Parsing Names in MS Office, Visual Basic 6, and Visual Basic for Applications


Published:
Browse All Articles > Parsing Names in MS Office, Visual Basic 6, and Visual Basic for Applications
By Patrick Matthews
Any time you have to store or process people's names, best practice dictates that you maintain each "name part", e.g., title, first name, middle name, last/surname, and/or suffix, as a discrete piece of information:
Doing so enables fast and efficient searches, and also enables atomicity.
However, you may have to work with a data set that did not adhere to these best practice guidelines, and thus you may be struggling with parsing the resulting "full name" strings to extract the various name parts.
This article will demonstrate some of the challenges inherent to parsing peoples names, provide a look at some techniques for parsing simple names in Excel, Access, Visual Basic 6 (VB6), and Visual Basic for Applications (VBA).
This article also includes the source code for two user defined functions, GetNamePart and GetAllNameParts, that you may use to parse peoples name, providing greater flexibility and ease of use than is possible using only native functions.
With apologies to users from other cultures, this article will focus on names as they typically occur in English-speaking cultures.
A very commonly asked question type on Experts Exchange involves parsing a "full name" string, and extracting from it the "name parts" such as title/honorific, first name, middle name, last name/surname, and suffix.
The following question makes an excellent example:
Similar questions ask for name parsing, but using a slightly different structure:
In either case, while the question is seemingly simple and straightforward, as the next section will show, name parsing can be a very complex matter.
The most common data entry formats for personal names are as follows:
![Name Part Structure]()
In either case, typically the first name and last name are both present, while the title, middle name, and/or suffixes are optional.
Of course, each name part can itself be somewhat complex:
![Name Part Detail]()
Thus, for each name part:
Taken together, these contingencies can make name parsing a difficult challenge indeed.
Consider relatively simple full names, as in the examples below. In these cases, the parsing task is very easy:
Now consider a slightly more complex situation, but probably a more typical one, in which a middle name/initial may or may not be present:
The Excel expressions become incomprehensible to most users. The Access and VB6/VBA expressions are not quite as complex, but they are already trending upward in complexity. We have not even considered any cases yet with titles and/or suffixes; the expressions needed to deal with names that leave the title, middle name, and/or suffixes optional (and potentially also to deal with compound titles and suffixes) would be excruciating in terms of length and difficulty to read and understand. Add in requirements for gracefully handling consecutive spaces, trimming extraneous spaces from the name parts, and allowing for optional spaces following a comma, and the task becomes close to impossible.
Excel does offer one other potential trick, the Text to Columns feature. However, on complex names, it too may lack the power to do name parsing well:
The graphic below demonstrates some of the difficulties involved in using Text to Columns. Note especially how the surname shows up in the first column of the transfrmed data, as expected, but how we cannot depend on any of the other name parts to show up predictably in certain columns.
![Name Part Text to Columns]()
Real-life data is complicated. Successful name parsing functions or expressions should be able to handle all of the following examples gracefully:
At this point it should be clear that relying on native functions alone will suffice only for the very simplest names we might encounter.
[b]The GetNamePart and GetAllNameParts user defined functions, described in the next section, are able to parse all of the full names above.[/b]
The GetNamePart and GetAllNameParts user defined functions are a flexible means for parsing full names to extract titles, first names, middle names, last/surnames, and/or suffixes.
GetNamePart and GetAllNameParts will work with both of the typical name orders, i.e., First Middle Last and Last, First Middle. However, you will not be able to mix the two name orders in the same data set, as the name order is one of the inputs into the functions.
GetNamePart and GetAllNameParts also gracefully handle compound titles and suffixes. Compound first, middle, and/or last names can still be problematic, however.
You can use GetNamePart in any VB6/VBA project, or directly in an Excel worksheet formula or Access query. GetAllNameParts, because it returns a Dictionary object, can be used in any VB6/VBA project, but cannot be used directly in an Excel worksheet formula or Access query.
Here is the source code for GetNamePart and GetAllNameParts:
GetNamePart takes four arguments:
Valid values for the NamePart argument are as follows, and are not case sensitive:
GetAllNameParts takes three arguments:
Please note the following (both functions):
If you are using True (or omitting) for FirstMiddleLast:
If you are using False for FirstMiddleLast:
Special note: the master lists for titles and suffixes can get quite long, and thus some users may want to explore the possibility of storing these items in an external text file, a database table, or some other data management structure/service. Such an improvement is beyond the scope of this article, however.
To implement the GetNamePart function in your projects for VB6 or VBA (using Excel, Access, or any other program that uses VBA) application, please do the following:
Please note that, due to the difficulties in dealing with compound names, you should always spot check the results of the function.
For example, consider the names below, with compound name parts marked by (*):
GetNamePart will struggle with those names, as seen in the results below:
![Name Part Compound]()
In both sample files, in addition to parsing out the various name parts, I also have a "Check" column that uses a simple test to see whether a particular record might be troublesome. For this test, I simply looked for records in which the middle name is found, or for which the extracted last name includes a space, as either condition can signal a compound name that should be verified by a human. I strongly recommend that you do something similar when using this function.
Despite the power and flexibility offered by GetNamePart and GetAllNameParts, you should always assume that the results will have to be audited by a person familiar with the data set and what it will be used for. Therefore, you should always retain a copy of the original data set to aid in the auditing process.
The GetNamePart and GetAllNameParts functions included in this article and in the sample files rely heavily on Regular Expressions to extract the name parts. Please see this article for more information on using Regular Expressions in VB6 and VBA.
This article by Excel MVP Chip Pearson includes a user defined function to parse names, but it is not quite as flexible as the GetNamePart and GetAllNameParts functions provided in this article. That same page also includes some more Excel formulas for parsing names.
For a demonstration of parsing names using the GetNamePart function, please download the sample files included here:
Each file includes examples of parsing names in both the First Middle Last and Last, First Middle structures.
GetNamePart.xls
Parse-Names-Demo.mdb
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
If you liked this article and want to see more from this author, please click here.
If you found this article helpful, please click the Yes button near the:
Was this article helpful?
label that is just below and to the right of this text. Thanks!
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
1. Introduction
Any time you have to store or process people's names, best practice dictates that you maintain each "name part", e.g., title, first name, middle name, last/surname, and/or suffix, as a discrete piece of information:
In a data entry/edit form, there should be different controls for each name part
In an Excel list, each name part should be stored in a different column
In a database table, each name part should be stored in a different column
In a VB6/VBA procedure, each name part should be stored in a different variable (or as different elements in an array, collection, or similar object)
Doing so enables fast and efficient searches, and also enables atomicity.
However, you may have to work with a data set that did not adhere to these best practice guidelines, and thus you may be struggling with parsing the resulting "full name" strings to extract the various name parts.
This article will demonstrate some of the challenges inherent to parsing peoples names, provide a look at some techniques for parsing simple names in Excel, Access, Visual Basic 6 (VB6), and Visual Basic for Applications (VBA).
This article also includes the source code for two user defined functions, GetNamePart and GetAllNameParts, that you may use to parse peoples name, providing greater flexibility and ease of use than is possible using only native functions.
With apologies to users from other cultures, this article will focus on names as they typically occur in English-speaking cultures.
2. What's in a Name? Why Name Parsing Is So Difficult
A very commonly asked question type on Experts Exchange involves parsing a "full name" string, and extracting from it the "name parts" such as title/honorific, first name, middle name, last name/surname, and suffix.
The following question makes an excellent example:
Using an access 2007 database. There is a field 'contact' that has hundreds of names in it. There are many formats:
Mr. FirstName LastName
Mrs. FirstName LastName
FirstName LastName
FirstName LastName-LastName2
FirstName LastName LastName2 Jr/Sr
I want to automatically get them into 2 columns: firstname, lastname
First, I am going to strip out ALL Mr., Mrs., Ms. to make it simple. So I know the first token is FirstName and the REST is LastName.
How can I accomplish this?
Similar questions ask for name parsing, but using a slightly different structure:
I have a column in Excel that shows a full name, in the following format:
Lastname, Firstname Middlename
Some entries may have titles and/or suffixes as well:
Lastname <Suffix>, <Title> Firstname Middlename
Please help me extract the Title, First Name, Middle Name, Last Name, and Suffix into separate columns.
In either case, while the question is seemingly simple and straightforward, as the next section will show, name parsing can be a very complex matter.
The most common data entry formats for personal names are as follows:
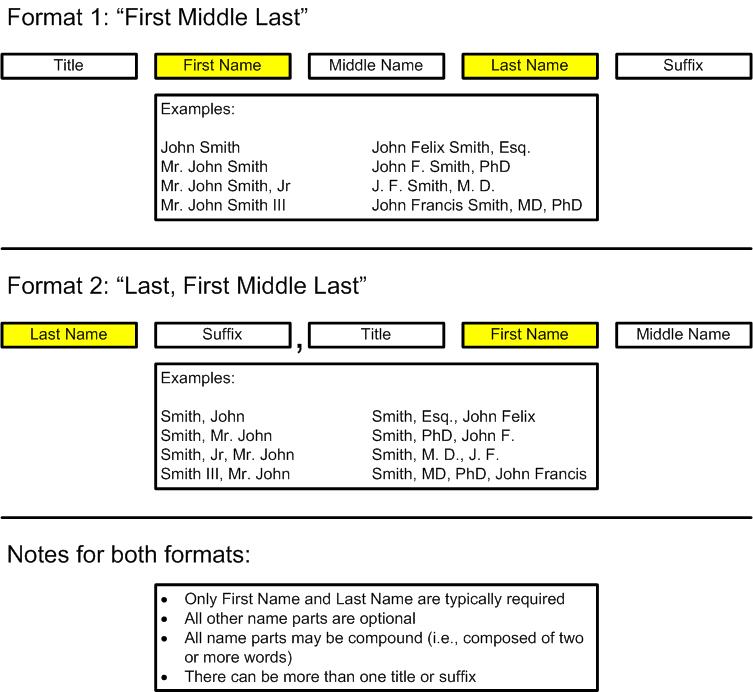
In either case, typically the first name and last name are both present, while the title, middle name, and/or suffixes are optional.
Of course, each name part can itself be somewhat complex:
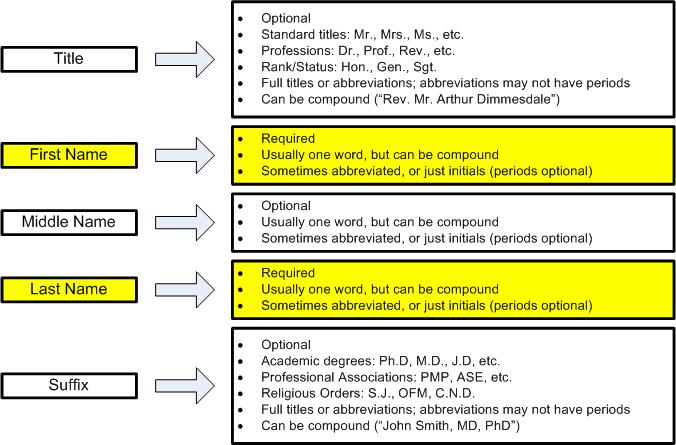
Thus, for each name part:
The name part may or may not appear, as in the case of titles, middle names, and suffixes
The name part may be a single word or be compound (more than one word, as in "Joe Bob" in "Joe Bob Briggs", "Ronald Reuel" in "John Ronald Reuel Tolkien", or "de la Renta" in "Oscar de la Renta"). In addition, there may be more than one title and/or suffix in a single full name
Name parts may be abbreviated, sometimes but always with a period
Name parts may be hyphenated
Taken together, these contingencies can make name parsing a difficult challenge indeed.
3. Parsing a Name Using Native Excel, Access, and VB6/VBA Functions
Consider relatively simple full names, as in the examples below. In these cases, the parsing task is very easy:
Full Name: John Smith
Assumption: Space delimits first and last names
Excel (full name in A1)
------------------------------------------
First Name: =LEFT(A1,FIND(" ",A1)-1)
Last Name: =MID(A1,FIND(" ",A1)+1,LEN(A1))
Access (full name in column FullName)
------------------------------------------
First Name: Left([FullName], InStr(1, [FullName], " ") - 1)
Last Name: Mid([FullName], InStr(1, [FullName], " ") + 1)
VB6/VBA (full name in variable FullName)
------------------------------------------
First Name: Left(FullName, InStr(1, FullName, " ") - 1)
Last Name: Mid(FullName, InStr(1, FullName, " ") + 1)Full Name: Smith, John
Assumption: Comma delimits last and first names
Excel (full name in A1)
------------------------------------------
First Name: =TRIM(MID(A1,FIND(",",A1)+1,LEN(A1)))
Last Name: =LEFT(A1,FIND(",",A1)-1)
Access (full name in column FullName)
------------------------------------------
First Name: =Trim(Mid([FullName], InStr(1, [FullName], ",") + 1))
Last Name: =Left([FullName], InStr(1, [FullName], ",") - 1)
VB6/VBA (full name in variable FullName)
------------------------------------------
First Name: =Trim(Mid(FullName, InStr(1, FullName, ",") + 1))
Last Name: =Left(FullName, InStr(1, FullName, ",") - 1)Now consider a slightly more complex situation, but probably a more typical one, in which a middle name/initial may or may not be present:
Full Name: John James Smith
Assumption: Middle name may or may not be present
Excel (full name in A1)
------------------------------------------
First: =LEFT(A1,FIND(" ",A1)-1)
Middle: =IF(ISERR(MID(A1,FIND(" ",A1)+1,IF(ISERR(FIND(" ",A1,FIND(" ",A1)
+1)),FIND(" ",A1),FIND(" ",A1,FIND(" ",A1)+1))-FIND(" ",A1)-1)),
"",MID(A1,FIND(" ",A1)+1,IF(ISERR(FIND(" ",A1,FIND(" ",A1)+1)),
FIND(" ",A1),FIND(" ",A1,FIND(" ",A1)+1))-FIND(" ",A1)-1))
Last: =RIGHT(A1,LEN(A1)-FIND("*",SUBSTITUTE(A1," ","*",LEN(A1)-
LEN(SUBSTITUTE(A1," ","")))))
Access (full name in column FullName)
------------------------------------------
First: Left([FullName], InStr(1, [FullName], " ") - 1)
Middle: IIf((Len(Replace([FullName], " ", "") - Len([FullName])) > 1,
Mid([FullName], InStr(1, [FullName], " ") + 1,
InStrRev([FullName], " ") - InStr(1, FullName, ",") - 1, "")
Last: Mid([FullName], InStrRev([FullName], " ") + 1)
VB6/VBA (full name in variable FullName)
------------------------------------------
First: Left(FullName, InStr(1, FullName, " ") - 1)
Middle: IIf((Len(Replace(FullName, " ", "") - Len(FullName)) > 1,
Mid(FullName, InStr(1, FullName, " ") + 1,
InStrRev(FullName, " ") - InStr(1, FullName, ",") - 1, "")
Last: Mid(FullName, InStrRev(FullName, " ") + 1)The Excel expressions become incomprehensible to most users. The Access and VB6/VBA expressions are not quite as complex, but they are already trending upward in complexity. We have not even considered any cases yet with titles and/or suffixes; the expressions needed to deal with names that leave the title, middle name, and/or suffixes optional (and potentially also to deal with compound titles and suffixes) would be excruciating in terms of length and difficulty to read and understand. Add in requirements for gracefully handling consecutive spaces, trimming extraneous spaces from the name parts, and allowing for optional spaces following a comma, and the task becomes close to impossible.
Excel does offer one other potential trick, the Text to Columns feature. However, on complex names, it too may lack the power to do name parsing well:
If your data set has entries with "missing" name parts, your output will have a varying number of columns, and not all name parts will be in the same column
There is no way to handle compound name parts
The graphic below demonstrates some of the difficulties involved in using Text to Columns. Note especially how the surname shows up in the first column of the transfrmed data, as expected, but how we cannot depend on any of the other name parts to show up predictably in certain columns.
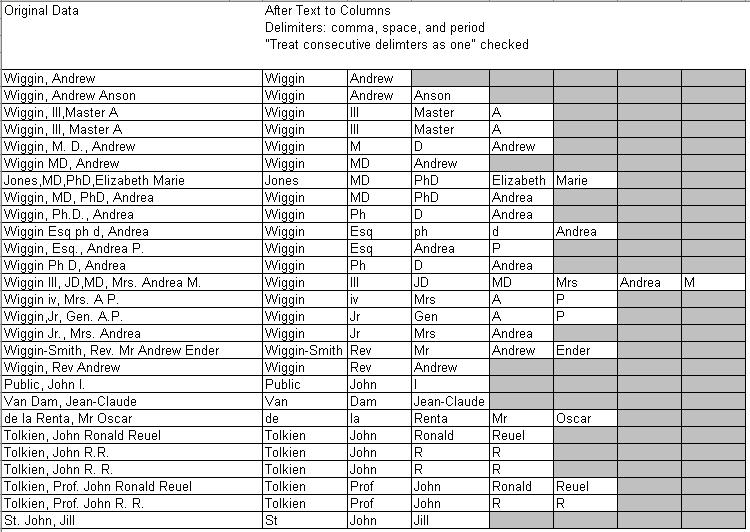
Real-life data is complicated. Successful name parsing functions or expressions should be able to handle all of the following examples gracefully:
First Middle Last | Last, Middle First
-----------------------------------|------------------------------
John Smith | Smith, John
John James Smith | Smith, John James
Dr. John Smith | Smith, Dr. John
Dr John James Smith III | Smith III, Dr John James
Rev. Dr. Martin Luther King, Jr. | King, Jr., Rev. Dr. Martin Luther
Elizabeth Marie Jones, M.D, Ph.D. | Jones, M.D, Ph.D., Elizabeth Marie
Elizabeth Marie Jones,MD,PhD | Jones,MD,PhD,Elizabeth Marie
Nancy Jones-Smythe | Jones-Smythe, NancyAt this point it should be clear that relying on native functions alone will suffice only for the very simplest names we might encounter.
[b]The GetNamePart and GetAllNameParts user defined functions, described in the next section, are able to parse all of the full names above.[/b]
4. GetNamePart and GetAllNameParts User Defined Functions
The GetNamePart and GetAllNameParts user defined functions are a flexible means for parsing full names to extract titles, first names, middle names, last/surnames, and/or suffixes.
GetNamePart returns a specific name part from the full name string
GetAllNameParts returns a Dictionary object with items for all possible name parts in the input string (keys are Title, First, Middle, Last, and Suffix)
GetNamePart and GetAllNameParts will work with both of the typical name orders, i.e., First Middle Last and Last, First Middle. However, you will not be able to mix the two name orders in the same data set, as the name order is one of the inputs into the functions.
GetNamePart and GetAllNameParts also gracefully handle compound titles and suffixes. Compound first, middle, and/or last names can still be problematic, however.
You can use GetNamePart in any VB6/VBA project, or directly in an Excel worksheet formula or Access query. GetAllNameParts, because it returns a Dictionary object, can be used in any VB6/VBA project, but cannot be used directly in an Excel worksheet formula or Access query.
Here is the source code for GetNamePart and GetAllNameParts:
Option Explicit
Function GetNamePart(NameStr As String, NamePart As String, Optional UseMiddle As Boolean = True, _
Optional FirstMiddleLast As Boolean = True)
' Function by Patrick Matthews
' This code may be freely used or distributed so long as you acknowledge authorship and cite the URL
' where you found it
' This function relies on Regular Expressions. For more information on RegExp, please see:
' http://www.experts-exchange.com/articles/Programming/Languages/Visual_Basic/Parsing-Names-in-MS-Office-Visual-Basic-6-and-Visual-Basic-for-Applications.html
' This function parses a name string, and depending on the arguments passed to it it returns a
' title, first name, middle name, surname, or suffix.
' This function can be used in any VBA or VB6 project. It can also be used directly in Excel worksheet
' formulae and in Access queries
' The function takes the following arguments:
'
' 1) NameStr is the full name to be parsed. Its assumed structure is determined by the FirstMiddleLast
' argument
' 2) NamePart indicates the portion of the name you want returned. Valid values (NOT case sensitive):
' Title: "TITLE", "HONORIFIC", "T", "H", "1"
' First: "FIRST NAME", "FIRSTNAME", "FNAME", "F NAME", "FIRST", "F", "FN", "F N", "2"
' Middle: "MIDDLE NAME", "MIDDLENAME", "MNAME", "M NAME", "MIDDLE", "M", "MN", "M N", "3"
' Last: "LAST NAME", "LASTNAME", "LNAME", "L NAME", "LAST", "L", "LN", "L N", "SURNAME", "4"
' Suffix: "SUFFIX", "5"
' 3) UseMiddle indicates whether or not a middle name *might* be present in the NameStr. If True or
' omitted, the function assumes that a middle name *might* be there. If False, it assumes there
' is never a middle name
' 4) FirstMiddleLast indicates the order of the name parts. If True or omitted, the function assumes:
' <Title (optional)> <First name> <Middle Name (optional)> <Surname> <Suffix (optional)>
' If False, the function assumes:
' <Surname> <Suffix (optional)>, <First name> <Middle Name (optional)>
' Notes:
' 1) The function has a prebuilt list of Titles (see GenerateLists function below), which you can modify to
' fit your needs. The Titles string will be embedded in a RegExp Pattern string, so be sure to follow
' proper RegExp Pattern syntax
' 2) The function will recognize compound titles, as long as they are delimited by spaces
' 3) The function has a prebuilt list of Suffixes (see GenerateLists function below), which you can modify to
' fit your needs. The Suffixes string will be embedded in a RegExp Pattern string, so be sure to
' follow proper RegExp Pattern syntax
' 4) The function will recognize compound suffixes, as long as they are delimited by commas and/or spaces
' 5) If you are using True (or omitting) for FirstMiddleLast:
' a) It is always assumed that the first name has a single "word"
' b) It is always assumed that the middle name, if present, has a single "word"
' c) After the function has identfied the title, first name, middle name, and suffix, it assumes that
' whatever is left must be the surname/last name
' d) Thus, this function will process compound first/middle names incorrectly
' 6) If you are using False for FirstMiddleLast:
' a) It is always assumed that the last comma in NameStr delimits the <Surname><Suffix> block
' from the <Title><First name><Middle name> block
' b) Whatever is left in the <Surname><Suffix> block after the suffix has been removed is assumed
' to be the last name
' c) After the Title is removed from the <Title><First name><Middle name> block, if there is only
' one "word", it is the first name. If there are 2+ "words" and UseMiddle = True or omitted,
' then the last word is the middle name, and the rest is the first name
' d) Thus, this function will process compound middle names incorrectly, and may erroneously think
' a compound first name is a first name and a middle name
Dim Title As String
Dim FName As String
Dim MName As String
Dim LName As String
Dim Suffix As String
Dim RegXReturn As Object
Dim NameArr As Variant
Dim Counter As Long
Dim StartsAt As Long
Dim TitleLen As Long
Dim LastComma As Long
Dim Part1 As String
Dim Part2 As String
Static Titles As String
Static Suffixes As String
Static RegX As Object 'holding as a Static variable to improve performance
If Trim(NameStr) = "" Or Trim(NamePart) = "" Then
GetNamePart = ""
Exit Function
End If
If Titles = "" Then Titles = GenerateLists("Titles")
If Suffixes = "" Then Suffixes = GenerateLists("Suffixes")
' remove leading and trailing spaces
NameStr = Trim(NameStr)
' instantiate RegExp if needed (static variable, so it will remain in between calls)
If RegX Is Nothing Then
Set RegX = CreateObject("VBScript.RegExp")
With RegX
.IgnoreCase = True ' case insensitive
.Global = True ' finds all matches, not just first match
End With
End If
' Determine structure of NameStr
If FirstMiddleLast Then
' NameStr is structured <Title (optional)> <First name> <Middle Name (optional)> <Surname> <Suffix (optional)>
' Set Pattern to look for titles at beginning of NameStr
RegX.Pattern = "^(" & Titles & ")\.? +"
' Look for titles. Use Do...Loop to allow for compound suffixes, as in "Rev. Mr. Arthur Dimmesdale"
Do
Set RegXReturn = RegX.Execute(Mid(NameStr, TitleLen + 1))
If RegXReturn.Count > 0 Then
TitleLen = TitleLen + Len(RegXReturn(0))
Else
Exit Do
End If
Loop
' Get Title
Title = Trim(Left(NameStr, TitleLen))
' Adjust NameStr
NameStr = Mid(NameStr, TitleLen + 1)
' Look for suffixes. Use Do...Loop to allow for compound suffixes, as in "Alfred E. Neumann, PhD, Esq."
' StartsAt indicates where the suffix(es) start in the NameStr. Initialize to -1, indicating no suffix
StartsAt = -1
' Set Pattern to look for suffix at end of NameStr
RegX.Pattern = "(, *| +)(" & Suffixes & ")\.?$"
' Evaluate the NameStr. As long as a suffix is found in the portion evaluated, reset the StartsAt variable.
' When no more suffixes are found, terminate the loop
Do
Set RegXReturn = RegX.Execute(Left(NameStr, IIf(StartsAt > -1, StartsAt, Len(NameStr))))
If RegXReturn.Count > 0 Then
StartsAt = RegXReturn(0).FirstIndex ' Recall that FirstIndex starts at position zero, not 1 !!!
Else
Exit Do
End If
Loop
' If a suffix is found, then grab the entire suffix
If StartsAt > -1 Then
Suffix = Mid(NameStr, StartsAt + 1)
' remove comma if applicable
If Left(Suffix, 1) = "," Then Suffix = Mid(Suffix, 2)
' remove possible leading space
Suffix = Trim(Suffix)
' adjust NameStr to remove suffixes
NameStr = Left(NameStr, StartsAt)
End If
' Ensure we have space delimiters for remaining NameStr
NameStr = Replace(NameStr, ".", ". ")
' Remove extraneous spaces
RegX.Pattern = " {2,}"
NameStr = Trim(RegX.Replace(NameStr, " "))
' Create zero-based array with remaining "words" in the name
NameArr = Split(NameStr, " ")
' First name is always assumed to be in position zero
FName = NameArr(0)
' Depending on how many "words" are left and whether middle name is assumed to possibly be there
' (UseMiddle argument), grab middle/last names
Select Case UBound(NameArr)
Case 0
'no middle or last names
Case 1
' first name and last name
LName = NameArr(1)
Case Else
' potentially first, middle, and last names are present
If UseMiddle Then
' position 1 is assumed to be middle name, and positions 2 to N the last name
MName = NameArr(1)
' remaining "words" are for last name
For Counter = 2 To UBound(NameArr)
LName = LName & " " & NameArr(Counter)
Next
' drop leading space
LName = Trim(LName)
Else
' assume no middle name, and all remaining words are for the last name
For Counter = 1 To UBound(NameArr)
LName = LName & " " & NameArr(Counter)
Next
' drop leading space
LName = Trim(LName)
End If
End Select
Else
' NameStr is structured <Surname> <Suffix (optional)>, <Title (optional)> <First name> <Middle Name (optional)>
' Find position of last comma
LastComma = InStrRev(NameStr, ",")
If LastComma > 0 Then
' Part1 will be <Surname> <Suffix (optional)> block;
' Part2 is <Title (optional)> <First name> <Middle Name (optional)>
Part1 = Trim(Left(NameStr, LastComma - 1))
Part2 = Trim(Mid(NameStr, LastComma + 1))
' Look for suffixes. Use Do...Loop to allow for compound suffixes, as in "Neumann, PhD, Esq., Alfred E."
' StartsAt indicates where the suffix(es) start in Part1. Initialize to -1, indicating no suffix
StartsAt = -1
' Set Pattern to look for suffix at end of Part1
RegX.Pattern = "(, *| +)(" & Suffixes & ")\.?$"
' Evaluate Part1. As long as a suffix is found in the portion evaluated, reset the StartsAt variable.
' When no more suffixes are found, terminate the loop
Do
Set RegXReturn = RegX.Execute(Left(Part1, IIf(StartsAt > -1, StartsAt, Len(Part1))))
If RegXReturn.Count > 0 Then
StartsAt = RegXReturn(0).FirstIndex ' Recall that FirstIndex starts at position zero, not 1 !!!
Else
Exit Do
End If
Loop
' If a suffix is found, then grab the entire suffix
If StartsAt > -1 Then
Suffix = Mid(Part1, StartsAt + 1)
' remove comma if applicable
If Left(Suffix, 1) = "," Then Suffix = Mid(Suffix, 2)
' remove possible leading space
Suffix = Trim(Suffix)
' adjust Part1 to remove suffixes
Part1 = Left(Part1, StartsAt)
End If
LName = Trim(Part1)
' Set Pattern to look for titles at beginning of Part2
RegX.Pattern = "^(" & Titles & ")\.? +"
' Look for titles. Use Do...Loop to allow for compound suffixes, as in "Dimmesdale, Rev. Mr. Arthur"
Do
Set RegXReturn = RegX.Execute(Mid(Part2, TitleLen + 1))
If RegXReturn.Count > 0 Then
TitleLen = TitleLen + Len(RegXReturn(0))
Else
Exit Do
End If
Loop
' Get Title
Title = Trim(Left(Part2, TitleLen))
' Adjust Part2
Part2 = Mid(Part2, TitleLen + 1)
' Ensure we have space delimiters for remaining Part2
Part2 = Replace(Part2, ".", ". ")
' Remove extraneous spaces
RegX.Pattern = " {2,}"
Part2 = Trim(RegX.Replace(Part2, " "))
' Grab first/middle names from Part2
If UseMiddle And InStr(1, Part2, " ") > 0 Then
MName = Mid(Part2, InStrRev(Part2, " ") + 1)
FName = Left(Part2, InStrRev(Part2, " ") - 1)
Else
FName = Part2
End If
End If
End If
' determine function's return value
Select Case UCase(NamePart)
Case "TITLE", "HONORIFIC", "T", "H", "1"
GetNamePart = Title
Case "FIRST NAME", "FIRSTNAME", "FNAME", "F NAME", "FIRST", "F", "FN", "F N", "2"
GetNamePart = FName
Case "MIDDLE NAME", "MIDDLENAME", "MNAME", "M NAME", "MIDDLE", "M", "MN", "M N", "3"
GetNamePart = MName
Case "LAST NAME", "LASTNAME", "LNAME", "L NAME", "LAST", "L", "LN", "L N", "SURNAME", "4"
GetNamePart = LName
Case "SUFFIX", "S", "5"
GetNamePart = Suffix
Case Else
GetNamePart = ""
End Select
' destroy object variable
Set RegXReturn = Nothing
End Function
Function GetAllNameParts(NameStr As String, Optional UseMiddle As Boolean = True, _
Optional FirstMiddleLast As Boolean = True)
' Function by Patrick Matthews
' This code may be freely used or distributed so long as you acknowledge authorship and cite the URL
' where you found it
' This function relies on Regular Expressions. For more information on RegExp, please see:
' http://www.experts-exchange.com/articles/Programming/Languages/Visual_Basic/Parsing-Names-in-MS-Office-Visual-Basic-6-and-Visual-Basic-for-Applications.html
' This function parses a name string, and returns a Dictionary object (Microsoft Scripting Runtime) with
' keys corresponding to title, first name, middle name, surname, and suffix. If a name part is missing from the
' full name, the Dictionary item associated with that key is a zero-length string. The keys are:
' Title, First, Middle, Last, and Suffix (not case sensitive)
' This function can be used in any VBA or VB6 project. However, it cannot be used directly in an Excel
' worksheet formula or an Access query
' The function takes the following arguments:
'
' 1) NameStr is the full name to be parsed. Its assumed structure is determined by the FirstMiddleLast
' argument
' 2) UseMiddle indicates whether or not a middle name *might* be present in the NameStr. If True or
' omitted, the function assumes that a middle name *might* be there. If False, it assumes there
' is never a middle name
' 3) FirstMiddleLast indicates the order of the name parts. If True or omitted, the function assumes:
' <Title (optional)> <First name> <Middle Name (optional)> <Surname> <Suffix (optional)>
' If False, the function assumes:
' <Surname> <Suffix (optional)>, <First name> <Middle Name (optional)>
' Notes:
' 1) The function has a prebuilt list of Titles (see GenerateLists function below), which you can modify to
' fit your needs. The Titles string will be embedded in a RegExp Pattern string, so be sure to follow
' proper RegExp Pattern syntax
' 2) The function will recognize compound titles, as long as they are delimited by spaces
' 3) The function has a prebuilt list of Suffixes (see GenerateLists function below), which you can modify to
' fit your needs. The Suffixes string will be embedded in a RegExp Pattern string, so be sure to
' follow proper RegExp Pattern syntax
' 4) The function will recognize compound suffixes, as long as they are delimited by commas and/or spaces
' 5) If you are using True (or omitting) for FirstMiddleLast:
' a) It is always assumed that the first name has a single "word"
' b) It is always assumed that the middle name, if present, has a single "word"
' c) After the function has identfied the title, first name, middle name, and suffix, it assumes that
' whatever is left must be the surname/last name
' d) Thus, this function will process compound first/middle names incorrectly
' 6) If you are using False for FirstMiddleLast:
' a) It is always assumed that the last comma in NameStr delimits the <Surname><Suffix> block
' from the <Title><First name><Middle name> block
' b) Whatever is left in the <Surname><Suffix> block after the suffix has been removed is assumed
' to be the last name
' c) After the Title is removed from the <Title><First name><Middle name> block, if there is only
' one "word", it is the first name. If there are 2+ "words" and UseMiddle = True or omitted,
' then the last word is the middle name, and the rest is the first name
' d) Thus, this function will process compound middle names incorrectly, and may erroneously think
' a compound first name is a first name and a middle name
Dim Title As String
Dim FName As String
Dim MName As String
Dim LName As String
Dim Suffix As String
Dim RegXReturn As Object
Dim NameArr As Variant
Dim Counter As Long
Dim StartsAt As Long
Dim TitleLen As Long
Dim LastComma As Long
Dim Part1 As String
Dim Part2 As String
Dim dic As Object
Static Titles As String
Static Suffixes As String
Static RegX As Object 'holding as a Static variable to improve performance
If Titles = "" Then Titles = GenerateLists("Titles")
If Suffixes = "" Then Suffixes = GenerateLists("Suffixes")
Set dic = CreateObject("Scripting.Dictionary")
With dic
.CompareMode = 1
.Add "Title", ""
.Add "First", ""
.Add "Middle", ""
.Add "Last", ""
.Add "Suffix", ""
End With
If Trim(NameStr) = "" Then
Set GetAllNameParts = dic
Set dic = Nothing
Exit Function
End If
' remove leading and trailing spaces
NameStr = Trim(NameStr)
' instantiate RegExp if needed (static variable, so it will remain in between calls)
If RegX Is Nothing Then
Set RegX = CreateObject("VBScript.RegExp")
With RegX
.IgnoreCase = True ' case insensitive
.Global = True ' finds all matches, not just first match
End With
End If
' Determine structure of NameStr
If FirstMiddleLast Then
' NameStr is structured <Title (optional)> <First name> <Middle Name (optional)> <Surname> <Suffix (optional)>
' Set Pattern to look for titles at beginning of NameStr
RegX.Pattern = "^(" & Titles & ")\.? +"
' Look for titles. Use Do...Loop to allow for compound suffixes, as in "Rev. Mr. Arthur Dimmesdale"
Do
Set RegXReturn = RegX.Execute(Mid(NameStr, TitleLen + 1))
If RegXReturn.Count > 0 Then
TitleLen = TitleLen + Len(RegXReturn(0))
Else
Exit Do
End If
Loop
' Get Title
Title = Trim(Left(NameStr, TitleLen))
' Adjust NameStr
NameStr = Mid(NameStr, TitleLen + 1)
' Look for suffixes. Use Do...Loop to allow for compound suffixes, as in "Alfred E. Neumann, PhD, Esq."
' StartsAt indicates where the suffix(es) start in the NameStr. Initialize to -1, indicating no suffix
StartsAt = -1
' Set Pattern to look for suffix at end of NameStr
RegX.Pattern = "(, *| +)(" & Suffixes & ")\.?$"
' Evaluate the NameStr. As long as a suffix is found in the portion evaluated, reset the StartsAt variable.
' When no more suffixes are found, terminate the loop
Do
Set RegXReturn = RegX.Execute(Left(NameStr, IIf(StartsAt > -1, StartsAt, Len(NameStr))))
If RegXReturn.Count > 0 Then
StartsAt = RegXReturn(0).FirstIndex ' Recall that FirstIndex starts at position zero, not 1 !!!
Else
Exit Do
End If
Loop
' If a suffix is found, then grab the entire suffix
If StartsAt > -1 Then
Suffix = Mid(NameStr, StartsAt + 1)
' remove comma if applicable
If Left(Suffix, 1) = "," Then Suffix = Mid(Suffix, 2)
' remove possible leading space
Suffix = Trim(Suffix)
' adjust NameStr to remove suffixes
NameStr = Left(NameStr, StartsAt)
End If
' Ensure we have space delimiters for remaining NameStr
NameStr = Replace(NameStr, ".", ". ")
' Remove extraneous spaces
RegX.Pattern = " {2,}"
NameStr = Trim(RegX.Replace(NameStr, " "))
' Create zero-based array with remaining "words" in the name
NameArr = Split(NameStr, " ")
' First name is always assumed to be in position zero
FName = NameArr(0)
' Depending on how many "words" are left and whether middle name is assumed to possibly be there
' (UseMiddle argument), grab middle/last names
Select Case UBound(NameArr)
Case 0
'no middle or last names
Case 1
' first name and last name
LName = NameArr(1)
Case Else
' potentially first, middle, and last names are present
If UseMiddle Then
' position 1 is assumed to be middle name, and positions 2 to N the last name
MName = NameArr(1)
' remaining "words" are for last name
For Counter = 2 To UBound(NameArr)
LName = LName & " " & NameArr(Counter)
Next
' drop leading space
LName = Trim(LName)
Else
' assume no middle name, and all remaining words are for the last name
For Counter = 1 To UBound(NameArr)
LName = LName & " " & NameArr(Counter)
Next
' drop leading space
LName = Trim(LName)
End If
End Select
Else
' NameStr is structured <Surname> <Suffix (optional)>, <Title (optional)> <First name> <Middle Name (optional)>
' Find position of last comma
LastComma = InStrRev(NameStr, ",")
If LastComma > 0 Then
' Part1 will be <Surname> <Suffix (optional)> block;
' Part2 is <Title (optional)> <First name> <Middle Name (optional)>
Part1 = Trim(Left(NameStr, LastComma - 1))
Part2 = Trim(Mid(NameStr, LastComma + 1))
' Look for suffixes. Use Do...Loop to allow for compound suffixes, as in "Neumann, PhD, Esq., Alfred E."
' StartsAt indicates where the suffix(es) start in Part1. Initialize to -1, indicating no suffix
StartsAt = -1
' Set Pattern to look for suffix at end of Part1
RegX.Pattern = "(, *| +)(" & Suffixes & ")\.?$"
' Evaluate Part1. As long as a suffix is found in the portion evaluated, reset the StartsAt variable.
' When no more suffixes are found, terminate the loop
Do
Set RegXReturn = RegX.Execute(Left(Part1, IIf(StartsAt > -1, StartsAt, Len(Part1))))
If RegXReturn.Count > 0 Then
StartsAt = RegXReturn(0).FirstIndex ' Recall that FirstIndex starts at position zero, not 1 !!!
Else
Exit Do
End If
Loop
' If a suffix is found, then grab the entire suffix
If StartsAt > -1 Then
Suffix = Mid(Part1, StartsAt + 1)
' remove comma if applicable
If Left(Suffix, 1) = "," Then Suffix = Mid(Suffix, 2)
' remove possible leading space
Suffix = Trim(Suffix)
' adjust Part1 to remove suffixes
Part1 = Left(Part1, StartsAt)
End If
LName = Trim(Part1)
' Set Pattern to look for titles at beginning of Part2
RegX.Pattern = "^(" & Titles & ")\.? +"
' Look for titles. Use Do...Loop to allow for compound suffixes, as in "Dimmesdale, Rev. Mr. Arthur"
Do
Set RegXReturn = RegX.Execute(Mid(Part2, TitleLen + 1))
If RegXReturn.Count > 0 Then
TitleLen = TitleLen + Len(RegXReturn(0))
Else
Exit Do
End If
Loop
' Get Title
Title = Trim(Left(Part2, TitleLen))
' Adjust Part2
Part2 = Mid(Part2, TitleLen + 1)
' Ensure we have space delimiters for remaining Part2
Part2 = Replace(Part2, ".", ". ")
' Remove extraneous spaces
RegX.Pattern = " {2,}"
Part2 = Trim(RegX.Replace(Part2, " "))
' Grab first/middle names from Part2
If UseMiddle And InStr(1, Part2, " ") > 0 Then
MName = Mid(Part2, InStrRev(Part2, " ") + 1)
FName = Left(Part2, InStrRev(Part2, " ") - 1)
Else
FName = Part2
End If
End If
End If
' determine function's return value
With dic
.Item("Title") = Title
.Item("First") = FName
.Item("Middle") = MName
.Item("Last") = LName
.Item("Suffix") = Suffix
End With
Set GetAllNameParts = dic
' destroy object variable
Set RegXReturn = Nothing
Set dic = Nothing
End Function
Private Function GenerateLists(ListType As String)
Dim Titles As String
Dim Suffixes As String
' In creating the master title and suffix lists, keep in mind that the strings will be passed in as part of a
' RegExp pattern, and so typical syntax rules for the VBScript implementation of RegExp will apply for things
' such as optional characters and escaping reserved characters. For example:
'
' M\.? ?D
'
' matches M, then zero or one period, then zero or one space, then D. Use the pipe character to delimit your
' entries
' If the lists get too long to keep using line continuators, then simply break them up into separate expressions:
'
' Titles = 'Dr|Doctor|Mrs|Ms|Miss|Mr|Mister|Master|'
' Titles = Titles & "Reverend|Rev|Right Reverend|Right Rev|Most Reverend|
' Titles = Titles & "Most Rev|Honorable|Honourable"
' Populate master title list. This can be expanded according to your needs. There is no need to include a
' trailing period here, as the Pattern string built later on includes an optional period at the end. In cases
' where a title may be shortened, list the longer version first. For example, list Senator before Sen.
Titles = "Dr|Doctor|Mrs|Ms|Miss|Mr|Mister|Master|Reverend|Rev|Right Reverend|Right Rev|Most Reverend|" & _
"Most Rev|Honorable|Honourable|Hon|Monsignor|Msgr|Father|Fr|Bishop|Sister|Sr|Mother Superior|Mother|" & _
"Senator|Sen|President|Pres|Vice President|V\.? ?P|Secretary|Sec|General|Gen|Lieutenant General|Lt\.? ?Gen|" & _
"Major General|Maj\.? ?Gen|Brigadier General|Brig\.? ?Gen|Colonel|Col|Lieutenant Colonel|Lt\.? ?Col|Major|" & _
"Maj|Sir|Dame|Lord|Lady|Judge|Professor|Prof"
' Populate master suffix list. This can be expanded according to your needs. There is no need to include a
' trailing period here, as the Pattern string built later on includes an optional period at the end. In cases
' where a title may be shortened, list the longer version first. For example, list Esquire before Esq. Also,
' list III before II, and II before I
Suffixes = "M\.? ?D|Ph\.? ?D|Esquire|Esq\.?|J\.? ?D|D\.? ?D|Jr|Sr|III|II|I|IV|X|IX|VIII|VII|VI|V|M\.? ?P|" & _
"M\.? ?S\.? ?W|C\.? P\.? ?A|P\.? M\.? ?P|L\.? ?P\.? ?N|R\.? ?N|A\.? ?S\.? ?E|U\.? ?S\.? ?N|" & _
"U\.? ?S\.? ?M\.? ?C|R\.? ?G\.? ?C\.? ?E|P\.? ?M\.? ?P|P\.? ?E|M\.? ?O\.? ?S|M\.? ?C\.? ?T\.? ?S|" & _
"M\.? ?C\.? ?T|M\.? ?C\.? ?S\.? ?E|M\.? ?C\.? ?S\.? ?D\.? ?|M\.? ?C\.? ?S\.? ?A|M\.? ?C\.? ?P\.? ?D|" & _
"M\.? ?C\.? ?M|M\.? ?C\.? ?L\.? ?T|M\.? ?C\.? ?I\.? ?T\.? ?P|M\.? ?C\.? ?D\.? ?S\.? ?T|" & _
"M\.? ?C\.? ?D\.? ?B\.? ?A|M\.? ?C\.? ?B\.? ?M\.? ?S\.? ?S|M\.? ?C\.? ?B\.? ?M\.? ?S\.? ?P|" & _
"M\.? ?C\.? ?A\.? ?S|M\.? ?C\.? ?A\.? ?D|M\.? ?C\.? ?A|I\.? ?T\.? ?I\.? ?L|C\.? ?R\.? ?P|C\.? ?N\.? ?E|" & _
"C\.? ?N\.? ?A|C\.? ?I\.? ?S\.? ?S\.? ?P|C\.? ?C\.? ?V\.? ?P|C\.? ?C\.? ?S\.? ?P|C\.? ?C\.? ?N\.? ?P|" & _
"C\.? ?C\.? ?I\.? ?E|C\.? ?A\.? ?P\.? ?M|S\.? ?J|O\.? ?F\.? ?M|C\.? ?N\.? ?D|M\.? ?B\.? ?A|M\.? ?S"
If ListType = "Titles" Then
GenerateLists = Titles
Else
GenerateLists = Suffixes
End If
End FunctionGetNamePart takes four arguments:
NameStr is the full name to be parsed. Its assumed structure (i.e., name order) is determined by the FirstMiddleLast argument
NamePart indicates the portion of the name you want returned
UseMiddle indicates whether or not a middle name might be present in the NameStr. If True or omitted, the function assumes that a middle name might be there. If False, it assumes there is never a middle name
FirstMiddleLast indicates the order of the name parts. If True or omitted, the function assumes: <Title (optional)> <First name> <Middle Name (optional)> <Surname> <Suffix (optional)>. If False, the function assumes: <Surname> <Suffix (optional)>, <First name> <Middle Name (optional)>
Valid values for the NamePart argument are as follows, and are not case sensitive:
Title: "TITLE", "HONORIFIC", "T", "H", "1"
First: "FIRST NAME", "FIRSTNAME", "FNAME", "F NAME", "FIRST", "F", "FN", "F N", "2"
Middle: "MIDDLE NAME", "MIDDLENAME", "MNAME", "M NAME", "MIDDLE", "M", "MN", "M N", "3"
Last: "LAST NAME", "LASTNAME", "LNAME", "L NAME", "LAST", "L", "LN", "L N", "SURNAME", "4"
Suffix: "SUFFIX", "S", "5"
GetAllNameParts takes three arguments:
NameStr is the full name to be parsed. Its assumed structure (i.e., name order) is determined by the FirstMiddleLast argument
UseMiddle indicates whether or not a middle name might be present in the NameStr. If True or omitted, the function assumes that a middle name might be there. If False, it assumes there is never a middle name
FirstMiddleLast indicates the order of the name parts. If True or omitted, the function assumes: <Title (optional)> <First name> <Middle Name (optional)> <Surname> <Suffix (optional)>. If False, the function assumes: <Surname> <Suffix (optional)>, <First name> <Middle Name (optional)>
Please note the following (both functions):
Name parts may be hyphenated or abbreviated. In the case of titles and suffixes, make sure that the abbreviated forms are included in the code
The function has a pre-built list of Titles, which you can modify to fit your needs. The Titles string will be embedded in a RegExp Pattern string, so be sure to follow proper RegExp Pattern syntax
The function will recognize compound titles, as long as they are delimited by spaces
The function has a pre-built list of Suffixes, which you can modify to fit your needs. The Suffixes string will be embedded in a RegExp Pattern string, so be sure to follow proper RegExp Pattern syntax
The function will recognize compound suffixes, as long as they are delimited by commas and/or spaces
Both functions rely on a third, private function included in the source code above, GenerateLists, to create the master title and suffix lists. If you need to modify your master lists, make the changes there
If you are using True (or omitting) for FirstMiddleLast:
It is always assumed that the first name has a single "word"
It is always assumed that the middle name, if present, has a single "word"
After the function has identfied the title, first name, middle name, and suffix, it assumes that whatever is left must be the surname/last name
Thus, this function will process compound first/middle names incorrectly
If you are using False for FirstMiddleLast:
It is always assumed that the last comma in NameStr delimits the <Surname><Suffix> block from the <Title><First name><Middle name> block
Whatever is left in the <Surname><Suffix> block after the suffix has been removed is assumed to be the last name
After the Title is removed from the <Title><First name><Middle name> block, if there is only one "word", it is the first name. If there are 2+ "words" and UseMiddle = True or omitted, then the last word is the middle name, and the rest is the first name
Thus, this function will process compound middle names incorrectly, and may erroneously think a compound first name is a first name and a middle name
Special note: the master lists for titles and suffixes can get quite long, and thus some users may want to explore the possibility of storing these items in an external text file, a database table, or some other data management structure/service. Such an improvement is beyond the scope of this article, however.
5. Implementing GetNamePart and GetAllNameParts in Your VB6/VBA Project
To implement the GetNamePart function in your projects for VB6 or VBA (using Excel, Access, or any other program that uses VBA) application, please do the following:
Go to the Visual Basic Editor
Add a new "regular" module to your project (not a class module!)
Paste the code for GetNamePart, GetAllNameParts, and GenerateLists into that module
Update the title and/or suffix lists in the code if needed to support your specific data sets
Start using GetNamePart and/or GetAllNameParts in your code procedures, formulas, queries, and/or forms project
Please note that, due to the difficulties in dealing with compound names, you should always spot check the results of the function.
For example, consider the names below, with compound name parts marked by (*):
First Middle Last
------------------------------------------------------
Anne Marie (*) Thomason Miller
John Ronald Reuel (*) Tolkien
John R.R. (*) Tolkien
John R. R. (*) Tolkien
Oscar de la Renta (*)
Jill St. John (*)GetNamePart will struggle with those names, as seen in the results below:
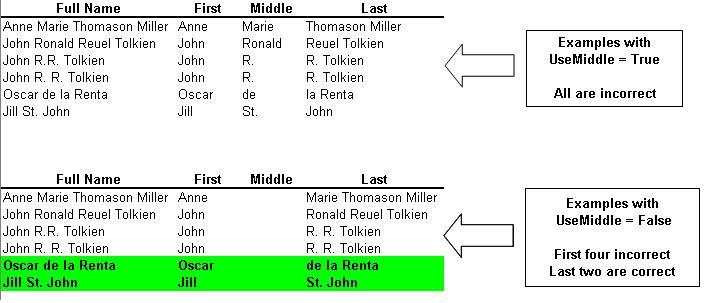
In both sample files, in addition to parsing out the various name parts, I also have a "Check" column that uses a simple test to see whether a particular record might be troublesome. For this test, I simply looked for records in which the middle name is found, or for which the extracted last name includes a space, as either condition can signal a compound name that should be verified by a human. I strongly recommend that you do something similar when using this function.
Despite the power and flexibility offered by GetNamePart and GetAllNameParts, you should always assume that the results will have to be audited by a person familiar with the data set and what it will be used for. Therefore, you should always retain a copy of the original data set to aid in the auditing process.
6. Further Reading
The GetNamePart and GetAllNameParts functions included in this article and in the sample files rely heavily on Regular Expressions to extract the name parts. Please see this article for more information on using Regular Expressions in VB6 and VBA.
This article by Excel MVP Chip Pearson includes a user defined function to parse names, but it is not quite as flexible as the GetNamePart and GetAllNameParts functions provided in this article. That same page also includes some more Excel formulas for parsing names.
7. Sample Files
For a demonstration of parsing names using the GetNamePart function, please download the sample files included here:
GetNamePart.xls
Parse Names Demo.mdb
Each file includes examples of parsing names in both the First Middle Last and Last, First Middle structures.
GetNamePart.xls
Parse-Names-Demo.mdb
=-=-=-=-=-=-=-=-=-=-=-=-=-
If you liked this article and want to see more from this author, please click here.
If you found this article helpful, please click the Yes button near the:
Was this article helpful?
label that is just below and to the right of this text. Thanks!
=-=-=-=-=-=-=-=-=-=-=-=-=-
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (5)
Commented:
Great article. Thanks! Voted "Yes" above.
Commented:
What an outstanding article. I've struggled with these issues ever since the Radio Shack TRS-80 days. It's wonderful to have a reference that pulls it all together. This article has got to be one of the best, if not the best resource, on the subject. Got my Yes vote above.
Author
Commented:I recently came across a situation where last names ending in "i" were being misinterpreted as a "I" (the first) suffix. A small tweak to the RegExp patterns appears to fix it.
The code below implements the fix, and in addition to that I have added the academic degrees MBA and MS to the suffix list.
Cheers, Patrick
Open in new window
Commented:
Please note, I encountered the following bug in the code when running on my system (Access 2010):
FNLN$ = JUAN A BROOKS JR
debug.print GetNamePart(FNLN$, "Last") & GetNamePart(FNLN$, "Suffix") & "/" & GetNamePart(FNLN$, "First") & " " & GetNamePart(FNLN$, "Middle")
produces: BROOKS/JUAN A (without the JR)
I didn't trace the code, but on my system, calling the function with "Last" removes the suffix from FNLN$. I solved the problem by adding BYVAL to the declaration as follows:
ByVal NameStr As String
This removes the possibility of any inadvertent changes to NameStr.
Author
Commented:Thank you for your comment. I tried but could not reproduce your result. I did notice one problem with your expression:
Open in new window
You have no separator between the surname and suffix in that expression.
Patrick