

Browse All Articles > Eliminating duplicate data with Duplicate Master V2
Introduction - The Problem
Many people use or inherit spreadsheets built with database functionality. A frequent problem with such spreadsheets is duplicate data, either of entire records, or in specific fields. Duplicate data in your spreadsheet can cost your organization in many ways:
Not surprisingly, one of the most common requests in the online Excel forums is for solutions to handling the
Several years ago I created the Duplicate Master addin which packages VBA code to provide this additional functionality to Excel. This is an extension beyond Excel's in-built duplicate handling which is provided via Advanced Filtering, and now the "Remove Duplicates" in Excel 2007. The Duplicate Master Version 1.4 had been downloaded over 12,000 times at the time I decommissioned my web-site in May 2008.
Duplicate Master Excel add-in V2
In this Article I am now pleased to present Duplicate Master V2.0 - in beta form - which delivers additional functionality in 3 areas:
1) The string comparison options have been significantly beefed up
3) I have added an option to exclude any items from a unique list if they occur more than once
The latest xla file is
** Updated to V2.18 on 13 July 2011**
Duplicate-Master-V2.18.zip
Assumed Knowledge
This tutorial assumed that users are familiar with general downloading and installation of Excel add-ins.
Tutorial contents
This Article provides a brief overview of applying the string matching options to a basic two field data list where the aim is to highlight the entire row where both fields result in a duplicate match.
Four increasingly more specific matching options are covered:
1 Basic Match
2 Match applying using Excel's CLEAN & TRIM worksheet functions
3 Using Regular Expression matching on the first field
4 As per (3), but case insensitive over both fields
The simple Name - Surname list below has been used for this example.![list]() 1 Basic Match
1 Basic Match
This example runs a basic match over the cells in B2:C11 where the strings must be identical (by character case, and white space) to flag a row match. For these settings data sets 1 and 9 are identical and are highlighted as duplicate rows.
![1]() 2 Match applying the CLEAN & TRIM functions
2 Match applying the CLEAN & TRIM functions
In this example the Excel CLEAN & TRIM functions are used to remove non-printing characters and excess spaces. Data sets 1, 6, 9 and 10 are now flagged as duplicates. Please note that the "Ignore ALL white-space chars (ASCII 9-13, 32 & 160" String Option offers this combined option plus handling for the presence of character 160.
![2]() 3 Using Regular Expression matching on the first field
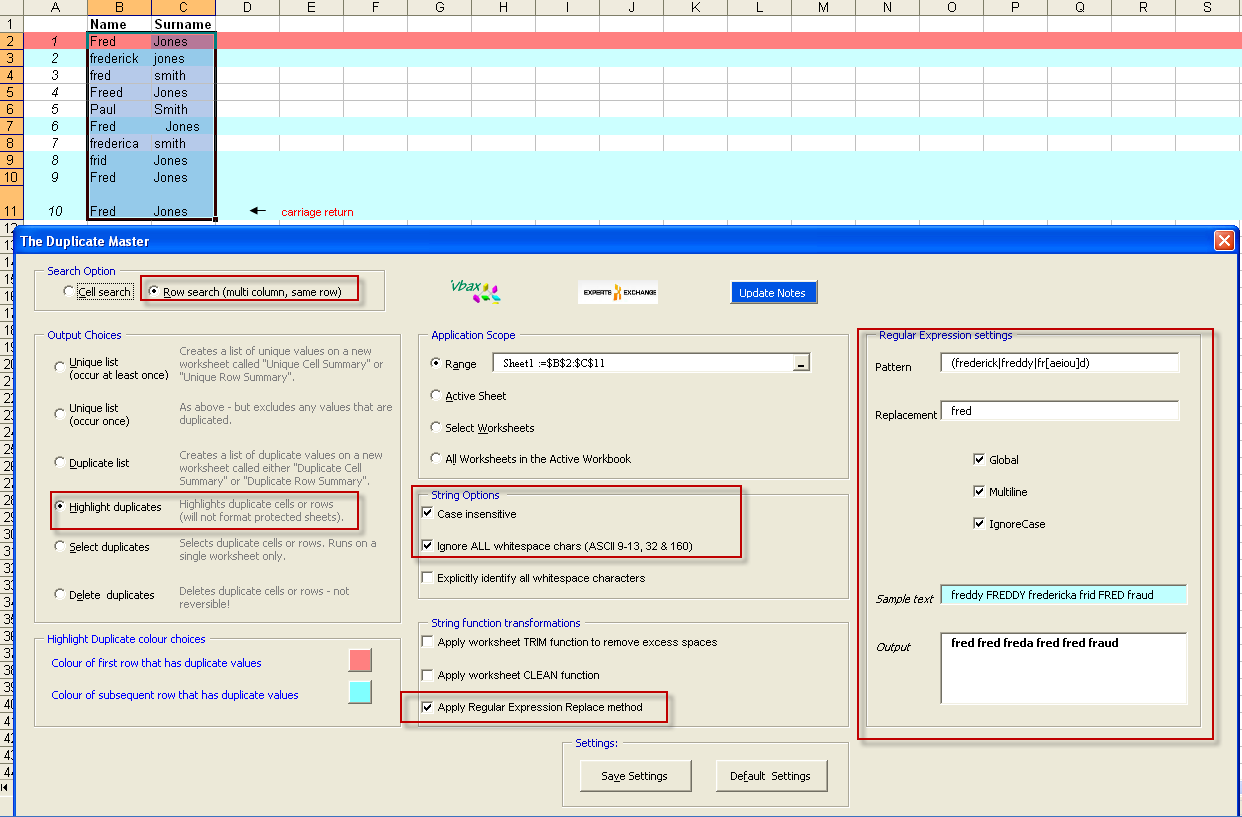
3 Using Regular Expression matching on the first field
I won't go into detail on Regular Expressions here, for those who want more background I suggest visiting the definitive VBA-RegExp resource by Patrick Matthews here.
In this case we would like to match the Name column if
Any other variants will not convert purely into Fred (NB: i.e., Fredericka becomes would become Freda in this example, so this would match other Freda fields. If you want to avoid these matches then use a string such as "||xyz||" for the replacement text)
Running this RegExp option - in combination with "Ignore ALL white-space chars (ASCII 9-13, 32 & 160" results in rows 1, 6, 8, 9 and 10 matching
![3]() 4 As per (3), but case insensitive over both fields
4 As per (3), but case insensitive over both fields
The regular expression options above were designed to cater for variations of "Fred" only (in either the Name or Surname) fields). The RegExp IgnoreCase setting applies only to strings where there is a valid RegExp match. If we use the same settings as per step 3, but now use the String Option Case Insensitive then row 2 is added as an additional match.
![4]()
Hopefully this tutorial has been useful in identifying the string matching capabilities of the upgraded addin.
Some readers may have already appreciated the versatility that applying RegExp matches provides. For example, pattern matching for numbers would allow a user to remove all rows in an entire workbook where numbers are contained in any or specific fields.
As always I would appreciate feedback and comments, especially as I would like to move this version from beta to final and make the addin generally available over the web for download.
Regards
Dave (brettdj)
Many people use or inherit spreadsheets built with database functionality. A frequent problem with such spreadsheets is duplicate data, either of entire records, or in specific fields. Duplicate data in your spreadsheet can cost your organization in many ways:
incorrect financial calculations,
incorrect statistics,
increased mailing costs,
wasted manpower due to CRM inaccuracies
Introduction - The Solution
Not surprisingly, one of the most common requests in the online Excel forums is for solutions to handling the
identification,
extraction,
highlighting,
or removal
of duplicate or unique lists, in either single or multi-column fields
Several years ago I created the Duplicate Master addin which packages VBA code to provide this additional functionality to Excel. This is an extension beyond Excel's in-built duplicate handling which is provided via Advanced Filtering, and now the "Remove Duplicates" in Excel 2007. The Duplicate Master Version 1.4 had been downloaded over 12,000 times at the time I decommissioned my web-site in May 2008.
Duplicate Master Excel add-in V2
In this Article I am now pleased to present Duplicate Master V2.0 - in beta form - which delivers additional functionality in 3 areas:
1) The string comparison options have been significantly beefed up
case insensitive searches,
ignore all white-space searches (ASCII 9-13,32,160),
apply the worksheet CLEAN and/or TRIM functions,
and for those who want some serious matching capability - Regular Expression functionality
2) The string handling code has been further optimised to improve code speed, especially on string concatenation
3) I have added an option to exclude any items from a unique list if they occur more than once
The latest xla file is
** Updated to V2.18 on 13 July 2011**
Duplicate-Master-V2.18.zip
Assumed Knowledge
This tutorial assumed that users are familiar with general downloading and installation of Excel add-ins.
Tutorial contents
This Article provides a brief overview of applying the string matching options to a basic two field data list where the aim is to highlight the entire row where both fields result in a duplicate match.
Four increasingly more specific matching options are covered:
1 Basic Match
2 Match applying using Excel's CLEAN & TRIM worksheet functions
3 Using Regular Expression matching on the first field
4 As per (3), but case insensitive over both fields
The simple Name - Surname list below has been used for this example.
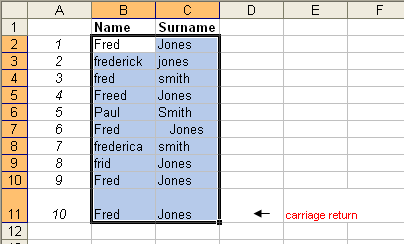 1 Basic Match
1 Basic Match
This example runs a basic match over the cells in B2:C11 where the strings must be identical (by character case, and white space) to flag a row match. For these settings data sets 1 and 9 are identical and are highlighted as duplicate rows.
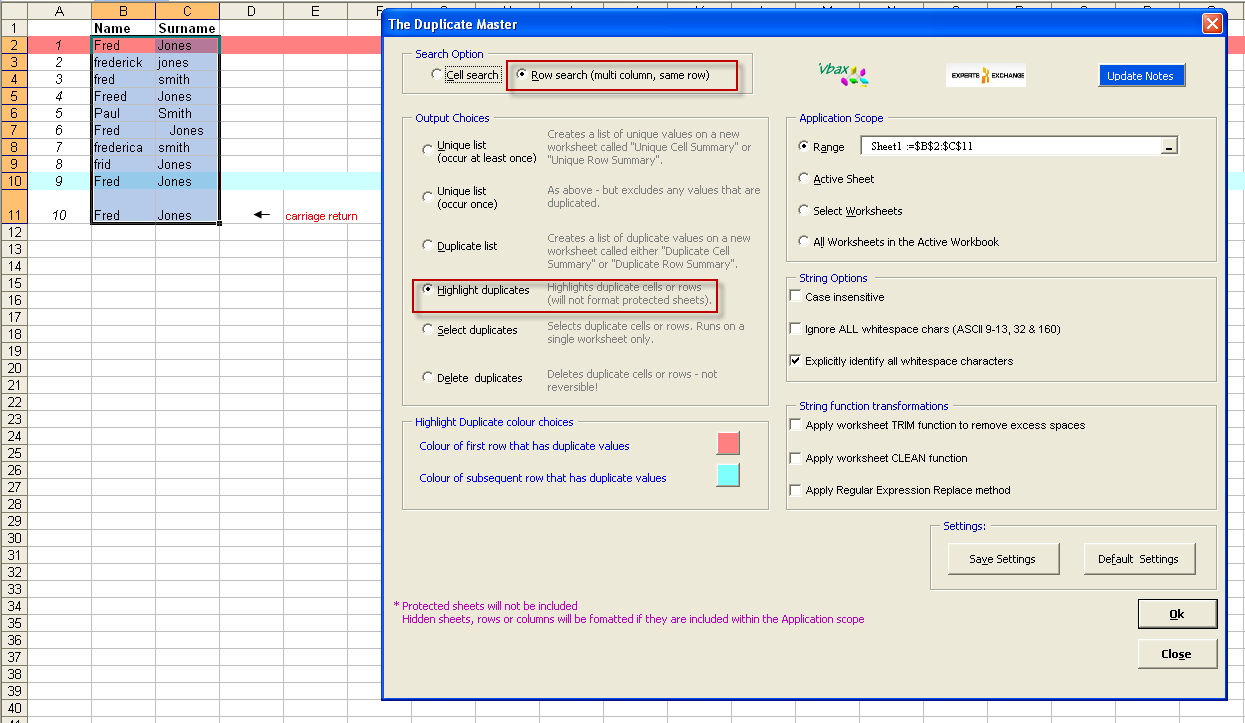 2 Match applying the CLEAN & TRIM functions
2 Match applying the CLEAN & TRIM functions
In this example the Excel CLEAN & TRIM functions are used to remove non-printing characters and excess spaces. Data sets 1, 6, 9 and 10 are now flagged as duplicates. Please note that the "Ignore ALL white-space chars (ASCII 9-13, 32 & 160" String Option offers this combined option plus handling for the presence of character 160.
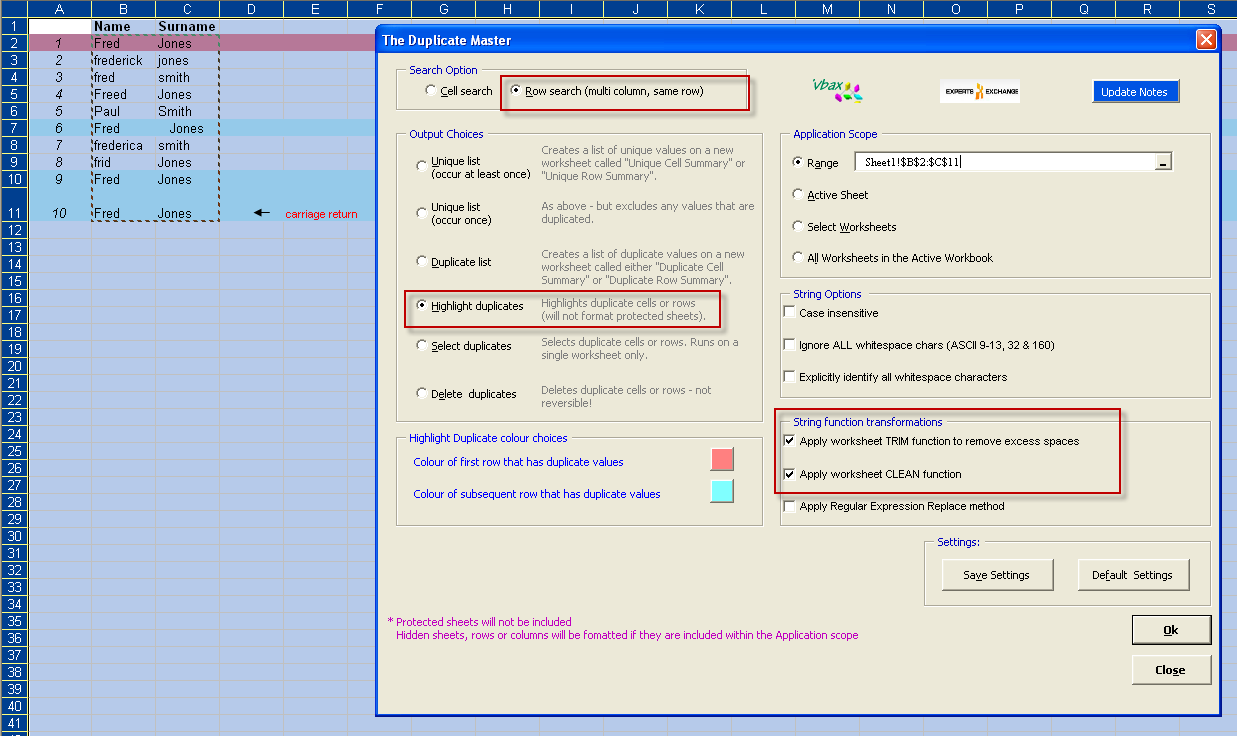 3 Using Regular Expression matching on the first field
3 Using Regular Expression matching on the first field
I won't go into detail on Regular Expressions here, for those who want more background I suggest visiting the definitive VBA-RegExp resource by Patrick Matthews here.
In this case we would like to match the Name column if
the name is Fred, Freddy or Frederick
for Fred spelt as Frad, Fred, Frid, Frod, Frud
The regular expression used will convert all of these versions into "Fred" - the Duplicate Master Replacement text option for data matching
Any other variants will not convert purely into Fred (NB: i.e., Fredericka becomes would become Freda in this example, so this would match other Freda fields. If you want to avoid these matches then use a string such as "||xyz||" for the replacement text)
Running this RegExp option - in combination with "Ignore ALL white-space chars (ASCII 9-13, 32 & 160" results in rows 1, 6, 8, 9 and 10 matching
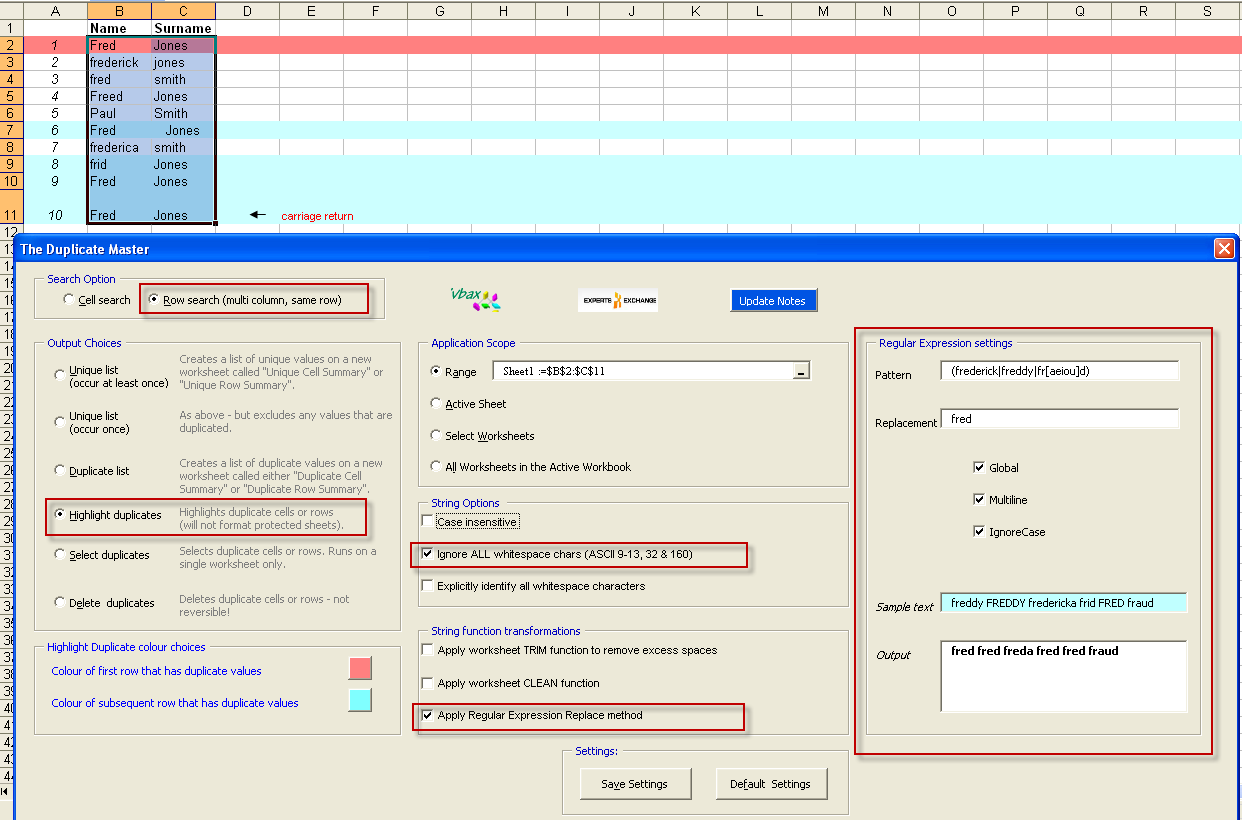 4 As per (3), but case insensitive over both fields
4 As per (3), but case insensitive over both fields
The regular expression options above were designed to cater for variations of "Fred" only (in either the Name or Surname) fields). The RegExp IgnoreCase setting applies only to strings where there is a valid RegExp match. If we use the same settings as per step 3, but now use the String Option Case Insensitive then row 2 is added as an additional match.
Hopefully this tutorial has been useful in identifying the string matching capabilities of the upgraded addin.
Some readers may have already appreciated the versatility that applying RegExp matches provides. For example, pattern matching for numbers would allow a user to remove all rows in an entire workbook where numbers are contained in any or specific fields.
As always I would appreciate feedback and comments, especially as I would like to move this version from beta to final and make the addin generally available over the web for download.
Regards
Dave (brettdj)
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (27)
Author
Commented:Are you able to send me a copy of the file?
Regards
Dave
Commented:
Have tried many times to upload file with no joy. Its only 24Mb so not sure why it wont upload. Perhaps as I am just community member?
Do you have FTP perhaps?
Commented:
File attached.
Book3.xlsx
Author
Commented:Open in new window
on the 500k rowsWhich is interesting as stepping through manually works - after a time lag of 5-10 seconds
I will keep looking at it
Cheers
Dave
Commented:
Very greatful for you looking into this.
I have been using TDM for years now and think your a genius!
My dedupes on similiar file type whilst always a tad slow under Excel 97/2003 format (ie 65K rows) always worked well. I always put that down to slow CPU speed.
I have only just started using TDM with Excel 2010 (1m+ rows) and wonder if that has anything to do with it. Anyway you would know that better than I.
Again greatful for any suggestions.
View More