AFGPHXExcel
asked on
Is there a formula to find the last used row in a column
I am trying to avoid using VBA, so I would like to use a formula to identify the last used row in column. I've tried searching and I keep getting VBA code. Any options out there?
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
The same formula structure can be used on multiple columns:
=MAX(IF(ISBLANK(A1:Z10000)
also an array formula.
Kevin
=MAX(IF(ISBLANK(A1:Z10000)
also an array formula.
Kevin
If the formula is outside the evaluation range (such as on another worksheet) then you can check the whole row (but not the whole column):
=MAX(IF(ISBLANK(1:10000),"
Kevin
=MAX(IF(ISBLANK(1:10000),"
Kevin
>That kinda doesn't work because array formulas don't work as expected with full columns and rows.
That should have been:
That kinda doesn't work because array formulas don't work as expected with full columns.
Array formulas do work with full rows - at least in this case.
Kevin
That should have been:
That kinda doesn't work because array formulas don't work as expected with full columns.
Array formulas do work with full rows - at least in this case.
Kevin
You can do this without array formulas, and thus probably faster.
1) If you expect your "last" row to be numeric or a date:
=MATCH(10^200,A:A)
2) If you expect your "last" row to be text:
=MATCH("ZZZZZZZZZZ",A:A)
3) If your column has both numeric and text values, either of these work:
=MAX(MATCH("ZZZZZZZZZ",A:A
=MAX(MATCH({"ZZZZZZZZZ",1E
(That second one is not an array formula, but it does use an array constant.)
If you go with this, but there is a possibility that you will not have at least one number/date AND at least one string, modify to:
=MAX(IFERROR(MATCH("ZZZZZZ
Note that any of the string-enabled formulas here will "count" a cell that has a formula that evaluates to a zero-length string.
1) If you expect your "last" row to be numeric or a date:
=MATCH(10^200,A:A)
2) If you expect your "last" row to be text:
=MATCH("ZZZZZZZZZZ",A:A)
3) If your column has both numeric and text values, either of these work:
=MAX(MATCH("ZZZZZZZZZ",A:A
=MAX(MATCH({"ZZZZZZZZZ",1E
(That second one is not an array formula, but it does use an array constant.)
If you go with this, but there is a possibility that you will not have at least one number/date AND at least one string, modify to:
=MAX(IFERROR(MATCH("ZZZZZZ
Note that any of the string-enabled formulas here will "count" a cell that has a formula that evaluates to a zero-length string.
Hi Kevin,
I did test the function. It's painfully slow, but it does work exactly as written, in Excel 2007. What do you mean by “array formulas don't work as expected with full columns”?
(°v°)
I did test the function. It's painfully slow, but it does work exactly as written, in Excel 2007. What do you mean by “array formulas don't work as expected with full columns”?
(°v°)
Sorry Markus!
They don't work as expected in Excel 2003 and earlier. Microsoft fixed this in 2007 and later.
So your formula WILL work in this case. I retract my earlier comment.
Kevin
They don't work as expected in Excel 2003 and earlier. Microsoft fixed this in 2007 and later.
So your formula WILL work in this case. I retract my earlier comment.
Kevin
Ah, OK. I didn't know about the limitations up to version 2003. — (^v°)
A note on "fast": If this formula will only be used in one cell (highly recommended) then speed should not be an issue unless you do something wild and crazy like:
=MAX(IF(ISBLANK(1:1000000)
The cost of evaluating a reasonably complex and large array formula once and then referencing the result instead of copying the same complex array formula a million times really doesn't hurt performance unless you are still working on an 8086 PC with a few K of memory. But then Excel 2007 would probably not be running anyway.
For example, if your table is in columns A:H and will not exceed a few 1,000 rows, then a formula such as:
=MAX(IF(ISBLANK(A1:H2000),
will not change your calculation time by any perceptible amount.
Kevin
=MAX(IF(ISBLANK(1:1000000)
The cost of evaluating a reasonably complex and large array formula once and then referencing the result instead of copying the same complex array formula a million times really doesn't hurt performance unless you are still working on an 8086 PC with a few K of memory. But then Excel 2007 would probably not be running anyway.
For example, if your table is in columns A:H and will not exceed a few 1,000 rows, then a formula such as:
=MAX(IF(ISBLANK(A1:H2000),
will not change your calculation time by any perceptible amount.
Kevin
Bloody hell, all of my formulas are based on finding the last row used in a column. Re-writing to find last column used in a row...
You can do this without array formulas, and thus probably faster.
1) If you expect your "last" row to be numeric or a date:
=MATCH(10^200,1:1)
2) If you expect your "last" row to be text:
=MATCH("ZZZZZZZZZZ",1:1)
3) If your column has both numeric and text values, either of these work:
=MAX(MATCH("ZZZZZZZZZ",1:1
=MAX(MATCH({"ZZZZZZZZZ",1E
(That second one is not an array formula, but it does use an array constant.)
If you go with this, but there is a possibility that you will not have at least one number/date AND at least one string, modify to:
=MAX(IFERROR(MATCH("ZZZZZZ
Note that any of the string-enabled formulas here will "count" a cell that has a formula that evaluates to a zero-length string.
You can do this without array formulas, and thus probably faster.
1) If you expect your "last" row to be numeric or a date:
=MATCH(10^200,1:1)
2) If you expect your "last" row to be text:
=MATCH("ZZZZZZZZZZ",1:1)
3) If your column has both numeric and text values, either of these work:
=MAX(MATCH("ZZZZZZZZZ",1:1
=MAX(MATCH({"ZZZZZZZZZ",1E
(That second one is not an array formula, but it does use an array constant.)
If you go with this, but there is a possibility that you will not have at least one number/date AND at least one string, modify to:
=MAX(IFERROR(MATCH("ZZZZZZ
Note that any of the string-enabled formulas here will "count" a cell that has a formula that evaluates to a zero-length string.
Yo, dude, you had it right the first time:
"Is there a formula to find the last used row in a column"
Kevin
"Is there a formula to find the last used row in a column"
Kevin
Not enough coffee, apparently :)
@ matthewspatrick,
If you are working with non-English version this formula might not give you the correct result.
=MATCH("ZZZZZZZZZZ",A:A)
try with a slight variation
=MATCH(rept(char(255),25),
http://www.excelfox.com/forum/showthread.php?91-Last-Filled-Cell-Having-Text
If you are working with non-English version this formula might not give you the correct result.
=MATCH("ZZZZZZZZZZ",A:A)
try with a slight variation
=MATCH(rept(char(255),25),
http://www.excelfox.com/forum/showthread.php?91-Last-Filled-Cell-Having-Text
Nice.
krishnakrkc,
Well played, sir :)
Patrick
Well played, sir :)
Patrick
krishnakrkc,
With all due respect, this advice is totally bogus. ANSI (and Unicode) character 255 is “ÿ”, which Excel sorts before the “Z”. If you want to go that route, please run the following in a blank sheet:
Notice also that only very few Latin characters are sorted after “z”: some obsolete phonetic characters and some very rare variations such as the letters “v” and “w” with a right hook. For all applications using the Latin alphabet, “Z” is perfect.
The third column is what you can obtain with Excel functions, since the antiquated CHAR() is the only option, corresponding to the old BASIC Chr() function. The newer (yet over ten years old) ChrW() function has yet to be implemented as a worksheet function.
Mr. ExcelFox might know a thing or two about Excel, but has yet to learn the basics of character encoding, collation order, and Unicode support in Microsoft products...
Cheers!
(°v°)
With all due respect, this advice is totally bogus. ANSI (and Unicode) character 255 is “ÿ”, which Excel sorts before the “Z”. If you want to go that route, please run the following in a blank sheet:
Sub Unicode()
Dim lngCP As Long
Dim Unicode(2 ^ 16 - 1, 3)
For lngCP = 0 To 2 ^ 16 - 1
Unicode(lngCP, 0) = lngCP
Unicode(lngCP, 1) = ChrW(lngCP)
If lngCP < 256 Then Unicode(lngCP, 2) = Chr(lngCP)
Next lngCP
Range("A1").Resize(2 ^ 16, 3) = Unicode ' WorksheetFunction.Transpose(Unicode)
End SubNotice also that only very few Latin characters are sorted after “z”: some obsolete phonetic characters and some very rare variations such as the letters “v” and “w” with a right hook. For all applications using the Latin alphabet, “Z” is perfect.
The third column is what you can obtain with Excel functions, since the antiquated CHAR() is the only option, corresponding to the old BASIC Chr() function. The newer (yet over ten years old) ChrW() function has yet to be implemented as a worksheet function.
Mr. ExcelFox might know a thing or two about Excel, but has yet to learn the basics of character encoding, collation order, and Unicode support in Microsoft products...
Cheers!
(°v°)
Owl Man strikes again!
And I was so excited about having learned something new today. Now I have to use my Men-In-Black memory zapper.
And I was so excited about having learned something new today. Now I have to use my Men-In-Black memory zapper.
He'll still be stinging from that in a few days, I reckon :)
Yep, confirmed. Looks like the lowest character is a lower case z with a little ditty over it (I'm an American and have no idea what the little ditty is called - I DO know where France is though).
The formula then becomes:
=MATCH(REPT(CHAR(158),99),
I changed the 25 to 99 just to be sure.
Now someone will tell me that different locals use different ASCII character sets and then I'll say "OK, fine, the solution is for Western character sets only."
Kevin
The formula then becomes:
=MATCH(REPT(CHAR(158),99),
I changed the 25 to 99 just to be sure.
Now someone will tell me that different locals use different ASCII character sets and then I'll say "OK, fine, the solution is for Western character sets only."
Kevin
Looks like I'm late ......but for any type of data try this array formula
=MATCH(2,1/(A:A<>""))
confirmed with CTRL+SHIFT+ENTER
or to avoid CSE
=MATCH(2,INDEX(1/(A:A<>"")
regards, barry
=MATCH(2,1/(A:A<>""))
confirmed with CTRL+SHIFT+ENTER
or to avoid CSE
=MATCH(2,INDEX(1/(A:A<>"")
regards, barry
Dude, when you have to look at something for a minute to figure it out and your head hurts, it doesn't count.
Yowzers. My head hurts, and I still don't understand it :)
You're an Access boy. You're excused.
Note for readers: Barry's formulas won't work in 2003 or earlier unless the ranges are less than a full column.
Kevin
Note for readers: Barry's formulas won't work in 2003 or earlier unless the ranges are less than a full column.
Kevin
Hey, has anyone seen AFGPHXExcel?
Kevin: character ANSI 158 (or U+017E), aka Latin small letter z with caron, doesn't perform any differently from plain old letter z without caron (technically, they have the same collation order). Forget about REPT(CHAR(158),99) and keep on using the more readable string of Zs.
Barry: I tried your extraordinary expression, but found it is just as slow as my feeble attempt, even the version that doesn't need to be entered as an array function. In terms of usability, I'd go with Patrick's http:#36203231
Why isn't there a worksheet function to return the sheet's used range? or a range trimmed to the the used range?
(°v°)
Barry: I tried your extraordinary expression, but found it is just as slow as my feeble attempt, even the version that doesn't need to be entered as an array function. In terms of usability, I'd go with Patrick's http:#36203231
Why isn't there a worksheet function to return the sheet's used range? or a range trimmed to the the used range?
(°v°)
Well, well, well. Actually, I can make a string of Z's fail although it's pretty improbable.
It isn't true that they have the same collation order. The order is specific: z/Z and then the caron z/Z.
Also, MATCH does stop when it gets a match OR finds a value that is "smaller". A match is specific and WILL generate unexpected results if you make the assumptions you did.
You are right about the performance issue with Barry's formula because it has to create an intermediate array of a million elements.
I'll stick with MATCH(REPT(CHAR(158),99),A
And for numeric columns I like:
MATCH(2^1023,A:A)
Can't break that one either.
Kevin
It isn't true that they have the same collation order. The order is specific: z/Z and then the caron z/Z.
Also, MATCH does stop when it gets a match OR finds a value that is "smaller". A match is specific and WILL generate unexpected results if you make the assumptions you did.
You are right about the performance issue with Barry's formula because it has to create an intermediate array of a million elements.
I'll stick with MATCH(REPT(CHAR(158),99),A
And for numeric columns I like:
MATCH(2^1023,A:A)
Can't break that one either.
Kevin
>Can't break that one either
Hey Kevin, you're not trying then.......surely you can enter a number greater than 2^1023? For example 9E+307 :)
regards, barry
Hey Kevin, you're not trying then.......surely you can enter a number greater than 2^1023? For example 9E+307 :)
regards, barry
I don't use numbers that big. Neither does Mr. Sagan. Although the US debt is getting up there.
I can also enter 101 Z's or whatever the hell I ended up using - some caron thingy - and break the alpha version too.
I can also enter 101 Z's or whatever the hell I ended up using - some caron thingy - and break the alpha version too.
Kevin: more on the z caron saga...
Please run these from the immediate pane (it will be more readable than using CHAR())
This has turned into quite a technical excursion...
(°v°)
Please run these from the immediate pane (it will be more readable than using CHAR())
[A1] = "= ""z""=""" & Chr(158) & """"
[A2] = "= ""z""<""" & Chr(158) & """"
[A3] = "= ""zz""<""" & Chr(158) & """"
[A4] = "= MATCH(""zz"",{""" & Chr(158) & """})"
[B1] = "= ""a""=""b"""
[B2] = "= ""a""<""b"""
[B3] = "= ""aa""<""b"""
[B4] = "= MATCH(""aa"",{""b""})"
[C1] = "= ""a""=""à"""
[C2] = "= ""a""<""à"""
[C3] = "= ""aa""<""à"""
[C4] = "= MATCH(""aa"",{""à""})"[F1] = "z"
[F2] = "za"
[F3] = "zb"
[F4] = "zc"
[F5] = Chr(158)
[F6] = Chr(158) & "a"
[F7] = Chr(158) & "b"
[F8] = Chr(158) & "c"This has turned into quite a technical excursion...
(°v°)
One of my friends was working with a Estonian project where we noticed this problem.
The formula MATCH("zzzzzz",A:A) was not able to give the last row and eventually we come up with MATCH(rept(char(255),25),a
@ Kevin, I replaced the MATCH(rept(char(255),25),a
krishnakrkc,
After some research, this makes much more sense.
I'm not totally sure what CHAR(255) returns using the Windows-1257 (Windows Baltic) code page. It's quite probably the “ÿ” and not the “dot above” (U+02D9); it would be quite strange if CHAR was code-page dependant. I will assume it is the “ÿ”, which sorts before Z in many languages.
However, the Estonian alphabet doesn't end with the letter Z. It ends with Y... So you should indeed use MATCH(REPT("y",...),...) instead of MATCH(REPT("z",...),...) when Estonian language support is enabled.
In other words, it's by sheer luck that the character 255 works for Estonian, and not because it's the highest number for a eight-bit code page; I don't know if there are other alphabets where Y is the last letter...
Cheers!
(°v°)
After some research, this makes much more sense.
I'm not totally sure what CHAR(255) returns using the Windows-1257 (Windows Baltic) code page. It's quite probably the “ÿ” and not the “dot above” (U+02D9); it would be quite strange if CHAR was code-page dependant. I will assume it is the “ÿ”, which sorts before Z in many languages.
However, the Estonian alphabet doesn't end with the letter Z. It ends with Y... So you should indeed use MATCH(REPT("y",...),...) instead of MATCH(REPT("z",...),...) when Estonian language support is enabled.
In other words, it's by sheer luck that the character 255 works for Estonian, and not because it's the highest number for a eight-bit code page; I don't know if there are other alphabets where Y is the last letter...
Cheers!
(°v°)
Note: in Access, I recommend using ChrW(446) as a relatively safe character sorting after the the letters in the alphabet. It works in Excel with Western settings; perhaps this works also for Estonian? That way, the worksheet would work regardless of the language settings. Try:
[H1] = "= MATCH(""" & ChrW(446) & """,A:A)"
I don't think that REPT is needed. The glyph is an obsolete phonetic symbol, which isn't likely to be found in any actual data anywhere.
(°v°)
[H1] = "= MATCH(""" & ChrW(446) & """,A:A)"
(°v°)
>The caron adds something to the sort order, but only when all other characters in the string match. Their small difference is swamped by the stronger-level difference in the full string.
They do sort together but in the same way that A relates to B. Only two characters of different case seem to have the same collating sequence and are not sorted in any particular order relative to each other.
As with any sort algorithm, the difference between A and B is the same as with AA and AB. I'm not sure it's a swamping, but it does have significance. The bottom line - two characters (or strings of characters) either have the same collating value or they don't. If they don't then their order is predictable. If their order is predictable then the MATCH function will notice and act accordingly.
>I replaced the MATCH(rept(char(255),25),a
"OK, fine, the solution is for Western character sets only." Want a localized solution? In a blank workbook enter =CHAR(ROW()) in cell A1 and copy the formula down to cell A255. Select column A, copy, paste values only, and sort. In any unused cell enter =CODE(A255) and you will have your highest character code in your locale's single byte collating sequence.
At the end of the day, locales and their different character sets and collating sequences make this discussion either moot or very complex.
At this point I'll revert to my first post above with the notion that anyone looking to find the last used row in a column or worksheet will (and should) only do it once in one cell and with one formula and probably with a reasonable number of rows so therefore performance is NOT an issue.
In other words, it depends on the context and, at this point, we have probably moved will beyond the context behind this question. And, having absolutely no feedback from the asker, we are barking up rather unusual and probably unnecessary trees and going down rat and rabbit holes with nothing more than a desire to prove something to ourselves versus solve what is very likely an extremely simple problem.
>Any options out there?
Oh yes. We have definitely answered THAT part of the question.
They do sort together but in the same way that A relates to B. Only two characters of different case seem to have the same collating sequence and are not sorted in any particular order relative to each other.
As with any sort algorithm, the difference between A and B is the same as with AA and AB. I'm not sure it's a swamping, but it does have significance. The bottom line - two characters (or strings of characters) either have the same collating value or they don't. If they don't then their order is predictable. If their order is predictable then the MATCH function will notice and act accordingly.
>I replaced the MATCH(rept(char(255),25),a
"OK, fine, the solution is for Western character sets only." Want a localized solution? In a blank workbook enter =CHAR(ROW()) in cell A1 and copy the formula down to cell A255. Select column A, copy, paste values only, and sort. In any unused cell enter =CODE(A255) and you will have your highest character code in your locale's single byte collating sequence.
At the end of the day, locales and their different character sets and collating sequences make this discussion either moot or very complex.
At this point I'll revert to my first post above with the notion that anyone looking to find the last used row in a column or worksheet will (and should) only do it once in one cell and with one formula and probably with a reasonable number of rows so therefore performance is NOT an issue.
In other words, it depends on the context and, at this point, we have probably moved will beyond the context behind this question. And, having absolutely no feedback from the asker, we are barking up rather unusual and probably unnecessary trees and going down rat and rabbit holes with nothing more than a desire to prove something to ourselves versus solve what is very likely an extremely simple problem.
>Any options out there?
Oh yes. We have definitely answered THAT part of the question.
You are right, let's close this up. But not on misconceptions! (*grin*)
1) Remember that collating order is based on entire strings, not on individual characters, hence “a < ab < b < ba” (the letters are predominant) but “y < ÿ < ya < ÿa” (the difference between y and ÿ is weaker than the character order).
2) When searching for a characters that sorts after “Z” (and after “Y” in Estonian), a good candidate is ChrW(446), an obsolete phonetic sign.
3) The character CHAR(255) is the “ÿ”; it is one of the highest characters in the collating order only for alphabets where “Y” is the last letter, like Estonian. In most cases, CHAR(255) isn't the highest character in a given collating order...
> a desire to prove something to ourselves
Guilty as charged!
(^v°)
1) Remember that collating order is based on entire strings, not on individual characters, hence “a < ab < b < ba” (the letters are predominant) but “y < ÿ < ya < ÿa” (the difference between y and ÿ is weaker than the character order).
2) When searching for a characters that sorts after “Z” (and after “Y” in Estonian), a good candidate is ChrW(446), an obsolete phonetic sign.
3) The character CHAR(255) is the “ÿ”; it is one of the highest characters in the collating order only for alphabets where “Y” is the last letter, like Estonian. In most cases, CHAR(255) isn't the highest character in a given collating order...
> a desire to prove something to ourselves
Guilty as charged!
(^v°)
Yes, a < ab because b is greater than the implied space following the a, and a is also less than aa - this was never in question. Varying degrees of strength or weakness means varying degrees of difference, such as the vagueness used in expert system decision trees. The difference between y and ÿ is exactly the same as the difference between A and B. In both cases they both have different positions in the collating order. In both cases one sorts above or below the other. It's a binary result: is the one character greater than or less than the other. There is no notion of an A is more less than a B than a y is less than a ÿ. They are either in different positions of the collating sequence or they are in the same position.
Well, Kevin, we are still not there yet.
Collating order is meant for entire strings, based on various rules on the individual characters. As such, B comes after A and after AB, quite logically. The difference between the initials A and B is strong. However à comes after A (alone) but before AB. The difference between any variant of A alone and a variant of A followed by a B is stronger than the difference between A and Ã. In other words à comes after A only when there is no stronger rule to suggest otherwise.
Please copy those in a column, they are sorted in the way you are expecting they should be. Ask Excel to sort, and you will see what I mean. The primary sort order is unaccented (A and à have the same weight), and only strings that are otherwise equal are sorted among themselves based on accentuation.
I hope this will convince you.
(°v°)
Collating order is meant for entire strings, based on various rules on the individual characters. As such, B comes after A and after AB, quite logically. The difference between the initials A and B is strong. However à comes after A (alone) but before AB. The difference between any variant of A alone and a variant of A followed by a B is stronger than the difference between A and Ã. In other words à comes after A only when there is no stronger rule to suggest otherwise.
Please copy those in a column, they are sorted in the way you are expecting they should be. Ask Excel to sort, and you will see what I mean. The primary sort order is unaccented (A and à have the same weight), and only strings that are otherwise equal are sorted among themselves based on accentuation.
A
AA
AÃ
AB
Ã
ÃA
ÃÃ
ÃB
B
BA
BÃ
BBI hope this will convince you.
(°v°)
What you are describing is the result of a technique Windows uses to collate. It's more common use is to handle single apostrophes, dashes, and other marks that define the language but have a secondary priority in the collating sequence. For example, to place Car's in the right place:
Carp
Cars
Car's
Cart
the apostrophe is removed, the strings compared, and, if the strings a different the collating sequence is established. If the same, the apostrophe is used to establish the sequence (although it has a higher collating position than when alone which leads one to think there is even more going on behind the scenes.)
The same basic process occurs for accented characters. The comparison is made by first translating all the characters to their equivalent base character (Ã -> A) and the comparison made. If different then the collating order is established. If the same then the accented characters are used to establish the sequence.
So, yes, there is a tighter relationship of accented characters to their un-accented equivalents and I now concede that it is a stronger relationship.
All in all it has nothing to do with this question or how the MATCH function looks at a sorted list. A string is either equal or it isn't. And if they are different then one will be greater than the other for collating purposes. And, no matter how you slice it, a string of caron y's is going to always go to the bottom of any list, and the longer the better - just in case.
Carp
Cars
Car's
Cart
the apostrophe is removed, the strings compared, and, if the strings a different the collating sequence is established. If the same, the apostrophe is used to establish the sequence (although it has a higher collating position than when alone which leads one to think there is even more going on behind the scenes.)
The same basic process occurs for accented characters. The comparison is made by first translating all the characters to their equivalent base character (Ã -> A) and the comparison made. If different then the collating order is established. If the same then the accented characters are used to establish the sequence.
So, yes, there is a tighter relationship of accented characters to their un-accented equivalents and I now concede that it is a stronger relationship.
All in all it has nothing to do with this question or how the MATCH function looks at a sorted list. A string is either equal or it isn't. And if they are different then one will be greater than the other for collating purposes. And, no matter how you slice it, a string of caron y's is going to always go to the bottom of any list, and the longer the better - just in case.
The base character Y sorts last in Estonian, but sorts before Z in our alphabets. The following returns 5 on my computer, and probably 6 with Estonian settings:
=MATCH("ÿÿÿ",{"a","b","c",
Conversely, the following returns 6, and probably 4 in Estonian:
=MATCH("zzz",{"a","b","c",
I was suggesting to replace the “last letter of the alphabet” (be it Z or Y) in the match function with a glyph that is sorted after the last letter. In Access, ChrW(446) or U+01BE works fine.
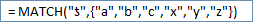 This was my suggestion in http:#36205681
This was my suggestion in http:#36205681
Cheers!
(°v°)
=MATCH("ÿÿÿ",{"a","b","c",
=MATCH("zzz",{"a","b","c",
This was my suggestion in http:#36205681Cheers!
(°v°)
I wonder what this will spit out in various locales:
Dim Char As Long
Dim HighChar As Long
For Char = 0 To 255
If StrComp(Chr(Char), Chr(HighChar), vbTextCompare) > -1 Then HighChar = Char
Next Char
MsgBox "The highest collating single byte ASCII character in the current locale is CHAR(" & HighChar & ")"
Kevin
Dim Char As Long
Dim HighChar As Long
For Char = 0 To 255
If StrComp(Chr(Char), Chr(HighChar), vbTextCompare) > -1 Then HighChar = Char
Next Char
MsgBox "The highest collating single byte ASCII character in the current locale is CHAR(" & HighChar & ")"
Kevin
Interesting!
I wasn't able to influence StrComp with vbTextCompare by any simple method, but in Access, the function has the additional vbDatabaseCompare option. Using that, and testing various Latin-based sort orders available (it's a global database setting), I found:
General, French, German, etc: 142 (Ž) and 158 (ž)
Estonian: 159 (Ÿ) and 255 (ÿ)
Islandic: 216 (Ø) and 248 (ø)
Norvegian/Danish: 197 (Å) and 229(å)
Your test function returns the lower-case character, a TOP 1 query in Access returns both, because they are equal under the default case insensitive sort order.
Note also that I didn't change the Windows code page, and I don't know exactly how Chr() (or Excel's CHAR()) behaves with different code pages loaded. In other words, I examined the ANSI character table using different collating rules, without any possible missing characters for the languages. In reality, the collating order is defined on the Unicode table.
The same test, but including basic Latin, Latin-1, Latin-A, and Latin-B, reveals the surprising ChrW(446), which is always after the last letter of the alphabet, whichever that is. In other words, the following:
The funny thing is that it's quite probably an accident. Anyway, it's the best upper bound for an alphabetical list I was able to find. I suggest using that instead of Z in Accent Insensitive Search in Access. Come to think of it, I should mention Estonian as an example in that article!
(°v°)
PS: I wrote an addendum as comment, so I don't forget about it.
I wasn't able to influence StrComp with vbTextCompare by any simple method, but in Access, the function has the additional vbDatabaseCompare option. Using that, and testing various Latin-based sort orders available (it's a global database setting), I found:
General, French, German, etc: 142 (Ž) and 158 (ž)
Estonian: 159 (Ÿ) and 255 (ÿ)
Islandic: 216 (Ø) and 248 (ø)
Norvegian/Danish: 197 (Å) and 229(å)
Note also that I didn't change the Windows code page, and I don't know exactly how Chr() (or Excel's CHAR()) behaves with different code pages loaded. In other words, I examined the ANSI character table using different collating rules, without any possible missing characters for the languages. In reality, the collating order is defined on the Unicode table.
The same test, but including basic Latin, Latin-1, Latin-A, and Latin-B, reveals the surprising ChrW(446), which is always after the last letter of the alphabet, whichever that is. In other words, the following:
Dim Char As Long
Dim HighChar As Long
For Char = 0 To &H24F
If StrComp(ChrW(Char), ChrW(HighChar), vbDatabaseCompare) > -1 Then HighChar = Char
Next Char
MsgBox "The highest character in all Latin Unicode blocks is ChrW(" & HighChar & ")"The funny thing is that it's quite probably an accident. Anyway, it's the best upper bound for an alphabetical list I was able to find. I suggest using that instead of Z in Accent Insensitive Search in Access. Come to think of it, I should mention Estonian as an example in that article!
(°v°)
PS: I wrote an addendum as comment, so I don't forget about it.
=MAX(ROW(D:D)*NOT(ISBLANK(
(°v°)