Dynamic Pivot Procedure without the Pivot function


Love to Help
Give a man a fish and you've fed him for a day; Teach a man to fish and you've fed him for the rest of his life. Be the teacher
Give a man a fish and you've fed him for a day; Teach a man to fish and you've fed him for the rest of his life. Be the teacher
Published:
Browse All Articles > Dynamic Pivot Procedure without the Pivot function
by Mark Wills
PIVOT is a great facility. Well that was the opening line in my previous similarly named article : https://www.experts-exchange.com/Microsoft/Development/MS-SQL-Server/SQL-Server-2005/A_653-Dynamic-Pivot-Procedure-for-SQL-Server.html
But what if you want to pivot multiple columns, or maybe multiple aggregates, or both, or don't have the PIVOT statement? That's exactly what happened recently in a question where the SQL 2008 server was actually pointing to a SQL 2000 database.
So how do we solve such a problem? Simple: we go back to basics and write our own pivot routine and that is exactly what the solution was for the above situation (seen here: https://www.experts-exchange.com/questions/26675089/SQL-Pivot-help.html).
Basically, we need to get the different values which will become the new columns, aggregate something for those columns, and then do a group by and case statement to check for those columns. Sounds easy, right? Well, not quite. For the specific problem it can be easier than the approach actually taken, but when you start playing with dates (such as month names) then you have to be able to make sure that the correct sequence is achieved and that adds a few challenges when trying to resolve the problem using data to help build the dynamic SQL.
So lets get started. But first we need some data...
Now we can get down and dirty with the Pivot routine. But planning comes first... Truth be told, way back in 2001 Rob Volk posted a routine using dynamic SQL to handle a cross tab result using Dynamic SQL and my first routine appeared soon after http://www.sqlteam.com/article/dynamic-cross-tabs-pivot-tables. Since then there have been quite a few variations on the same theme, but, wanted to take a fresh new look using my original routine as inspiration.
In thinking through this routine, I wanted to accommodate a few common problems:
1) multiple aggregates. e.g. sum(quantity) and sum(value)
2) multiple pivot columns e.g. months and then year (for year to date)
3) formatting those new column names - especially with multiple aggregates, we need unique column names
4) being "dynamic" it is all data driven so data sequence for say month names becomes important.
For our routine, we therefore need the following parameters :
1) the data source - any sql that returns a result set
2) the list of columns that we want to pivot (transpose vertically to horizontal)
3) the columns that define the row ie the columns we pivot over.
4) the aggregate columns
5) formatting requirements for the new column headings (mainly dates)
Being that there are multiple columns in some of those parameters, we need to delimit them to gain access to individual unique columns. We also need to align some of them to match up by ordinal position (e.g. the 1st format relates to the first pivot column etc).
With eyes wide open and thinking "Crikey, do I really want to do this, or simply answer the question," we write our uPivot routine:
Let's have a look at the above. All we really did was to generate the column list and do a simple group by query. You can try it again replacing the EXEC(@SQL) with Print @SQL and check your messages tab.
Now let's use that procedure by plugging the parameters needed for our PIVOT procedure. We will start simple, emulating a regular pivot.
Now if that is all we wanted, then we could have done that with a simple pivot query and gained some performance improvement as well. But we did do other stuff, and now have to explore what we can really do :) So...
Lets now try multiple aggregates...
And now lets add more pivot columns as well as multiple aggregates.
Your results should look like:
![upivot_results]()
And that as they say is that. We now have a routine that does a PIVOT, works in SQL2000, and handles a variety of requirements without using the PIVOT function.
Be warned about the number of columns. The dynamic SQL does have a length limit. If needed, create a view of your data and keep names small.
VIEWS allow data to be presented in a similar way in which we use a table. A view is a good way to present data that does need some kind of transformation. It also allows a certain detachment from the underlying table. Views are really a pointer or script to the actual data and does not contain data itself more so the "rules" on how to get/show the data. Once created, it is part of the database and can be re-used as often as you like.
Please take care when running on your machine make sure you check table names, double check your code, and go a step at a time. Finally, I hope you have some fun with it.
PIVOT is a great facility. Well that was the opening line in my previous similarly named article : https://www.experts-exchange.com/Microsoft/Development/MS-SQL-Server/SQL-Server-2005/A_653-Dynamic-Pivot-Procedure-for-SQL-Server.html
But what if you want to pivot multiple columns, or maybe multiple aggregates, or both, or don't have the PIVOT statement? That's exactly what happened recently in a question where the SQL 2008 server was actually pointing to a SQL 2000 database.
So how do we solve such a problem? Simple: we go back to basics and write our own pivot routine and that is exactly what the solution was for the above situation (seen here: https://www.experts-exchange.com/questions/26675089/SQL-Pivot-help.html).
Basically, we need to get the different values which will become the new columns, aggregate something for those columns, and then do a group by and case statement to check for those columns. Sounds easy, right? Well, not quite. For the specific problem it can be easier than the approach actually taken, but when you start playing with dates (such as month names) then you have to be able to make sure that the correct sequence is achieved and that adds a few challenges when trying to resolve the problem using data to help build the dynamic SQL.
So lets get started. But first we need some data...
-- first our customer masterfile (yeah I know it is pretty ordinary)
CREATE TABLE tst_Customer_Master (
TCM_ID INT Identity Primary Key Clustered,
TCM_Customer varchar(60),
TCM_Salesman varchar(60))
GO
-- then some customer sales activity
CREATE TABLE tst_Customer_Sales (
TCS_ID INT Identity Primary Key Clustered,
TCM_ID int,
TCS_Date DATETIME,
TCS_Quantity INT,
TCS_Value MONEY )
GO
-- now let's populate our tables
INSERT tst_Customer_Master (TCM_Customer, TCM_Salesman)
SELECT * FROM (
SELECT 'Customer 1' as customer,'Salesman 1'as salesman union all
SELECT 'Customer 2','Salesman 1' union all
SELECT 'Customer 3','Salesman 2' union all
SELECT 'Customer 4','Salesman 2' union all
SELECT 'Customer 5','Salesman 3' ) as src
GO
INSERT tst_Customer_Sales (TCM_ID, TCS_Date, TCS_Quantity, TCS_Value)
SELECT * FROM (
SELECT '1' as Customer,'20100101' as Date, 11 as Qty, 1001.00 as Val union all
SELECT '1','20100201',12, 1002.00 union all
SELECT '1','20100301',13, 1003.00 union all
SELECT '1','20100401',14, 1004.00 union all
SELECT '2','20100101',21, 2001.00 union all
SELECT '2','20100201',22, 2002.00 union all
SELECT '2','20100301',23, 2003.00 union all
SELECT '2','20100401',24, 2004.00 union all
SELECT '3','20100101',31, 3001.00 union all
SELECT '4','20100201',42, 4002.00 union all
SELECT '5','20100301',53, 5003.00 ) as src
GO
-- notice I do not mention the Identity Column - SQL will manage that for me
-- notice the yyyymmdd "style 112" format - implicitly converts to datetimeNow we can get down and dirty with the Pivot routine. But planning comes first... Truth be told, way back in 2001 Rob Volk posted a routine using dynamic SQL to handle a cross tab result using Dynamic SQL and my first routine appeared soon after http://www.sqlteam.com/article/dynamic-cross-tabs-pivot-tables. Since then there have been quite a few variations on the same theme, but, wanted to take a fresh new look using my original routine as inspiration.
In thinking through this routine, I wanted to accommodate a few common problems:
1) multiple aggregates. e.g. sum(quantity) and sum(value)
2) multiple pivot columns e.g. months and then year (for year to date)
3) formatting those new column names - especially with multiple aggregates, we need unique column names
4) being "dynamic" it is all data driven so data sequence for say month names becomes important.
For our routine, we therefore need the following parameters :
1) the data source - any sql that returns a result set
2) the list of columns that we want to pivot (transpose vertically to horizontal)
3) the columns that define the row ie the columns we pivot over.
4) the aggregate columns
5) formatting requirements for the new column headings (mainly dates)
Being that there are multiple columns in some of those parameters, we need to delimit them to gain access to individual unique columns. We also need to align some of them to match up by ordinal position (e.g. the 1st format relates to the first pivot column etc).
With eyes wide open and thinking "Crikey, do I really want to do this, or simply answer the question," we write our uPivot routine:
CREATE PROCEDURE dbo.uPivot (
@sourcedata varchar(8000),
@Pivot_Over_Source_Column varchar(2000),
@pivot_value_column varchar(2000),
@Pivot_Value_Aggregates varchar(2000),
@pivot_value_format varchar(500) = NULL)
AS
/*
@sourcedata is any legitimate select statement
@Pivot_Over_Source_Column is the column(s) that define the row
@pivot_value_column is the source of data giving the new column names
@Pivot_Value_Aggregates is what the individual cells will contain NB mandatory square brackets immediately after each aggregate
@pivot_value_format is used as the convert style for @pivot_value_column with the additions of 'day' and 'month' and 'year'
-----------------------------+-----------------------+-----------------------+
Pivot_Over_Source_Column |Pivot_Value_Column 1 |Pivot_Value_Column 2 |
-----------------------------+-----------------------+-----------------------+
row1 |Pivot_Value_Aggregates |Pivot_Value_Aggregates |
-----------------------------+-----------------------+-----------------------+
row1 |Pivot_Value_Aggregates |Pivot_Value_Aggregates |
-----------------------------+-----------------------+-----------------------+
Now those aggregates in @Pivot_Value_Aggregates (yes there can be more than one)
must be expressed as a legit aggregate followed by [] or [suffix] (no spaces)
e.g. 1) sum(my_column)[]
2) count(my_column)[_count], max(my_column)[_max]
The first example will simply have the headings as defined by @pivot_value_column
The second will have two columns the first as per @pivot_value_column plus the suffix '_count'
the second column as per @pivot_value_column plus the suffix '_max'
*/
Set nocount on
declare @sql varchar(8000)
declare @columns varchar(8000)
declare @id int
-- we need to use a few temp tables to unpack our delimited list of columns.
-- while these temp tables will survive just within this stored procedure,
-- I have an old habit of dropping first - mainly because I write these things initially just as T-SQL code then turn it into a SP
If object_id('tempdb..#pivot_column_name','U') is not null drop table #pivot_column_name
If object_id('tempdb..#pivot_column_style','U') is not null drop table #pivot_column_style
If object_id('tempdb..#pivot_column_data','U') is not null drop table #pivot_column_data
create table #pivot_column_name (id int identity,pivot_column_name varchar(255))
create table #pivot_column_data (id int identity,pivot_column_name varchar(255),pivot_column_data varchar(255),pivot_column_donor varchar(255))
create table #pivot_column_style (id int identity,pivot_column_style varchar(5))
-- now unpack our delimited list of pivot columns
insert into #pivot_column_name (pivot_column_name)
select substring(pivot_value_column,number,charindex(',',pivot_value_column+',',number)-number)
from (select @pivot_value_column as pivot_value_column) p
cross join (select number from master..spt_values where type = 'p') n
where substring(','+pivot_value_column,number,1) = ','
and number <= len(pivot_value_column)
-- and unpack out delimited list of formats needed for those columns
insert into #pivot_column_style (pivot_column_style)
select substring(pivot_column_style,number,charindex(',',pivot_column_style+',',number)-number)
from (select isnull(@pivot_value_format,'') as pivot_column_style) p
cross join (select number from master..spt_values where type = 'p') n
where substring(','+pivot_column_style,number,1) = ','
and number <= len(pivot_column_style)
-- now we can examine our source data to get the unique values for the new columns
Select @id=min(id) from #pivot_column_name
While @id>0
Begin
Select @pivot_value_column=pivot_column_name from #pivot_column_name where id = @id
set @pivot_value_format = isnull((select pivot_column_style from #pivot_column_style where id = @id),'')
set @sql = 'select distinct ''' + -- next column is the definition we need to use when comparing the actual data in the final query
case when isnumeric(isnull(@pivot_value_format,'')) = 1 then 'case when convert(varchar(255),' + @pivot_value_column +','+@pivot_value_format +')'
when isnull(@pivot_value_format,'') = 'Day' then 'case when datename(Day,' + @pivot_value_column +')'
when isnull(@pivot_value_format,'') = 'Month' then 'case when datename(Month,' + @pivot_value_column +')'
when isnull(@pivot_value_format,'') = 'Year' then 'case when datename(Year,' + @pivot_value_column +')'
else 'case when convert(varchar(255),' + @pivot_value_column + ')'
end
+''','+ -- next column is the data we need to use when comparing the actual data in the final query
case when isnumeric(isnull(@pivot_value_format,'')) = 1 then ''', convert(varchar(255),' + @pivot_value_column +','+@pivot_value_format +')'
when isnull(@pivot_value_format,'') = 'Day' then ' datename(Day,' + @pivot_value_column +')'
when isnull(@pivot_value_format,'') = 'Month' then ' datename(Month,' + @pivot_value_column +')'
when isnull(@pivot_value_format,'') = 'Year' then ' datename(Year,' + @pivot_value_column +')'
else ' convert(varchar(255),' + @pivot_value_column + ')'
end
+','+ @pivot_value_column
+' from ('+ @sourcedata +') srce order by '+@pivot_value_column
insert into #pivot_column_data(pivot_column_name,pivot_column_data,pivot_column_donor)
exec (@sql)
Select @id=min(id) from #pivot_column_name where id > @id
end
-- Because of dates we need to keep the original datetime to get correct chronology, but that could cause dupes, so no must remove any dupes from our column list
delete #pivot_column_data -- kill any dupes
where exists (select * from #pivot_column_data d2 where d2.id > #pivot_column_data.id and d2.Pivot_column_name = #pivot_column_data.pivot_column_name and d2.pivot_column_data = #pivot_column_data.pivot_column_data)
-- with a distinct list of new columns, we can now construct the aggregate values for each of the columns
select @columns = isnull(@columns+',',',') + replace(replace( @pivot_value_aggregates,'(','(' + Pivot_Column_name +' =''' + pivot_column_data + ''' THEN ' ),')[', ' ELSE '''' END) as [' + pivot_column_data )
from #pivot_column_data
-- with the columns fully defined, it becomes a fairly simple group by
set @sql = 'select ' + @pivot_over_source_column+@columns + ' from ('+ @sourcedata +') srce GROUP BY ' + @pivot_over_source_column
exec (@sql)
-- now clean up - unnecessary inside a stored procedure, but again that old habit...
if object_id('tempdb..#pivot_column_name','U') is not null drop table #pivot_column_name
if object_id('tempdb..#pivot_column_data','U') is not null drop table #pivot_column_data
If object_id('tempdb..#pivot_column_style','U') is not null drop table #pivot_column_style
-- and that is that.
GOLet's have a look at the above. All we really did was to generate the column list and do a simple group by query. You can try it again replacing the EXEC(@SQL) with Print @SQL and check your messages tab.
Now let's use that procedure by plugging the parameters needed for our PIVOT procedure. We will start simple, emulating a regular pivot.
uPivot
'select tcm_customer,tcm_salesman, s.*
from tst_customer_master M
inner join tst_Customer_Sales S on M.tcm_id = S.tcm_id', -- our query
'TCM_customer', -- the rows will be for each customer
'TCS_Date', -- we want months as columns
'sum(tcs_quantity)[]', -- we will aggregate quanity
'Month' -- our columns should display month namesNow if that is all we wanted, then we could have done that with a simple pivot query and gained some performance improvement as well. But we did do other stuff, and now have to explore what we can really do :) So...
Lets now try multiple aggregates...
uPivot
'select tcm_customer,tcm_salesman, s.*
from tst_customer_master M
inner join tst_Customer_Sales S on M.tcm_id = S.tcm_id', -- our query
'TCM_customer', -- the rows will be for each customer
'TCS_Date', -- we want months as columns
'sum(tcs_quantity)[_QTY],sum(tcs_value)[_SALES]', -- we will aggregate quanity
'Month' -- our columns should display month names
And now lets add more pivot columns as well as multiple aggregates.
uPivot
'select tcm_customer,tcm_salesman, s.*
from tst_customer_master M
inner join tst_Customer_Sales S on M.tcm_id = S.tcm_id', -- our query
'TCM_customer', -- the rows will be for each customer
'TCS_Date,TCS_Date', -- we want months as columns AND years
'sum(tcs_quantity)[_QTY],sum(tcs_value)[_SALES]', -- we will aggregate quanity AND sales value
'Month,Year' -- our columns should display month names or years
Your results should look like:
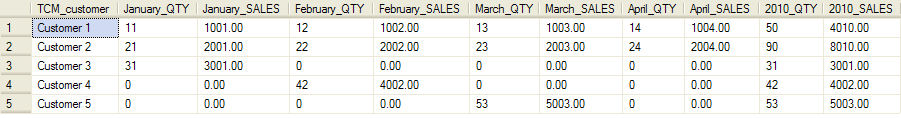
And that as they say is that. We now have a routine that does a PIVOT, works in SQL2000, and handles a variety of requirements without using the PIVOT function.
Be warned about the number of columns. The dynamic SQL does have a length limit. If needed, create a view of your data and keep names small.
VIEWS allow data to be presented in a similar way in which we use a table. A view is a good way to present data that does need some kind of transformation. It also allows a certain detachment from the underlying table. Views are really a pointer or script to the actual data and does not contain data itself more so the "rules" on how to get/show the data. Once created, it is part of the database and can be re-used as often as you like.
create view vw_custsales
as
select tcm_customer as customer
,tcm_salesman as salesman
,tcs_date as dt
,tcs_quantity as qty
,tcs_value as sales
from tst_customer_master M
inner join tst_Customer_Sales S on M.tcm_id = S.tcm_id
GO
-- also helps if you have indexes on those columns you want to pivot on
create index idx_tst_customer_sales_date on tst_customer_sales (tcs_date)
create index idx_tst_customer_master_customer on tst_customer_master (tcm_customer)
GO
-- now lets try the pivot one last time using our view
uPivot
'select * from vw_custsales', -- our query
'customer', -- the rows will be for each customer
'dt,dt', -- we want months as columns AND years
'sum(qty)[ #],sum(sales)[ $]', -- we will aggregate quanity AND sales value
'Month,Year' -- our columns should display month names or yearsPlease take care when running on your machine make sure you check table names, double check your code, and go a step at a time. Finally, I hope you have some fun with it.
Love to Help
Give a man a fish and you've fed him for a day; Teach a man to fish and you've fed him for the rest of his life. Be the teacher
Give a man a fish and you've fed him for a day; Teach a man to fish and you've fed him for the rest of his life. Be the teacher
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (3)
Commented:
You can also added a suppress-zeroes facility by replacing line 108 with this...
Open in new window
... where I used NULL in the inner part (instead of the original empty string) and added the ISNULL (or COALESCE) and CAST to output blanks instead of the NULLsI added a new parameter to allow this to be chosen by the caller.
You can also sort by the rows by adding an "ORDER BY @Pivot_over_Source_column"
It also works nicely if you add WITH ROLLUP at line 113 to get column totals, using an ISNULL (or COALESCE) with 'zz' to put the total at the bottom if you added the sort clause.
In short - thanks for a nice cross-tab solution, it's helped me with an immediate reporting need!
Author
Commented:Thanks for the feedback and for the additional insights.
Apologies for not acknowledging your comment earlier, was looking at extending the routines for a MTD and YTD requirement and only just noticed your comment.
Cheers,
Mark
Commented:
I noticed that you used master..spt_values
why will it work with Month,Day, Year, But not Quarter
I have some commented code I added but it was to analyze
Open in new window