspectives are very helpful. Yes, I have asked many questions on this topic but they are all different. The comments (answers) in each question are much different from one another and extremely helpful.
I have been using the following book to learn database design:
http://www.amazon.com/Database-Design-Mere-Mortals-Hands-/dp/B00DIKUOUA/ref=sr_1_11?s=books&ie=UTF8&qid=1408736146&sr=1-11&keywords=database+design+for+mere+mortals
It does not discuss the difference between logical and physical design.
Can you recommend any books/articles geared toward the beginner that discuss the difference between logical and physical design?
>>Can you recommend any books/articles geared toward the beginner that discuss the difference between logical and physical design?
Unfortunately, no. I went through all this so many years ago nothing I had back then probably doesn't exist today.
Design isn't a 'by the rules' thing. Sure, there are rules of normalization that some might argue are a 'science' but they really aren't. They are just rules...
You design the logical to make sure the design can answer ALL the questions the system can be answered by the design.
For example:
If I'm asked:
How many emails did a specific person send?
How many PDF's were sent on 1/1/2014?
etc...
The design can answer them. If I can answer ALL questions the requirements ask for (and the ones they don't ask for... this comes with experience), then I consider my design done.
When moving to the physical:
You need to make sure the design makes sense, you don't need to write 100 table joins to retrieve the data, performance is there.
I've denormalized my database based on efficiency. I report counts of items to my users on a web page based on a master 'document'. How many children does this master document have by type?
Can I generate them at run-time, sure but it takes time. To display the results much faster, I keep the counts of the children in the parent table. It takes extra code the make sure everything is in sync, but worth it when I go to get the data for the user.
End data is displayed like:
doc_id,type,count
1,green,2
1,blue,10
1,yellow,4
2,green,6
Sure I can do a sub-select with a count from SQL to get the numbers but in my app, seconds count. Better to just store the type counts in the parent table instead of generating them when asked for them.
The physical design goes against ALL 'rules' of normalization but makes sense when it comes to the systems that requires the data.
Unfortunately, no. I went through all this so many years ago nothing I had back then probably doesn't exist today.
Design isn't a 'by the rules' thing. Sure, there are rules of normalization that some might argue are a 'science' but they really aren't. They are just rules...
You design the logical to make sure the design can answer ALL the questions the system can be answered by the design.
For example:
If I'm asked:
How many emails did a specific person send?
How many PDF's were sent on 1/1/2014?
etc...
The design can answer them. If I can answer ALL questions the requirements ask for (and the ones they don't ask for... this comes with experience), then I consider my design done.
When moving to the physical:
You need to make sure the design makes sense, you don't need to write 100 table joins to retrieve the data, performance is there.
I've denormalized my database based on efficiency. I report counts of items to my users on a web page based on a master 'document'. How many children does this master document have by type?
Can I generate them at run-time, sure but it takes time. To display the results much faster, I keep the counts of the children in the parent table. It takes extra code the make sure everything is in sync, but worth it when I go to get the data for the user.
End data is displayed like:
doc_id,type,count
1,green,2
1,blue,10
1,yellow,4
2,green,6
Sure I can do a sub-select with a count from SQL to get the numbers but in my app, seconds count. Better to just store the type counts in the parent table instead of generating them when asked for them.
The physical design goes against ALL 'rules' of normalization but makes sense when it comes to the systems that requires the data.
ASKER
Thank you, slightwv.
>> If I can answer ALL questions the requirements ask for (and the ones they don't ask for... this comes with experience), then I consider my design done. <<
I'm not sure of the overall value of that as a criteria. You cannot possibly anticipate every future requirement. Besides, that's so informal a requirement as to be untestable and unrepeatable by others. How would you ever verify a design based on so haphazard a design approach?
Normalization is the standard logical design process. True, it's not 100% science, in particular with exactly how far to go (most agree to 3NF, but beyond that there is large disagreement). That process, properly followed, will give you a sufficiently robust design.
I'm not sure of the overall value of that as a criteria. You cannot possibly anticipate every future requirement. Besides, that's so informal a requirement as to be untestable and unrepeatable by others. How would you ever verify a design based on so haphazard a design approach?
Normalization is the standard logical design process. True, it's not 100% science, in particular with exactly how far to go (most agree to 3NF, but beyond that there is large disagreement). That process, properly followed, will give you a sufficiently robust design.
You can make educated guesses in the design even though the system requirements do not specifically call for them. I try to anticipate future requirements based on past experiences and make sure the design can account for them.
For example:
I need to capture a persons name, nickname, phone and email address. One entity? I'm thinking 5(three primary and two cross reference).
Both will meet the given requirement. One will address unknown requirement: OH, we need the ability to capture a secondary email address and phone as well as different aliases.
As far as it being repeatable by others:
Given 'X' number of designers and one set of requirements, you'll end up with 'X' different designs. So my process is just as repeatable as any other...
If everyone follows the basic rules for normalization, the 4 designs should have similar core entities and attributes but they will have differences.
As the asker can tell from all the previous related questions and the debates in there:
Everyone has their own process and there is no 'right' answer.
Best to just understand the concepts of normalization and then apply them to the unique task at hand.
For example:
I need to capture a persons name, nickname, phone and email address. One entity? I'm thinking 5(three primary and two cross reference).
Both will meet the given requirement. One will address unknown requirement: OH, we need the ability to capture a secondary email address and phone as well as different aliases.
As far as it being repeatable by others:
Given 'X' number of designers and one set of requirements, you'll end up with 'X' different designs. So my process is just as repeatable as any other...
If everyone follows the basic rules for normalization, the 4 designs should have similar core entities and attributes but they will have differences.
As the asker can tell from all the previous related questions and the debates in there:
Everyone has their own process and there is no 'right' answer.
Best to just understand the concepts of normalization and then apply them to the unique task at hand.
ASKER
Here is an updated ERD.