Browser Bot -- Automate Browsing Sequences with C++ (PART THREE)


Published:
Browse All Articles > Browser Bot -- Automate Browsing Sequences with C++ (PART THREE)
In PART ONE and PART TWO of this series, we created a simple dialog-based C++ program that opens a web page, populates some text boxes, and submits the form to a host.
In this article, PART THREE, we will navigate to a particular page of that site and collect some specific information.
There are many reasons to want to automate some browsing activities, but harvesting timely information from websites that provide it is perhaps the most common. In this article, we'll surf to the Yahoo Movies page so we can get the start times of movies at a local theater.
For demonstration purposes, we'll just collect some data and display it in a MessageBox. A real webbot might analyze the data -- maybe locate reviews about each movie to help you decide what to see and perhaps plan a schedule so you could see two movies back-to-back with the minimum delay between shows. Or if you used a bot to collect stock quotes, you might want to feed them into a spreadsheet to do trend analysis. There is just no limit to what you can do once you know the techniques of automating a browser.
Double-click the button to start coding its handler. Make it so:
![The target page]()
We have an OnDocumentComplete handler, and we could set a flag in there. But let's look at an alternative. We could loop, waiting for the ReadyState to go green, perhaps something like this:
Now we are ready to program the bot to take the next step -- put the entire HTML of the web page into a text string so that we can begin to process it.
If you uncomment the MessageBox line, you will see an enormous MessageBox containing the body text, in the internal IE format. If you compare this to the original source text, you will see considerable difference. Whitespace is gone, tags have been normalized to uppercase, unneeded quotes have been removed, and so forth. This is the text that we will parse through to locate the nuggets of information we want -- a movie name and its scheduled start times.
This is the time-honored tradition of screen scraping. There are several other ways to do this, and I'll provide some ideas at the end, but this technique is probably the most straightforward and perhaps the easiest to understand.
The basic technique is to look through the page's HTML source and locate something specific that is near to (just before) the data we want. We then lop-off all of the preceding HTML and work with that subset. We progressively zero-in on the data we want by moving forward through the text to find unique markers.
Add this code to the end of the OnBnClickedMovietimes() function:
First, the function locates the block of HTML that starts with the theater name, and discards everything before that. Then it locates the first movie by looking for the a unique marker -- I chose a class name "movie_title" and again I lop off everything before that. Next the code searches for two markers (">" and "<") that are directly before and after the movie name, and extracts just that name.
Eyeballing the HTML source, I can see that the scheduled times come soon after the movie name. They are in a <TD> (TABLE cell data) block that contains a <UL> block. So, I grab up the entire <UL> block data. The last couple of lines of code replace the unwanted <LI> tags with commas and do some final cleanup. The result is that we have two string variables, one containing the movie name and the other containing the schedule in comma-delimited format.![After parsing part of the HTML]()
I'll let you take it from here. If you wanted to develop this into a full-fledged utility, you would continue down the HTML page and collect the rest of the movie names and schedules. Perhaps you might output them to a spreadsheet or print the data out using your own formatting... whatever.
Other, More Respected Techniques
Screen scraping is universally derided for several reasons. It's messy and prone to errors. But the main reasons is that if the source page layout ever changes, your webbot will break -- you'll need to revise the code to look for new markers and change how you parse. Here are some thoughts about alternatives:
Review:
In this part, we...
IHTMLDocument2 Interface
http://msdn.microsoft.com/en-us/library/aa752574(VS.85).aspx
HTML and DHTML Reference
http://msdn.microsoft.com/en-us/library/ms533050(VS.85).aspx
DHTML Objects
http://msdn.microsoft.com/en-us/library/ms533054(VS.85).aspx
TR1 Regular Expressions
http://msdn.microsoft.com/en-us/library/bb982727.aspx
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
If you liked this article and want to see more from this author, please click the Yes button near the:
Was this article helpful?
label that is just below and to the right of this text. Thanks!
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
In this article, PART THREE, we will navigate to a particular page of that site and collect some specific information.
There are many reasons to want to automate some browsing activities, but harvesting timely information from websites that provide it is perhaps the most common. In this article, we'll surf to the Yahoo Movies page so we can get the start times of movies at a local theater.
For demonstration purposes, we'll just collect some data and display it in a MessageBox. A real webbot might analyze the data -- maybe locate reviews about each movie to help you decide what to see and perhaps plan a schedule so you could see two movies back-to-back with the minimum delay between shows. Or if you used a bot to collect stock quotes, you might want to feed them into a spreadsheet to do trend analysis. There is just no limit to what you can do once you know the techniques of automating a browser.
1. Navigate to the Target Page
Using our WebRobot application from PART ONE, open the Dialog Editor. Select the button tool and draw a new button on the form. Set its Caption to "Get Movie Times" and its ID to IDC_MovieTimesDouble-click the button to start coding its handler. Make it so:
void CWebRobotDlg::OnBnClickedMovietimes()
{
CComVariant vZoom( 75L ); // set the zoom level to 75% for fun
m_ctlBrowser.ExecWB( OLECMDID_OPTICAL_ZOOM, OLECMDEXECOPT_DONTPROMPTUSER, &vZoom, NULL);
//---------- navigate to the movies page for your local ZIP code
CString sUrlMovies= L"http://movies.yahoo.com/showtimes-tickets/?location=91011";
m_ctlBrowser.Navigate( sUrlMovies, 0,0,0,0 );
// --- more code to be added here
}2. Test the code
Run the program, and click the new [Get Movie Times] button. You should see: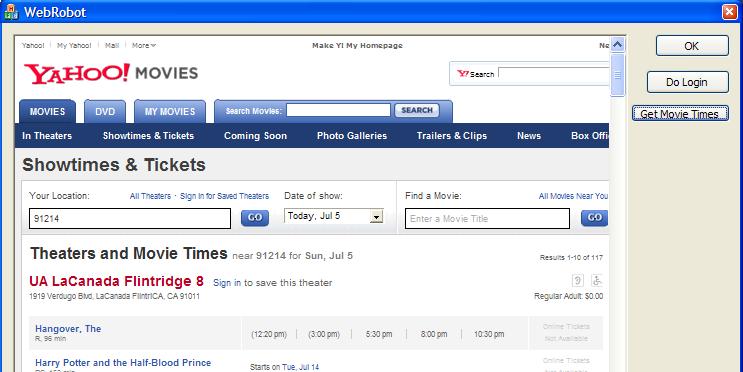
3. Get In Sync with the Browser Control
We'd like to proceed to collecting the movie times from the screen, but as I warned in PART ONE, there is a critical issue to be resolved: The program cannot start working with the DOM until the page has been fully downloaded and the browser has finalized its processing. At this point, we've called the browser control's Navigate function, but the page has not yet been loaded. We need to WAIT at least a little while.We have an OnDocumentComplete handler, and we could set a flag in there. But let's look at an alternative. We could loop, waiting for the ReadyState to go green, perhaps something like this:
while ( m_ctlBrowser.get_ReadyState() != READYSTATE_COMPLETE ) {
Sleep(100); //<<<---------------------- DON'T DO THIS!!
}
// ... continue with next bot operationvoid DelayMs( int nMs )
{
DWORD nMaxTick= GetTickCount()+ nMs;
while ( GetTickCount() < nMaxTick ) {
MSG msg;
while ( ( GetTickCount() < nMaxTick )
&& (::PeekMessage(&msg, NULL, 0, 0, PM_NOREMOVE) )
) {
AfxGetApp()->PumpMessage(); // does a ::GetMessage()
}
Sleep(1);
}
}Now we are ready to program the bot to take the next step -- put the entire HTML of the web page into a text string so that we can begin to process it.
4. Get the Page's HTML Into a String Variable
Replace the last line in OnBnClickedMovietimes() with this code: while ( m_ctlBrowser.get_ReadyState() != READYSTATE_COMPLETE ) {
DelayMs( 100 );
}
//------ page is ready to process
IHTMLDocument2* pDoc= (IHTMLDocument2*)m_ctlBrowser.get_Document();
IHTMLElement* pElemBody= NULL;
pDoc->get_body( &pElemBody );
CComBSTR bstrHTML;
pElemBody->get_innerHTML( &bstrHTML );
CString sBody= bstrHTML; // easier to work with as a CString
// MessageBox( sBody );If you uncomment the MessageBox line, you will see an enormous MessageBox containing the body text, in the internal IE format. If you compare this to the original source text, you will see considerable difference. Whitespace is gone, tags have been normalized to uppercase, unneeded quotes have been removed, and so forth. This is the text that we will parse through to locate the nuggets of information we want -- a movie name and its scheduled start times.
5. Scrape That Screen!
I am about to describe what is commonly considered a massive kludge by most programmers. We are going to dig through the HTML to extract program-usable data from a source that was intended only to be viewed.This is the time-honored tradition of screen scraping. There are several other ways to do this, and I'll provide some ideas at the end, but this technique is probably the most straightforward and perhaps the easiest to understand.
The basic technique is to look through the page's HTML source and locate something specific that is near to (just before) the data we want. We then lop-off all of the preceding HTML and work with that subset. We progressively zero-in on the data we want by moving forward through the text to find unique markers.
Add this code to the end of the OnBnClickedMovietimes() function:
//----------------- zero-in on the data of interest
int nOffset= sBody.Find(L"UA LaCanada");
CString sTmp= sBody.Mid( nOffset ); // lop off the preceding HTML
nOffset= sTmp.Find(L"movie_title" );
sTmp= sTmp.Mid( nOffset ); // lop off the preceding HTML
int nStart= sTmp.Find(L">" )+1; // isolate movie name
int nEnd= sTmp.Find(L"<" );
CString sMovieName= sTmp.Mid(nStart, nEnd-nStart );
nStart= sTmp.Find(L"class=first" )+12;
nEnd= sTmp.Find(L"</UL>" );
CString sMovieTimes= sTmp.Mid(nStart, nEnd-nStart );
sMovieTimes.Replace(L"</LI>\r\n<LI>", L"," ); // cleanup
sMovieTimes.Replace(L"</LI>", L"" );
MessageBox( sMovieTimes, sMovieName );First, the function locates the block of HTML that starts with the theater name, and discards everything before that. Then it locates the first movie by looking for the a unique marker -- I chose a class name "movie_title" and again I lop off everything before that. Next the code searches for two markers (">" and "<") that are directly before and after the movie name, and extracts just that name.
Eyeballing the HTML source, I can see that the scheduled times come soon after the movie name. They are in a <TD> (TABLE cell data) block that contains a <UL> block. So, I grab up the entire <UL> block data. The last couple of lines of code replace the unwanted <LI> tags with commas and do some final cleanup. The result is that we have two string variables, one containing the movie name and the other containing the schedule in comma-delimited format.

I'll let you take it from here. If you wanted to develop this into a full-fledged utility, you would continue down the HTML page and collect the rest of the movie names and schedules. Perhaps you might output them to a spreadsheet or print the data out using your own formatting... whatever.
Other, More Respected Techniques
Screen scraping is universally derided for several reasons. It's messy and prone to errors. But the main reasons is that if the source page layout ever changes, your webbot will break -- you'll need to revise the code to look for new markers and change how you parse. Here are some thoughts about alternatives:
Rather than my stepwise technique, it is often possible to use grep (Regular Expressions) to zero-in directly on the target data. Basically, that's what grep is all about. Since you may not have ever used grep before, I decided not to introduce it here.
You could simplify some of the steps by digging into the DOM. In this case, you might locate the desired TABLE element by its class name. You could then walk through the child nodes, and collect data without doing the messy HTML parsing. But that technique has the same major drawback: If the page changes, the program probably breaks.
Sometimes it is easier to get to a printer-ready page and parse it.
It goes without saying that if the site provides an RSS feed or some sort of API to provide the desired data in machine-readable format, then by all means, use that!
Review:
In this part, we...
Opened a web page and read its HTML into a string variable for processing.
Set the ZOOM factor to 75% just because we could.
Avoided the problem of trying to access the DOM before it was ready by using a PumpMessages loop.
Saw that the IE internal HTML differs from the original source code.
Used the infamous "screen scraping" technique to extract program-usable data from the HTML.
References:
IHTMLDocument2 Interface
http://msdn.microsoft.com/en-us/library/aa752574(VS.85).aspx
HTML and DHTML Reference
http://msdn.microsoft.com/en-us/library/ms533050(VS.85).aspx
DHTML Objects
http://msdn.microsoft.com/en-us/library/ms533054(VS.85).aspx
TR1 Regular Expressions
http://msdn.microsoft.com/en-us/library/bb982727.aspx
=-=-=-=-=-=-=-=-=-=-=-=-=-
If you liked this article and want to see more from this author, please click the Yes button near the:
Was this article helpful?
label that is just below and to the right of this text. Thanks!
=-=-=-=-=-=-=-=-=-=-=-=-=-
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (5)
Commented:
Two quick questions:
1. Another essential task for WEB bots, is modifying the incoming page - perhaps removing unwanted ads or pictures, or changing other content.
2. If the page contains frames, the elements are now contained in the frames, not the main document. How do you extract elements then?
Could you please provide a link, or an example to these?
Author
Commented:It is quite possible to use the DOM to inject HTML into a page or remove it. For instance, the IHTMLElement::put_innerHTM
Commented:
DanRollins, maybe the comments suggest by yossikally might be an "Advanced" techniques follow up Article ? Would like to see that...
Thanks for your three part Article, enjoyed this series...
Regards,
Mark
Commented:
https://www.experts-exchange.com/questions/24552000/Hi-Dan-Or-someone-else-as-well-Can-you-provide-an-example-of-a-bot-that-modifies-page's-content.html
Commented: