Raid levels explained
Published:
Browse All Articles > Raid levels explained
Hi,
I've made you some graphics for a better understanding how RAID works.
First of all, there are two ways a raid can be generated:
- By hardware
- By software
What does that mean?
This means: If you have a hardware RAID controller, there will be a card inside your PC/server that will manage everything that handles I/O to your disks. There are no drivers needed. The Operating system will see the "raid set" as one big disk.
A software raid means: your operating system will handle the distribution or mirroring to the disks. It is OS dependant. That means: Your OS has to support that implementation of RAID. You can't simply switch from Windows to Linux or otherwise. And: your CPU will be involved in calculating the parts that are used for redundandy, called "parity bits". I'll come to that later on.
So, what are the RAID levels?
Basic Approaches:
Raid 0:
The simplest thing you can do is just to distribute all of your data to every disk that's available. This is called "RAID 0". It is referred to as a "stripeset" since the data is striped to every available disk to the set of disks that build up the raid.
This is very performant, but: If one disk fails, it's like you take a pumpgun and shoot to your filesystem. It's simply gone. Unrecoverable.
This is what a RAID 0 looks like:
378163![RAID 0]()
Raid 1:
So you might want to have some redundancy? No problem. Here's RAID 1. It mirrors your data to another disk. That means: Every block you write to your RAID gets written to two separate physical disks, of which one may fail. There's no problem for you. Your data will be intact.
This costs no measurable performance at all when it's done by a hardware raid controller and very little to nothing if it's done by the operating system itself (software raid).
Here's how it looks:
![RAID 1]()
You can combine both of these worlds to create something that's called "RAID 10". Which simply means: "Mirror a stripeset".
Here's how it looks:
![RAID 10]()
It simply mirrors every disk in a stripeset.
How many disks may fail? => Depends!
If, in the worst possible case" the two mirrored disks fail, everyhing's gone. If, in the best case, one entire stripeset fails, everything's good. The advantage of this solution is: Best performance! Since mirroring takes much less effort to the controller (hardware raid) or the operating system (software raid) than calculating "parities". (More on that later)
Now we come to the slightly more complicated part:
Paritys! Eeeh? What's that?!
It's simple: Let's assume you have five disks and want to be immune to a failure of one disk. Then you create a RAID 3 (or RAID 5 - I'll come to that later on). Both approaches are: "One disk may fail". This can be easily explained when looking at RAID 3:
![RAID 3]()
In this case, you distribute all of the data to four disks (of your five available ones). But you do some magic, too: Calculating parities. This calculations are either be made by your hardware raid controller or by your operating system (and therefore your CPU, whichs costs CPU cycles and performance!)
So, what's "parity"?
Parity is a astonishingly simple set of only one rule: Count every Bits (1 or 0) in a row that are "1" and decide: Is the number I've counted odd or even?
This picture explains it:
![Parity Explained]()
This is either be done by your controller (hardware raid) or by your operating system (software raid).
This (RAID 3) is the worst possible RAID level!
Why?
The writing speed entirely depends on how fast you can write the parity to your dedicated "parity-disk".
Therefore they invented RAID 5:
RAID 5: distributes the parity over all available disks.
Sounds like voodoo to you? Here's a picture to explain it clearly:
![RAID 5]()
So, people decided: I want more redundancy! I want to be able to handle the failure of two disks!
No problem, here's where RAID 6 kicks in: It calculates the parity in two different ways and distributes the parity to all available disks.
This is how it looks:
![RAID 6]()
I've made you some graphics for a better understanding how RAID works.
First of all, there are two ways a raid can be generated:
- By hardware
- By software
What does that mean?
This means: If you have a hardware RAID controller, there will be a card inside your PC/server that will manage everything that handles I/O to your disks. There are no drivers needed. The Operating system will see the "raid set" as one big disk.
A software raid means: your operating system will handle the distribution or mirroring to the disks. It is OS dependant. That means: Your OS has to support that implementation of RAID. You can't simply switch from Windows to Linux or otherwise. And: your CPU will be involved in calculating the parts that are used for redundandy, called "parity bits". I'll come to that later on.
So, what are the RAID levels?
Basic Approaches:
Raid 0:
The simplest thing you can do is just to distribute all of your data to every disk that's available. This is called "RAID 0". It is referred to as a "stripeset" since the data is striped to every available disk to the set of disks that build up the raid.
This is very performant, but: If one disk fails, it's like you take a pumpgun and shoot to your filesystem. It's simply gone. Unrecoverable.
This is what a RAID 0 looks like:
378163
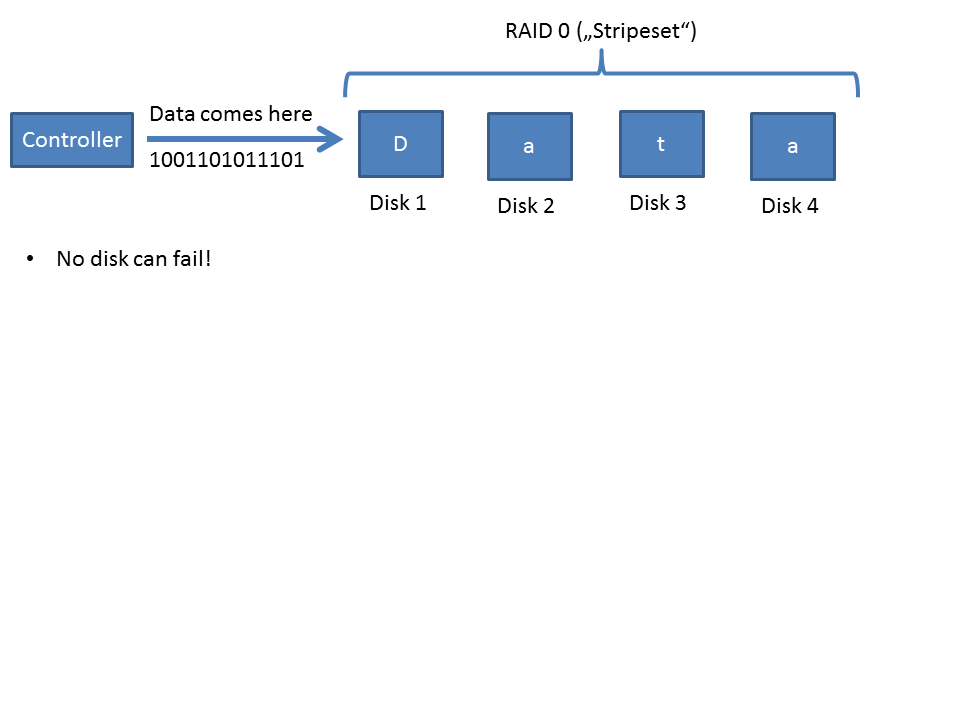
Raid 1:
So you might want to have some redundancy? No problem. Here's RAID 1. It mirrors your data to another disk. That means: Every block you write to your RAID gets written to two separate physical disks, of which one may fail. There's no problem for you. Your data will be intact.
This costs no measurable performance at all when it's done by a hardware raid controller and very little to nothing if it's done by the operating system itself (software raid).
Here's how it looks:
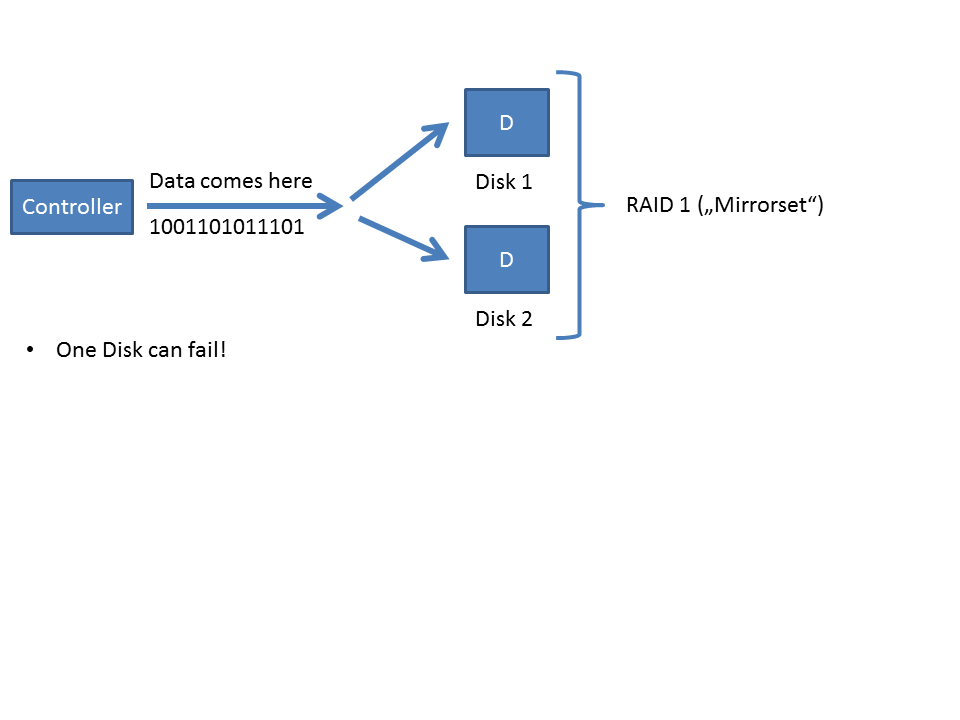
You can combine both of these worlds to create something that's called "RAID 10". Which simply means: "Mirror a stripeset".
Here's how it looks:
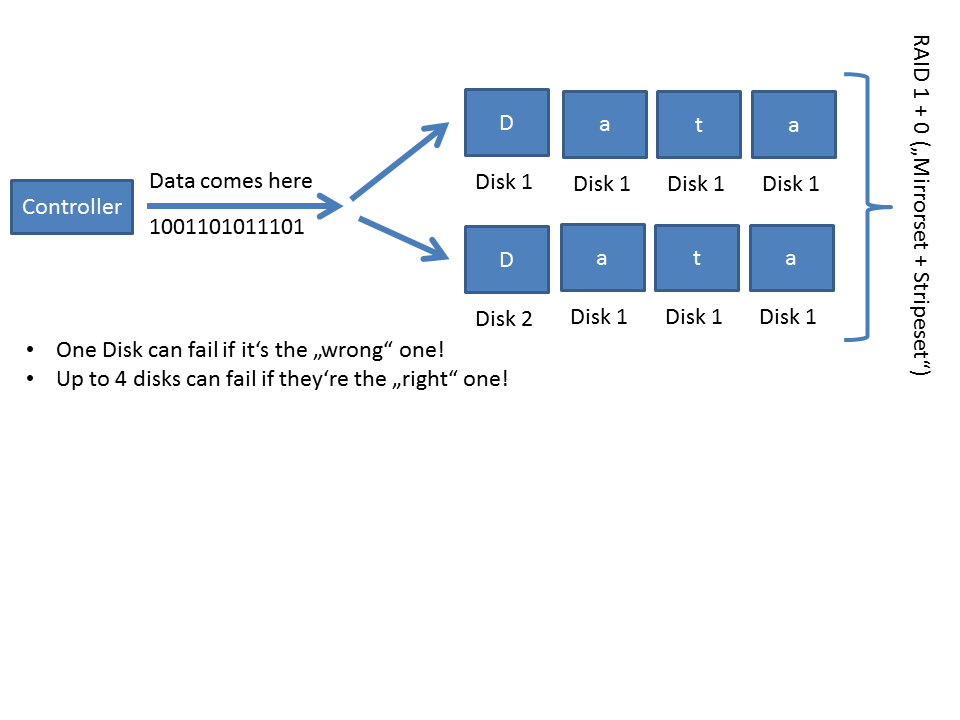
It simply mirrors every disk in a stripeset.
How many disks may fail? => Depends!
If, in the worst possible case" the two mirrored disks fail, everyhing's gone. If, in the best case, one entire stripeset fails, everything's good. The advantage of this solution is: Best performance! Since mirroring takes much less effort to the controller (hardware raid) or the operating system (software raid) than calculating "parities". (More on that later)
Now we come to the slightly more complicated part:
Paritys! Eeeh? What's that?!
It's simple: Let's assume you have five disks and want to be immune to a failure of one disk. Then you create a RAID 3 (or RAID 5 - I'll come to that later on). Both approaches are: "One disk may fail". This can be easily explained when looking at RAID 3:
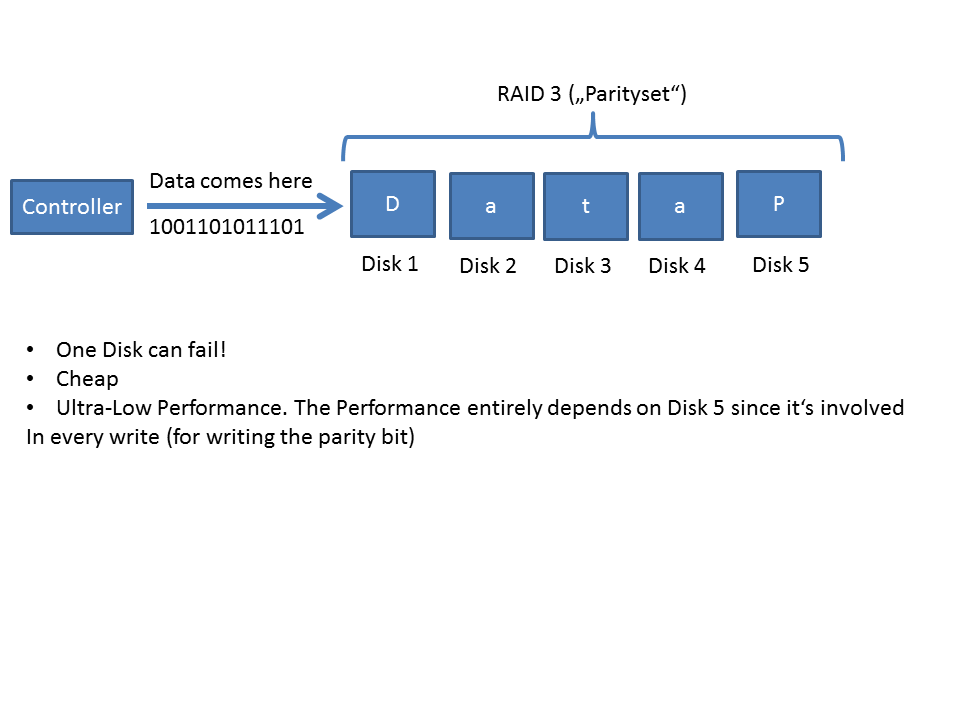
In this case, you distribute all of the data to four disks (of your five available ones). But you do some magic, too: Calculating parities. This calculations are either be made by your hardware raid controller or by your operating system (and therefore your CPU, whichs costs CPU cycles and performance!)
So, what's "parity"?
Parity is a astonishingly simple set of only one rule: Count every Bits (1 or 0) in a row that are "1" and decide: Is the number I've counted odd or even?
This picture explains it:
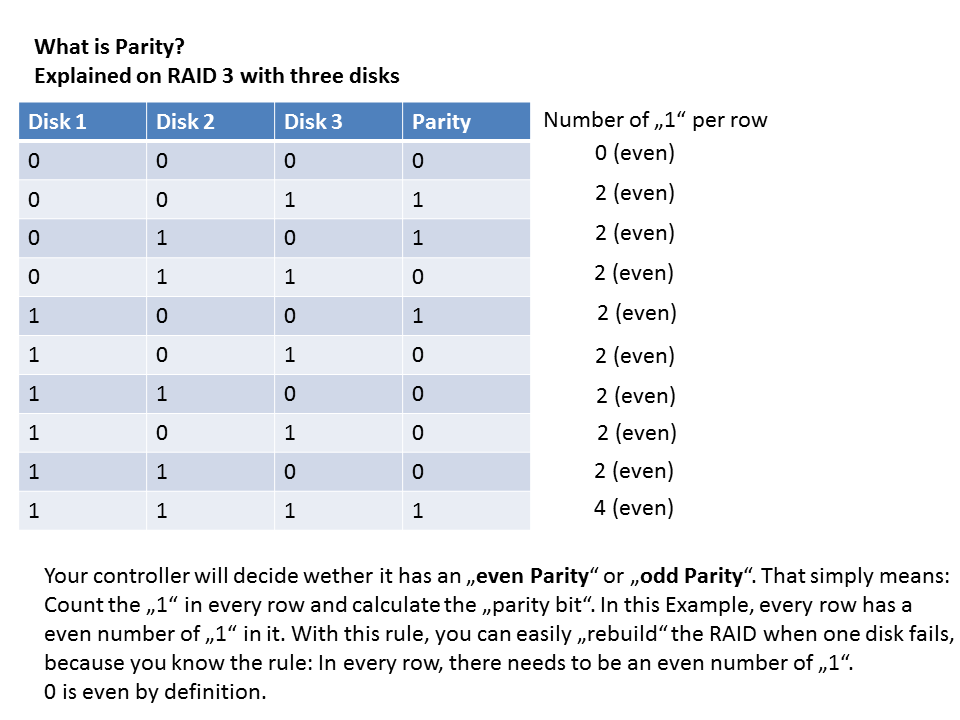
This is either be done by your controller (hardware raid) or by your operating system (software raid).
This (RAID 3) is the worst possible RAID level!
Why?
The writing speed entirely depends on how fast you can write the parity to your dedicated "parity-disk".
Therefore they invented RAID 5:
RAID 5: distributes the parity over all available disks.
Sounds like voodoo to you? Here's a picture to explain it clearly:
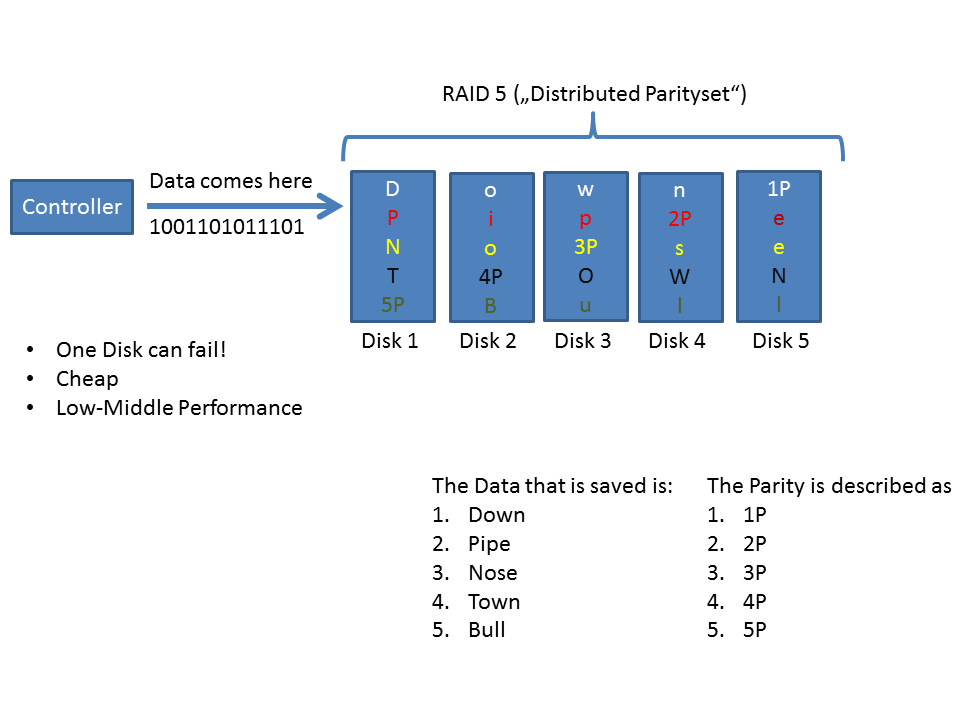
So, people decided: I want more redundancy! I want to be able to handle the failure of two disks!
No problem, here's where RAID 6 kicks in: It calculates the parity in two different ways and distributes the parity to all available disks.
This is how it looks:

Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (7)
Commented:
* It is not as simple as hardware or software RAID. You should consider adding the Intel Matrix and other FakeRAID chips. The "hardware" is a $2.00 chip, but the work is done with software drivers.
* You are working on an incorrect premise that RAID works exclusively at the disk level. Granted this is mostly the case for PCI-based controllers, it certainly isn't true for host-based RAID. LINUX software RAID, for example will let you mirror two partitions on the same HDD in order to improve data integrity and read performance.
* You did not address the most likely failure scenario .. unrecoverable read errors. RAID does not protect against losing a HDD, it protects losing unreadable data in a stripe. Many people in EE have lost data in RAID5 when they only had a single HDD failure, and it is a disservice to tell them they can survive merely a disk failure.
* Not all software RAID mechanisms use simple parity. Solaris' ZFS is a good example of that. NetApp & EMC's hardware RAID implementations are further examples.
Commented:
Your RAID1 assessment on performance is just flat-out wrong. Case in point, windows software RAID1 has read load balancing. So in a perfect world RAID1 will have twice the performance of a single disk drive. Heck in my Win7 PC I typically get 70% read performance over a single HDD in high I/O situations.
Other RAID implementations vary as well. So I suggest taking performance out of this entirely unless you mention it is all implementation specific.
Commented:
Commented:
This is also when you are most likely to find out if there is another weak disk in the array. if you have a failure of a disk during the rebuild process you will lose the array.
For modern systems using standard hard drives it's best to stick with Raid 10.
Regards
Commented:
View More