How to find rows that are in one table, but not another


Published:
Browse All Articles > How to find rows that are in one table, but not another
Introduction
A commonly seen question in the database zones is "How do I find data that is in table A but not in table B?". Anytime I see a question asked repeatedly, it seems to me that it would be a good topic for an article.
Setup
For the purposes of this article, we're going to assume the following setup (based upon a system I work with).
I will run examples in both SQL Server and Oracle and we'll examine the execution plans as well. The purpose of this article is not to compare and contrast the two engines, just to give examples of how both work and how each database system handles each of the different options.
For the SQL Server system:
There is a table called SUPPLIER that contains 3584 rows. There is a unique index (the primary key) on a column called SUPPLIER_NO. There is another table called ORDERS that contains 975059 rows. There is a unique index (the primary key) on a column called PO_NO. There is also an index on a combination of some other columns (SUPPLIER_NO, ORDER_DATE, CREATED_DATE, PO_NO).
The purpose of our demonstration here will be to find all suppliers with whom we have never placed orders; that is, the supplier number exists on SUPPLIER but not on ORDERS.
We will also assume that all database statistics are up to date. For the SQL Server system, in order to make the execution plan clearer, I'll be forcing it to single thread and remove parallelism and also performing dbcc dropcleanbuffers before the query to flush the buffer cache.
Finally, each of these queries return exactly the same data. I'm not showing that for security reasons, you'll have to take my word for it :)
Demo Time!
There are 3 ways to do this that immediately come to mind that will work for both SQL Server and Oracle. There is a 4th way that effectively does the same thing in both Oracle and SQL Server but is implemented slightly differently.
The first way is by the use of the NOT IN clause:
dbcc dropcleanbuffers
select supplier_no from supplier
where supplier_no not in (select supplier_no from orders)
option (maxdop 1)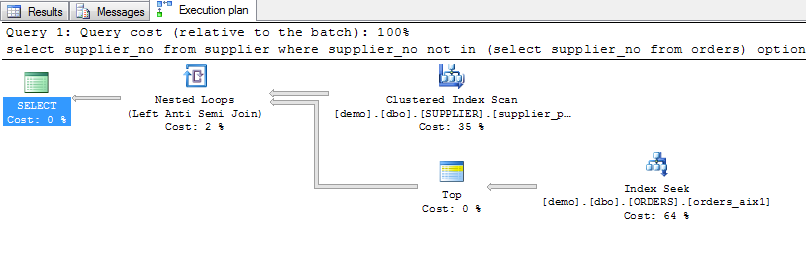
The second way is to use the NOT EXISTS clause:
dbcc dropcleanbuffers
select supplier_no from supplier a
where not exists (select 1 from orders b
where a.supplier_no = b.supplier_no )
option (maxdop 1)
The third way is to use an outer join and check for the existence of NULLS to determine the missing rows:
dbcc dropcleanbuffers
select a.supplier_no
from supplier a
left join orders b on a.supplier_no = b.supplier_no
where b.supplier_no is null
option (maxdop 1)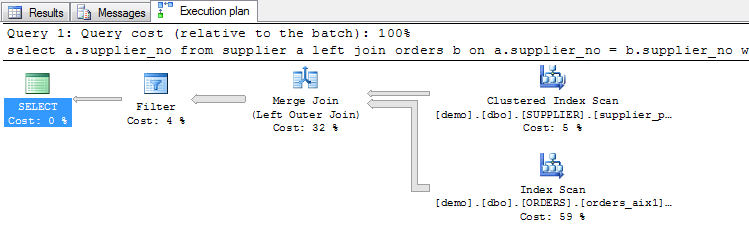
The fourth way is using a SQL Server specific extension, called EXCEPT. This runs two queries with syntax similar to that of a UNION and returns all rows from the first query that aren't in the second.
dbcc dropcleanbuffers
select supplier_no from supplier
except
select supplier_no from orders
option (maxdop 1)
Examining these execution plans, what do we see ? NOT IN and NOT EXISTS appear to produce the same execution plan. Using the LEFT JOIN option produces a pretty short and concise plan and EXCEPT seems to do a little more work.
I don't want to make the definitive claim here that that one is more efficient than the other, especially since they all run for about the same time, but the LEFT JOIN certainly seems to produce the cleanest plan of the lot.
Now we'll try the same queries with Oracle and see what the Oracle optimizer thinks of them.
On the Oracle system is slightly different in table size than the SQL Server System, but the same tables and indexes are present. SUPPLIER has 15421 rows and ORDERS has 422009 rows. Before each query, we'll assume that alter system flush buffer_cache has been run as well to clear the buffer cache. Execution plan output is generated via SET AUTOTRACE ON from sqlplus.
The first query (NOT IN):
SQL> select supplier_no from supplier
2 where supplier_no not in (select supplier_no from orders);Execution Plan
----------------------------------------------------------
Plan hash value: 1005948720
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 15421 | 210K| 572 (2)| 00:00:07 |
|* 1 | HASH JOIN ANTI | | 15421 | 210K| 572 (2)| 00:00:07 |
| 2 | INDEX FAST FULL SCAN| SUPPLIER_PK | 15421 | 105K| 10 (0)| 00:00:01 |
| 3 | INDEX FAST FULL SCAN| ORDERS_IX1 | 422K| 2884K| 559 (1)| 00:00:07 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("SUPPLIER_NO"="SUPPLIER_NO")The second query (NOT EXISTS):
SQL> select supplier_no from supplier a
2 where not exists (select 1 from orders b
3 where a.supplier_no = b.supplier_no );Execution Plan
----------------------------------------------------------
Plan hash value: 1005948720
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 15421 | 210K| 572 (2)| 00:00:07 |
|* 1 | HASH JOIN ANTI | | 15421 | 210K| 572 (2)| 00:00:07 |
| 2 | INDEX FAST FULL SCAN| SUPPLIER_PK | 15421 | 105K| 10 (0)| 00:00:01 |
| 3 | INDEX FAST FULL SCAN| ORDERS_IX1 | 422K| 2884K| 559 (1)| 00:00:07 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("A"."SUPPLIER_NO"="B"."SUPPLIER_NO")SQL> select a.supplier_no
2 from supplier a
3 left join orders b on a.supplier_no = b.supplier_no
4 where b.supplier_no is null;Execution Plan
----------------------------------------------------------
Plan hash value: 1005948720
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 15421 | 210K| 572 (2)| 00:00:07 |
|* 1 | HASH JOIN ANTI | | 15421 | 210K| 572 (2)| 00:00:07 |
| 2 | INDEX FAST FULL SCAN| SUPPLIER_PK | 15421 | 105K| 10 (0)| 00:00:01 |
| 3 | INDEX FAST FULL SCAN| ORDERS_IX1 | 422K| 2884K| 559 (1)| 00:00:07 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("A"."SUPPLIER_NO"="B"."SUPPLIER_NO")SQL> select supplier_no from supplier
2 minus
3 select supplier_no from orders;Execution Plan
----------------------------------------------------------
Plan hash value: 116939239
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 15421 | 2990K| | 2089 (2)| 00:00:26 |
| 1 | MINUS | | | | | | |
| 2 | SORT UNIQUE | | 15421 | 105K| 256K| 66 (4)| 00:00:01 |
| 3 | INDEX FAST FULL SCAN| SUPPLIER_PK | 15421 | 105K| | 10 (0)| 00:00:01 |
| 4 | SORT UNIQUE | | 422K| 2884K| 6632K| 2023 (2)| 00:00:25 |
| 5 | INDEX FAST FULL SCAN| ORDERS_IX1 | 422K| 2884K| | 559 (1)| 00:00:07 |
----------------------------------------------------------------------------------------------Interestingly, Oracle produces the exact same execution plan for all three of the first three queries. The final way is a much different plan with an increased execution time.
Extra Considerations
If is possible that one, or both of the tables may not have such convenient indexes. In the event that indexes are not available for evaluation by the optimizer, you will end up with full table scans - this will of course alter the execution plans show above and the way that the data returned from each step is treated.
For SQL Server, instead of Nested Loops to match the data returned from the 2 queries, it turns into a Hash Join.
For Oracle, all it did was to change the lookup of one table to a full table scan but the join method remained the same, as Hash Join Anti.
Each optimizer adapted to no indexes in a different way. If you have to do this kind of query, having available indexes will improve the performance of finding the result set. No available indexes won't stop the results being returned, it may just take longer, depending upon the volume of the data you are dealing with.
Conclusion
As with most things database related, there may be many ways to perform a task. In order to find the most efficient way for whatever it is you're attempting to do, examine the options and look at the output from the tools provided to find the best way for your situation.
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (0)