Data integration between Bigdata and SQL Server

Alpesh Patel![]() Solution Architect at TCS (SAFe®Agilist, TOGAF® Foundation, PSM I®, MCP, MCSD)
Solution Architect at TCS (SAFe®Agilist, TOGAF® Foundation, PSM I®, MCP, MCSD)
 Solution Architect at TCS (SAFe®Agilist, TOGAF® Foundation, PSM I®, MCP, MCSD)
Solution Architect at TCS (SAFe®Agilist, TOGAF® Foundation, PSM I®, MCP, MCSD)
CERTIFIED EXPERT
Published:
Browse All Articles > Data integration between Bigdata and SQL Server
Hello Experts, Today I am going to write something for Big Data and SQL Server. Nowadays, Data is growing and it’s not easy to manage this amount of Data using current Applications. Hence, Apache has worked and created project Hadoop to cope with the big issue of Managing Data. Moreover, all big players in the Database field like Oracle, Microsoft, and SAP etc. all have started to give integration with Big Data.
Same way, it’s not easy task for developer to work with Big Data as well.
Here, I am going to showcase how to create VM for existing Image of VM using VMware Player and then we import and export data from SQL Server to Big Data using Sqoop command and SSIS package respectively.
Big Data is just a word. To work with Apache has created open source projects like Hadoop, MapReduce, HDFS etc. (Read More)
![1.2.VMWare.PNG]()
![1.1.OpenVM.PNG]()
![1.3.VMWareImport.PNG]()
![1.4.VMWareStarted.PNG]()
![1.5.VMWareStart1.PNG]()
![1.6.VMWareRunning.PNG]()
![2.1.OpenHadoop.PNG]()
![2.2.OpenHadoopUI.PNG]()
Note : One can install hadoop on Windows as well. To do that download Hadoop using Window Platform Installation utility.
To manage data operation with SQL server to Hadoop you need JDBC driver for SQL Server from microsoft site.
![3.1.winscp.PNG]()
![3.2.winscpFTP.PNG]()
![3.3.ConfigSQL.PNG]()
![3.4.ConfigSQLTCPIP.PNG]()
![3.4.ConfigSQLTCPIPPort.PNG]()
![3.5-CheckDBconn.png]()
![4.1.ODBCConfig.PNG]()
![4.2.ODBCSSIS.PNG]()
Same way, it’s not easy task for developer to work with Big Data as well.
Here, I am going to showcase how to create VM for existing Image of VM using VMware Player and then we import and export data from SQL Server to Big Data using Sqoop command and SSIS package respectively.
Big Data is just a word. To work with Apache has created open source projects like Hadoop, MapReduce, HDFS etc. (Read More)
1. Configure Hadoop on VM
We use the existing SandBox from Hartonworks and configure it locally.
- Download HDP 2.1 Sandbox from here. We recommend to download HDP 2.1 Sandbox
on VMWare Fusion or Player. - Download VMware player to create VM from here.
- Open VMware Player and import image of downloaded Sandbox from Hartonworks.
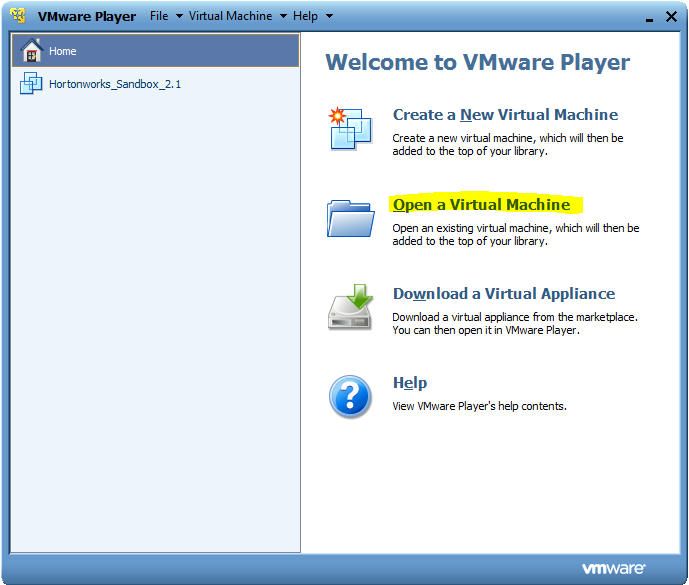
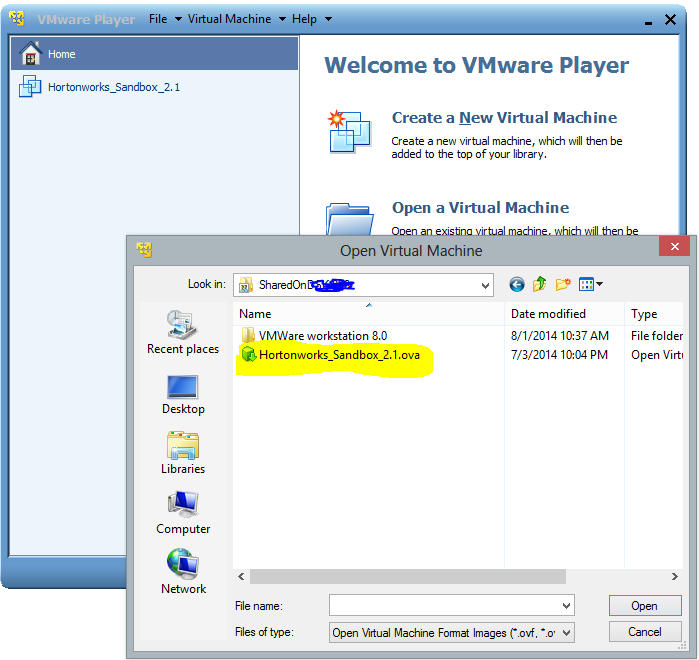
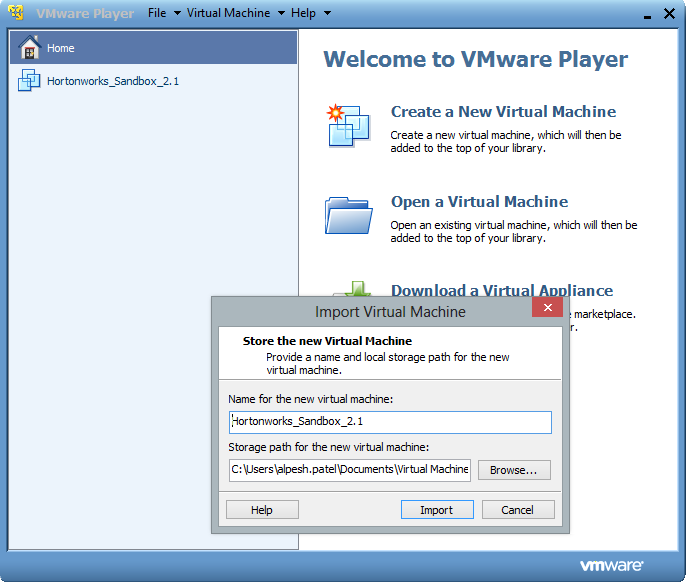
- Sandbox image is imported to VM and now VM is up. Using the VMware Player we are going to start VM machine as shown.

- Now VM is started and running. Login to VM as instructed on screen.
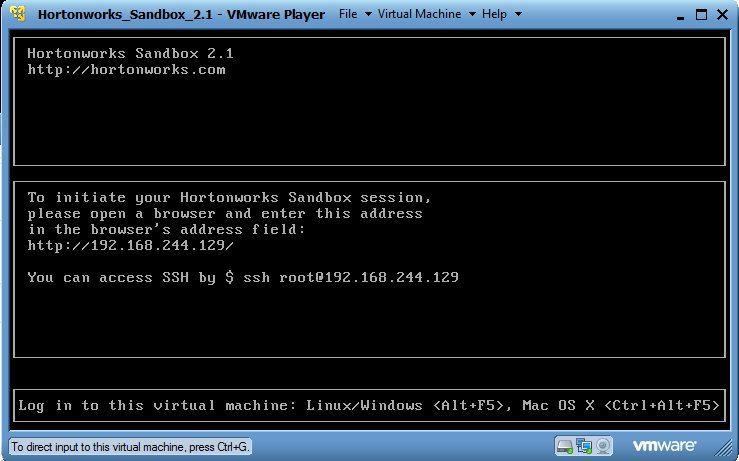
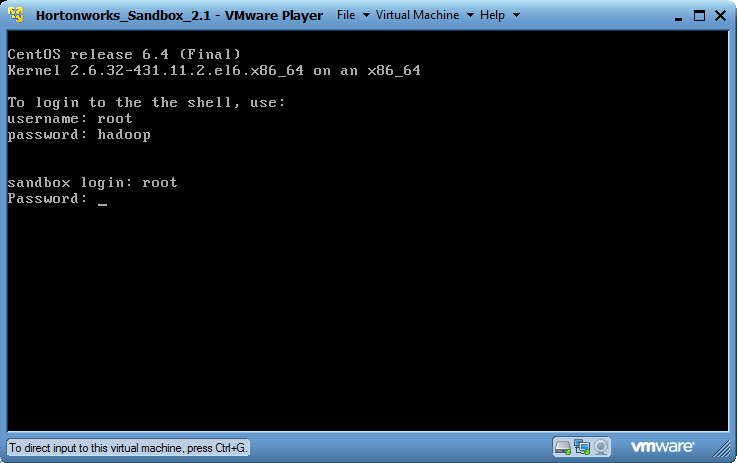
2. Let's we check installed Hadoop in local system. Is it available or not via url.
- Check url in above screen of runnip VM and try that url in Browser. In my case it is 192.168.244.129
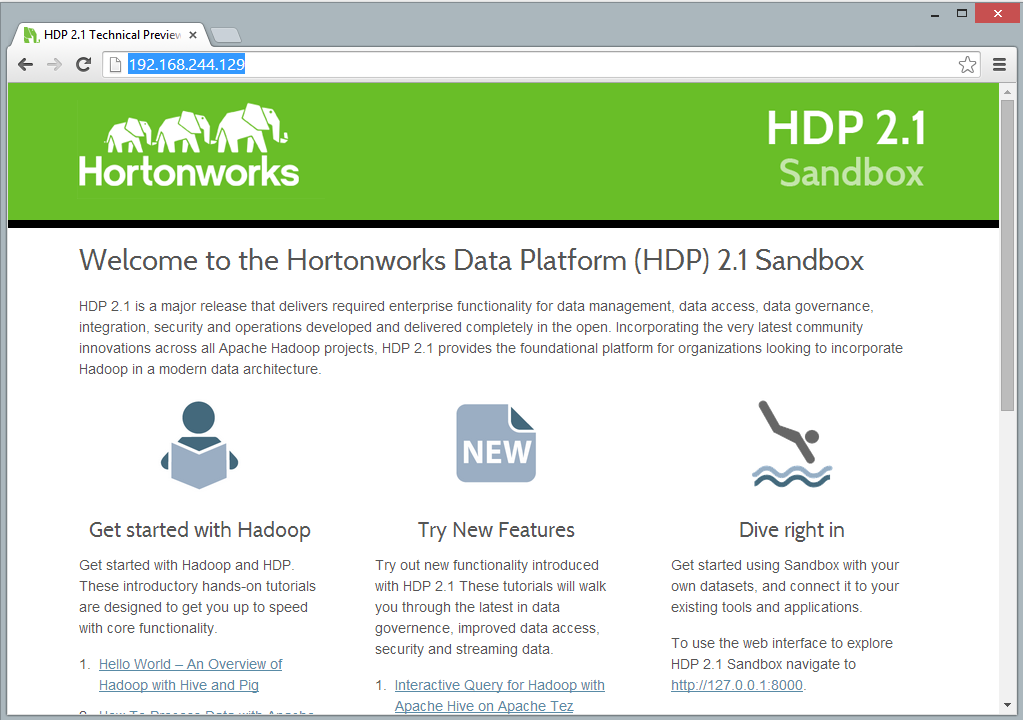
- If you want to look into then ckick link under Dive right in. It will take you to Hadoop environment from where you can create database, table, import/export data to table etc under different tabs.
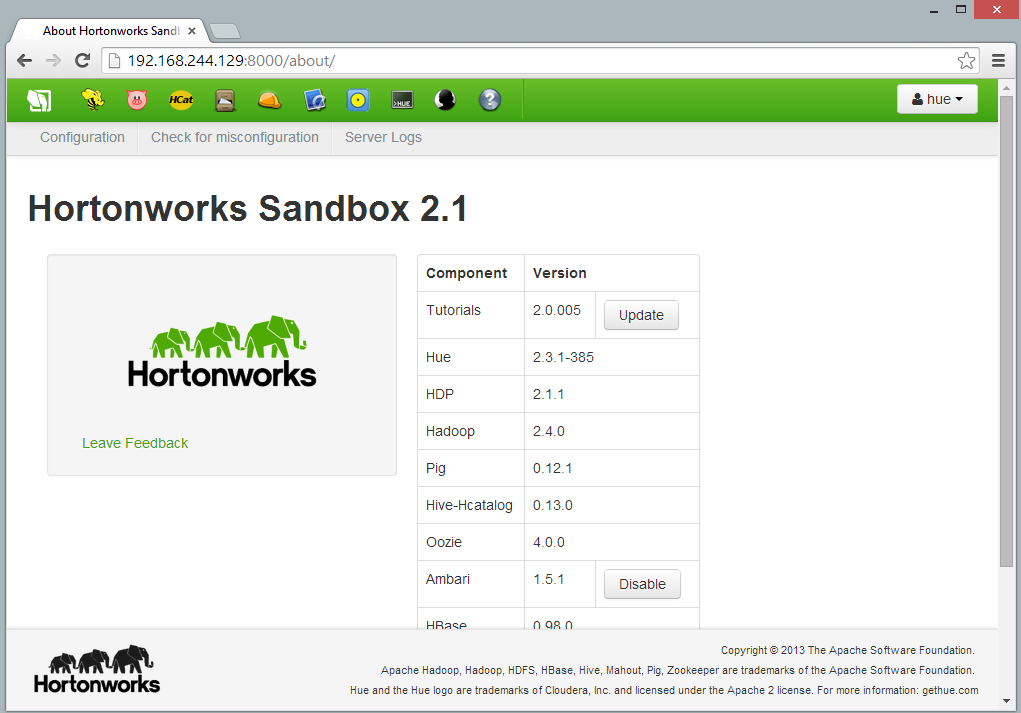
Note : One can install hadoop on Windows as well. To do that download Hadoop using Window Platform Installation utility.
3. Import data to Hadoop using Sqoop
- Sqoop is utility to manage data operations to Hadoop.
To manage data operation with SQL server to Hadoop you need JDBC driver for SQL Server from microsoft site.
- Now extract and copy file sqljdbc4.jar to VM directory /usr/lib/sqoop/lib. It will be done by winscp utility.
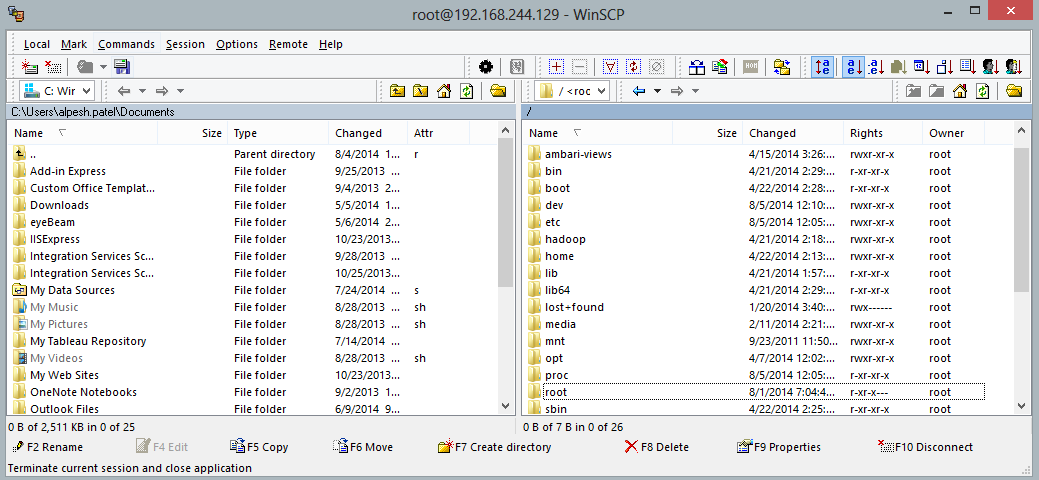
- Then we check connection to SQL Serever using Sqoop. To do that we need TCP/IP protocol enabled with specific port and that is available through Firewall.
- To disable Shared Memory open SQL Configuration manager -> goto -> SQL Server Network Configuration -> Protocol for -> Shared Memory -> Properties and make enabled to False.
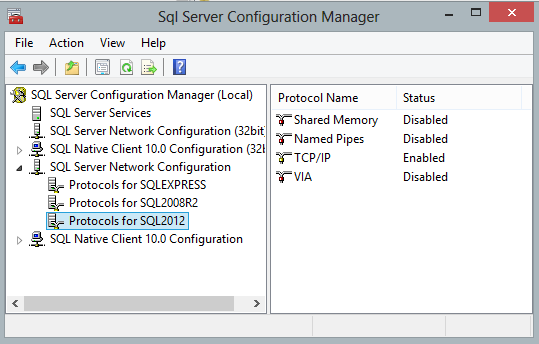
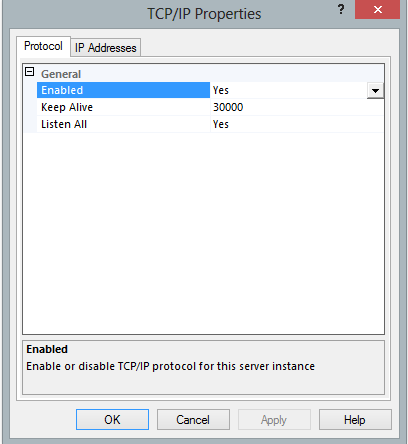
- To enable TCP/IP protocol : goto -> SQL Server Network Configuration -> Protocol for -> TCP/IP -> Properties and make enabled to True. Same way on second IP Addresses tab changes port#.
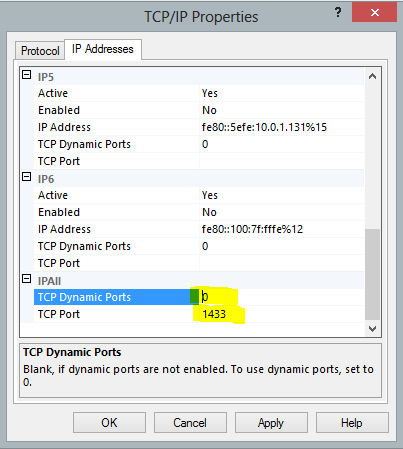
- Now you are ready to play with Hadoop and SQL server for data operations.
- Now we move to VM environment and execute command to check SQL Server connectivity.
undefined- To check the connectivity we execute command as below on VM command prompt. (IP Address and Port # from result of Above query)
undefined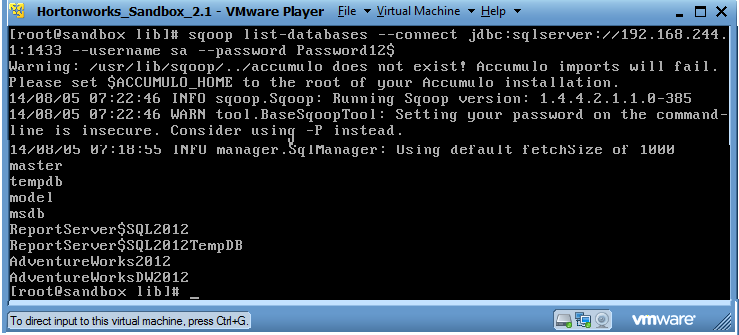
- To import table to Hadoop with schema, you can use below command
undefined- To import data to existing Hadoop table, you can use below command
undefined4. Export data from Hadoop using SSIS Package
- To access Hadoop data we need ODBC driver for Hive. You can download from microsoft site.
- Create new SSIS project using SSDT and open package.
- Configure ODBC for Hive connection
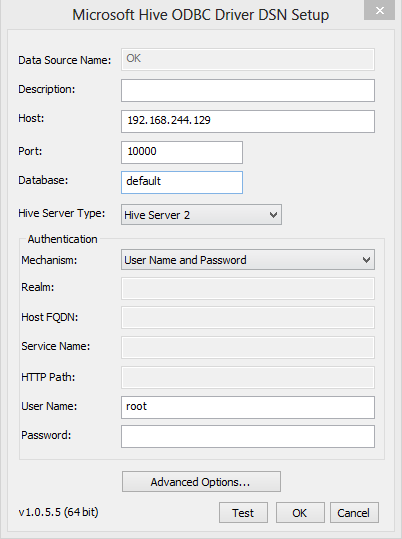
- Create new connection using ODBC
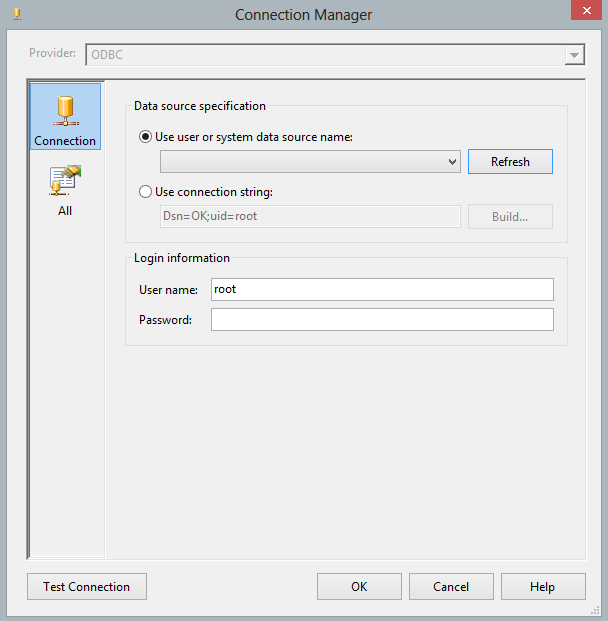
- Now create Dataflow task to fetch data using ODBC Source
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (2)
Commented:
Author
Commented: