PDF Decryption?
Hi Experts,
Someone's sent me a PDF file which I can read on the screen (via Acrobat Reader and Foxit Reader), but I'd like to read it with my screen reader software (TextAloud). TextAloud can usually read PDFs, but for this one it just reads rubbish ("greater-than 4 exclamation-point 5 percent T", etc). I've confirmed this by trying to copy and paste from the PDF to Notepad, and all I get is a lot of special characters, most of which are boxes. I assume this is because the PDF was created with some kind of encryption, right?
Q1. How do you recommend I resolve this problem (for free)? (I don't want to go back to the person who sent it to me, because they've spent enough time on this already, and I'd like a solution I can use in future, too.)
Q2. Will PDF decryption software solve this problem?
Q3. If so, what software can you recommend? (I see many on the web, but I don't know what's good and what's not.)
Q4. Do you know of any (free) online solutions, which don't require me to install any software on my PC? This would be my preference. (Sometimes I use zamzar.com, but it doesn't seem to decrypt PDFs.)
Please number your answers (1-4) accordingly.
Thanks.
tel2
Someone's sent me a PDF file which I can read on the screen (via Acrobat Reader and Foxit Reader), but I'd like to read it with my screen reader software (TextAloud). TextAloud can usually read PDFs, but for this one it just reads rubbish ("greater-than 4 exclamation-point 5 percent T", etc). I've confirmed this by trying to copy and paste from the PDF to Notepad, and all I get is a lot of special characters, most of which are boxes. I assume this is because the PDF was created with some kind of encryption, right?
Q1. How do you recommend I resolve this problem (for free)? (I don't want to go back to the person who sent it to me, because they've spent enough time on this already, and I'd like a solution I can use in future, too.)
Q2. Will PDF decryption software solve this problem?
Q3. If so, what software can you recommend? (I see many on the web, but I don't know what's good and what's not.)
Q4. Do you know of any (free) online solutions, which don't require me to install any software on my PC? This would be my preference. (Sometimes I use zamzar.com, but it doesn't seem to decrypt PDFs.)
Please number your answers (1-4) accordingly.
Thanks.
tel2
ASKER
Hi Joe,
Thanks for your prompt response.
> A1. Convert the PDF to text using Boxoft's FREE PDF to Text Converter:
> http://www.boxoft.com/pdf-to-text/
I haven't yet tried this, but I did try saving directly from Acrobat Reader to Text and I landed up with the same kind of rubbish that I did when I copied and pasted, so I doubt this will be any better.
> Or convert the PDF to Word using Nuance's FREE PDF Reader:
> http://nuancepdf.com/PDFReader/Download.aspx
First you install the reader, then it lets you upload files for conversion.
I doubt this will work, based on my examples above and below.
> A2. I doubt it, because I don't think the file is encrypted.
Q2a. How can we tell whether it's encrypted?
> A3. N/A if I'm right that it's not encrypted.
Q3a. What is it called when the creator takes the option to stop people from being able to copy & paste from a PDF? I guessed it was "encryption", but maybe it's called something else.
> A4. Convert the PDF to Word using one of these online tools:
> http://www.pdfonline.com/pdf-to-word-converter/
> http://www.pdftoword.com/
OK, I've tried both of those, but I end up with documents containing rubbish, a bit (or maybe a byte) like when I saved as text or copied and pasted.
Please answer Q2a & Q3a above.
Thanks.
tel2
Thanks for your prompt response.
> A1. Convert the PDF to text using Boxoft's FREE PDF to Text Converter:
> http://www.boxoft.com/pdf-to-text/
I haven't yet tried this, but I did try saving directly from Acrobat Reader to Text and I landed up with the same kind of rubbish that I did when I copied and pasted, so I doubt this will be any better.
> Or convert the PDF to Word using Nuance's FREE PDF Reader:
> http://nuancepdf.com/PDFReader/Download.aspx
First you install the reader, then it lets you upload files for conversion.
I doubt this will work, based on my examples above and below.
> A2. I doubt it, because I don't think the file is encrypted.
Q2a. How can we tell whether it's encrypted?
> A3. N/A if I'm right that it's not encrypted.
Q3a. What is it called when the creator takes the option to stop people from being able to copy & paste from a PDF? I guessed it was "encryption", but maybe it's called something else.
> A4. Convert the PDF to Word using one of these online tools:
> http://www.pdfonline.com/pdf-to-word-converter/
> http://www.pdftoword.com/
OK, I've tried both of those, but I end up with documents containing rubbish, a bit (or maybe a byte) like when I saved as text or copied and pasted.
Please answer Q2a & Q3a above.
Thanks.
tel2
ASKER
After a bit of Googling, it looks as if the term might be "protected", not "encrypted". Still need a solution though. Tried GuaPDF Demo 3.25, but that says my PDF is not "encryped", so I guess I need different software.
I'm looking here:
http://pcsupport.about.com/od/toolsofthetrade/tp/pdf-password-remover.htm
I'm looking here:
http://pcsupport.about.com/od/toolsofthetrade/tp/pdf-password-remover.htm
Can you post the file? I'd like to take a run at it with commercial-grade (non-free) tools that I have.
ASKER
I'll consider that, Joe, if other options don't work out.
Thanks.
tel2
Thanks.
tel2
ASKER
OK Joe,
Here's a link to pages 2 & 3 of the PDF. I extracted them by printing to Primo PDF. I see the text is vertical in this extract, but I still have the same problems with it.
https://www.transferbigfiles.com/ba25543c-98c4-41da-a933-d2de1f90c928?rid=vcfQnm7my4558Wj3YkzI3w2
Thanks.
Here's a link to pages 2 & 3 of the PDF. I extracted them by printing to Primo PDF. I see the text is vertical in this extract, but I still have the same problems with it.
https://www.transferbigfiles.com/ba25543c-98c4-41da-a933-d2de1f90c928?rid=vcfQnm7my4558Wj3YkzI3w2
Thanks.
Yep, if the file were encrypted, you wouldn't be able to view it on the screen via Adobe Reader and Foxit Reader without the decryption key. To see what the "protections" are (Adobe term is "Restrictions"), open the file in Adobe Reader, and then [File>Properties>Security]
Btw, when you open the PDF in Adobe Reader, does it say "SECURED" on the title bar, like this:
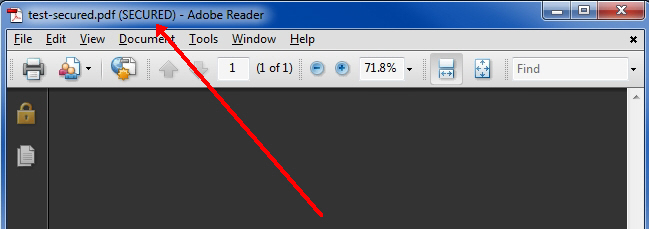 Regards, Joe
Regards, Joe
Btw, when you open the PDF in Adobe Reader, does it say "SECURED" on the title bar, like this:
Regards, Joe
Our posts crossed. Let me know if TextAloud can handle the attached. Regards, Joe
P2-3-copy-paste-read-aloud.pdf
P2-3-copy-paste-read-aloud.pdf
ASKER
Thanks Joe. That's a good start!
I opened it in Acrobat Reader 8.1.3 and I note the following:
- Yes, TextAloud can read it.
- I can copy and paste it and the paragraph text appears.
- I can't select the headings anymore (e.g. when I drag across them), and they do not paste after I select all then copy.
- When I try to do File > Save as Text, it now crashes, and offers to send a report to Microsoft.
- The restrictions shown in Properties > Security seem to be the same as in the file I gave you.
- The size of the PDF has increased from about 56KB to 180KB. (That's not a problem for me, but I wonder why.)
What did you do to make all the above changes?
I opened it in Acrobat Reader 8.1.3 and I note the following:
- Yes, TextAloud can read it.
- I can copy and paste it and the paragraph text appears.
- I can't select the headings anymore (e.g. when I drag across them), and they do not paste after I select all then copy.
- When I try to do File > Save as Text, it now crashes, and offers to send a report to Microsoft.
- The restrictions shown in Properties > Security seem to be the same as in the file I gave you.
- The size of the PDF has increased from about 56KB to 180KB. (That's not a problem for me, but I wonder why.)
What did you do to make all the above changes?
Since you extracted the file by printing to PrimoPDF, I did not even attempt to figure out the core problem, because I need the original file to do that. In other words, the file created by PrimoPDF may not have the same issues as the original file. I'll be happy to try to figure out the "real" problem, but I'll need the original PDF for that.
What I did was use an imaging product called PaperPort to make a PDF Searchable Image file, which is a PDF file that has both the images and a layer of text created by OCR. That's why you can't select the headings – the quality of the headings are worse than the text in the body, and are so bad that the OCR process can't create text from them. You can see the "image", and you know what it says because the human brain is the best OCR engine in the world, but there's no text created for the headings.
[File>Save as Text] crashes here, too, in Adobe Reader 9.5.2, which is really weird, since Select All and then Copy works just fine. Go figure.
No surprise that the restrictions are the same...I don't think that's the issue.
The size increased because of the process to convert it from the PDF file you sent to a PaperPort PDF Searchable Image file. Regards, Joe
What I did was use an imaging product called PaperPort to make a PDF Searchable Image file, which is a PDF file that has both the images and a layer of text created by OCR. That's why you can't select the headings – the quality of the headings are worse than the text in the body, and are so bad that the OCR process can't create text from them. You can see the "image", and you know what it says because the human brain is the best OCR engine in the world, but there's no text created for the headings.
[File>Save as Text] crashes here, too, in Adobe Reader 9.5.2, which is really weird, since Select All and then Copy works just fine. Go figure.
No surprise that the restrictions are the same...I don't think that's the issue.
The size increased because of the process to convert it from the PDF file you sent to a PaperPort PDF Searchable Image file. Regards, Joe
ASKER
Thanks Joe,
I'd prefer not to pass on the original document as it contains some stuff that people may not want passed on. But the document I've given you fails in the same 3 areas that I said the original did (i.e. copy/paste, TextAloud, Save as Text), and shows the same restrictions in Properties > Security, so would you be willing to treat that as the original and try to work out how I should get such PDFs to work in those 3 areas, with free options? If your final solution works on this but not my original, I can always convert the original to the Primo PDF format before using your solution.
Regarding heading quality, I can zoom in on them in the file I gave you and the quality looks good to me. The font is different from the rest, so I would expect that OCR is just not recognising that font. Would you agree?
BTW, I already have something called ScanSoft PaperPort 11 installed (not sure if it's the same software you have - this came with a Brother MFC-990CW), but I didn't know that it could do OCR on a PDF file. It's not really the solution I'm after (since it misses the headings), but where is the option to do that? I can't see it.
Thanks.
tel2
I'd prefer not to pass on the original document as it contains some stuff that people may not want passed on. But the document I've given you fails in the same 3 areas that I said the original did (i.e. copy/paste, TextAloud, Save as Text), and shows the same restrictions in Properties > Security, so would you be willing to treat that as the original and try to work out how I should get such PDFs to work in those 3 areas, with free options? If your final solution works on this but not my original, I can always convert the original to the Primo PDF format before using your solution.
Regarding heading quality, I can zoom in on them in the file I gave you and the quality looks good to me. The font is different from the rest, so I would expect that OCR is just not recognising that font. Would you agree?
BTW, I already have something called ScanSoft PaperPort 11 installed (not sure if it's the same software you have - this came with a Brother MFC-990CW), but I didn't know that it could do OCR on a PDF file. It's not really the solution I'm after (since it misses the headings), but where is the option to do that? I can't see it.
Thanks.
tel2
> so would you be willing to treat that as the original and try to work out how I should get such PDFs to work in those 3 areas, with free options?
OK, I'll work on it during the weekend.
> so I would expect that OCR is just not recognising that font. Would you agree?
Nope. OCR can handle that font fine.
> ScanSoft PaperPort 11
Yes, that's the same software, but an earlier version. Turns out that PP11 and prior versions require a separate Nuance product called OmniPage in order to create a PDF Searchable Image file...that's why you can't see it (btw, ScanSoft acquired Nuance and decided to keep the Nuance name for the merged companies). PP12 and PP14 (yes, Nuance got superstitious and skipped version 13) have the ability to create a PDF Searchable Image file without the separate OmniPage product (the OmniPage Capture SDK is utilized in PP12 and PP14 to provide its OCR engine).
Btw, I'm in the US Central Time zone...hence, my lack of response last night. I assume from your spelling of "recognise" that you're in the UK. Cheers, Joe
OK, I'll work on it during the weekend.
> so I would expect that OCR is just not recognising that font. Would you agree?
Nope. OCR can handle that font fine.
> ScanSoft PaperPort 11
Yes, that's the same software, but an earlier version. Turns out that PP11 and prior versions require a separate Nuance product called OmniPage in order to create a PDF Searchable Image file...that's why you can't see it (btw, ScanSoft acquired Nuance and decided to keep the Nuance name for the merged companies). PP12 and PP14 (yes, Nuance got superstitious and skipped version 13) have the ability to create a PDF Searchable Image file without the separate OmniPage product (the OmniPage Capture SDK is utilized in PP12 and PP14 to provide its OCR engine).
Btw, I'm in the US Central Time zone...hence, my lack of response last night. I assume from your spelling of "recognise" that you're in the UK. Cheers, Joe
ASKER
Thanks very much for your efforts, and info, Joe.
I'm in NZ (New Zealand), (one of UK's colonies, hence my spelling..."errors"). GMT+12 (or GMT+13 during DST, which is now). No worries with any delays. This is not that urgent.
I'm in NZ (New Zealand), (one of UK's colonies, hence my spelling..."errors"). GMT+12 (or GMT+13 during DST, which is now). No worries with any delays. This is not that urgent.
Here's a screenshot from Adobe Reader after doing File>Properties>Fonts on the PrimoPDF version of the file:
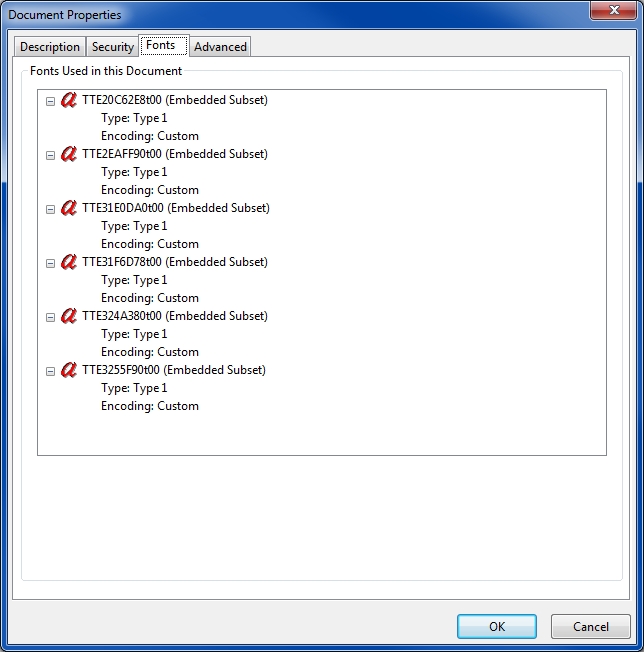 Do you see the same thing in the original file? If you don't mind posting the File>Properties>Fonts dialog from the original file, that would be helpful. Regards, Joe
Do you see the same thing in the original file? If you don't mind posting the File>Properties>Fonts dialog from the original file, that would be helpful. Regards, Joe
Do you see the same thing in the original file? If you don't mind posting the File>Properties>Fonts dialog from the original file, that would be helpful. Regards, Joe
ASKER
Hi Joe,
The original has many more fonts than the PrimoPDF version. Too many to fit all the Type/Encoding details on one screen shot, but I see those details are all the same, so see attached with only the 1st font's details expanded.
Thanks.
PDF-Original.gif
The original has many more fonts than the PrimoPDF version. Too many to fit all the Type/Encoding details on one screen shot, but I see those details are all the same, so see attached with only the 1st font's details expanded.
Thanks.
PDF-Original.gif
Hi tel2 (don't recollect seeing your name anywhere along the way),
I think the problem is related to the embedded fonts and the use of non-standard encoding for mapping glyph indices to characters. The way they're doing it results in garbage characters during Copy/Paste and Save As Text. This theory is bolstered by the following message from Acrobat X during Save As Text:
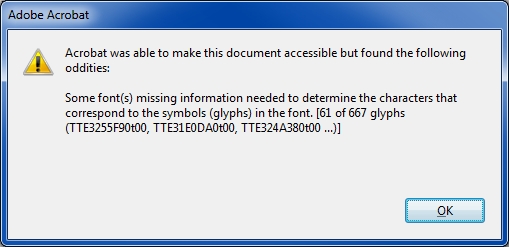 I don't think this is fixable...if it is, I don't know how to do it. I tried many things...none worked. I think the only recourse is to go back to the creator of the document.
I don't think this is fixable...if it is, I don't know how to do it. I tried many things...none worked. I think the only recourse is to go back to the creator of the document.
I did take another run at OCR with better results. Instead of using PaperPort, I used the full OmniPage Professional 18 software to rotate the document and then OCR it. The OmniPage Proofreader did not flag any words, meaning it was confident that it OCRed everything correctly. I told OP18 to make a Word 2007 file...it is attached (DOCX). In case you don't have Word 2007 (or 2010), I had Word 2007 save it as a Word 97-2003 document (DOC), also attached. Then I used the Acrobat plug-in in Word to create a PDF, also attached. As you can see, OP18 got the headers right, and I think everything else, too, but let me know if you see any OCR errors that it made. Regards, Joe
P.S. When I tried to upload the DOCX file, it wouldn't let me. The nice thing about the DOCX is that it's much smaller...around 1/3 the size...12,567 bytes, while the DOC is 34,304. I tried to upload it by changing the file type but it still didn't work (there's something inside the DOCX that EE doesn't like...it says, "The extension of one or more files in the archive is not in the list of allowed extensions"). No big deal...just wanted to let you know.
P2-3-OCR-OmniPage18Pro.doc
P2-3-OCR-OP18-PDF-Acrobat.pdf
I think the problem is related to the embedded fonts and the use of non-standard encoding for mapping glyph indices to characters. The way they're doing it results in garbage characters during Copy/Paste and Save As Text. This theory is bolstered by the following message from Acrobat X during Save As Text:
I don't think this is fixable...if it is, I don't know how to do it. I tried many things...none worked. I think the only recourse is to go back to the creator of the document.I did take another run at OCR with better results. Instead of using PaperPort, I used the full OmniPage Professional 18 software to rotate the document and then OCR it. The OmniPage Proofreader did not flag any words, meaning it was confident that it OCRed everything correctly. I told OP18 to make a Word 2007 file...it is attached (DOCX). In case you don't have Word 2007 (or 2010), I had Word 2007 save it as a Word 97-2003 document (DOC), also attached. Then I used the Acrobat plug-in in Word to create a PDF, also attached. As you can see, OP18 got the headers right, and I think everything else, too, but let me know if you see any OCR errors that it made. Regards, Joe
P.S. When I tried to upload the DOCX file, it wouldn't let me. The nice thing about the DOCX is that it's much smaller...around 1/3 the size...12,567 bytes, while the DOC is 34,304. I tried to upload it by changing the file type but it still didn't work (there's something inside the DOCX that EE doesn't like...it says, "The extension of one or more files in the archive is not in the list of allowed extensions"). No big deal...just wanted to let you know.
P2-3-OCR-OmniPage18Pro.doc
P2-3-OCR-OP18-PDF-Acrobat.pdf
ASKER
Thank you so much for your time and efforts, Joe.
> I don't think this is fixable...if it is, I don't know how to do it.
Do you think it would make any difference if you had the original PDF to work with?
> I think the only recourse is to go back to the creator of the document.
What should I say to the creator? (I think they might be using CutePDF to generate it from Publisher, and I don't think they are very technical types.)
> I don't think this is fixable...if it is, I don't know how to do it.
Do you think it would make any difference if you had the original PDF to work with?
> I think the only recourse is to go back to the creator of the document.
What should I say to the creator? (I think they might be using CutePDF to generate it from Publisher, and I don't think they are very technical types.)
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Thanks for all that, Joe!
I must try doPDF myself sometime, too.
Feel free to take the rest of the day off. You certainly deserve it.
tel2
I must try doPDF myself sometime, too.
Feel free to take the rest of the day off. You certainly deserve it.
tel2
You're welcome! Have a great day. Cheers, Joe
A1. Convert the PDF to text using Boxoft's FREE PDF to Text Converter:
http://www.boxoft.com/pdf-to-text/
Or convert the PDF to Word using Nuance's FREE PDF Reader:
http://nuancepdf.com/PDFReader/Download.aspx
First you install the reader, then it lets you upload files for conversion.
A2. I doubt it, because I don't think the file is encrypted.
A3. N/A if I'm right that it's not encrypted.
A4. Convert the PDF to Word using one of these online tools:
http://www.pdfonline.com/pdf-to-word-converter/
http://www.pdftoword.com/
Regards, Joe