

Browse All Articles > How to duplicate a Master-Detail structure using Merge
Today while answering the questions I found one especially interesting. It wasn't anything obvious or standard and nothing I'd have a ready answer for. It led me to quite interesting solution. While it was too complex to try to explain it all in the question comments, I decided to put just code snippet as an answer and write this article to explain why and how it works.
So let's get started. First we need to create a test environment to replicate that question. I will use it to explain the problem scenario.
This should create two tables and pre-populate them with some test data
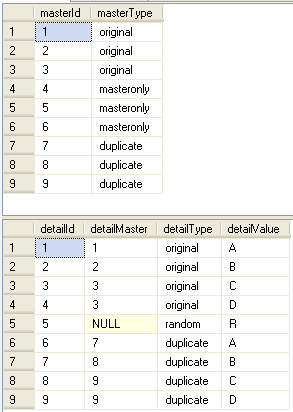
![Stage1]() What we've got here is master to details, one to many relation with detailMaster pointing to masterId. But as you can see from this example not all master records have details and some details may be orphans. The task is to duplicate original details creating new parents for them.
What we've got here is master to details, one to many relation with detailMaster pointing to masterId. But as you can see from this example not all master records have details and some details may be orphans. The task is to duplicate original details creating new parents for them.
One can argue at this point that the database design is wrong to start with but I will consider it irrelevant to a problem at hand and carry on. Why? Because not always we work with databases designed perfectly (by ourselves most likely) or environments where structure of a database may be changed at will; and still in this very imperfect world we need to be able to solve problems we encounter. If you like, consider a business requirement whereby new Purchases Orders need to be generated from selected existing details - maybe an oversimplification for our real problem - but a legitimate business requirement by way of analogy.
At a very first glance it looks simple but quickly you will realize that the tables don't share enough information to try any joins or temporary tables. In the example the detailValue is unique so you can use it in a temporary table to try to link it back but it will never work in a real life situation as detailValue is not necessarily unique.
What's left? Cursors obviously! But cursors are evil so I started to look for a better, more data-set oriented solution. Firstly I thought about the INSERT statement with OUTPUT clause but it was no good as OUTPUT for INSERT (as opposed to OUTPUT for UPDATE or DELETE) can return only INSERTED.* and nothing else, no literals, no columns from_table_name so it was no better than a temporary table. But then I remembered that MERGE treats all operations equally and that you can OUTPUT from_table_name even when effectively insert rows into a table.
NOTE: The below code is using MERGE statement. If you are not familiar with it, I advise you to look it up before proceeding. You may find this page at Technet helpful. And please keep in mind that what I am going to show below is not very standard way of using MERGE.
So here is what I came with:
And here is plain text explanation of what the above code does:
Line 1: Create temporary table that will store 'mapping' information of old to new masterID.
Line 6: Merge will operate on MasterTable refered to as target later in the query.
Line 7: Data will be pulled from DetailsTable to merge it with the target.
Line 10: Row_Number is computed for each detail row with partitioning by masterId. It will be used later on not to insert too many master rows.
Now, the MERGE statement comes into the play together with the trick.
Line 17: this always false condition makes sure that always the processed record will be inserted and never updated
Line 18: rownum=1 stops duplicates from being inserted into temporary table by OUTPUT statement
Line 19: The new master row is inserted
Line 21: And information about the mapping is stored in the temporary table
Line 25: Easy to overlook but very important semicolon as every MERGE statement has to be ended with semicolon.
Line 27: Finally the new rows are inserted into DetailsTable
The result is as expected and achieved our goals:
![Stage2]()
NOTE: Because the solution uses MERGE statement which was introduced in SQL 2008 it will not work with earlier versions of SQL Server and I am afraid that cursors are the only solution to solve the problem purely on the database level.
References
MERGE at Technet
Why cursors are eveil at SQL Server Performance
Another article about cursors' performance at SQL Team
So let's get started. First we need to create a test environment to replicate that question. I will use it to explain the problem scenario.
create table MasterTable (masterId int identity, masterType varchar(32))
create table DetailsTable (detailId int identity, detailMaster int, detailType varchar(32), detailValue varchar(32))
insert into MasterTable (masterType) values ('original')
insert into MasterTable (masterType) values ('original')
insert into MasterTable (masterType) values ('original')
insert into DetailsTable (detailMaster, detailType, detailValue)
select masterId, masterType, CHAR(ASCII('A')+masterId-1) from MasterTable
insert into DetailsTable (detailMaster, detailType, detailValue) values (3, 'original', 'D')
insert into DetailsTable (detailMaster, detailType, detailValue) values (null, 'random', 'R')
insert into MasterTable values ('masteronly')
insert into MasterTable values ('masteronly')
insert into MasterTable values ('masteronly')
select * from MasterTable
select * from DetailsTable This should create two tables and pre-populate them with some test data
 What we've got here is master to details, one to many relation with detailMaster pointing to masterId. But as you can see from this example not all master records have details and some details may be orphans. The task is to duplicate original details creating new parents for them.
What we've got here is master to details, one to many relation with detailMaster pointing to masterId. But as you can see from this example not all master records have details and some details may be orphans. The task is to duplicate original details creating new parents for them.
One can argue at this point that the database design is wrong to start with but I will consider it irrelevant to a problem at hand and carry on. Why? Because not always we work with databases designed perfectly (by ourselves most likely) or environments where structure of a database may be changed at will; and still in this very imperfect world we need to be able to solve problems we encounter. If you like, consider a business requirement whereby new Purchases Orders need to be generated from selected existing details - maybe an oversimplification for our real problem - but a legitimate business requirement by way of analogy.
At a very first glance it looks simple but quickly you will realize that the tables don't share enough information to try any joins or temporary tables. In the example the detailValue is unique so you can use it in a temporary table to try to link it back but it will never work in a real life situation as detailValue is not necessarily unique.
What's left? Cursors obviously! But cursors are evil so I started to look for a better, more data-set oriented solution. Firstly I thought about the INSERT statement with OUTPUT clause but it was no good as OUTPUT for INSERT (as opposed to OUTPUT for UPDATE or DELETE) can return only INSERTED.* and nothing else, no literals, no columns from_table_name so it was no better than a temporary table. But then I remembered that MERGE treats all operations equally and that you can OUTPUT from_table_name even when effectively insert rows into a table.
NOTE: The below code is using MERGE statement. If you are not familiar with it, I advise you to look it up before proceeding. You may find this page at Technet helpful. And please keep in mind that what I am going to show below is not very standard way of using MERGE.
So here is what I came with:
declare @temporaryValues table (
newMasterId int
,oldMasterId int
)
merge MasterTable as target
using (
select
detailMaster as oldMasterId
,row_number() over(partition by detailMaster order by detailMaster) as rownum
from DetailsTable
where detailType = 'original'
) as source (
oldMasterId
,rownum
)
on (0=1)
when not matched and rownum=1 then
insert (masterType)
values ('duplicate')
output
inserted.masterId
,source.oldMasterId
into @temporaryValues
;
insert into DetailsTable (detailMaster, detailType, detailValue)
select temps.newMasterId, 'duplicate', originals.detailValue
from DetailsTable originals
inner join @temporaryValues temps
on originals.detailMaster = temps.oldMasterId
and originals.detailType = 'original' And here is plain text explanation of what the above code does:
Line 1: Create temporary table that will store 'mapping' information of old to new masterID.
Line 6: Merge will operate on MasterTable refered to as target later in the query.
Line 7: Data will be pulled from DetailsTable to merge it with the target.
Line 10: Row_Number is computed for each detail row with partitioning by masterId. It will be used later on not to insert too many master rows.
Now, the MERGE statement comes into the play together with the trick.
Line 17: this always false condition makes sure that always the processed record will be inserted and never updated
Line 18: rownum=1 stops duplicates from being inserted into temporary table by OUTPUT statement
Line 19: The new master row is inserted
Line 21: And information about the mapping is stored in the temporary table
Line 25: Easy to overlook but very important semicolon as every MERGE statement has to be ended with semicolon.
Line 27: Finally the new rows are inserted into DetailsTable
The result is as expected and achieved our goals:
NOTE: Because the solution uses MERGE statement which was introduced in SQL 2008 it will not work with earlier versions of SQL Server and I am afraid that cursors are the only solution to solve the problem purely on the database level.
References
MERGE at Technet
Why cursors are eveil at SQL Server Performance
Another article about cursors' performance at SQL Team
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (0)