SQL Server Delete Duplicate Rows


Microsoft SQL Server database developer, architect, and author specializing in Business Intelligence, ETL, and Data Warehousing.
Published:
Browse All Articles > SQL Server Delete Duplicate Rows
This article is a montage of common Microsoft SQL Server 'How to delete duplicate rows?' solutions commonly provided here at Experts-Exchange. The code uses Microsoft SQL Server 2012 Transact-SQL (T-SQL), and I'll make a wild assumption that this article is intuitive enough so that readers using other databases can understand the concepts and apply them to their database of choice.
![calvin-and-hobbes-duplicator.gif]() Scenarios
Scenarios
HIDE
#1 SELECT (aka show) unique rows, but none of the column values that were duplicated
#2 SELECT (aka show) unique columns AND one or more of the column values that were duplicated
SHOW
#1 SELECT (aka show) the duplicates
DELETE
#1 HARD DELETE all duplicate rows from the table
#2 SOFT DELETE all duplicate rows by not deleting, but updating an is_active column from 'Y' to 'N'.
Extra Stuff on DELETE
#1 How to test your DELETE statement using a transaction
#2 How to back up what was just deleted into another table, just in case you need those rows later
Intro
My current client is an airline, and for one ETL project I receive a file every minutes that has flight information.
Often the files are sent to us multiple times, and even within each file there are a lot of duplicates.
Run this first!
Execute the below block of SQL to load my demo table of flights, which contains twenty five rows with twenty unique flights and five of which are duplicates.
The resulting table is here. (Column duplicate_number is only used to illustrate the duplicates, and not used in any logic here.)
![flights-beginning-set.jpg]()
HIDE #1 SELECT (aka show) unique rows, but none of the column values that were duplicated
Note that 20 rows are returned out of the 25 rows in table flights.
A helpful article in Experts-Exchange is DISTINCT and GROUP BY... and why does it not work for my query?
HIDE #2 SELECT (aka show) unique columns AND one or more of the column values that were duplicated
Pretty easy with GROUP BY as all you'll need to do is add to the SELECT clause another column with an aggregate function such as Min, Max, Sum, Count, Avg, etc.
For example, in the below image the first set returns all 23 rows, but the second set returns 20, the total number of rows based on the four-column primary key we're using. Adding Max(entered_dt) as most_recently_added to the SELECT clause returns only the value across duplcate rows that has the maximum (most recent with dates) datetime. For flight_date='2014-07-15', flight_number=103, dep='MSP', reg=801, there are two rows in the first set (grey background), but only the most recent entered_dt is returned (black arrows).
![group-by-with-aggregate.jpg]()
Another helpful article in Experts-Exchange is SQL Server GROUP BY Solutions.
SHOW #1 SELECT (aka show) the duplicates
This query uses the HAVING clause, which is essentially a WHERE clause on an aggregate amount, such as 'Give me all the professional athletes that made over $100 million in their lifetimes')
This query uses a Common Table Expression to group (PARTITION BY) rank all of the rows by the primary key columns, and then sort (ORDER BY) by the entered_dt. The query below it then selects all of the rows where the rank number is greater than 1, i.e. duplicates.
![show-duplicate-rows-return-sets-only.jpg]()
DELETE #1 HARD DELETE all duplicate rows from the table
To handle this based on a condition you'll have to
Note: If your situation deals with duplicates for all columns, hence no sorting/ORDER BY fits your situation, then use ORDER BY (SELECT NULL) in place of the above ORDER BY clause.
To handle this not based on a condition, i.e. 'just delete all except one, I don't care which', then change the ORDER BY ISNULL(actual_out_tm, '23:59:59') line to ORDER BY (SELECT NULL)).
DELETE #2 SOFT DELETE all duplicate rows by updating an is_active column.
A 'soft delete' is when the row is not actually deleted, but there is a column that shows whether the column is considered active or not. Companies will have multiple reasons for deleting this way that deal with preserving the history of the row, such as Customers that change addresses and policy holders where the policy changes.
and here's the return set
![soft-delete-return-set.jpg]()
Extra Stuff on DELETE #1 How to test your DELETE statement using a transaction
A word of caution ... if your requirement is to delete duplicate rows from a production table, YOU'RE PLAYING WITH FIRE!!! One delete without a WHERE clause and the entire table contents are deleted. So GOOD GOD MAKE A BACKUP FIRST. Then, you can use a transaction rolled back to view the delete action BEFORE IT IS ACTUALLY DELETED, then you can run multiple times to insure that the delete is correct, then you can make the permanent delete with a commit.
Extra Stuff on DELETE #2 How to back up what was just deleted into another table
Often it's helpful to save the rows deleted into another table, just for quick reference in case you need to do anything with those rows later. The quickest way I've found to do this is two steps...
Step 1 Create the 'temp' table to store deleted rows.
Step 2 Perform the delete. Same code as previous, but the OUTPUT in the 2nd line inserts the deleted rows from flights INTO z_flights_backup_20140907.
The end. Good luck. Thank you for reading my article, feel free to leave me some feedback regarding the content or to recommend future work. If you liked this article please click on the big green 'Vote' button near the bottom of the page.
I look forward to hearing from you. - Jim Horn ( LinkedIn ) ( Twitter )
 Scenarios
Scenarios
HIDE
#1 SELECT (aka show) unique rows, but none of the column values that were duplicated
#2 SELECT (aka show) unique columns AND one or more of the column values that were duplicated
SHOW
#1 SELECT (aka show) the duplicates
DELETE
#1 HARD DELETE all duplicate rows from the table
#2 SOFT DELETE all duplicate rows by not deleting, but updating an is_active column from 'Y' to 'N'.
Extra Stuff on DELETE
#1 How to test your DELETE statement using a transaction
#2 How to back up what was just deleted into another table, just in case you need those rows later
Intro
My current client is an airline, and for one ETL project I receive a file every minutes that has flight information.
Often the files are sent to us multiple times, and even within each file there are a lot of duplicates.
Run this first!
Execute the below block of SQL to load my demo table of flights, which contains twenty five rows with twenty unique flights and five of which are duplicates.
IF EXISTS (SELECT name FROM sys.tables WHERE name='flights')
DROP TABLE flights
GO
CREATE TABLE flights (
-- KEY columns
flight_date date,
flight_number smallint,
dep char(3), -- Departing airport code. LAX = Los Angeles, MSP = Minnespolis/St. Paul, etc.
reg char(3), -- aka number on the tail of the plane, N810SY, but for this demo only using the three numbers = 810
-- NON-KEY columns along for the ride
arr char(3), -- arriving station.
-- SCHEDULED TIMES: Out means leafing the dep airport gate, in means arriving at the arr airport gate. Always populated.
-- Normally datetime, but shortened to time for this demo.
scheduled_out_tm time(0),
scheduled_in_tm time(0),
-- ACTUAL TIMES: Will have times ONLY when it happeneds, else it's scheduled and NULL.
actual_out_tm time(0),
actual_in_tm time(0),
-- ACTIVE: Used to detect a good flight for 'soft deletes', if you're not allowed to delete rows but can have update a bit column.
is_active char(1),
-- Auditing columns for who last touched the row.
entered_dt datetime NULL,
entered_by varchar(10) NULL,
duplicate_number tinyint NULL)
INSERT INTO flights (flight_date, flight_number, reg, dep, arr, scheduled_out_tm, scheduled_in_tm, actual_out_tm, actual_in_tm, entered_dt, entered_by, duplicate_number)
VALUES
-- Flight 101 MSP-BOS-NY are actual flights. Good to go.
('2014-07-15', '101', '816', 'MSP', 'BOS', '08:00:00', '12:00:00', '08:00:00', '12:00:00', '2014-07-15 12:05:00', 'Jack', NULL),
('2014-07-15', '101', '816', 'BOS', 'NY', '13:00:00', '13:45:00', '13:00:00', '13:45:00', '2014-07-15 14:00:00', 'W.P.', NULL),
-- Flight 102 MSP-MIA-HAV hasn't happened yet, so scheduled flight with no actual times. Good to go.
('2014-07-15', '102', '802', 'MSP', 'MIA', '08:00:00', '12:00:00', NULL, NULL, '2014-06-01 00:00:00', 'Scheduling', NULL),
('2014-07-15', '102', '802', 'MIA', 'HAV', '13:00:00', '14:00:00', NULL, NULL, '2014-06-01 00:00:00', 'Scheduling', NULL),
-- Duplicate #1: Flight 103 has two actuals on the MSP-PHX leg, five minutes apart. Note: Temps rise thirty degrees upon descent to PHX.
('2014-07-15', '103', '801', 'MSP', 'PHX', '04:00:00', '6:00:00', '04:00:00', '6:00:00', '2014-07-15 06:05:00', 'Jack', NULL),
('2014-07-15', '103', '801', 'MSP', 'PHX', '04:00:00', '6:00:00', '04:00:00', '6:00:00', '2014-07-15 06:10:00', 'Jack', 1),
('2014-07-15', '103', '801', 'PHX', 'SJC', '07:00:00', '08:45:00', '07:00:00', '08:45:00', '2014-07-15 09:00:00', 'Miriam', NULL),
-- Duplicate #2: Flight 104 has a SCHEDULED and an ACTUAL row for MSP-DTW. The business only wants to see the actual.
('2014-07-15', '104', '816', 'MSP', 'DTW', '16:00:00', '18:45:00', '16:00:00', '18:45:00', '2014-07-15 18:50:00', 'Jack', NULL),
('2014-07-15', '104', '816', 'MSP', 'DTW', '16:00:00', '18:45:00', NULL, NULL, '2014-06-01 00:00:00', 'Scheduling', 2),
('2014-07-15', '104', '816', 'DTW', 'MSP', '08:00:00', '12:00:00', '12:05:00', '12:00:00', '2014-07-15 18:50:00', 'Bob', NULL),
-- Flight 105 MSP-LAN and back are actual flights. Go Green. Go White!
('2014-07-15', '105', '814', 'MSP', 'LAN', '08:00:00', '12:00:00', '08:00:00', '12:00:00', '2014-07-15 12:05:00', 'Jack', NULL),
('2014-07-15', '105', '814', 'LAN', 'MSP', '13:00:00', '13:30:00', '13:00:00', '13:30:00', '2014-07-15 12:05:00', 'Sparty', NULL),
-- Flight 106 MSP-CZM is an in-progress flight. Good to go.
('2014-07-15', '106', '802', 'MSP', 'CZM', '08:00:00', '12:00:00', '08:00:00', NULL, '2014-07-15 12:05:00', 'Jack', NULL),
-- Duplicate #3: Flight 107 has two scheduled on the MSP-SFO leg, all rows identical
('2014-07-15', '107', '802', 'MSP', 'SFO', '04:00:00', '6:00:00', NULL, NULL, '2014-06-01 00:00:00', 'Scheduling', NULL),
('2014-07-15', '107', '802', 'MSP', 'SFO', '04:00:00', '6:00:00', NULL, NULL, '2014-06-01 00:00:00', 'Scheduling', 3),
-- Duplicate #4: Flight 108 has two scheduled on the MSP-SFO leg, all rows identical except entered_dt
('2014-07-15', '108', '811', 'MSP', 'SFO', '04:00:00', '6:00:00', NULL, NULL, '2014-06-01 00:00:00', 'Scheduling', NULL),
('2014-07-15', '108', '811', 'MSP', 'SFO', '04:00:00', '6:30:00', NULL, NULL, '2014-06-02 00:00:00', 'Scheduling', 4),
-- Flight 109 MSP-LAS-MSP. 10 flights/day in the Minnesota winter, only one in the summer. Good to go.
('2014-07-15', '109', '881', 'MSP', 'LAS', '07:15:00', '9:15:00', '07:15:00', '9:15:00', '2014-07-15 09:30:00', 'Mikey', NULL),
('2014-07-15', '109', '881', 'LAS', 'MSP', '11:15:00', '15:15:00', '11:15:00', '15:15:00', '2014-07-15 15:30:00', 'Jimbo', NULL),
-- Flights 110 and 111 are both MSP-Chicago Midway for the Chicago rush hour. Good to go.
('2014-07-15', '110', '888', 'MSP', 'MDW', '07:00:00', '9:00:00', '07:00:00', '9:00:00', '2014-07-15 09:30:00', 'Flavo', NULL),
('2014-07-15', '111', '889', 'MSP', 'MDW', '07:10:00', '9:10:00', '07:10:00', '9:10:00', '2014-07-15 09:30:00', 'Valentino', NULL),
-- Duplicate #5: Flights 112 is an air return, where they took off, realized they forgot the coffee, went back to MSP, got coffee, and completed the flight.
('2014-07-15', '112', '891', 'MSP', 'MSP', '07:00:00', '07:30:00', '07:00:00', '07:30:00', '2014-07-15 07:50:00', 'Jack', NULL),
('2014-07-15', '112', '891', 'MSP', 'POR', '07:00:00', '09:45:00', '07:45:00', '09:45:00', '2014-07-15 09:30:00', 'Greg', 5),
-- Flight 113 had a 'tail swap' when they changed planes for the MSP-SEA leg, but didn't delete the scheduled row for the first plane. Good to go.
('2014-07-15', '113', '805', 'MSP', 'SEA', '07:00:00', '9:00:00', NULL, NULL, '2014-06-01 00:00:00', 'Scheduling', NULL),
('2014-07-15', '113', '842', 'MSP', 'SEA', '07:15:00', '9:00:00', NULL, NULL, '2014-06-02 00:00:00', 'Scheduling', NULL)
-- Display the table
SELECT * FROM flightsThe resulting table is here. (Column duplicate_number is only used to illustrate the duplicates, and not used in any logic here.)

HIDE #1 SELECT (aka show) unique rows, but none of the column values that were duplicated
Note that 20 rows are returned out of the 25 rows in table flights.
SELECT DISTINCT flight_date, flight_number, scheduled_out_tm, reg
FROM flights
ORDER BY flight_date, flight_number, scheduled_out_tm, reg
SELECT flight_date, flight_number, scheduled_out_tm, reg
FROM flights
GROUP BY flight_date, flight_number, scheduled_out_tm, reg
ORDER BY flight_date, flight_number, scheduled_out_tm, regA helpful article in Experts-Exchange is DISTINCT and GROUP BY... and why does it not work for my query?
HIDE #2 SELECT (aka show) unique columns AND one or more of the column values that were duplicated
Pretty easy with GROUP BY as all you'll need to do is add to the SELECT clause another column with an aggregate function such as Min, Max, Sum, Count, Avg, etc.
For example, in the below image the first set returns all 23 rows, but the second set returns 20, the total number of rows based on the four-column primary key we're using. Adding Max(entered_dt) as most_recently_added to the SELECT clause returns only the value across duplcate rows that has the maximum (most recent with dates) datetime. For flight_date='2014-07-15', flight_number=103, dep='MSP', reg=801, there are two rows in the first set (grey background), but only the most recent entered_dt is returned (black arrows).
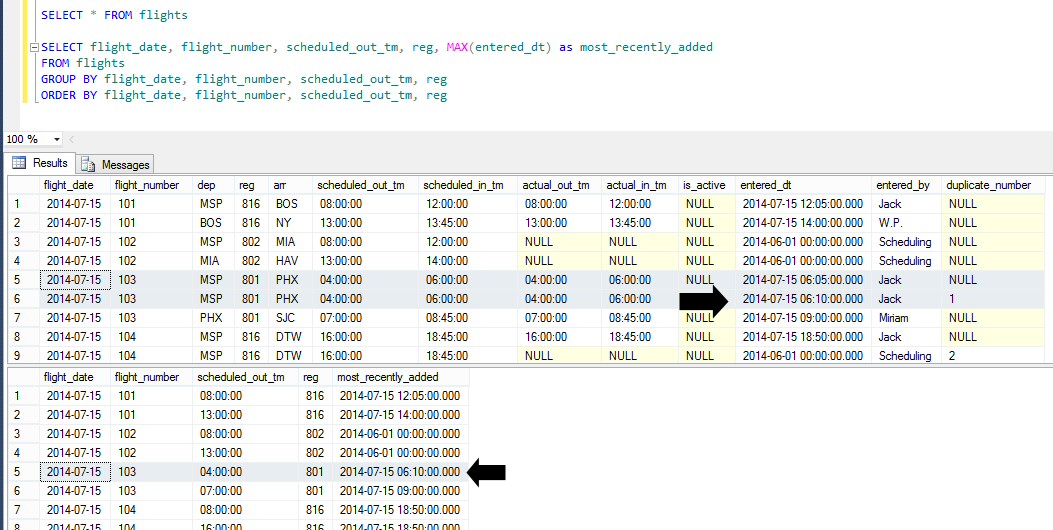
Another helpful article in Experts-Exchange is SQL Server GROUP BY Solutions.
SHOW #1 SELECT (aka show) the duplicates
This query uses the HAVING clause, which is essentially a WHERE clause on an aggregate amount, such as 'Give me all the professional athletes that made over $100 million in their lifetimes')
SELECT flight_date, flight_number, dep, reg
FROM flights
GROUP BY flight_date, flight_number, dep, reg
HAVING COUNT(*) > 1This query uses a Common Table Expression to group (PARTITION BY) rank all of the rows by the primary key columns, and then sort (ORDER BY) by the entered_dt. The query below it then selects all of the rows where the rank number is greater than 1, i.e. duplicates.
;WITH a as (
SELECT flight_date, flight_number, dep, reg,
row_number() OVER (PARTITION BY flight_date, flight_number, dep, reg ORDER BY entered_dt) as row_number
FROM flights
)
SELECT * FROM a WHERE row_number > 1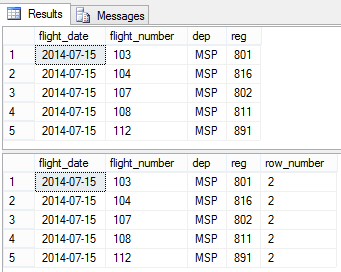
DELETE #1 HARD DELETE all duplicate rows from the table
To handle this based on a condition you'll have to
- Rank order the column that's being duplicated for every instance of the grouped columns (1, 2, 3, ..)
- Also, since the business wants to see actual flights in place of scheduled, ISNULL(actual_out_tm, '23:59:59') is used in the ORDER BY.
- Delete the rows where rank_order > 1
;with a as (
SELECT flight_date, flight_number, dep, reg,
row_number() OVER (partition by flight_date, flight_number, dep, reg ORDER BY ISNULL(actual_out_tm, '23:59:59'), entered_dt) as row_number
FROM flights
)
DELETE FROM a WHERE row_number > 1Note: If your situation deals with duplicates for all columns, hence no sorting/ORDER BY fits your situation, then use ORDER BY (SELECT NULL) in place of the above ORDER BY clause.
To handle this not based on a condition, i.e. 'just delete all except one, I don't care which', then change the ORDER BY ISNULL(actual_out_tm, '23:59:59') line to ORDER BY (SELECT NULL)).
DELETE #2 SOFT DELETE all duplicate rows by updating an is_active column.
A 'soft delete' is when the row is not actually deleted, but there is a column that shows whether the column is considered active or not. Companies will have multiple reasons for deleting this way that deal with preserving the history of the row, such as Customers that change addresses and policy holders where the policy changes.
-- Set all is_active values to 'Y' (just for the demo)
UPDATE flights
SET is_active='Y'
GO
-- Now set all duplicate rows is_active='N'
;with f as (
SELECT *,
row_number() over(partition by flight_date, flight_number, scheduled_out_tm, reg order by ISNULL(actual_out_tm, '23:59:59'), entered_dt) as row_number
FROM flights
)
UPDATE f
SET is_active='N'
WHERE row_number > 1and here's the return set
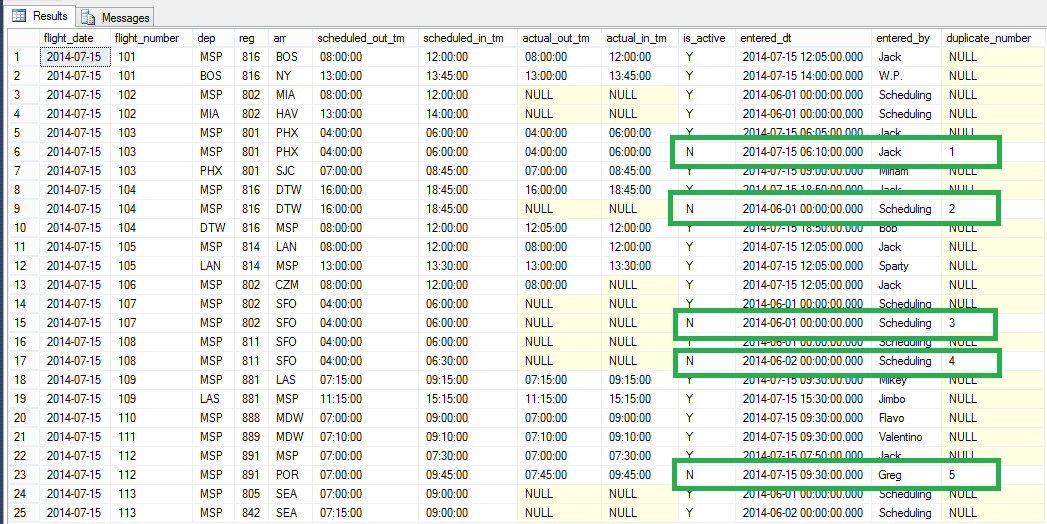
Extra Stuff on DELETE #1 How to test your DELETE statement using a transaction
A word of caution ... if your requirement is to delete duplicate rows from a production table, YOU'RE PLAYING WITH FIRE!!! One delete without a WHERE clause and the entire table contents are deleted. So GOOD GOD MAKE A BACKUP FIRST. Then, you can use a transaction rolled back to view the delete action BEFORE IT IS ACTUALLY DELETED, then you can run multiple times to insure that the delete is correct, then you can make the permanent delete with a commit.
BEGIN TRAN tr
BEGIN TRY
-- Delete query goes here
SELECT CAST(@@ROWCOUNT as varchar(max)) + ' rows were deleted'
-- Show the rowcount post-delete
SELECT 'After the delete there are ' + CAST(COUNT(*) as varchar(max)) + ' rows in table flights.'
FROM flights
-- Show the table post-delete
SELECT * FROM flights
-- VERY IMPORTANT! If you don't want to actually save the delete, ROLLBACK goes here.
-- If you do want to save then COMMIT goes here.
ROLLBACK TRAN TR
END TRY
BEGIN CATCH
SELECT @@ERROR
ROLLBACK TRAN TR
END CATCH
ENDExtra Stuff on DELETE #2 How to back up what was just deleted into another table
Often it's helpful to save the rows deleted into another table, just for quick reference in case you need to do anything with those rows later. The quickest way I've found to do this is two steps...
Step 1 Create the 'temp' table to store deleted rows.
- The z_ prefix insures that the table will sort in SSMS to the bottom, and 20140907 = '2014-09-07'. Use whatever naming convention floats your boat.
- btw 1 will never equal 0, this is just a quick way to create the table without spelling out the schema, or inserting any rows.
SELECT * INTO z_flights_backup_20140907 FROM flights WHERE 1=0Step 2 Perform the delete. Same code as previous, but the OUTPUT in the 2nd line inserts the deleted rows from flights INTO z_flights_backup_20140907.
DELETE f
OUTPUT DELETED.* INTO z_flights_backup_20140907
FROM flights f
JOIN (
SELECT a.flight_date, a.flight_number, a.dep, reg, a.entered_dt, a.rank_order
FROM (
SELECT flight_date, flight_number, dep, reg, entered_dt, RANK() OVER (PARTITION BY flight_date, flight_number, dep, reg ORDER BY entered_dt DESC) as rank_order
FROM flights) a
WHERE rank_order > 1 ) del
-- JOIN on the key columns
ON del.flight_date = f.flight_date AND del.flight_number = f.flight_number AND del.dep = f.dep AND del.reg = f.reg
-- and the non-key column used to define duplicates
AND del.entered_dt = f.entered_dtThe end. Good luck. Thank you for reading my article, feel free to leave me some feedback regarding the content or to recommend future work. If you liked this article please click on the big green 'Vote' button near the bottom of the page.
I look forward to hearing from you. - Jim Horn ( LinkedIn ) ( Twitter )
Microsoft SQL Server database developer, architect, and author specializing in Business Intelligence, ETL, and Data Warehousing.
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (0)