How To Rename-Move a Batch of PDF Files Based on Contents of the Files


50+ years in computers
EE FELLOW 2017 — first ever recipient of Fellow award
MVE 2015,2016,2018
CERTIFIED GOLD EXPERT
DISTINGUISHED EXPERT
EE FELLOW 2017 — first ever recipient of Fellow award
MVE 2015,2016,2018
CERTIFIED GOLD EXPERT
DISTINGUISHED EXPERT
Published:
Edited by: Andrew Leniart
Browse All Articles > How To Rename-Move a Batch of PDF Files Based on Contents of the Files
Article Update 13-March-2020: I removed the full source code and the code snippets. The article that remains should act as a "design roadmap" for members who want to write the code in the programming language of your choice. If you are interested in discussing the program further, please contact me via the EE message system.
A recent question here at Experts Exchange piqued my interest, so I decided to provide a thorough solution and publish this Article about it. The Original Poster (OP) of the question has approximately one thousand PDF files containing 7-character sequential alphanumeric file names (and, of course, all of the file extensions are PDF). Although the OP did not state this, it is likely that the sequential alphanumerics represent unique identifiers for his customers, perhaps customer numbers. The alphanumeric file name is cryptic, in no way identifiable with the customer, so the OP would like the file name to contain the customer name in addition to the number. For example, a file might be named:
D123456.PDF
The OP would like this file to be renamed:
D123456 John Smith.PDF
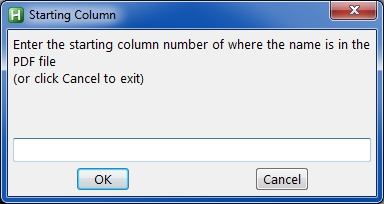
The customer name always begins in column 16 on the first line of the first page in the PDF file (and runs to the end of the line). The OP wants an automated way to rename the thousand PDF files, based on the customer name in the contents of each file – in essence, a batch/mass rename. The program documented in this Article (and provided in source code) performs this function.
Two excellent freeware products are needed for this solution – the AutoHotkey scripting language (the program is written in this) and the Xpdf package to convert the PDF files to text (so the program can extract the customer names for renaming the files). Here are the links for downloading both:
http://ahkscript.org (also, see my EE article: AutoHotkey - Getting Started)
http://www.foolabs.com/xpdf/download.html
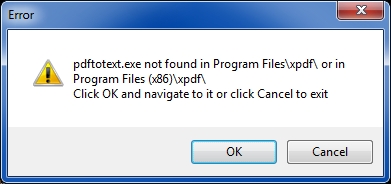
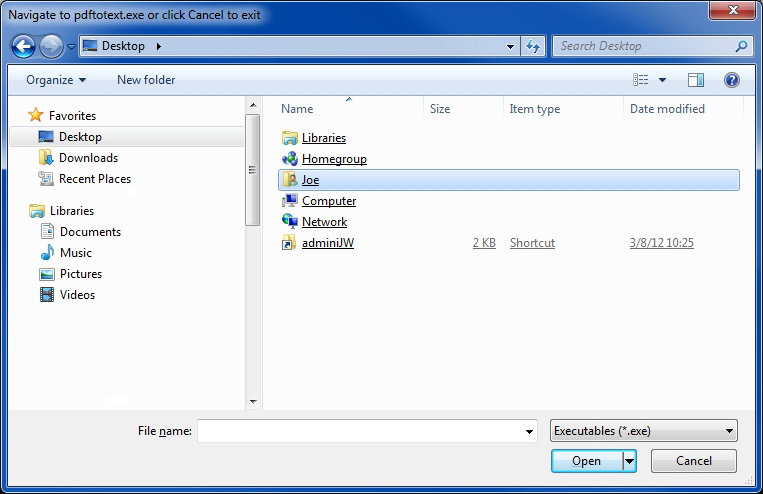
The Xpdf binaries (both 32-bit and 64-bit) contain seven tools, but the only one needed is pdftotext.exe. The script looks for this file in Program Files and Program Files (x86), but you may put pdftotext.exe wherever you want and simply navigate to it – the script gives you a file browse dialog if it doesn't find it in Program Files or Program Files (x86).
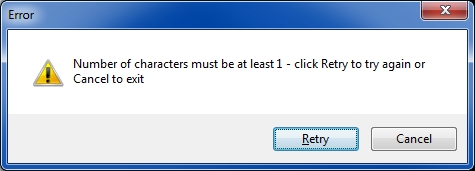
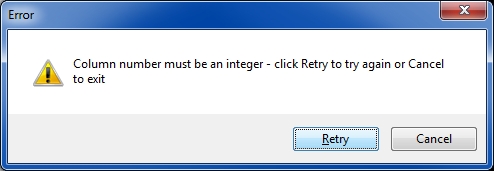
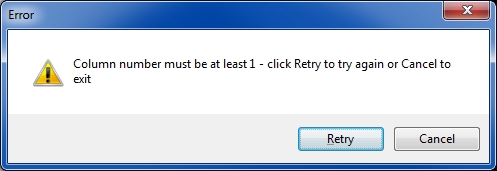
The program generalizes the solution by allowing any number of characters in the original file name (for the OP it is 7) and any starting column number for the string that will be in the new file name (for the OP it is 16). The latter is an area where significant generalization and/or customization can take place. For example, the string that will be in the new file name may be on some line other than the first; or the string may be in a variable column number preceded by a string that identifies it, such as Account Number:. By providing the source code, you may modify the program to parse the text extracted from the PDF files in order to create the new file names. If an EE member needs something different from a fixed column number on the first line of the first page (and you don't feel comfortable modifying the script), please post your requirement in a comment on this Article and (within reason) I'll modify the script for you and post it here.
For those interested in understanding how the script works, the remainder of this Article shows the entire script broken down into code snippets, with a description of what each snippet does, including screenshots where appropriate. This also acts as a form of documentation for the program.
Code snippet:
Code snippet:
 Code snippet:
Code snippet:
Code snippet:
Code snippet:

Code snippet:
Code snippet:
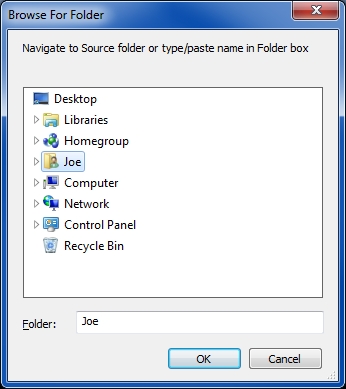
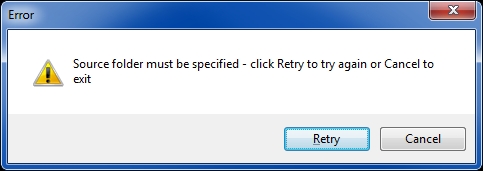
Code snippet:
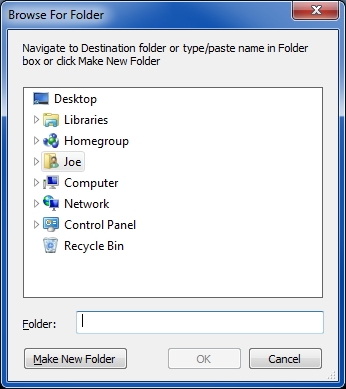
Code snippet:
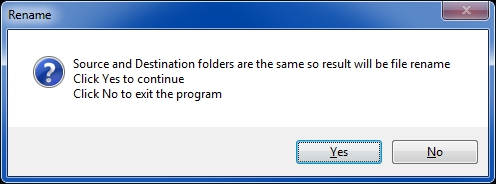
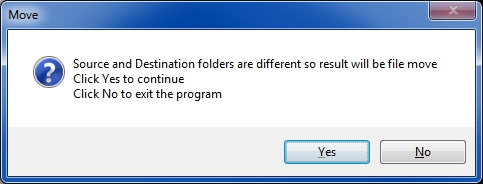
Code snippet:
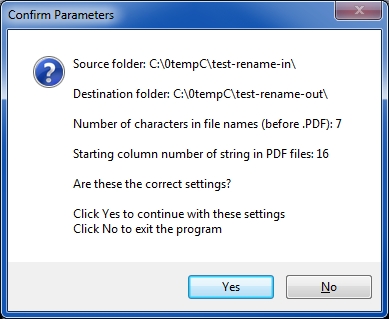
Code snippet:
Code snippet:

Code snippet:
Code snippet:
Code snippet:
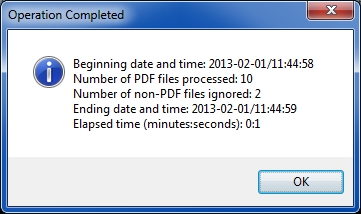
That's it! I hope this helps the OP as well as other EE members. If you find this article to be helpful, please click the thumbs-up icon below. This lets me know what is valuable for EE members and provides direction for future articles. Thanks very much! Regards, Joe
A recent question here at Experts Exchange piqued my interest, so I decided to provide a thorough solution and publish this Article about it. The Original Poster (OP) of the question has approximately one thousand PDF files containing 7-character sequential alphanumeric file names (and, of course, all of the file extensions are PDF). Although the OP did not state this, it is likely that the sequential alphanumerics represent unique identifiers for his customers, perhaps customer numbers. The alphanumeric file name is cryptic, in no way identifiable with the customer, so the OP would like the file name to contain the customer name in addition to the number. For example, a file might be named:
D123456.PDF
The OP would like this file to be renamed:
D123456 John Smith.PDF
The customer name always begins in column 16 on the first line of the first page in the PDF file (and runs to the end of the line). The OP wants an automated way to rename the thousand PDF files, based on the customer name in the contents of each file – in essence, a batch/mass rename. The program documented in this Article (and provided in source code) performs this function.
Two excellent freeware products are needed for this solution – the AutoHotkey scripting language (the program is written in this) and the Xpdf package to convert the PDF files to text (so the program can extract the customer names for renaming the files). Here are the links for downloading both:
http://ahkscript.org (also, see my EE article: AutoHotkey - Getting Started)
http://www.foolabs.com/xpdf/download.html
The Xpdf binaries (both 32-bit and 64-bit) contain seven tools, but the only one needed is pdftotext.exe. The script looks for this file in Program Files and Program Files (x86), but you may put pdftotext.exe wherever you want and simply navigate to it – the script gives you a file browse dialog if it doesn't find it in Program Files or Program Files (x86).
The program generalizes the solution by allowing any number of characters in the original file name (for the OP it is 7) and any starting column number for the string that will be in the new file name (for the OP it is 16). The latter is an area where significant generalization and/or customization can take place. For example, the string that will be in the new file name may be on some line other than the first; or the string may be in a variable column number preceded by a string that identifies it, such as Account Number:. By providing the source code, you may modify the program to parse the text extracted from the PDF files in order to create the new file names. If an EE member needs something different from a fixed column number on the first line of the first page (and you don't feel comfortable modifying the script), please post your requirement in a comment on this Article and (within reason) I'll modify the script for you and post it here.
For those interested in understanding how the script works, the remainder of this Article shows the entire script broken down into code snippets, with a description of what each snippet does, including screenshots where appropriate. This also acts as a form of documentation for the program.
Code snippet:
SetBatchLines, -1 ; run at maximum speedCode snippet:
removedremovedCode snippet:
removedCode snippet:
removedCode snippet:
removedCode snippet:
removedCode snippet:
removedCode snippet:
removedCode snippet:
removedCode snippet:
removedCode snippet:
removedCode snippet:
removedCode snippet:
removedCode snippet:
removedThat's it! I hope this helps the OP as well as other EE members. If you find this article to be helpful, please click the thumbs-up icon below. This lets me know what is valuable for EE members and provides direction for future articles. Thanks very much! Regards, Joe
50+ years in computers
EE FELLOW 2017 — first ever recipient of Fellow award
MVE 2015,2016,2018
CERTIFIED GOLD EXPERT
DISTINGUISHED EXPERT
EE FELLOW 2017 — first ever recipient of Fellow award
MVE 2015,2016,2018
CERTIFIED GOLD EXPERT
DISTINGUISHED EXPERT
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (63)
Commented:
Commented:
I have what I believe a application to rename multiple PDF files and would greatly appreciate receiving a copy of the AutoHotKey script.
Thank You
Author
Commented:Perhaps you missed my answer to your same question at my Split-Rename-Move article, so I'll repeat it here for you.
When I removed the source code last year from six articles that I published here at EE, my intention was that the removal be temporary. I began a project to rewrite all of the programs in my portfolio in order to generalize them for a broader audience and to have a standard user interface, including both a GUI (graphical user interface) and, where it makes sense, a CLI (command line interface). It wound up being a much larger effort than I anticipated, and I'm still not ready to post or distribute the source code for this program (or any of the other five published at EE — and I don't know when or even if that will be, for a variety of reasons).
I have created customized versions of these various programs for EE members who became clients of mine. I provided licenses for the run-time programs (the executables, i.e., the compiled EXE files) for an agreed-upon fee, but I did not provide the source code. I did this previously when EE had the "Hire Me" button, but that no longer exists. The mechanism now at EE for such work is the new Gigs feature, if that interests you.
Regards, Joe
Commented:
Thanks for your response.
I appreciate your comments & issues.
I would greatly appreciate it if you could see your way clear to send me your original AutoHotKey script.
I'm trying to learn more about AutoHotKey scripts and especially how it interfaces with Xpdf's pdftotext.exe
Thanks
Author
Commented:I received your email at my personal email address, which I'll respond to in a moment. I already responded to your post at the AHK forum, which led you to this article, and then to my Split-Rename-Move article. Instead of three different communication venues (EE, AHK, email), let's continue this discussion via just email.
That said, a quick message about your comments is that the Tutorials forum and the Scripts and Functions forum at the AHK boards are the way to go "to learn more about AutoHotKey scripts" (as well as the Tutorial at the AHK docs site).
There's not much to learn about "how it interfaces with Xpdf's pdftotext.exe" — the RunWait command is it. Here's an actual call from one of my programs:
Open in new window
I'm sure from the names of the variables you can figure out what that line does. Also, I gave you links at the AHK forum to my two 5-minute EE video Micro Tutorials that should help you with learning about how to use the pdftotext.exe tool:Xpdf - Command Line Utility for PDF Files
Xpdf - Convert PDF Files to Plain Text Files
If you haven't viewed them yet, I think you'll find them to be a worthwhile expenditure of 10 minutes. Regards, Joe
View More