Analytical SQL : Where do you rank?


Father, husband and general problem solver who loves coding SQL, C#, Salesforce Apex or whatever.
Published:
Browse All Articles > Analytical SQL : Where do you rank?
"Top 10 customers by salesperson" sound familiar? Yes! I would expect so, and am sure there are a number of other great business analyses with a similar principle now flowing through your mind.
So, how do you query this data in your SQL system?
No answer; no worries! This article aims to answer that question for you. As the title suggests, this comes down to knowing a customer's rank with respect to other customers for a given salesperson and then selecting just those customers with a rank no greater than 10.
Presuming you already have SQL knowledge, we will go through the different methods to getting this rank and subsequently selecting our data by it in various database systems. To this end, you will find the article organized as follows to ease the navigation to the content most pertinent to your environment.
The following attachments are a set of SQL scripts to create the table structure and data we will be working with throughout this article.
MS SQL:
rankdata.sql.txt
MySQL:
rnkmysql.sql.txt
Oracle:
rankora.sql.txt
And to include our MS Access friends:
rankmdb.zip
For those comfortable in just running the script (appropriate to your environment) and understand the structure to be used in this article's queries, you can grab the file you need and move on to the next section, otherwise, I will go through briefly the table design and sample of data.
Important: If you already have a table in your system called "bookings", please change ALL references to the name "bookings" in the following SQL statements.
1. MySQL DDL to create table.
2. Sampling of data.
We'll see more of the data in action soon enough, so let's move on shall we...
We will be using a simple example of top 10 customers by salesperson. This will be determined by highest sales volume ("bk_amount") first, highest quantity booked ("bk_quantity") second, and, lastly, the newest order date ("bk_date") if duplicate sales dollars and units are encountered.
MS Access, MS SQL, MySQL, and Oracle:
![Rank by Derived Table Results]() Results are exactly what we needed in this case, but one thing to note is that this method is more of a dense ranking: if we had two customers with the same amount of dollars and units booked on the same exact date, then they would both get the same rank.
Results are exactly what we needed in this case, but one thing to note is that this method is more of a dense ranking: if we had two customers with the same amount of dollars and units booked on the same exact date, then they would both get the same rank.
Furthermore, we have to use a derived table which then uses a sub query to get ranking per record. I think you can see how the maintainability can get out of hand.
Let's keep moving...
Being the above is very inefficient in complex cases, it is fortunate that MS SQL 2005+ and Oracle both offer great tools for handling ranking.
The following four functions all utilize the OVER() clause which takes the following form:
(MS SQL shown, please see Oracle link for differences)
1. Row_Number() function.
Per my note above regarding our previous solution being a "dense rank", you will see that what works best for top n selections by some grouping is the row_number() function which will give a distinct 1-n ordering of records.
Our new code:
![Rank with Analytical Functions Results]() View as spreadsheet :
View as spreadsheet :
rank-funcs-results.xls
So we replaced the derived table with a WITH clause here, so no real change there; however, notice we no longer have a sub query with a long where filter. The over() analytical clause that accompanies row_number() function takes care of our logic very straight-forward: we partition (group by) a salesperson; get our highest amounts first; get our highest quantities first within matching amounts; get newest date within matching quantities. Hopefully that sounds very familiar as that was our requirement.
For your reference, the other three functions, including ntile() not yet mentioned, also work in both MS SQL and Oracle and look something like this...
2. Rank() function.
3. Dense_Rank() function.
Both of the above will give you duplicate ranks for duplicate values. The key difference between the two is that rank() keeps track of the number of rows that are duplicated while dense_rank() does not. In other words, rank() will return five rows with rank of 1 and then a row or rows with rank of 6; however, dense_rank() will return the 6th and subsequent matching rows with a rank of 2, meaning second highest ranking.
4. NTile(x) function.
(where x is numerical value representing the number of groups the data is split into)
![NTile Results (Top 10 %)]()
As discussed in the Flexibility at a Price article, we shouldn't try to force the use of row_number(), rank(), or dense_rank() for all cases, but we truly have a good fit scenario here and I would highly recommend this approach when applicable.
For more details on these analytical or ranking functions, please see the references below specific to your SQL platform.
Now, what about MS Access and MySQL?
MS Access readers, sorry I don't have a lot more for you. The "universal" approach shown in the "Everyone Ranks The Same!" section is pretty much the pure SQL approach available in Access to my knowledge.
Using DCount, however, we can eliminate at least the need for the sub query, but introduces a little VB syntax to our SQL.
![Rank with Dcount Results]()
For MS Access I would recommend you stay with the sub query approach or go to full VBA for better control (maintainability) of complex ranking filters similar to what we started with. However, I would consider the DCount() methodology very useful in simple cases such as shown above with one partitioning filter (by salesperson) and one ranking one (by amount).
And last but not least...
For MySQL, the following options provide close likenesses to the row_number() function.
1. Group_Concat() and Find_In_Set(): a great combination.
Group_Concat(), roughly, handles the same duties as the over() clause. To best illustrate this point, take a look at the syntax for Group_Concat() to partition by a salesperson and order the associated customers by amount, quantity, and date as we did above.
![Group_Concat() Results]() Technically, what you are seeing is a BLOB (en.wikipedia.org/wiki/Bina
Technically, what you are seeing is a BLOB (en.wikipedia.org/wiki/Binary_large_object ) containing all the customers grouped under a given salesperson. Therefore, this is very powerful, but, potentially, inefficient if improperly used.
For our ranking needs, let's move forward with the understanding the benefit outweighs the consequences here...
Find_In_Set(), as Angel Eyes discusses in "delimited list as parameter, what are the options?", works well for parsing a comma delimited list and so when coupled with our Group_Concat() results acts as the row_number() function.
So putting the code together:
Any questions, please refer to the reference "Emulating Analytic (AKA Ranking) Functions with MySQL". If you still would like to learn more, please leave me a comment below, but onward we shall march...
2. RowNum Adaptation.
Another interesting method I will demonstrate below was adapted from my reading of "Displaying Row Number (rownum) in MySQL" which was just meant to be a brief blog on displaying row number on a result set.
Since the row_number() portion is covered for us already, the trick is simply to compose a good over() equivalent. My approach, is to add another variable for the "partition by" portion of over() which I called "lastsalesperson".
Clear ?
Let's look at some code that should help:
Personally I have found this more efficient (or at least faster) in a number of cases, but each scenario as we have been saying throughout should be considered careful before just implementing one blanket approach across the board.
That as they say is all folks!
Hopefully you now know where your SQL ranks in the world of analytical functions and know when to pull these handy statements out of the toolbox. Additionally, if nothing else, please take away that for the best blend of power and performance, make sure to utilize the tools available to you such as EXPLAIN to determine the query and function set with which you will get the best execution plan and/or where indexing may need to be tweaked to aid you in your task(s) of keeping your data in rank.
Lastly, with MS Access 2007, MS SQL 2005, MySQL 5.0.x, and Oracle 10g installed and used in testing, I would love to hear your feedback if I missed something from your environment that I will be sure to update accordingly.
Thanks for reading!
Happy coding!
Best regards,
Kevin (aka MWVisa1)
Related Resources / References:
(Referred to for FIND_IN_SET(); however, this is a general database resource)
delimited list as parameter, what are the options?
https://www.experts-exchange.com/A_1536.html
MS Access
Rank (Sub Query Methodology)
ACC2.0-97 > http://support.microsoft.com/kb/120608/en-us
ACC2000+ > http://support.microsoft.com/kb/208946
MS SQL
Ranking Functions in MS SQL
http://msdn.microsoft.com/en-us/library/ms189798(SQL.90).aspx
ROW_NUMBER(), RANK(), and DENSE_RANK() Flexibility at a Price
http://thehobt.blogspot.com/2009/02/rownumber-rank-and-denserank.html
MySQL
Emulating Analytic (AKA Ranking) Functions with MySQL
http://onlamp.com/pub/a/mysql/2007/03/29/emulating-analytic-aka-ranking-functions-with-mysql.html
Displaying Row Number (rownum) in MySQL
http://jimlife.wordpress.com/2008/09/09/displaying-row-number-rownum-in-mysql/
Database Developers' Quick-Reference to MySQL
https://www.experts-exchange.com/A_659.html
Database Developers' Quick-Reference to MySQL DDL
https://www.experts-exchange.com/A_1522.html
Oracle
Analytical (Ranking) Functions in Oracle
http://download.oracle.com/docs/cd/A87860_01/doc/server.817/a76994/analysis.htm#13275
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
If you found this article helpful, please click the Yes button after the question just below. This will give me (the author) a few points and might encourage me to write more articles.
If you didn't or otherwise feel the need to vote No, please first leave a comment to give me a chance to answer and perhaps to improve this article.
Thank you!
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
So, how do you query this data in your SQL system?
No answer; no worries! This article aims to answer that question for you. As the title suggests, this comes down to knowing a customer's rank with respect to other customers for a given salesperson and then selecting just those customers with a rank no greater than 10.
Presuming you already have SQL knowledge, we will go through the different methods to getting this rank and subsequently selecting our data by it in various database systems. To this end, you will find the article organized as follows to ease the navigation to the content most pertinent to your environment.
The Data.
Everyone Ranks The Same!
MS SQL and Oracle Move Up The Ranks!
MS Access Dense to Ranking.
MySQL Emulates The Best of Them.
1. The Test Data.
The following attachments are a set of SQL scripts to create the table structure and data we will be working with throughout this article.
MS SQL:
rankdata.sql.txt
MySQL:
rnkmysql.sql.txt
Oracle:
rankora.sql.txt
And to include our MS Access friends:
rankmdb.zip
For those comfortable in just running the script (appropriate to your environment) and understand the structure to be used in this article's queries, you can grab the file you need and move on to the next section, otherwise, I will go through briefly the table design and sample of data.
Important: If you already have a table in your system called "bookings", please change ALL references to the name "bookings" in the following SQL statements.
1. MySQL DDL to create table.
create table if not exists bookings (
bk_id integer auto_increment primary key ,
bk_date datetime ,
bk_quantity integer ,
bk_amount decimal(19,4) ,
bk_salesperson varchar(50) ,
bk_customer varchar(10)
)
;2. Sampling of data.
insert into bookings( bk_date, bk_quantity, bk_amount, bk_salesperson, bk_customer )
select '20090928', 3, 56.0960, 'mark_wills', 'C543423'
union all select '20091003', 9, 220.8000, 'mwvisa1', 'C1234318'
union all select '20091008', 14, 364.4800, 'chapmandew', 'C89086'
union all select '20090928', 18, 627.6896, 'chapmandew', 'C101160'
union all select '20091002', 23, 790.2400, 'aneeshattingal', 'C123796'
union all select '20090930', 120, 4187.6480, 'angeliii', 'C123419'
union all select '20091010', 11, 276.0000, 'mwvisa1', 'C1234595'
union all select '20091007', 23, 784.6120, 'chapmandew', 'C1011923'
union all select '20091007', 8, 187.6480, 'angeliii', 'C123275'
union all select '20090910', 36, 1234.5000, 'aneeshattingal', 'C1234465'
union all select '20090912', 353, 12345.0000, 'angeliii', 'C1234300'
union all select '20090917', 163, 5690.5000, 'chapmandew', 'C543497'
union all select '20090909', 4, 87.6500, 'mark_wills', 'C543937'
union all select '20090914', 9, 234.7500, 'aneeshattingal', 'C123206'
union all select '20090908', 3, 69.5000, 'chapmandew', 'C890141'
union all select '20090913', 5, 123.4563, 'mark_wills', 'C101132'
union all select '20090917', 84, 2931.2500, 'angeliii', 'C1234754'
union all select '20090914', 5, 109.5625, 'angeliii', 'C543382'
union all select '20090915', 21, 711.8750, 'chapmandew', 'C890979'
union all select '20090923', 12, 300.1600, 'aneeshattingal', 'C12319'
union all select '20090923', 12, 300.1600, 'aneeshattingal', 'C123481'
union all select '20090924', 56, 1929.0000, 'angeliii', 'C104742'
union all select '20090916', 240, 8375.2960, 'angeliii', 'C123646'
;We'll see more of the data in action soon enough, so let's move on shall we...
2. Everyone Ranks The Same!
We will be using a simple example of top 10 customers by salesperson. This will be determined by highest sales volume ("bk_amount") first, highest quantity booked ("bk_quantity") second, and, lastly, the newest order date ("bk_date") if duplicate sales dollars and units are encountered.
MS Access, MS SQL, MySQL, and Oracle:
select bks.*
from (
select bk_salesperson as salesperson,
bk_customer as customer,
bk_amount as sales,
bk_quantity as units,
(select count(*) from bookings b2
where b2.bk_salesperson = b1.bk_salesperson
and (b2.bk_amount > b1.bk_amount
or (b2.bk_amount = b1.bk_amount
and (b2.bk_quantity > b1.bk_quantity
or (b2.bk_quantity = b1.bk_quantity
and b2.bk_date > b1.bk_date)
)
))
) + 1 as ranking
from bookings b1
) bks
where ranking <= 10
order by salesperson, ranking
;Furthermore, we have to use a derived table which then uses a sub query to get ranking per record. I think you can see how the maintainability can get out of hand.
Let's keep moving...
3. MS SQL and Oracle Move Up The Ranks!
Being the above is very inefficient in complex cases, it is fortunate that MS SQL 2005+ and Oracle both offer great tools for handling ranking.
The following four functions all utilize the OVER() clause which takes the following form:
(MS SQL shown, please see Oracle link for differences)
OVER ( [ PARTITION BY value_expression , ... [ n ] ]
<ORDER BY_Clause> )1. Row_Number() function.
Per my note above regarding our previous solution being a "dense rank", you will see that what works best for top n selections by some grouping is the row_number() function which will give a distinct 1-n ordering of records.
Our new code:
with bks_ranked
as
(
select bk_salesperson as salesperson,
bk_customer as customer,
bk_amount as sales,
bk_quantity as units,
row_number()
over (partition by bk_salesperson
order by bk_amount desc,
bk_quantity desc,
bk_date desc) ranking
from bookings
)
select *
from bks_ranked
where ranking <= 10
order by salesperson, ranking
;rank-funcs-results.xls
So we replaced the derived table with a WITH clause here, so no real change there; however, notice we no longer have a sub query with a long where filter. The over() analytical clause that accompanies row_number() function takes care of our logic very straight-forward: we partition (group by) a salesperson; get our highest amounts first; get our highest quantities first within matching amounts; get newest date within matching quantities. Hopefully that sounds very familiar as that was our requirement.
For your reference, the other three functions, including ntile() not yet mentioned, also work in both MS SQL and Oracle and look something like this...
2. Rank() function.
rank()
over (partition by bk_salesperson
order by bk_amount desc,
bk_quantity desc,
bk_customer) ranking3. Dense_Rank() function.
dense_rank()
over (partition by bk_salesperson
order by bk_amount desc,
bk_quantity desc,
bk_customer) rankingBoth of the above will give you duplicate ranks for duplicate values. The key difference between the two is that rank() keeps track of the number of rows that are duplicated while dense_rank() does not. In other words, rank() will return five rows with rank of 1 and then a row or rows with rank of 6; however, dense_rank() will return the 6th and subsequent matching rows with a rank of 2, meaning second highest ranking.
4. NTile(x) function.
(where x is numerical value representing the number of groups the data is split into)
ntile(10)
over (partition by bk_salesperson
order by bk_amount desc,
bk_quantity desc,
bk_customer) ranking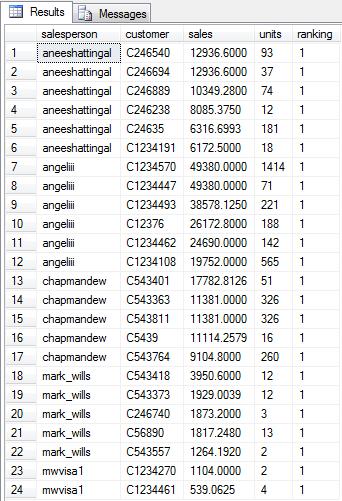
As discussed in the Flexibility at a Price article, we shouldn't try to force the use of row_number(), rank(), or dense_rank() for all cases, but we truly have a good fit scenario here and I would highly recommend this approach when applicable.
For more details on these analytical or ranking functions, please see the references below specific to your SQL platform.
Now, what about MS Access and MySQL?
4. MS Access Dense to Ranking.
MS Access readers, sorry I don't have a lot more for you. The "universal" approach shown in the "Everyone Ranks The Same!" section is pretty much the pure SQL approach available in Access to my knowledge.
Using DCount, however, we can eliminate at least the need for the sub query, but introduces a little VB syntax to our SQL.
SELECT bks.*
FROM (
SELECT bk_salesperson AS salesperson,
bk_customer AS customer,
bk_amount AS sales,
bk_quantity AS units,
dcount("*","bookings",
"bk_salesperson = """ &
b1.bk_salesperson & """ and bk_amount > " &
b1.bk_amount)+1 AS ranking
FROM bookings AS b1
) AS bks
WHERE ranking<=10
ORDER BY salesperson, ranking
;For MS Access I would recommend you stay with the sub query approach or go to full VBA for better control (maintainability) of complex ranking filters similar to what we started with. However, I would consider the DCount() methodology very useful in simple cases such as shown above with one partitioning filter (by salesperson) and one ranking one (by amount).
And last but not least...
5. MySQL Emulates The Best of Them.
For MySQL, the following options provide close likenesses to the row_number() function.
1. Group_Concat() and Find_In_Set(): a great combination.
Group_Concat(), roughly, handles the same duties as the over() clause. To best illustrate this point, take a look at the syntax for Group_Concat() to partition by a salesperson and order the associated customers by amount, quantity, and date as we did above.
select bk_salesperson as salesperson,
group_concat(bk_customer
order by bk_amount desc,
bk_quantity desc,
bk_date desc) as customers
from bookings
group by bk_salesperson
; Technically, what you are seeing is a BLOB (en.wikipedia.org/wiki/Bina
Technically, what you are seeing is a BLOB (en.wikipedia.org/wiki/BinaFor our ranking needs, let's move forward with the understanding the benefit outweighs the consequences here...
Find_In_Set(), as Angel Eyes discusses in "delimited list as parameter, what are the options?", works well for parsing a comma delimited list and so when coupled with our Group_Concat() results acts as the row_number() function.
So putting the code together:
select bk_salesperson as salesperson,
bk_customer as customer,
bk_amount as sales,
bk_quantity as units,
find_in_set(b.bk_customer, customers) as ranking
from bookings b
inner join (
select bk_salesperson as salesperson,
group_concat(bk_customer
order by bk_amount desc,
bk_quantity desc,
bk_date desc) as customers
from bookings
group by bk_salesperson
) p on p.salesperson = b.bk_salesperson
where find_in_set(b.bk_customer, customers) <= 10
order by salesperson, ranking
;Any questions, please refer to the reference "Emulating Analytic (AKA Ranking) Functions with MySQL". If you still would like to learn more, please leave me a comment below, but onward we shall march...
2. RowNum Adaptation.
Another interesting method I will demonstrate below was adapted from my reading of "Displaying Row Number (rownum) in MySQL" which was just meant to be a brief blog on displaying row number on a result set.
Since the row_number() portion is covered for us already, the trick is simply to compose a good over() equivalent. My approach, is to add another variable for the "partition by" portion of over() which I called "lastsalesperson".
(select @rownum:=0, @lastsalesperson:=null) rClear ?
Let's look at some code that should help:
select salesperson, customer, sales, units, ranking
from (
select bk_customer as customer,
bk_amount as sales,
bk_quantity as units,
/* if salesperson is same as row above,
increment row number; else, start at 1. */
if(bk_salesperson = @lastsalesperson,
@rownum:=@rownum+1,
@rownum:=1) as ranking,
/* since using @lastsalesperson in @rownum,
have to set @lastsalesperson 2nd;
otherwise, current and last would always equal.
*/
@lastsalesperson:=bk_salesperson as salesperson
from bookings b,
(select @rownum:=0, @lastsalesperson:=null) r
order by bk_salesperson,
bk_amount desc,
bk_quantity desc,
bk_date desc
) bks
where ranking <= 10
order by salesperson, ranking
;Personally I have found this more efficient (or at least faster) in a number of cases, but each scenario as we have been saying throughout should be considered careful before just implementing one blanket approach across the board.
That as they say is all folks!
Hopefully you now know where your SQL ranks in the world of analytical functions and know when to pull these handy statements out of the toolbox. Additionally, if nothing else, please take away that for the best blend of power and performance, make sure to utilize the tools available to you such as EXPLAIN to determine the query and function set with which you will get the best execution plan and/or where indexing may need to be tweaked to aid you in your task(s) of keeping your data in rank.
Lastly, with MS Access 2007, MS SQL 2005, MySQL 5.0.x, and Oracle 10g installed and used in testing, I would love to hear your feedback if I missed something from your environment that I will be sure to update accordingly.
Thanks for reading!
Happy coding!
Best regards,
Kevin (aka MWVisa1)
Related Resources / References:
(Referred to for FIND_IN_SET(); however, this is a general database resource)
delimited list as parameter, what are the options?
https://www.experts-exchange.com/A_1536.html
MS Access
Rank (Sub Query Methodology)
ACC2.0-97 > http://support.microsoft.com/kb/120608/en-us
ACC2000+ > http://support.microsoft.com/kb/208946
MS SQL
Ranking Functions in MS SQL
http://msdn.microsoft.com/en-us/library/ms189798(SQL.90).aspx
ROW_NUMBER(), RANK(), and DENSE_RANK() Flexibility at a Price
http://thehobt.blogspot.com/2009/02/rownumber-rank-and-denserank.html
MySQL
Emulating Analytic (AKA Ranking) Functions with MySQL
http://onlamp.com/pub/a/mysql/2007/03/29/emulating-analytic-aka-ranking-functions-with-mysql.html
Displaying Row Number (rownum) in MySQL
http://jimlife.wordpress.com/2008/09/09/displaying-row-number-rownum-in-mysql/
Database Developers' Quick-Reference to MySQL
https://www.experts-exchange.com/A_659.html
Database Developers' Quick-Reference to MySQL DDL
https://www.experts-exchange.com/A_1522.html
Oracle
Analytical (Ranking) Functions in Oracle
http://download.oracle.com/docs/cd/A87860_01/doc/server.817/a76994/analysis.htm#13275
=-=-=-=-=-=-=-=-=-=-=-=-=-
If you found this article helpful, please click the Yes button after the question just below. This will give me (the author) a few points and might encourage me to write more articles.
If you didn't or otherwise feel the need to vote No, please first leave a comment to give me a chance to answer and perhaps to improve this article.
Thank you!
=-=-=-=-=-=-=-=-=-=-=-=-=-
Father, husband and general problem solver who loves coding SQL, C#, Salesforce Apex or whatever.
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (14)
Author
Commented:Thank you for the kind words and the vote.
Respectfully yours,
Kevin
Author
Commented:Dlookup and the Domain Functions
https://www.experts-exchange.com/A_12.html
Access Techniques: Fast Table Lookup Functions
https://www.experts-exchange.com/A_1921.html
Access & VB's Missing Domain Lookup Functions
https://www.experts-exchange.com/A_2011.html
Additionally, to further stimulate your brain cells and see Dlookup() in action, see:
Computing row-wise aggregations in Access
https://www.experts-exchange.com/A_1775.html
Probably some other very good ones about you can find, just wanted to add these for your convenience.
Thanks again for reading and for the support from those who have/will vote this helpful.
Respectfully yours,
Kevin
Commented:
Author
Commented:Commented:
View More