How To Split-Rename-Move a Batch of PDF Files Based on Contents of the Files


50+ years in computers
EE FELLOW 2017 — first ever recipient of Fellow award
MVE 2015,2016,2018
CERTIFIED GOLD EXPERT
DISTINGUISHED EXPERT
EE FELLOW 2017 — first ever recipient of Fellow award
MVE 2015,2016,2018
CERTIFIED GOLD EXPERT
DISTINGUISHED EXPERT
Published:
Edited by: Andrew Leniart
Browse All Articles > How To Split-Rename-Move a Batch of PDF Files Based on Contents of the Files
Article Update 13-March-2020: I removed the full source code and the code snippets. The article that remains should act as a "design roadmap" for members who want to write the code in the programming language of your choice. If you are interested in discussing the program further, please contact me via the EE message system.
INTRODUCTION
This Article is a follow-up to the Article entitled How To Rename-Move a Batch of PDF Files Based on Contents of the Files, recently published here at Experts Exchange.
I considered adding the new feature (splitting a single document into multiple documents) to that Article and program, but concluded that it is a significant enough enhancement to warrant a new Article and program.
PREVIOUS ARTICLE
To understand this Article, it will be helpful to read the previous Article, but to get things going here right away, here's a summary of the previous problem and solution.
There is a large batch of PDF files, all with cryptic names, such as [D123456.PDF]. Inside each file on the first line of the first page (always starting at a fixed column and running to the end of the line) is a human-friendly identifier for the file, such as [John Smith]. The requirement is to loop through all of the files in a specified folder in an automated fashion, changing the file names from, for example,
D123456.PDF
to
D123456 John Smith.PDF
That is, add the identifier from the first line of the first page to the file name.
NEW REQUIREMENT
Following publication of the previous Article and the program that implements the solution, the Original Poster (OP) of the question that prompted the Article asked if an enhancement is possible. Specifically, a single PDF file may be composed of what are really multiple PDF files, and the OP wants the program to split the single PDF into multiple PDFs. For example, pages 1 to 3 of [D123456.PDF] may be an invoice for John Smith, while page 4 may be a different invoice, and pages 5 to 6 yet another invoice. With the previous program, the 6-page [D123456.PDF] would simply be renamed to [D123456 John Smith.PDF], still containing all six pages (three invoices). The OP wants the program to split the original PDF file and create three PDFs, one for each of the invoices. The program still has to rename the files based on content, but, in addition, has to provide a suffix for the multiple files, such as
D123456 John Smith-1.PDF
D123456 John Smith-2.PDF
D123456 John Smith-3.PDF
INSTALLATION INSTRUCTIONS FOR REQUIRED SOFTWARE
The previous solution requires two excellent freeware products – the AutoHotkey scripting language (the program is written in this) and [pdftotext.exe] from the Xpdf package to convert the PDF files to text (so the program can extract the identifying names for renaming the files). This new solution requires another excellent freeware product – PDFtk (the PDF Toolkit) from PDF Labs.
Here are the steps for installation of these three packages:
(1) AutoHotkey – http://ahkscript.org (also, see my EE article: AutoHotkey - Getting Started)
Click the Download button at the page above, save the install file, and then run it.
(2) Xpdf – http://www.foolabs.com/xpdf/download.html
Click the [xpdfbin-win-3.03.zip] link at the page above to download the Windows files. Unzip the zip file and there will be folders for 32-bit Windows (bin32) and 64-bit Windows (bin64). Be sure to select the right folder for your version of Windows (32-bit or 64-bit) and copy the file called [pdftotext.exe] to wherever you want (the Xpdf binaries are "no-install" executables). The script will automatically find it if you put it in [Program Files\xpdf\] or [Program Files (x86)\xpdf\], but if you put it somewhere else, that's fine – the script gives you a browse-for-file dialog so you may navigate to it.
(3) PDFtk – http://www.pdflabs.com/tools/pdftk-the-pdf-toolkit/
Click the [pdftk_server-1.45-windows-setup.msi] link at the page above, save the install file, and then run it. It will create a folder called [Program Files\PDF Labs\PDFtk Server\] or [Program Files (x86)\PDF Labs\PDFtk Server\] with a [bin] folder that contains two files – [pdftk.exe] and [libiconv2.dll]. If you'd like to move those two files, that's fine. The script automatically finds them if you leave them where the installer put them, but if you move them somewhere else, it gives you a browse-for-file dialog so you may navigate to them (place both files in the same folder).
ASSUMPTIONS FOR NEW PROGRAM
All of the assumptions for the previous program apply to the new program, namely:
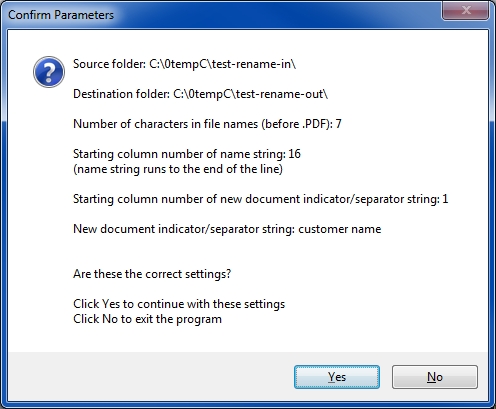
There is a fixed number of characters in the original file name (before the ".pdf"). For example, with file names like [D123456.PDF], that number is 7.
There is a fixed starting column number for the string that will be in the new file name (and it runs to the end of the line). In other words, following the examples above, this is the column number where "John Smith" begins (for the OP, this is 16).
The user specifies the source and destination folders. If they are the same, the program does just a Rename; if they are different, the program does a Rename and a Move.
Here is the assumption unique to the new program:
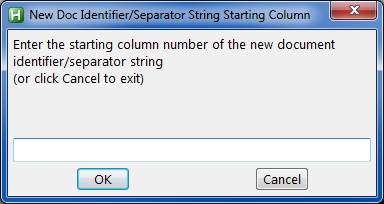
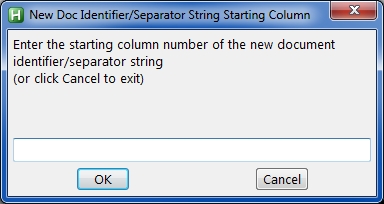
The first line of a page contains a string that identifies it as a new document. It is a fixed string (specified by the user) beginning in a fixed column (also specified by the user). An example is that the first line of the first page of an invoice contains "Customer Name:" beginning in column 5, while all subsequent pages of that same invoice do NOT contain "Customer Name:" beginning in column 5.
So the program reads the first line of each page and if it contains the specified new document identifier/separator string (such as "Customer Name:" or "Client Name-" or "Account Number") in the specified starting column (such as 1 or 5 or 10), then it knows this is the first page of a new document; if it does not, then it knows this is a continuation page of the current document.
HOW TO RUN THIS PROGRAM
Download the attached file called Batch-Mass-Split-Rename-Move-PDF-Files.ahk. After downloading it, you may run it by simply double-clicking on it in Windows Explorer or whatever file manager you use. Since its file type is AHK, AutoHotkey will be launched to process it. If you prefer, the file may be turned into an executable via the AutoHotkey compiler, which is installed during the standard installation of AutoHotkey. If you right-click on an AHK file in Windows Explorer or whatever file manager you use, there will be a context menu pick called Compile Script. Select that and it will create an EXE file, which is a stand-alone, no-install executable of the AHK program.
HOW THE PROGRAM WORKS
For those interested in understanding how the script works, the remainder of this Article shows some code snippets, with a description of what each snippet does, including screenshots where appropriate (this also acts as a form of documentation for the program). However, it does not include code snippets that are the same, or substantially the same, as the code snippets in the previous program, which have already been discussed in the previous Article.
Code snippet:
Code snippet:
The confirmation dialog is similar to the previous program, but the differences are worth noting here:
Code snippet:
Code snippet:
Code snippet:
Code snippet:
Code snippet:
Code snippet
Code snippet:
Code snippet:
Code snippet:
The text file looks like this:
Operational Statistics from Batch-Mass-Split-Rename-Move-PDF-Files
Beginning date and time: 2013-02-11/18:19:22
Number of PDF files processed: 1,969
Number of non-PDF files ignored: 14
Ending date and time: 2013-02-11/18:29:24
Elapsed time (minutes:seconds): 10:2
That's it! I hope this helps the OP as well as other EE members. Although I did a bit of generalization, I realize that the solution is still rather specific to the OP's requirements. However, by providing the source code, I hope that other folks with similar needs will be able to modify the program to suit their purposes.
If you find this article to be helpful, please click the thumbs-up icon below. This lets me know what is valuable for EE members and provides direction for future articles. Thanks very much! Regards, Joe
INTRODUCTION
This Article is a follow-up to the Article entitled How To Rename-Move a Batch of PDF Files Based on Contents of the Files, recently published here at Experts Exchange.
I considered adding the new feature (splitting a single document into multiple documents) to that Article and program, but concluded that it is a significant enough enhancement to warrant a new Article and program.
PREVIOUS ARTICLE
To understand this Article, it will be helpful to read the previous Article, but to get things going here right away, here's a summary of the previous problem and solution.
There is a large batch of PDF files, all with cryptic names, such as [D123456.PDF]. Inside each file on the first line of the first page (always starting at a fixed column and running to the end of the line) is a human-friendly identifier for the file, such as [John Smith]. The requirement is to loop through all of the files in a specified folder in an automated fashion, changing the file names from, for example,
D123456.PDF
to
D123456 John Smith.PDF
That is, add the identifier from the first line of the first page to the file name.
NEW REQUIREMENT
Following publication of the previous Article and the program that implements the solution, the Original Poster (OP) of the question that prompted the Article asked if an enhancement is possible. Specifically, a single PDF file may be composed of what are really multiple PDF files, and the OP wants the program to split the single PDF into multiple PDFs. For example, pages 1 to 3 of [D123456.PDF] may be an invoice for John Smith, while page 4 may be a different invoice, and pages 5 to 6 yet another invoice. With the previous program, the 6-page [D123456.PDF] would simply be renamed to [D123456 John Smith.PDF], still containing all six pages (three invoices). The OP wants the program to split the original PDF file and create three PDFs, one for each of the invoices. The program still has to rename the files based on content, but, in addition, has to provide a suffix for the multiple files, such as
D123456 John Smith-1.PDF
D123456 John Smith-2.PDF
D123456 John Smith-3.PDF
INSTALLATION INSTRUCTIONS FOR REQUIRED SOFTWARE
The previous solution requires two excellent freeware products – the AutoHotkey scripting language (the program is written in this) and [pdftotext.exe] from the Xpdf package to convert the PDF files to text (so the program can extract the identifying names for renaming the files). This new solution requires another excellent freeware product – PDFtk (the PDF Toolkit) from PDF Labs.
Here are the steps for installation of these three packages:
(1) AutoHotkey – http://ahkscript.org (also, see my EE article: AutoHotkey - Getting Started)
Click the Download button at the page above, save the install file, and then run it.
(2) Xpdf – http://www.foolabs.com/xpdf/download.html
Click the [xpdfbin-win-3.03.zip] link at the page above to download the Windows files. Unzip the zip file and there will be folders for 32-bit Windows (bin32) and 64-bit Windows (bin64). Be sure to select the right folder for your version of Windows (32-bit or 64-bit) and copy the file called [pdftotext.exe] to wherever you want (the Xpdf binaries are "no-install" executables). The script will automatically find it if you put it in [Program Files\xpdf\] or [Program Files (x86)\xpdf\], but if you put it somewhere else, that's fine – the script gives you a browse-for-file dialog so you may navigate to it.
(3) PDFtk – http://www.pdflabs.com/tools/pdftk-the-pdf-toolkit/
Click the [pdftk_server-1.45-windows-setup.msi] link at the page above, save the install file, and then run it. It will create a folder called [Program Files\PDF Labs\PDFtk Server\] or [Program Files (x86)\PDF Labs\PDFtk Server\] with a [bin] folder that contains two files – [pdftk.exe] and [libiconv2.dll]. If you'd like to move those two files, that's fine. The script automatically finds them if you leave them where the installer put them, but if you move them somewhere else, it gives you a browse-for-file dialog so you may navigate to them (place both files in the same folder).
ASSUMPTIONS FOR NEW PROGRAM
All of the assumptions for the previous program apply to the new program, namely:
There is a fixed number of characters in the original file name (before the ".pdf"). For example, with file names like [D123456.PDF], that number is 7.
There is a fixed starting column number for the string that will be in the new file name (and it runs to the end of the line). In other words, following the examples above, this is the column number where "John Smith" begins (for the OP, this is 16).
The user specifies the source and destination folders. If they are the same, the program does just a Rename; if they are different, the program does a Rename and a Move.
Here is the assumption unique to the new program:
The first line of a page contains a string that identifies it as a new document. It is a fixed string (specified by the user) beginning in a fixed column (also specified by the user). An example is that the first line of the first page of an invoice contains "Customer Name:" beginning in column 5, while all subsequent pages of that same invoice do NOT contain "Customer Name:" beginning in column 5.
So the program reads the first line of each page and if it contains the specified new document identifier/separator string (such as "Customer Name:" or "Client Name-" or "Account Number") in the specified starting column (such as 1 or 5 or 10), then it knows this is the first page of a new document; if it does not, then it knows this is a continuation page of the current document.
HOW TO RUN THIS PROGRAM
Download the attached file called Batch-Mass-Split-Rename-Move-PDF-Files.ahk. After downloading it, you may run it by simply double-clicking on it in Windows Explorer or whatever file manager you use. Since its file type is AHK, AutoHotkey will be launched to process it. If you prefer, the file may be turned into an executable via the AutoHotkey compiler, which is installed during the standard installation of AutoHotkey. If you right-click on an AHK file in Windows Explorer or whatever file manager you use, there will be a context menu pick called Compile Script. Select that and it will create an EXE file, which is a stand-alone, no-install executable of the AHK program.
HOW THE PROGRAM WORKS
For those interested in understanding how the script works, the remainder of this Article shows some code snippets, with a description of what each snippet does, including screenshots where appropriate (this also acts as a form of documentation for the program). However, it does not include code snippets that are the same, or substantially the same, as the code snippets in the previous program, which have already been discussed in the previous Article.
Code snippet:
removedCode snippet:
removedThe confirmation dialog is similar to the previous program, but the differences are worth noting here:
Code snippet:
removedCode snippet:
removedCode snippet:
removedCode snippet:
removedCode snippet:
removedCode snippet
removedCode snippet:
removedCode snippet:
removedCode snippet:
removedThe text file looks like this:
Operational Statistics from Batch-Mass-Split-Rename-Move-PDF-Files
Beginning date and time: 2013-02-11/18:19:22
Number of PDF files processed: 1,969
Number of non-PDF files ignored: 14
Ending date and time: 2013-02-11/18:29:24
Elapsed time (minutes:seconds): 10:2
That's it! I hope this helps the OP as well as other EE members. Although I did a bit of generalization, I realize that the solution is still rather specific to the OP's requirements. However, by providing the source code, I hope that other folks with similar needs will be able to modify the program to suit their purposes.
If you find this article to be helpful, please click the thumbs-up icon below. This lets me know what is valuable for EE members and provides direction for future articles. Thanks very much! Regards, Joe
50+ years in computers
EE FELLOW 2017 — first ever recipient of Fellow award
MVE 2015,2016,2018
CERTIFIED GOLD EXPERT
DISTINGUISHED EXPERT
EE FELLOW 2017 — first ever recipient of Fellow award
MVE 2015,2016,2018
CERTIFIED GOLD EXPERT
DISTINGUISHED EXPERT
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (15)
Commented:
Author
Commented:Thanks for the compliment — much appreciated! I'm not ready to re-post the source code here, but there may be some other way that I can help you. I'll reply to the message you sent via the Messaging System in a short while. Regards, Joe
Commented:
Commented:
Author
Commented:When I removed the source code last year from six articles that I published here at EE, my intention was that the removal be temporary. I began a project to rewrite all of the programs in my portfolio in order to generalize them for a broader audience and to have a standard user interface, including both a GUI (graphical user interface) and, where it makes sense, a CLI (command line interface). It wound up being a much larger effort than I anticipated, and I'm still not ready to post or distribute the source code for this program (or any of the other five published at EE — and I don't know when or even if that will be, for a variety of reasons).
I have created customized versions of these various programs for EE members who became clients of mine. I provided licenses for the run-time programs (the executables, i.e., the compiled EXE files) for an agreed-upon fee, but I did not provide the source code. I did this previously when EE had the "Hire Me" button, but that no longer exists. The mechanism now at EE for such work is the new Gigs feature, if that interests you.
Regards, Joe
View More