gopher_49
asked on
slow snapshot removal
I'm using VEEAM Backup and Replication v5. It seems that when my Exchange and SQL g backups finish they hang on the snapshot removal for the VM at that moment in time doesn't respond to any client requests... It usually lasts about 15 mins... It just started doing this randomly.. Any suggestions? I plan to try creating and removing snapshots via vCenter and see if I get the same symptoms.
What Operating system are the hosts?
Any errors in the vCenter events?
Any errors in the vCenter events?
Are the Exchange and SQL VMs backed up at the same time ? To which location (NFS / SAN) are they being backed up ?
Hi gopher_49, take a look at http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=5962168 and see if you think this is applicable to your situation. Exchange and SQL can both have high transaction rates.
ASKER
I do not see any errors in vcenter. I also do not see any errors pertaining to VSS in the event logs. Where do I create a snapshot using the quiesing options and not the memory option? Is this done in VEEAM or in vcenter? All guests OS's are Windows Server 2003 Standard 32 bit with all updates.
The Exchange servers are being backed up at the same time, however, my file/SQL server finishes by itself. At the end of the job is when I see the performance issues. I see them on both hosts that the VM's are stored on. I see them on both NAS appliances. I have two NAS appliances. The VM backs up to the alternating NAS appliance. So, if VM is stored on appliance A it backs up to B and vice versa. These are low performance appliances, however, I did not have this problem in the past.
I'm about to try disabling the VCB SYNC Driver (LGTO_Sync) per the link bgoering sent.
The Exchange servers are being backed up at the same time, however, my file/SQL server finishes by itself. At the end of the job is when I see the performance issues. I see them on both hosts that the VM's are stored on. I see them on both NAS appliances. I have two NAS appliances. The VM backs up to the alternating NAS appliance. So, if VM is stored on appliance A it backs up to B and vice versa. These are low performance appliances, however, I did not have this problem in the past.
I'm about to try disabling the VCB SYNC Driver (LGTO_Sync) per the link bgoering sent.
You see it in the take a snapshot dialog as checkboxes - not sure how you would do that in Veeam.
See picture.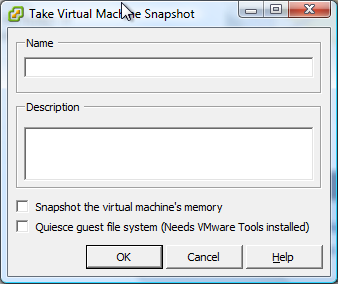
See picture.
Thats why I asked about VSS errors on the WIndows event logs, because you would usally see errors pertaining to the VCB SYNC Driver (LGTO_Sync) there (maybe).
you tick the box in vCenter
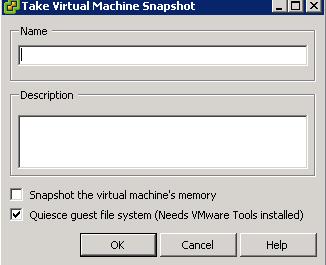
you tick the box in vCenter
Veeam will automatically call this function when it backups via API.
The test here is to see if you can generate the same issue with completing a manual snapshot, what we call a manual stun cycle in the virtual machine, because I/O is temporaily stopped or frozen!
If no issue here, it looks like latency in the datastore, can cause the same issues.
But lets wait and see the results here, but do this BEFORE you remove the SYNC driver! Because this function calls the Sync driver function.
If no issue here, it looks like latency in the datastore, can cause the same issues.
But lets wait and see the results here, but do this BEFORE you remove the SYNC driver! Because this function calls the Sync driver function.
ASKER
The link posted isn't for VSS, however, at the bottom of it there is a link pointing to VSS based snapshots. Based on the information noted in that link everything seems to be fine. My VMWare tools version is Version 4.0.0, build-208167. I'm about to upgrade it if there is a current version. I'm running Vcenter Version 4.0.0 Build 162856. Now, in VEEAM I'm accessing the VM's directly via their host and not through vcenter. I don't see how that would even matter.
Can you complete Manual Snapshots as above with no issue?
yes or no?
yes or no?
ASKER
I'll try to manually create a snapshot after hours and will then update everyone. This is the approach I told VEEAM support I would try. I'm also curious to if the native snapshot process gets the same symptoms. I'll update the ticket in the morning or late evening.
ASKER
When I first went tot the snapshot manager I saw that there was a VEEAM snapshot still residing in the snapshot manager. I thought those where supposed to be flushed out after every job. I created and removed snapshots manually.. I tried it with the default options and the ones suggested. I got the same symptoms on my Exchange VM's and my FSsql VM. When removing snapshots the server became unavailble for 10-15 secs. It hung on 95% in the tasks pane in vcenter for a very long time. Like 20 mins or so, when hung on 95% the server responded perfectly fine except once it didn't respond for 15-20 secs. So, that's not near as bad as before.. Before it was hanging for minutes and sometimes even longer. Now, I waited 30 mins or so and tried it again. I unchecked the memory option and had the quiesing option checked. This being the same option as I did earlier except this time the VM's never dropped. When pinging them maybe 2 packets failed over the entire process but that was it... The servers stayed up... It almost seems like the snapshots got purged giving me better performance?! Not sure.. I plan to run a VEAAM job and see what happens.
ASKER
I ran a VEEAM job and watched the tasks in Vcenter. When the job first starts it creates a snapshot and then removes it. It hangs on 95% as it always does. The only different this time is that the Exchange VM became non-responsive for about a minute. After that it still stayed on 95% on the removing snapshot status for 20 mins or so.. I have ICMP monitoring and Exchange service monitoring enabled.. So, when the job gets done (this is usually when it's the worst) I'll receive email notification if the server and/or services is unavailable and I'll know how lony they where unavailable. I don't mind my Exchange server dropping for 1 min or so for all clients are in cache mode and it's not a big deal, however, my file/SQL is a problem. Even if it drops for 1 or 2 mins (and it's usually way longer) files will get corrupt.. Especially in the accounting department where they use a file based accounting system. If they are posting and/or processing and the file server stops responding we'll get corrupt data possibly. Very rarely do my backups span over to working hours but I need to be able for this to happen and users not be affected.
ASKER
I just ran a full backup of an Exchange VM and the snapshot removal is hung on 95% for over 30 mins now and the VM quit responding 5+ mins.. It's still not responding... It seems on the full it's much worse than on the reverse incrementals... The below link might be of interest... I'm running ESXi version ESXi 4.0.0. 208167. Is there a patch for this version?
http://communities.vmware.com/message/1674911
http://communities.vmware.com/message/1674911
ASKER
Below is a link to VMWares ESXi patch page. Is anyone familiar with the patch that pertains to slow snapshot removal of snapshots on NFS volumes? Also, my ESXi hosts have local storage.. Right at 300 GB's... I wonder if I should use that as my snapshot storage?! This would help rule out if it's a NFS volume issue.. There seems to be a know bug out there.... I guess it might be easier to find the patch...
http://www.vmware.com/patch/s3portal.portal?_nfpb=true&_windowLabel=SearchPatch&SearchPatch_actionOverride=%2Fportlets%2Fpatchupdate%2FfindPatch&_pageLabel=s3portal_pages_downloadPatch_page
http://www.vmware.com/patch/s3portal.portal?_nfpb=true&_windowLabel=SearchPatch&SearchPatch_actionOverride=%2Fportlets%2Fpatchupdate%2FfindPatch&_pageLabel=s3portal_pages_downloadPatch_page
There have been issues with Change Block Tracking for a while. It's just just NFS.
VMware's advice would be to disable Change Block Tracking on the VM, that's having issues, however, when you do this, Incremental Backups using CBT will not work for Veeam or any other Backup Product.
See this solution here also,
https://www.experts-exchange.com/questions/26718729/CBT-Changed-Block-Tracking-VMWare-on-ESXi-4-1.html
VMware's advice would be to disable Change Block Tracking on the VM, that's having issues, however, when you do this, Incremental Backups using CBT will not work for Veeam or any other Backup Product.
See this solution here also,
https://www.experts-exchange.com/questions/26718729/CBT-Changed-Block-Tracking-VMWare-on-ESXi-4-1.html
ASKER
VMWare's solution is a HORRIBLE solution. I have local disks that are 300 GB's SCSI RAID 1+0. How can I use that datastore instead of the NFS the VM is stored on? Will I need equal space of the total VM to use this local storage?
ASKER
Also,
The solution you posted refers to change block tracing getting turned back on?! Why would I turn it back on if it only causes issues? I'm trying to replicate offsite and there's no way I can replicate offsite without CBT enabled...
The solution you posted refers to change block tracing getting turned back on?! Why would I turn it back on if it only causes issues? I'm trying to replicate offsite and there's no way I can replicate offsite without CBT enabled...
ASKER
Also,
I'm able to create iSCSI volumes with my storage appliance. It will still be a Linux based volume for that is what's running the appliance, but, it will be iSCSI. I guess I could move the VM to an iSCSI volume and see what happens... I much rather use NAS for I have a shared pool of storage OR even better simply use my local disk for snapshots only.
I'm able to create iSCSI volumes with my storage appliance. It will still be a Linux based volume for that is what's running the appliance, but, it will be iSCSI. I guess I could move the VM to an iSCSI volume and see what happens... I much rather use NAS for I have a shared pool of storage OR even better simply use my local disk for snapshots only.
Changed Block Tracking could be the issue here, and it can be problematic with ESX and snapshots.
You either need to disable it, and your incrementals will stop.
Or reset it, but disabling and enabling.
Sorry, I mean to type It's NOT just limited to NFS storage. ALL storage is affected.
DISABLE it if it's causing issues. (VMware will advise the same), or try the above to disable and re-enable.
You either need to disable it, and your incrementals will stop.
Or reset it, but disabling and enabling.
Sorry, I mean to type It's NOT just limited to NFS storage. ALL storage is affected.
DISABLE it if it's causing issues. (VMware will advise the same), or try the above to disable and re-enable.
ASKER
Why in the world do VMWare partners add features like this that simply don't work?! Horrible. I'll try disabling it and the other method. I'll update later.
ASKER
VEEAM and VMWare need a better relationship for things sometimes just don't work. When they don't work we end up resorting to calling VMWare for $300 per call... Insane... Luckily we have forums like these to resort to...
Some VMware Virtual Machines have issues with Change Block Tracking, not all, it's also worth noting that third party backup vendors use this feature in their software to increase backup speed.
We are still doing lots of reaearch in this area for both parties, to try and isolate the fault.
If it's a documented issue with VMware, you should try and get a refund.
We are still doing lots of reaearch in this area for both parties, to try and isolate the fault.
If it's a documented issue with VMware, you should try and get a refund.
ASKER
The bottom line is that VMWare should train their partners or their partners be straight up about this feature. The response I should get from VEEAM is that it's a known issue with some VM's and I should contact VMWare. This will void me causing server stability issues and void me spending a lot of time on troubleshooting this...
I'll leave it disabled for now and will update with the results.
I'll leave it disabled for now and will update with the results.
We our a VMware Partner and a Veeam Partner and we know about it, and have done since 2009!
We understand your fustration. It has caused us several issues, as vDR is reliant upon this also. If a Snapshot fails with vDR the machine does not get backed-up. This has caused us real embarrasment, because we've had to fund third party backup solutions, because vDR has failed due to this issue. (where vDR was part of the design!),
ASKER
The change block tracing option should be noted as 'use at you're own risk and can cause your VM to not respon for a very long period!'. I'm using VMWare certified appliances so I just assume that all is well... Luckily the accounting software isn't on a VM yet for it gets corrupted very easily. If a backup rolled over to the next day it would result in serious data issues and to get it fixed costs us $120 per hour.... I'm messing around with change block tracing turned off... It seems to run perfectly find in this mode.. Just slow.. I'll update in a bit.
VEEAM and VMWare need to make these feature disabled by default or have warnings for I had no idea. Backups and replications failing can cost companies a lot of money and possibly cost someone their job. Luckily I use CA BrightStor as my primary backup still and VEEAM as my redundant backup solution for fail safe..
VEEAM and VMWare need to make these feature disabled by default or have warnings for I had no idea. Backups and replications failing can cost companies a lot of money and possibly cost someone their job. Luckily I use CA BrightStor as my primary backup still and VEEAM as my redundant backup solution for fail safe..
It's very complicated trying to resolve this some clients, have no issues. Some are plagued with in. Some have been working fine, and then it stops.
Which could be, "how long CBT has been running", still working on it.
Which could be, "how long CBT has been running", still working on it.
ASKER
Mine ran just fine for a long time... My server monitoring software very rarely ever showed ICMP packets failing to these servers and never say the Exchange services rule get sent due to backups.. It started a few weeks ago... I can't take the risk so I'll keep it disabled.
ASKER
I started a VEEAM job when snapshots where still being removed. How do I manually cancel the creation of the new snapshot?
Do into Snapshot Manager and remove all Snapshots, or Cancel the Veeam job, it should deal with the snapshot on cancelling.
ASKER
I job finally cancelled.. Now, with change block tracing disabled in VEEAM (I didn't alter the .vmx files) it seems that during the end of the backup process it still hangs on 95% when removing snapshots, however, the VM is still online the entire time. Before it would become completely unresponsive for 3-7 minutes.. Now, a few of my FileMaker users did have an issue with their file when the snapshot was being removed. The only lost a few entries in the DB but it did post an error in the FileMaker application.
I guess I need to really void backups rolling over into the next day... It seems with change block tracing disabled backups run WAY smoother... I'm just thinking FileMaker is really sensative?!
I guess I need to really void backups rolling over into the next day... It seems with change block tracing disabled backups run WAY smoother... I'm just thinking FileMaker is really sensative?!
When a snpshot function is called, it can freeze the machine for micro-seconds!
Currently working on another reponse, and this is what I wrote about snapshots
What you need to work out, is how much the Virtual Machine is going to change whilst the Veeam Backup is taking place.
When you complete your Veeam Backup's is also a worth considering.
If you complete your Veeam Backup's at the business "quietest time" e.g. 3-4am in the morning, there will be very little change in the Virtual Machine, and hence less snapshot place required, compared to running the Veeam Backups at 9am in the morning.
I have a procedure, which I can share, it's quite detailed and you need to do alot, which can track changes in the VM between times, so you can see the rate of change of the virtual machine, and then work out when the best time to complete backups.
I would recommend trying to do backups at ouf hours.
Currently working on another reponse, and this is what I wrote about snapshots
What you need to work out, is how much the Virtual Machine is going to change whilst the Veeam Backup is taking place.
When you complete your Veeam Backup's is also a worth considering.
If you complete your Veeam Backup's at the business "quietest time" e.g. 3-4am in the morning, there will be very little change in the Virtual Machine, and hence less snapshot place required, compared to running the Veeam Backups at 9am in the morning.
I have a procedure, which I can share, it's quite detailed and you need to do alot, which can track changes in the VM between times, so you can see the rate of change of the virtual machine, and then work out when the best time to complete backups.
I would recommend trying to do backups at ouf hours.
ASKER
another use just mentioned the same problem... They where unable to access the network drive mappings for a very short amount of time... It seems that even with VEEAM having change block tracing disabled I'm having similar problems but not as bad... It seems that I need to edit the.VMX file also.. It still shows the 'scsi0:0.ctkEnabled = "TRUE" and 'ctkEnabled = "TRUE"' syntax. I'll set to false and run another backup and we'll see if the snapshots hang. The snapshot hung on the removal process at 95% for 20-30 mins. Randomly throughout this process some users noticed issues...
Remember if you are changing VMX settings, when
1. the machine is power-up
2. vcenter is running
is not ideal because the VMX is cached, and it can change them back
1. the machine is power-up
2. vcenter is running
is not ideal because the VMX is cached, and it can change them back
I would recommend trying to do backups at ouf hours.
"try the backups out of hours to try and avoid user issues with backups running."
ASKER
I changed my .vmx file. The changes are listed below. One thing I did notice is under the scsi 0:0 line there is a 'ctkEnabled = "FALSE" by itself. Is that normal? Should that be removed?
scsi0:1.fileName = "FSsql.vmdk"
scsi0:1.mode = "persistent"
scsi0:1.ctkEnabled = "FALSE"
scsi0:1.deviceType = "scsi-hardDisk"
scsi0:1.present = "TRUE"
scsi0:1.redo = ""
scsi0:0.ctkEnabled = "FALSE"
ctkEnabled = "FALSE"
scsi0:2.fileName = "FSsql_1.vmdk"
scsi0:2.mode = "persistent"
scsi0:2.ctkEnabled = "FALSE"
scsi0:2.deviceType = "scsi-hardDisk"
scsi0:2.present = "TRUE"
scsi0:2.redo = ""
scsi0:3.fileName = "FSsql_2.vmdk"
scsi0:3.mode = "persistent"
scsi0:3.ctkEnabled = "FALSE"
scsi0:3.deviceType = "scsi-hardDisk"
scsi0:3.present = "TRUE"
scsi0:3.redo = ""
scsi0:1.fileName = "FSsql.vmdk"
scsi0:1.mode = "persistent"
scsi0:1.ctkEnabled = "FALSE"
scsi0:1.deviceType = "scsi-hardDisk"
scsi0:1.present = "TRUE"
scsi0:1.redo = ""
scsi0:0.ctkEnabled = "FALSE"
ctkEnabled = "FALSE"
scsi0:2.fileName = "FSsql_1.vmdk"
scsi0:2.mode = "persistent"
scsi0:2.ctkEnabled = "FALSE"
scsi0:2.deviceType = "scsi-hardDisk"
scsi0:2.present = "TRUE"
scsi0:2.redo = ""
scsi0:3.fileName = "FSsql_2.vmdk"
scsi0:3.mode = "persistent"
scsi0:3.ctkEnabled = "FALSE"
scsi0:3.deviceType = "scsi-hardDisk"
scsi0:3.present = "TRUE"
scsi0:3.redo = ""
ASKER
With change block tracing disabled it takes 19 hours to backup this VM. With it enabled it usually only take 4-5 hours. Sometimes it runs very slow even with change block tracing enabled and spans over until the next day. With change block tracing enabled the server was becoming unresponsive for minutes at a time... I guess today I truly didn't not have it disabled for it was still in the .vmx file. I only disabled it via the backup software. One thing I do know is that I can't use change block tracing in the backup application for it makes the server become unresponsive for minutes at a time... If backups always finished after hours that wouldn't be a problem but sometimes they run slow and carry over.
ASKER
Also,
Is it normal for the snapshot removal to hang on 95% for 20-30 mins? I see this after hours and during busy hours too. Now, this is with change block tracing enabled on the VM and not on the application. I just now disabled it on the VM. I might end up powering the VM off and double checking the .VMX file to assure it kept the settings and then run a snapshot creation/removal and then run a backup.
Is it normal for the snapshot removal to hang on 95% for 20-30 mins? I see this after hours and during busy hours too. Now, this is with change block tracing enabled on the VM and not on the application. I just now disabled it on the VM. I might end up powering the VM off and double checking the .VMX file to assure it kept the settings and then run a snapshot creation/removal and then run a backup.
WIth Change Block Tracking disabled it will take longer, because it's doing full backup of the vmdk, and not incrementals, because change block tracking tracks the blocks which have changed.
So incrementals can be performed quicker.
So this is to be expected. If you disable, you get Full Backups, rather than incrementals.
So incrementals can be performed quicker.
So this is to be expected. If you disable, you get Full Backups, rather than incrementals.
It's not hanging at 95%, it's committing the disks. (VMware find it very difficult to have a real progress graph, so it jumps to 95%, sticks and then does the committ).
You must have lots of changes going on in the time it takes to do the backup.
But if it's taking almost 24 hours to complete a backup, there could be a days worth of changes.
I really think you need to escalate this issue to VMware, and open an SR, and get them to check your environment.
You must have lots of changes going on in the time it takes to do the backup.
But if it's taking almost 24 hours to complete a backup, there could be a days worth of changes.
I really think you need to escalate this issue to VMware, and open an SR, and get them to check your environment.
ASKER
Do you think disabling change block tracing (was still enabled in the .vmx file) will help?
ASKER
should I try to move the snapshots to a different and much faster file system?
If Backup takes 19 hours (change block tracking) is disabled.
If Backup takes 4-5 hours (change block tracking) is enabled.
If you are experiencing a high level of transactions on this server (changes made), and Snapshots will take a while to Committ, and that depends on storage, Host CPU.
Storage - how fast is it, are they are bottle necks here, are jumbo frames enable for NFS, what is the storage platform.
CPU - Host CPU is not maxed out.
If you have a bottleneck somewhere, you could experience, VM pauses, which if being used at that very time the backup is running, could cause issue.
What NFS NAS are you using?
If Backup takes 4-5 hours (change block tracking) is enabled.
If you are experiencing a high level of transactions on this server (changes made), and Snapshots will take a while to Committ, and that depends on storage, Host CPU.
Storage - how fast is it, are they are bottle necks here, are jumbo frames enable for NFS, what is the storage platform.
CPU - Host CPU is not maxed out.
If you have a bottleneck somewhere, you could experience, VM pauses, which if being used at that very time the backup is running, could cause issue.
What NFS NAS are you using?
ASKER
There are high amounts of transactions made from 8-5, however, after that there shouldn't be too many.
I'm using QNAP 850 appliances... The storage platform is Linux and the performance is tolerable... I don't see anywhere to enable jumbo frames on my NFS store. I have a GUI that manages the NFS stores. Should I find out if and how to turn it on?
During backups the host CPU is not maxed out. Maybe 70%.
I'm using QNAP 850 appliances... The storage platform is Linux and the performance is tolerable... I don't see anywhere to enable jumbo frames on my NFS store. I have a GUI that manages the NFS stores. Should I find out if and how to turn it on?
During backups the host CPU is not maxed out. Maybe 70%.
ASKER
Earlier it was at 40% when it had random issues.
It sounds like things are taking a long time. Is it perhaps a limitation of hardware? What kind of servers are you running? How much memory? And most importantly for this issue - what kind of disk storage? Local or SAN? If SAN what type? If local do you have battery backed write cache (BBWC) configured for write back mode? What kind of drives? SAS or SATA?
For you Exchange - how many users? Average size of mailbox? approximate transaction rate? For SQL how many iops are you driving?
On Veeam what is your backup media? Tape or disk? etc.
The more information the better?
For you Exchange - how many users? Average size of mailbox? approximate transaction rate? For SQL how many iops are you driving?
On Veeam what is your backup media? Tape or disk? etc.
The more information the better?
QNAP 850 appliances with NFS?
How many Exchange Users?
Jumbo Frames is really a MUST for NFS, and performance in a production enviroment.
ASKER
HP DL380 g4's
12 GB's of RAM
I'm using QNAP 850 appliances. They are lower end SATA appliances. They are VMWare ceritified though and would figure would be plenty fine for a 90 user network.
The exchange environment is 75 users on one server and 2 on the other. Both serves have the exactly same issues. Read and writting from two different appliances. They reside on two different hosts. All hosts and appliances are identical. The 75 user VM has user mailboxes at the size of around 700-800 MB per user. The 2 user server has two mailboxes that are around 15 GB's each. Not sure the iops SQL is driving but it's only an email archive DB for 80+ users.
I'm backing up to my NFS volume.
When chang block tracing is enabled with VEEAM the Exchange servers becomes unresponsive for 3-5 mins.. The file / SQL server 7-10 mins... The snapshot removal take anywhere from 20-30 mins... When CBT is disabled in VEEAM the VM's drop user connections here and there but not nearly as bad as when CBT is enabled. I have not yet disabled CBT completely via the .vmx file. I was curious to trying that tonight.
See,
When CBT is enabled usually backups finish before users get on the network so it's all good... But... Sometimes they span into the next morning. When CBT is enabled the VM's become unresponsive completely for the time mentioned above..
12 GB's of RAM
I'm using QNAP 850 appliances. They are lower end SATA appliances. They are VMWare ceritified though and would figure would be plenty fine for a 90 user network.
The exchange environment is 75 users on one server and 2 on the other. Both serves have the exactly same issues. Read and writting from two different appliances. They reside on two different hosts. All hosts and appliances are identical. The 75 user VM has user mailboxes at the size of around 700-800 MB per user. The 2 user server has two mailboxes that are around 15 GB's each. Not sure the iops SQL is driving but it's only an email archive DB for 80+ users.
I'm backing up to my NFS volume.
When chang block tracing is enabled with VEEAM the Exchange servers becomes unresponsive for 3-5 mins.. The file / SQL server 7-10 mins... The snapshot removal take anywhere from 20-30 mins... When CBT is disabled in VEEAM the VM's drop user connections here and there but not nearly as bad as when CBT is enabled. I have not yet disabled CBT completely via the .vmx file. I was curious to trying that tonight.
See,
When CBT is enabled usually backups finish before users get on the network so it's all good... But... Sometimes they span into the next morning. When CBT is enabled the VM's become unresponsive completely for the time mentioned above..
What size are the drives, how many spindles, what is the RAID configuration in your QNAP devices? Large drives with few spindles will not perform well. Note also that SATA does not perform very well if I/O rates are high, and RAID 5 will hurt you for snapshot removal because of the write penalty for RAID 5 while things are being consolidated.
As mentioned, Jumbo frames are desirable for either NFS or iSCSI so verify that is enabled.
As mentioned, Jumbo frames are desirable for either NFS or iSCSI so verify that is enabled.
Do you have SAS local storage on your servers? If so could a machine be migrated and tested there? Might be able pin it down to disk performance if so.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
I'm using RAID 6. I have 5 x 1 TB drives. All of them making 1 large NFS volume. I assume jumbo frames are setup in the NFS appliance, correct? Also, each of my ESXi hosts has local LUN's that are SCSI drives.. RAID 1+0. I have right at 300 GB's... Should I try setting this as my snapshot drive via the syntax mentioned at http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=1002929
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
And yes - but not just the snapshot drives because consolidating the data entails many writes the base disk, you should move the entire VM to local drives to test.
ASKER
What if I set my snapshots to use the RAID 1+0 array that's local to the host?
RAID 6 on SATA is killing your write performance, which gets very busy during snapshot removal as data is being consolidated.
ASKER
I can't move the entire VM for it's too large and saving the snapshots to this drive will cause disk space issues... I might be able to move the Exchange server to the local disk but not the file / SQL server..
Can you try moving the entire VM to local? Also verify you have the BBWC mentioned above on the local controller.
ASKER
do you think disabling CBT in the .vmx is worth a try?
I think you would be better MOVING the VMs OFF onto Local Storage, and using the NAS as Backup.
If you only have one ESX server and you are not using vMotion, HA, DRS.
Provided that you local disk is U320 10k or 15k SCSIs, with Smart Array controller with BBWC.
If you have more than one ESX host, and need to use vMotion, HA, DRS, you should seriosuly look at new storage for this environment.
If you only have one ESX server and you are not using vMotion, HA, DRS.
Provided that you local disk is U320 10k or 15k SCSIs, with Smart Array controller with BBWC.
If you have more than one ESX host, and need to use vMotion, HA, DRS, you should seriosuly look at new storage for this environment.
ASKER
Also,
I get the same symtpoms when replcating via the VM running the replication software and the host that the VM resides on being a different host than the other two mentioned above.. I get the exact same symptoms. I guess this points to the base disks the VM's are stored on for the target is different.
I get the same symtpoms when replcating via the VM running the replication software and the host that the VM resides on being a different host than the other two mentioned above.. I get the exact same symptoms. I guess this points to the base disks the VM's are stored on for the target is different.
Waste of TIME.
You storage is not up to the job I'm afraid.
You storage is not up to the job I'm afraid.
ASKER
I have two ESXi hosts. Each has 273 GB's of RAID 1+0 storage. I can move each Exchange server to this volume, however, when creating snapshots I'm worried about running out of storage. Should I redirect the snapshot creation to my NAS appliance to void running out of drive space?
What size is our the Exchange disks?
Snapshot writes on the NFS won't hurt as bad as having the base disk there. You would typically only have one level of snapshot anyway. It is the writes that is hurting the most. If you could clear the NAS and make it RAID 5 that would help.
We put in a new Hitachi AMS2100 at our DR site last year with several shelves of 10k and 15k SAS drives. Our storage admin said "cool, it supports RAID6" and so set it up that way. You should have heard the DBA's and other users scream about performance! He had to redo it to RAID1+0 for Oracle logs, and RAID5 for DATA and VMFS.
We put in a new Hitachi AMS2100 at our DR site last year with several shelves of 10k and 15k SAS drives. Our storage admin said "cool, it supports RAID6" and so set it up that way. You should have heard the DBA's and other users scream about performance! He had to redo it to RAID1+0 for Oracle logs, and RAID5 for DATA and VMFS.
obviously if you move off shared storage to local, you'll lose vMotion, HA, DRS if you have it licensed.
ASKER
the thing is that it worked perfectly fine in the past... These symptoms just recently appeared. Maybe the transactions have only increased. I'll move one of the Exchange server to the new storage once backups finish. I want a up to date backup of the server before moving. I guess I can go back to the good ole' fashion extermal attached SCSI based storage... Drives are pretty expensive and I usually get used drives, but, the performance is insane.
When configuring my external storage appliance should I spring for RAID 1+0 or do you think RAID 5 will be just fine? Or, should I try RAID 5 with my current SATA appliance? I have 3 x drive bays available. I could try that... Is that worth even trying?
When configuring my external storage appliance should I spring for RAID 1+0 or do you think RAID 5 will be just fine? Or, should I try RAID 5 with my current SATA appliance? I have 3 x drive bays available. I could try that... Is that worth even trying?
You need to fine out if this NAS supports NFS. (Jumbo Frames).
RAID 10 would be better.
RAID 10 would be better.
RAID 10 typically a bit faster, but I use RAID5 pretty much everywhere and don't have any trouble.
ASKER
I'll have a response from QNAP tomorrow in regards to if their NAS supports Jumbo Frames... The Exchange disks are 75, 50, and 50. The last one is for an email archiver.
ASKER
How much extra storage will I need (in gerneral) if my Exchange VM is 185 GB's? Will having 50 GB's be enough?
ASKER
The previous question was in regards to snapshot storage.. Will 50 GB's be enough? For now I want to move a 185 GB Exchange VM to a volume that has 250 GB's free. I should be able to safely use 50 GB's for snapshot storage. Is that safe?
Just make sure you run Veeam Backups, at quite times.
I would also re-enable CBT on local volumes.
You do have U320 10k or 15k disks?
BBWC - Battery Backed Write Cache and Smart Array controller?
You do have U320 10k or 15k disks?
BBWC - Battery Backed Write Cache and Smart Array controller?
I generally recomment about 20% of the datastore size, so if your datastore is 300 GB then about 60GB would be appropriate. For your test I would simply move the machine to local and don't change where snapshots are pointed, run your test then if successful redirect your snapshots to the NAS and test again... see if there is much difference.
so if the backup starts and takes 4-5 hours, starting at 2am finishing at 7am, how many emails in and out of the Exchange server, and how big will the snapshot grow.
you could manually test this, with a manual snapshot at these times, but you'd have to stop backups that day.
you could manually test this, with a manual snapshot at these times, but you'd have to stop backups that day.
ASKER
I have U320 10K drives on a Smart Array 6400 with Battery Cache. 128 MB. By default the snapshots are stored where the VM is stored so those will move too.
during the times of backups the amount of emails is VERY small... I know for almost all are automatically deleted at the frontend server for 99% of them are SPAM and never hit the backend server.
Even during after hours times the Exchange servers become nonresponsive for minutes... You'll see Outlook give server errors and the server can't be pinged...
I'll move the server this evening and test.
during the times of backups the amount of emails is VERY small... I know for almost all are automatically deleted at the frontend server for 99% of them are SPAM and never hit the backend server.
Even during after hours times the Exchange servers become nonresponsive for minutes... You'll see Outlook give server errors and the server can't be pinged...
I'll move the server this evening and test.
cool gopher_49 - let us know how it goes
ASKER
Also,
My NFS appliance spec sheet has the below note about jumbo frames..
•Dual Gigabit LAN with Jumbo Frame
I guess the Jumbo Frame protocol is supported.. I'll verify. But.. Do I have to enable it on the ESXi host, switches, and appliance?
My NFS appliance spec sheet has the below note about jumbo frames..
•Dual Gigabit LAN with Jumbo Frame
I guess the Jumbo Frame protocol is supported.. I'll verify. But.. Do I have to enable it on the ESXi host, switches, and appliance?
ASKER
I just verified and my Jumbo MTU is set to 1500. Do I enable on my switch and ESXi now?
yes.
Do one thing at a time. Not all at once.
But yes, you need to set this to 9000.
see my solution here
https://www.experts-exchange.com/questions/26700015/Enable-Jumbo-Frames-on-ESXi-4-1.html
BUT BE Warned.
You need to enable on your Switch, NAS, ESXi servers.
otherwise all sorts of network issues are going to happen!
DO NOT ENABLE WITHOUT PLANNING!!!
Do one thing at a time. Not all at once.
But yes, you need to set this to 9000.
see my solution here
https://www.experts-exchange.com/questions/26700015/Enable-Jumbo-Frames-on-ESXi-4-1.html
BUT BE Warned.
You need to enable on your Switch, NAS, ESXi servers.
otherwise all sorts of network issues are going to happen!
DO NOT ENABLE WITHOUT PLANNING!!!
ASKER
I'll give it a shot after hours. Most likely tomorrow.
ASKER
How much of a difference in performance can this make?
It could be considerable improvement in performance for large block reads and writes, but it won't fix the write performance on only 5 spindles of SATA configured as RAID 6
depends on how good your storage is!
what's the bottleneck, but when we've enabled jumbo frames for Software iSCSI, we've seen better performance than hardware based ISCSI initators.
have you got both NICs on the NAS connected to the switches, as Aggregated Links, not sure if it supports this.
what's the bottleneck, but when we've enabled jumbo frames for Software iSCSI, we've seen better performance than hardware based ISCSI initators.
have you got both NICs on the NAS connected to the switches, as Aggregated Links, not sure if it supports this.
ASKER
Is supports dual nics aggregated but I only have it as fail over right now.
something to change as well, providing you got a switch that can be configured for it as well.
ASKER
I changed the MTU to 9000 on vSwitch1 for both ESXi server. My third ESXi server does not have SSH enabled on it. I need to enable it. Please send a link for the one I have is old... I do not plan to replicate or use the third ESXi server for a few days so it's not a big deal. The switch is setup to handle packets up to 9220 bytes. I guess there's no reason to set the exact MTU for the switch for it handles 1522 up to 9220 bytes. I also set both NAS appliances to use a MTU of 9000. I also plan to use both NIC's. I'll set that up tomorrow.
So,
I'll run some backups with the new jumpbo packets enabled and we'll see if it helps?!
So,
I'll run some backups with the new jumpbo packets enabled and we'll see if it helps?!
Have you tried moving a troublesome machine to the local SAS storage? Or did you want to try the jumbo frames first...
To be fair to readers and experts, and to try and keep this extended question on topic, please post a new question with reference to SSH enabled on server.
ASKER
I plan to move the troublesome VM's to my local LUN's which are a SCSI based RAID 1+0 array. When we discussed doing this someone asked if I had jumbo packets enabled... When I replied that I didn't it was suggested that when using NAS appliances I really need to have this enabled. So, we're giving that a shot for I plan to use these appliances for my backup target at mininum. I possibly plan to use them as my snapshot drive also for I have so much extra space on my NAS appliances. I do see myself moving one of the VM's to the local storage to see how the snapshot removal works... I'm wanting to watch the snapshot removal with jumbo packets enabled. So far it seems that my backups accelerated much quicker. It usually takes awhile before they accelerate to their maximum speed, however, with jumbo packets enabled it accelerated much faster.
Let's recap on my symptoms and configuration changes for there is some info I left out... Starting around the 9th of this month at the end of my Exchange and file / SQL VM backup job the VM's become un-responsive. Anywhere from 3-10 mins... I also noticed during the snapshot removal process it hangs on 95% for 30 mins sometimes. Now, all of this happend when running jobs on veeambackupserver1. The particular server was giving me other problems so on the 15th I moved my jobs to veeambackupserver2. When doing so I have to run full jobs again... During that weekend I received the same symptoms. During the snapshot removal process VM's became un-responsive. I tried turning change block tracing off and it helped in regards to tbe VM becoming un-responsive... It still became un-responsive randomly throughout the removal process, but, not nearly as bad. Bad enough where users noticed it during working hours. So, we enabled change block tracing again. The backup jobs run much faster now and usually will finish before users connect, however, every once and awhile my jobs run REAL slow... So slow they span over until the morning when users are on the network. This is where I run into my problem. It seems that no matter what configruation I do (prior to jumbo packets) during the snapshot removal process I have performance issues. We ended up with a few corrupt files last time. So, my goal is make the snapshot removal process much shorter and even if it occurs during working hours users are not affected. I'm currently running backup jobs that will finish at different times. I plan to make note to how long each snapshot removal process takes. I also have monitoring enabled for if the VM becomes un-responsive I'll be emailed. The last time snapshots finished the monitoring polling intervals didn't catch any ICMP or service queries failing, however, users did have some issues saving and working in database files.. So, sometimes monitoring doesn't always catch it.
Let's recap on my symptoms and configuration changes for there is some info I left out... Starting around the 9th of this month at the end of my Exchange and file / SQL VM backup job the VM's become un-responsive. Anywhere from 3-10 mins... I also noticed during the snapshot removal process it hangs on 95% for 30 mins sometimes. Now, all of this happend when running jobs on veeambackupserver1. The particular server was giving me other problems so on the 15th I moved my jobs to veeambackupserver2. When doing so I have to run full jobs again... During that weekend I received the same symptoms. During the snapshot removal process VM's became un-responsive. I tried turning change block tracing off and it helped in regards to tbe VM becoming un-responsive... It still became un-responsive randomly throughout the removal process, but, not nearly as bad. Bad enough where users noticed it during working hours. So, we enabled change block tracing again. The backup jobs run much faster now and usually will finish before users connect, however, every once and awhile my jobs run REAL slow... So slow they span over until the morning when users are on the network. This is where I run into my problem. It seems that no matter what configruation I do (prior to jumbo packets) during the snapshot removal process I have performance issues. We ended up with a few corrupt files last time. So, my goal is make the snapshot removal process much shorter and even if it occurs during working hours users are not affected. I'm currently running backup jobs that will finish at different times. I plan to make note to how long each snapshot removal process takes. I also have monitoring enabled for if the VM becomes un-responsive I'll be emailed. The last time snapshots finished the monitoring polling intervals didn't catch any ICMP or service queries failing, however, users did have some issues saving and working in database files.. So, sometimes monitoring doesn't always catch it.
In the test we've completed local storage will always be faster than NFS, iSCSI or FC. Especially when using U320 10k drives.
If it was me, I would leave the Snapshots on the same local disks as the VMs. (I would just hate to see corruption happen, if snaphots went bad reading or writing). Again snapshots, if the VM is on local disk it will read faster, Incrementals will work better with Veeam and CBT, backups will be faster, less changes in the VM, quicker Snapshot Committ, no use issues, and less data in the Snapshot.
Enable Jumbo Frames for use with NFS, and use the QNAP NAS, as a backup device, due to slow SATA, not many spindles. It will perform very well as a Backup NAS, and also test servers (not for production use).
Just my thoughts, you don't have to follow them.
If it was me, I would leave the Snapshots on the same local disks as the VMs. (I would just hate to see corruption happen, if snaphots went bad reading or writing). Again snapshots, if the VM is on local disk it will read faster, Incrementals will work better with Veeam and CBT, backups will be faster, less changes in the VM, quicker Snapshot Committ, no use issues, and less data in the Snapshot.
Enable Jumbo Frames for use with NFS, and use the QNAP NAS, as a backup device, due to slow SATA, not many spindles. It will perform very well as a Backup NAS, and also test servers (not for production use).
Just my thoughts, you don't have to follow them.
ASKER
When purchasing the QNAP appliances I read most admins used them for labs and for backup storage. I just figured with a 95 user network I could possibly squeeze by using them in a production environment... They are tolerable except for when removing snapshots. When I first deployed my VM's I did not have enough local storage to use my local disks.. So... I moved forward with the QNAP appliances. Now, after moving some data around I might be able to use an external storage enclosure and get right at 500 GB's of SCSI RAID 5 U320 storage. These being 10K drives... So... I might be able to move all of my troublesome VM's to local storage. It will take some time but it's possible.
Now,
Here are the results from my backup jobs... The Exchange server snapshots removed in a few seconds... This is perfeclty fine considering most of my users use cache mode and won't even notice it anyway. My file / SQL server snapshot removed in 3 mins. During most of this time the VM was un-responsive. This is perfectly fine except for every once and awhile my file / SQL backup runs insanely slow. Like 6-10 MB/sec instead of the somestime 50-70 MB/sec. Not sure to why but it sometimes happens... Now... If the backup runs really slow does this mean the snapshot is going to remove really slow too? I guess there are many factore to consider but I'm really concerned about what happens when I start to do remote replication. When doing remote replication backups will deffiantely be much slower and snapshot removal will most deffinately happen during the morning of some of the work days...
Now,
Here are the results from my backup jobs... The Exchange server snapshots removed in a few seconds... This is perfeclty fine considering most of my users use cache mode and won't even notice it anyway. My file / SQL server snapshot removed in 3 mins. During most of this time the VM was un-responsive. This is perfectly fine except for every once and awhile my file / SQL backup runs insanely slow. Like 6-10 MB/sec instead of the somestime 50-70 MB/sec. Not sure to why but it sometimes happens... Now... If the backup runs really slow does this mean the snapshot is going to remove really slow too? I guess there are many factore to consider but I'm really concerned about what happens when I start to do remote replication. When doing remote replication backups will deffiantely be much slower and snapshot removal will most deffinately happen during the morning of some of the work days...
ASKER
typo.. I meant 3 mins on the snapshot removal of one Exchange snapshot and 1 min for the removal of the other Exchange snapshot. The file / SQL snapshot was 3 mins as noted above.
ASKER
Also,
During a full backup should snapshot removal always be slower than when doing a reverse incremental?
During a full backup should snapshot removal always be slower than when doing a reverse incremental?
snapshot removal time is related to the amount of data written to the snapshot that must be consolidated back into the base disk. When the backup runs a long time, it would follow that more data would be written to the snaps, and thus the longer to commit and remove them.
Because incrementals should run considerably faster than a full backup, it would follow that the snapshot removal should also be a bit quicker.
Because incrementals should run considerably faster than a full backup, it would follow that the snapshot removal should also be a bit quicker.
ASKER
So,
Since my replica jobs will obviously be running slower in theory I should have a larger snapshot to remove, however, that early in the morning I don't see what transactions would be occuring causing this to result in a large snapshot.
In my environment my reverse incrementals run extremely slow every once and awhile. Like 10 times slower which results into backups spanning into the next day... If I can void this from happening then I wouldn't have problems... I guess what's happening is that the snapshot gets so large due to it running for so long by the time it's removed it's huge. I just dont know why this happens. But I need an environment where no matter how long a replica or backup jobs runs the snapshot removal will not cause users issues. Currently if my jobs work properly I'm okay.. It's just when they run really slow I run into problems.
Since my replica jobs will obviously be running slower in theory I should have a larger snapshot to remove, however, that early in the morning I don't see what transactions would be occuring causing this to result in a large snapshot.
In my environment my reverse incrementals run extremely slow every once and awhile. Like 10 times slower which results into backups spanning into the next day... If I can void this from happening then I wouldn't have problems... I guess what's happening is that the snapshot gets so large due to it running for so long by the time it's removed it's huge. I just dont know why this happens. But I need an environment where no matter how long a replica or backup jobs runs the snapshot removal will not cause users issues. Currently if my jobs work properly I'm okay.. It's just when they run really slow I run into problems.
ASKER
Also,
I do see performance increase on all backups jobs since enabling jumbo frames. It didn't seem to fix my snapshot removal issue for it still takes awhile to remove a snapshot that was created during a 2 hours backup job when no users where on the network. If it took 3 mins to remove a snapshot in that small of a window it will take forever in the situation I run into when backups decide to run extremely slow... But... It did help overall performance. My BrightStor backup jobs and VEEAM backup jobs ran faster for sure.. Not a huge difference but deffiantely noticeable. My throughput increased on all jobs.. I know it's hard to compare with reverse incrementals when CBT is enabled, but, my full backups jobs all ran faster. I'll compare over the next few days too.. Not sure to if load balancing the dual gigabit ports will make much of a difference for none of the ports on my switch have ever reached 1 GB/sec.
I do see performance increase on all backups jobs since enabling jumbo frames. It didn't seem to fix my snapshot removal issue for it still takes awhile to remove a snapshot that was created during a 2 hours backup job when no users where on the network. If it took 3 mins to remove a snapshot in that small of a window it will take forever in the situation I run into when backups decide to run extremely slow... But... It did help overall performance. My BrightStor backup jobs and VEEAM backup jobs ran faster for sure.. Not a huge difference but deffiantely noticeable. My throughput increased on all jobs.. I know it's hard to compare with reverse incrementals when CBT is enabled, but, my full backups jobs all ran faster. I'll compare over the next few days too.. Not sure to if load balancing the dual gigabit ports will make much of a difference for none of the ports on my switch have ever reached 1 GB/sec.
Yes - I would expect better transfer speed across the network to your SAN by enabling jumbo frames and this should speed up backup times, however the disk perfomance of local SAS over NFS SATA will help with the snapshot removal. Another big help is I believe you said the local SAS is RAID 1+0 and the NFS is RAID 6 - I had a really bad experience where my storage admin set up some RAID 6 stuff on SAS and the write performance was so bad as to be intolerable. Once reconfigured for RAID 5 all was good.
If rule of thumb you pay a 15% penalty in write performance for RAID 5, then (again rule of thumb from my storage vendor) you pay an additional 27% penalty for RAID 6.
If rule of thumb you pay a 15% penalty in write performance for RAID 5, then (again rule of thumb from my storage vendor) you pay an additional 27% penalty for RAID 6.
ASKER
My NAS appliances will support RAID 1+0 with the official release of the new firmware next month. I'm wondering if even in a RAID 5 or a RAID 1+0 config if my NAS appliance will be able to remove snapshots properly. For now I thought about slowly moving some data I have around and free'ing up right at 500 GB's of storage in my SCSI U320 environment. I then planned on moving my file / SQL VM to this new series of SCSI drives... I'll have 250 GB's of RAID 1+0 that the VM can use and about 300 GB's of RAID 5 that it can use. These arrays will be running off of a Smart Array 6400 with 128MB battery cache. Since my file / SQL VM is the main problem it makes sense to move it for I really don't mind my Exchange servers being unavailable for a few mins... It's not a big deal in my environment due to users being in cache mode. I'll address those two VM's later...
So,
I'm still a little confused.. I understand that moving to my SCSI local disks will have much better performance and the snapshots created during my reverse incremental jobs will remove much quicker... Currently it takes 1-3 mins on my Exchange VM's and 3-5 mins on my file / SQL VM... During the time of the snapshot removal the VM's are un-responsive for almost the entire time. So, will this new SCSI config still allow clients to access the VM's during snapshot removal OR is the goal to have the snapshot removal so fast the VM never has a chance to become un-responsive?
So,
I'm still a little confused.. I understand that moving to my SCSI local disks will have much better performance and the snapshots created during my reverse incremental jobs will remove much quicker... Currently it takes 1-3 mins on my Exchange VM's and 3-5 mins on my file / SQL VM... During the time of the snapshot removal the VM's are un-responsive for almost the entire time. So, will this new SCSI config still allow clients to access the VM's during snapshot removal OR is the goal to have the snapshot removal so fast the VM never has a chance to become un-responsive?
Snapshot removal so fast the VM never has a chance to become un-responsive!
Correct, a Snapshot, is what we call in the trade a Stun Cycle - it Stuns the VM! very quicky for what should be a micro-second! (very short period of time!).
Depending on the underlying storage platform, host CPU performance, networking, how busy the VM is, it may not be prudent ever to Stun it! (Snapshot!). As more and more Backup products use the API to Snapshot, which they must do to take the Lock of the main VMDK to back it up.
Transaction based VMs, SQL, Exchange and AD seem to be the worse at recognising they been stuned! (snapshotted), many years ago we removed the Sync drivers from VMware Tools for AD, SQL servers etc, had big discussions with VMware and Backup Vendors that were reliant about this Snapshoting Technology. Which is umm, well you experience it.
Some work we do now, we do not Snapshot the VM at all, we snapshot the underlying storage, so there is no Stun, this produces a crash consistent backup. (and we could debate this for ever, the downside and upside of this!)
Correct, a Snapshot, is what we call in the trade a Stun Cycle - it Stuns the VM! very quicky for what should be a micro-second! (very short period of time!).
Depending on the underlying storage platform, host CPU performance, networking, how busy the VM is, it may not be prudent ever to Stun it! (Snapshot!). As more and more Backup products use the API to Snapshot, which they must do to take the Lock of the main VMDK to back it up.
Transaction based VMs, SQL, Exchange and AD seem to be the worse at recognising they been stuned! (snapshotted), many years ago we removed the Sync drivers from VMware Tools for AD, SQL servers etc, had big discussions with VMware and Backup Vendors that were reliant about this Snapshoting Technology. Which is umm, well you experience it.
Some work we do now, we do not Snapshot the VM at all, we snapshot the underlying storage, so there is no Stun, this produces a crash consistent backup. (and we could debate this for ever, the downside and upside of this!)
ASKER
As I understand I have to use your sync drivers due to VEEAM's method and/or calls to your API's.. So... I guess the bottom line is I need to beef up my storage as much as possible to handle these transactions, correct? The goal is to make the snapshot removal insanely fast.. Correct?!
I have 6 x 146 GB SCSI drives I can allocate to a RAID 5 array. 3 of these are in a storage volume mounted to one of my ESXi hosts. There is no data on the volume when I browse them via the datastore browse feature in vSphere. So, I need to physically remove these drives from this host. What's the best way to remove this volume from this ESXi host? Do I need to open a new ticket for this?
I have 6 x 146 GB SCSI drives I can allocate to a RAID 5 array. 3 of these are in a storage volume mounted to one of my ESXi hosts. There is no data on the volume when I browse them via the datastore browse feature in vSphere. So, I need to physically remove these drives from this host. What's the best way to remove this volume from this ESXi host? Do I need to open a new ticket for this?
Normally you would need to open a new ticket so we could get more points :) But this one is easy - just go to the storage screen on the configuration tab. Click on your empty datastore, then click delete.
Yes, beef the storage up.
6 x 146GB SCSI U320 RAID 5 should perform well. (but don't be too upset if you see the VM Stun!).
6 x 146GB SCSI U320 RAID 5 should perform well. (but don't be too upset if you see the VM Stun!).
ASKER
ok.. I guess I'm kinna stuck until the weekend. I need to move a really large VM (380 GB's) to the new SCSI datastore. I'll feel more comfortable doing this after a successful backup and on the weekend. I also have a bunch of data to move around. My goal is to have a RAID 5 array at the size of around 700 GB's this weekend. I'll then move the entire VM to the new datastore. I also plan to enable port trunking on the ports my NAS appliances are plugged into. Between port trunking and the jumbo packets I enabled I'll be able to move this VM much quicker to the new targe SCSI datastore. I already moved a template today and averaged around 250 mbps which is pretty good in my environment. It only took 4 mins to a little more than 7 GB's... I should be able to move my VM in a little over 3 hours at this rate. Not sure if port trunking will speed it up but I figured I'll go ahead and enable it this weekend also since I have the ability to do so. I'll make a call to HP to assure I'm enabling dynamic LACP port trunking properly.
I'll update the ticket this weekend. Thanks for everyone's help.
I'll update the ticket this weekend. Thanks for everyone's help.
ASKER
I don't want to see the VM Stun! hahahahaha... Do I need to really shoot for RAID 1+0 or will stunning possibly occur simply due to the method VEEAM is using to create/remove the snapshot?
it's not Veeam or any third party backup product. It's VMware Archirtecture that Stuns the VM.
see : 34639894
see : 34639894
ASKER
Isn't that the ticket number we're currently using? If stunning is something that has to occur due to the .vmdk being locked then thats fine as long as it's so quick users don't notice it and/or files don't get corrupt is users are connected at that time.
Again, it depends on your SLA, Service too users etc
34639894 is my previous comment above. http:/Q_26731168.html#a34639894
34639894 is my previous comment above. http:/Q_26731168.html#a34639894
ASKER
I'll probably end up creating two large RAID 1+0 arrays... I'll try the RAID 5 first.
gopher_49 you might find this article of interest: http://itknowledgeexchange.techtarget.com/virtualization-pro/what-is-changed-block-tracking-in-vsphere/
It explains change block tracking and how that works to speed up incremental backups...
It explains change block tracking and how that works to speed up incremental backups...
ASKER
In regards to SLA.. For some reason every once and awhile my file / SQL backup job runs insanely slow... This is really the only time I have real problems. Even with CBT enabled sometimes it runs at around 6 MB/sec which runs into the next day's working hours. When the snapshots get removed I have issues. Now, the reason it's slowing down every once and awhile might be a VEEAM issue. If I can isolate that problem and fix it I'll be okay. Even with my current storage solution. But... I need a solution where even if users are connected snapshots can be removed without causing problems. I plan to eventually replicate over a WAN and I'm sure my replica jobs will roll over into working hours sometimes.
ASKER
bgoering,
Thanks for the article. I've read about CBT in the past and have been utilizing it for about 4-6 months now. It really speeds up my reverse incrementals. I thought it was the problem in regards to my snapshot removal, however, it seems to be my environment and/or storage. Jumpbo frame sure did speed up backups and other operations I've been performing since enabling it though.. I guess now I just need more I/O's... This weekend I'll be able to see what change for I should have my troublesome VM on a RAID 5 with 6 x 146 GB drives.
Thanks for the article. I've read about CBT in the past and have been utilizing it for about 4-6 months now. It really speeds up my reverse incrementals. I thought it was the problem in regards to my snapshot removal, however, it seems to be my environment and/or storage. Jumpbo frame sure did speed up backups and other operations I've been performing since enabling it though.. I guess now I just need more I/O's... This weekend I'll be able to see what change for I should have my troublesome VM on a RAID 5 with 6 x 146 GB drives.
ASKER
Also,
The troublesome VM will be moving to an external SCSI enclosure. The SCSI cable connecting the enclosure to the SmartArray 6400 controller is about 6 feet long. Does this make much of a difference in performance? If so, I can move the storage enclosure to the same rack as the server and get a 3 foot cable instead.
The troublesome VM will be moving to an external SCSI enclosure. The SCSI cable connecting the enclosure to the SmartArray 6400 controller is about 6 feet long. Does this make much of a difference in performance? If so, I can move the storage enclosure to the same rack as the server and get a 3 foot cable instead.
I have never had any issues with 6 ft. SCSI cables - performance should be the same.
As long as it's a good quality Screened SCSI Cable, you should have no issues.
ASKER
It's insanely thick and I think it's the one that came with the Dell PowerVault 210S. I didn't purchase it new so my knowledge of it is limited, however, it seems to be a really thick quality cable.
Just curious for 6 feet seems a little long...
Just curious for 6 feet seems a little long...
Take a look at http://www.pcguide.com/ref/hdd/if/scsi/summary.htm - it is a table that shows specs for different types of SCSI cables. Lengths are given in meters.
I've got HP ones here that are that length, you could swing from tree with them! They very thick, like an amoured electrrical cable.
ASKER
thanks for the info. I think I'm good... I'll move my troublesome VM to the new array this weekend. Also, the vendor of my NAS appliance said there is performance issues with my current firnware. Upgrading the firmware will give me was faster results. They also suggested that I wait until next month and get the firmware that supports RAID 1+0. For now I'll use my new array.
ASKER
I created a RAID 5 array with 6 x 146 GB u320 drivers. The total size of the array is 683 GB's. The total size of my VM is approx 390 GB's. The largest .vmdk file is 276 GB's. When trying to move the VM I get a message 'File is larger than the maximum size supported by datastore 'vmhost2datastore2'
ASKER
I found the below link... I can change the block size, but, will this result in slower performance? I'm currently using a 1 MB 256 GB block size.
http://www.theblueboxes.com/vmware-esx-error-file-larger-maximum-size-supported-datastore
http://www.theblueboxes.com/vmware-esx-error-file-larger-maximum-size-supported-datastore
block size of store?
i dont think it should affect performance.
ASKER
yes. I have it set to 1 MB 256GB max file size. I can move it up to 2 MB 512GB max size.
increase it, good luck.
Performance can often get better with larger block sizes - and you will need at least 2MB block size to support larger than 256GB vmdk.
ASKER
I set it to 2 MB block sized and started the move. I'm averaging about 500 mbps via the statistics on my data switch for those two ports. In the past doing this I usually averaged about 250 mbps. The VM files are around 390 GB's so it will be done in about 3 hrs.. I'm a little confused for each port is showing 50% of 1 GB so I would think it would send at 500 mbps.... But, in the past it ended up being exactlty 250 mbps. Maybe I'm understanding the stats wrong.. But, since enabling jumbo frames I'm easily getting 250 mbps on copied. I plan to enable load balancing next weekend. Not sure if I'll need it but my switch and NAS appliance supports it. Of course I'll be using my SCSI array for my high transaction VM's anyway.. But, it won't hurt to load balance. Also, my NAS appliance vendor said with next months firmware upgrade and support for RAID 1+0 I'll see huge performance changes. I have a feeling I'll be sticking my good ole' fashion SCSI drives though. I'll update the ticket once the copy is done and I get a chance to run a backup and then I'll try to access the VM's while the snapshot is being removed.
ASKER
The copy is done and it only took 2 hrs 10 mins. That is way faster than any copy I've ever done. The jumbo packets I'm sure helped in that. It ended up on being around 390 mbps for it finished 350 GB's in a little over 2 hrs. The VM is booted and I'm about to do a snapshot and test it.
ASKER
I noticed my backups are running slow after copying this VM. Is this due to a lot of changed blocks after the copy? Usually I get way faster speeds on reverse incrementals assuming there isn't a ton of changes. Would change block tracing not help much as a copy of a VM? I guess since the target was a new datastore all of the blocks are new and/or showing as changed?
If I had to guess I would guess it is doing a full backup after the move
ASKER
VEEAM backup job is hanging on 3% and doesn't seem to be progressing. The VEEAM agent process is using a decent amount of CPU so it's deffinately trying to do something. I'm beginning to wonder if I should cancel the job and just do a full and have it not try CBT. I think the job is confused somehow.
could be - a full would at least reset everything in the new location
ASKER
yea. I'm giong to cancel it.. This is also a good way to test snapshot removal. Assuming the cancel works.
Any luck?
ASKER
ok. I had to delete the entire job from VEEAM to force it to do a true full backup. I dumped my backup sets to tape and then deleting all backup sets/jobs pertaining to this VM. Otherwise it would hang on 3%. It's now on 26% and averaging 12-14 MB/sec which is way faster than my previous full backup speeds. I used to get 7-8 MB/sec on full backups. There's deffinately an increase in performance in I/O based on those stats alone. Also, in the process of cancelling the previous jobs I had to remove snapshots. During this time I tested the VM's response to clients by sending constant ICMP packets. Maybe 2 out of the hundreds that where sent failed. So, it never became un-responsive for any large amount of time. We'll see how well the snapshot removal of this current VEEAM job does. But... So far it seems to be much more tolerable. To be honest. I'm thinking my NAS appliances will perform very close to this if I move to RAD 1+0 and utilize the new firmware being released. But.. For now we'll stick with the SCSI array. I'll update the ticket once this snapshot removal occurs. On my VEEAM full backups jobs I used to see the worse of the performance issues when removing snapshots... This will be a good test.
I can tell you for a fact you will never achieve the same throughput on a SATA NAS appliance that you will with local 10K or better SCSI/SAS drives. However, what you can do and what you need to do business are often two different things. I am certain that with RAID 1+0 instead of RAID 5 and with the jumbo frames you have going on now - the performance of you NAS appliance will be a lot better than it was before and may very well be sufficient for you. Just don't get spoiled with what you are achieving now if you are planning on going back :)
ASKER
I agree. Right now I'm running RAID 6 on a NAS appliance that has known performance issues with my current firmware. What I'm thinking is that once upgrading to the new firmware and moving to RAID 1+0 there's a good chance I can use this NAS appliances for my low transaction VM's and for a backup appliance also. This will allow me to need less SCSI storage for SCSI storage isn't cheap and comes in small increments.. We'll see.. But, I plan to keep my Exchange, file, and SQL servers on my SCSI arrays... I wish I had 300 GB's size SCSI drives for then I could create a RAID 1+0 array and still have enough storage. I'll update the ticket in regards to the snapshot removal in about 10 hrs.
ASKER
When my full backup completed it took 2mins 25 secs to remove the snapshot. That is way less than before for full backups usually resulted in a very slow snapshot removal. I was not on the network when it completed so I was unable to see if the VM was responding, however, I'm changing my ICMP polls to every 30 secs right before backups run. This will allow me to get a better understanding of how the VM is responding when it removes the snapshot, however, so far it seems that users will be able to use the network when removing snapshots.
ASKER
In regards to jumpbo packets/frames... I only set my core switch (the one that has my servers and NAS appliances) for a MTU of 9000. Do I need to set the switches that are uplinks into this one also? The reason I ask is that my VEEAM backup server is a phyiscal server. The network card supports jumbo packets, however, if I set this to a MTU of 9000 my EAP port authentication fails for clients connecting through the other switches. Does this mean I need to set jumbo packets on all switches?
Set the switches and ports up as jumbo frames, on the devices that need to use them,
So comminications between ESX and NAS - jumbo frames, enabled on both devices and switch that connects them.
If you Veeam Backup Server is also connected to this switch, and to take advantage of jumbo frames, you'll also need to enable JF on the server as well, I don't know what switches you have by somew switches you can enable JF on the ports, and some switches, JF is enabled on the whole switch.
So comminications between ESX and NAS - jumbo frames, enabled on both devices and switch that connects them.
If you Veeam Backup Server is also connected to this switch, and to take advantage of jumbo frames, you'll also need to enable JF on the server as well, I don't know what switches you have by somew switches you can enable JF on the ports, and some switches, JF is enabled on the whole switch.
Every device in the path that needs jumbo frames need to be set up, if you have periphy switches connecting normal servers/workstations not using the NAS they shouldn't have to be set up.
ASKER
The 6 switches I have uplinking into the core switch do not support jumpbo frames and are 10/100. None of the devices plugged into those switches need to use jumbo frames. Now, here's the problem I ran into. The physical server that is the VEEAM server is a domain controller, email archiver, IAS port authentication server, and VEEAM server. The EAP packets sent in the port authentication process do not support jumbo frames and/or I need to set jumbo frames on the wireless controller and client ports which can't be done. So, I can easily redirect IAS EAP authentication to another server, however, what about my other services/resources on this server. Should those be okay? The only service/resource that had issues was the EAP packets being sent to the server.
If that is the only one having difficulties and it can be easily moved then I would probably move it. However, it sounds like your NAS is in a seperate VLAN - can you just set the NIC in that one VLAN to jumbo frames? Or possibly dedicate a different server to the Veeam role?
ASKER
Everything is in the same VLAN. The entire VLAN on the core switch is setup for jumbo frames. I have redudant IAS servers that use EAP packets.. So... I can easily just use one of them for authentication. It's a quick and simple change. Another option would be to add another NIC card that has a MTU of 1500 and use that NIC card for IAS EAP authentication. For now I'll simply remove the server that has a MTU of 9000 from a listed authetication server.
I'll update the ticket shortly in regards to the VM responding during snapshot removals.
I'll update the ticket shortly in regards to the VM responding during snapshot removals.
ASKER
What about my clients hitting the VM's? Since the clients and the switch ports are set to a MTU of 1500 I guess that is the MTU that will stay thoughout the session?
My file / SQL VM just completed it's first reverse incremental. It's hard to tell performance based on the throughput noted in VEEAM for CBT is the one speeding things up based on changes.. But.. I incresed my ping increments to 30 secs. Every 30 secs 4 ICMP's are sent. If two fail it will send me an email. Not once did it detect a two or more requests timed out.. So... I'm thinking I'm good to go.
I'll test again tomorrow.
My file / SQL VM just completed it's first reverse incremental. It's hard to tell performance based on the throughput noted in VEEAM for CBT is the one speeding things up based on changes.. But.. I incresed my ping increments to 30 secs. Every 30 secs 4 ICMP's are sent. If two fail it will send me an email. Not once did it detect a two or more requests timed out.. So... I'm thinking I'm good to go.
I'll test again tomorrow.
ASKER
Tomorrow's ICMP rules will be configured as this... 4 sent every 15 seconds. If any fail then I'll be emailed. I would assume maybe one will fail here and there.. But, that shouldn't stop people from saving a file I would hope. I know for sure it will void people being disconnected completely.
I'm glad it's all looking good, after a very long question.
ASKER
It was a long question for sure but it addressed the infrastructure which had to be addressed to really get an understanding of where the bottleneck is. It seems that I have a few bottlenecks but in regards to my problem my snapshot removal really seems to be a disk I/O issue. A lot of it seems to be the RAID 6 config. It obviously takes a huge performance hit compared to RAID 5 and RAID 1+0, however, even if my NAS was configured to RAID 5 or RAID 1+0 I'm just not sold on the fact it will be able to remove snapshots and accecpt client requests all at the same time. It seems that it's just too much I/O for it. I do plan to give it a shot in the future though. For now I'll keep my file / SQL VM on my good ole' fashion RAID 5 scsi array for it's removing the snapshots so much faster and I can't get it to drop packets.
I opened up a another ticket at https://www.experts-exchange.com/questions/26764641/jumbo-frames-on-Windows-2003-server.html in regards to jumbo packets. I would like both of you to come over and join in.
I opened up a another ticket at https://www.experts-exchange.com/questions/26764641/jumbo-frames-on-Windows-2003-server.html in regards to jumbo packets. I would like both of you to come over and join in.
ASKER
I moved my troublesome VM to a SCSI RAID 5 array and snapshots can now be removed without users experiencing issues. I enabled jumbo frames on my QNAP appliances and that helped performance in regards to my backups and users accessing VM's that have datastores on the NAS, however, in regards to removing snapshots the SCSI based RAID 5 array was my only option. QNAP has a new firmware coming out in late FEB 2010 that supports RAID 1+0 and fixes various performance issues. I'll be testing that firmware in regards to snapshot removals in Feb. For now I plan to stick with my SCSI RAID 5 array.
there's a new kb for issues with snapshots on NFS datastores:
http://kb.vmware.com/kb/1031106 - Virtual machine freezes temporarily during snapshot removal on an NFS datastore in a ESX/ESXi 4.1 host
http://kb.vmware.com/kb/1031106 - Virtual machine freezes temporarily during snapshot removal on an NFS datastore in a ESX/ESXi 4.1 host
Also try and create a snpshot, with Quiesing Ticked, but not Memory?
Does it do the same?