DISTINCT and GROUP BY... and why does it not work for my query?


Published:
Browse All Articles > DISTINCT and GROUP BY... and why does it not work for my query?
0. Introduction
Often, when running a query with joins, the results show up "duplicates", and often, those duplicates can be "eliminated" in the results using DISTINCT, for example.Using DISTINCT is simple: just add it after the SELECT keyword, and you don't get duplicates. Unless you expect something else of what is a duplicate (and what not) than SQL does actually do.
DISTINCT will not return two rows with the same values. To make it clear: it will compare the returned columns for the SELECT it is applied to, and not to the full table/join. The user problem is usually that they "expect" SQL to apply the DISTINCT only for one (or more) key fields, for example the first column returned in the select.
Usually, GROUP BY can solve this, but it might not be the most efficient method, or fail to accomplish other issues with the requirements in the query.
The good method to solve the problem is to step back, and look at both the data and the requested output, which, once clarified, can be translated into SQL Query "easily".
1. Tables and Data
We usually have 2 tables in the scenario:
one master/parent table,
one dependant table, linked through a 1:n relationship, with information such as history, traffic, accounting, etc information.
Notes:
a related table is usually referred to as child table.
a related table should have, as all tables, its own primary key.
In real-world, the field employee_pk would be indexed to ensure optimal performance.
For visualizing, here the data, queried using the SQL Server Management Studio 2005:
Employees:
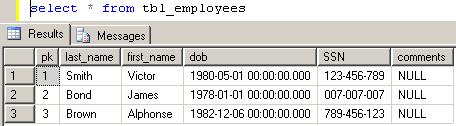
Work Records:
 If you have trouble with dates/times, please refer to this article.
If you have trouble with dates/times, please refer to this article.
2. What is the exact requirement?
Request: Presume we want to see the last work day, per employee.For Smith and Brown, we can forecast no major problems, but Bond lists 2 records for the last day...
Hence, you have to clarify:
do we just want the last record (date+time), or any record for the last date (ignoring time)?
if all "duplicates" have the same value, is there another column to discriminate them, so we can decide on which one to take?
if there are multiple records to be taken, what is the result we want to have?
Important:
This "problem" has to be solved first. Once the results from child table are OK, we can then join those results to the parent table (see step 7)
In our example, we could say:
A: give me just the last record, per employee, considering date + time![Result A]()
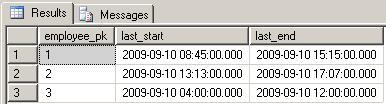
B: give me all records of the last day, per employee![Result B]()
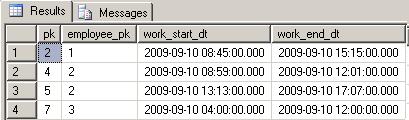
C: give me the last date, per employee, with the earliest time for the work-start field, but the latest time for the work-end field
![Result C]()
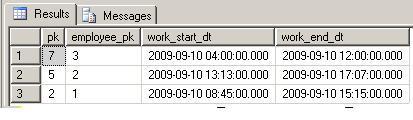
As you see, I showed the expected result data, and NOT the code yet; and all the results are different.
We will in the next steps show the SQL to achieve those results, in the different engines.
3. This might be fine... but usually is not
To get this result: Result_0.JPG, you just need to run this query, works across all databases (which is the only + for this syntax):select employee_pk
, max(work_start_dt) last_start
, max(work_end_dt) last_end
, max(pk) last_pk
from tbl_Employee_WorkRecords
group by employee_pk;
the value of max(pk) does not necessarily match the max(work_start_dt) or max(work_end_date)!
if you had other columns you wanted to show, you would have the same issue as for pk, and using max() or min() shall not give the correct results
4. Result A
So, let's take this query, which is using the correlated subquery technique, which works also for all databases:select t.*
from tbl_Employee_WorkRecords t
where t.work_start_dt =
( SELECT MAX(i.work_start_dt)
from tbl_Employee_WorkRecords i
where i.employee_pk = t.employee_pk
);select t.*
from tbl_Employee_WorkRecords t
join ( select employee_pk, max(work_start_dt) max_start_dt
from tbl_Employee_WorkRecords
group by employee_pk
) i
on i.employee_pk = t.employee_pk
and i.max_start_dt = t.work_start_dtSo, two working techniques, all fine, you could say, what else do we need?
The issue is this: in our sample data, there are no real duplicates (date+time).
Let me show the results, with this MS SQL server query, letting the query ignore the time portion:
--- MS SQL Server
select t.*
from tbl_Employee_WorkRecords t
where convert(varchar(10), t.work_start_dt, 120) =
( SELECT convert(varchar(10), MAX(i.work_start_dt), 120)
from tbl_Employee_WorkRecords i
where i.employee_pk = t.employee_pk
)You can see that if we had duplicates, the query would result also in duplicates. Both techniques shown have the same weakness!
To solve this, we need a unique row identifier. In my table, we could use the PK field, and the correlated query syntax becomes:
-- ms sql server
select t.*
from tbl_Employee_WorkRecords t
where t.pk = ( select top 1 i.pk
from tbl_Employee_WorkRecords i
where i.employee_pk = t.employee_pk
order by i.work_start_dt DESC
)For MySQL Server, at least until the latest version documentation I have which is 5.4, I have bad news:
ORDER BY + LIMIT in a correlated subquery is not supported
http://dev.mysql.com/doc/refman/5.4/en/subquery-errors.html
For Oracle, we will have to say more or less the same: the TOP 1 from MS SQL Server cannot be implemented simply like this:
-- oracle => incorrect code
select t.*
from tbl_Employee_WorkRecords t
where t.pk = ( select i.pk
from tbl_Employee_WorkRecords i
where i.employee_pk = t.employee_pk
and rownum = 1
order by i.work_start_dt DESC
)You might find some subquery in subquery syntax, but honestly: don't try, just use the much easier and still efficient method shown now:
-- oracle
select sq.*
from ( SELECT t.*
, ROW_NUMBER() OVER ( PARTITION BY employee_pk ORDER BY work_start_dt DESC ) rn
FROM tbl_Employee_WorkRecords t
) sq
WHERE sq.rn = 1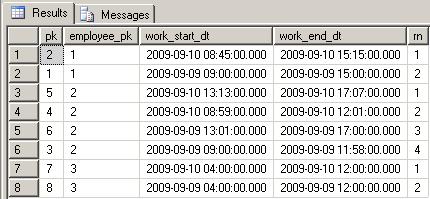 The same syntax will actually work in MS SQL Server 2005 or higher, but not in SQL 2000 or lower, though.
The same syntax will actually work in MS SQL Server 2005 or higher, but not in SQL 2000 or lower, though.
I will not discuss the performance of this syntax here; you can check this out for yourself using the execution plans/explain plans and timing the queries.
I have seen no major problems with either syntax, so far, in my applications.
5. Result B
We now want all records for the last day. In the previous section, I have already suggested a method for MS SQL Server, i.e. using CONVERT() to ignore the time portion.Let's look at it again, more closely:
--- MS SQL Server
select t.*
from tbl_Employee_WorkRecords t
where convert(varchar(10), t.work_start_dt, 120) =
( SELECT convert(varchar(10), MAX(i.work_start_dt), 120)
from tbl_Employee_WorkRecords i
where i.employee_pk = t.employee_pk
)The main issue is performance, as this part:
where convert(varchar(10), t.work_start_dt, 120) = (subquery)
will make it impossible to use an index on work_start_dt (unless you used oracle with a functional-based index, but that's another discussion)
A slight optimisation can be achieved by adding a predicate not using a function, at least on the outside of the sub-query (explanation inline), which gives the somewhat awkward query:
--- MS SQL Server
select t.*
from tbl_Employee_WorkRecords t
-- the work_start_dt needs to be higher than the max(work_start_dt) for this employee, -1 day
where t.work_start_dt >=
( SELECT DATEADD(DAY, -1, MAX(i.work_start_dt))
from tbl_Employee_WorkRecords i
where i.employee_pk = t.employee_pk
)
-- ensure the record(s) are on the same date, actually, and not on the previous day than MAX(work_start_dt)
AND convert(varchar(10), t.work_start_dt, 120) =
( SELECT convert(varchar(10), MAX(i.work_start_dt), 120)
from tbl_Employee_WorkRecords i
where i.employee_pk = t.employee_pk
)--- MySQL
select t.*
from tbl_Employee_WorkRecords t
-- the work_start_dt needs to be higher than the max(work_start_dt) for this employee, -1 day
where t.work_start_dt >=
( SELECT DATEADD(DAY, -1, MAX(i.work_start_dt))
from tbl_Employee_WorkRecords i
where i.employee_pk = t.employee_pk
)
-- ensure the record(s) are on the same date, actually, and not on the previous day than MAX(work_start_dt)
AND TO_DAYS(t.work_start_dt) =
( SELECT TO_DAYS(MAX(i.work_start_dt))
from tbl_Employee_WorkRecords i
where i.employee_pk = t.employee_pk
)--- Oracle
select t.*
from tbl_Employee_WorkRecords t
-- the work_start_dt needs to be higher than the max(work_start_dt) for this employee, -1 day
where t.work_start_dt >=
( SELECT TRUNC(MAX(i.work_start_dt))
from tbl_Employee_WorkRecords i
where i.employee_pk = t.employee_pk
)--- MS SQL Server
select t.*
from tbl_Employee_WorkRecords t
-- the work_start_dt needs to be higher than the max(work_start_dt) for this employee, -1 day
where t.work_start_dt >=
( SELECT CONVERT(DATETIME, CONVERT(VARCHAR(10), MAX(i.work_start_dt), 120), 120)
from tbl_Employee_WorkRecords i
where i.employee_pk = t.employee_pk
)But, we have even another bullet to solve this with SQL 2005+ and Oracle.
You have seen in Step 4 the ROW_NUMBER() function. We could use the RANK or DENSE_RANK function also, modifying the ORDER BY argument a little bit:
-- oracle
select sq.*
from ( SELECT t.*
, RANK () OVER ( PARTITION BY employee_pk ORDER BY TRUNC(work_start_dt) DESC ) rn
FROM tbl_Employee_WorkRecords t
) sq
WHERE sq.rn = 1For MS SQL Server, you need to use CONVERT(VARCHAR(10), work_start_dt, 120) instead of TRUNC(work_start_dt), obviously.
6. Result C
Now that we have seen Result B, for request C this should be easy, as option B returns already the records we need.In short, Result C is a variation of Result B, if you look closely at it.
7. Combine with master table
Once you found the correct rule to determine which row you want to take from the child table, you can take that query, and join to the master table. If the child table might return no records, it shall be a OUTER JOIN instead of INNER JOIN.So, here a sample in Oracle:
-- oracle
select sq.*, e.Name
from ( SELECT t.*
, ROW_NUMBER() OVER ( PARTITION BY employee_pk ORDER BY work_start_dt DESC ) rn
FROM tbl_Employee_WorkRecords t
) sq
join tbl_Employee e
ON e.pk = sq.employee_fk
WHERE sq.rn = 1For performance reasons, for example if the master table has a condition, you might want to join in the subquery directly, giving below code. The example returns all employees with lastname starting with 'B'.
Watch closely the condition sq.rn = 1 has to be part of the left join condition, and NOT of the where condition! If that condition was moved into the where, you make the query behave like a inner join.
-- oracle
select sq.*, e.Name
from tbl_Employee e
left join ( SELECT t.*
, ROW_NUMBER() OVER ( PARTITION BY t.employee_pk ORDER BY t.work_start_dt DESC ) rn
FROM tbl_Employee e
JOIN tbl_Employee_WorkRecords t
ON e.pk = sq.employee_fk
WHERE e.last_name like 'B%'
) sq
ON e.pk = sq.employee_fk
AND sq.rn = 1
WHERE e.last_name like 'B%'8. Conclusion
Once you clearly identified the needs for the output data, in regards to the input, the SQL can be written with above templates easily, just a matter of practice. Usually, you don't use DISTINCT or GROUP BY for these scenarios, either.I added a link about UNION vs. UNION ALL, because UNION used alone implicitly performs a DISTINCT, something that most newcomers in SQL just don't know... and wonder about the query running slowly.
Happy coding!
Analytical functions:
https://www.experts-exchange.com/articles/Database/Miscellaneous/Analytical-SQL-Where-do-you-rank.html
DISTINCTROW <> DISTINCT
MS Access : http://office.microsoft.com/en-us/access/HP010322051033.aspx
UNION vs. UNION ALL
SQL server : http://blog.sqlauthority.com/2009/03/11/sql-server-difference-between-union-vs-union-all-optimal-performance-comparison/
Oracle : http://www.oraclebrains.com/2007/09/sql-tipsuse-union-all-instead-of-union/
MySQL : http://www.mysqlperformanceblog.com/2007/10/05/union-vs-union-all-performance/
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (9)
Commented:
Author
Commented:Here the example for N = 1:
Open in new window
Here, the "JOIN condition" is done inside the CROSS APPLY, and instead of using ROW_NUMBER() function, we use the TOP x ... ORDER BY syntax, which will eventually be more readable/understandable for most people.Commented:
btw: there's a broken link to the dates/times article
Author
Commented:it's been fixed!
Commented:
View More