

Browse All Articles > Is there the best way to find a sub-tree in a self-referencing table?
Graph theory is omnipresent in computing and graph structures are very often used to model and solve problems. But despite being so theoretically common, graphs very often prove to be problematic. Not because they are inherently difficult, but seem so, because they are neglected and avoided whenever possible.
Just look how often here on EE people ask questions about tree operations on database level.
It is true that for many years it was hard to implement common tree functions in relational database systems but in 2005 MS SQL Server implemented Common Table Expressions (defined by SQL:1999 standard) which made truly recursive queries possible. In that same version XML data type has been added and later in version 2008 HierarchyId data type emerged, designed especially to make operations on trees easier.
Nowadays Transact-SQL gives us plenty of tools to deal with data structured as trees: sub-queries, recursive stored procedures, cursors, XML data type, temporary tables, CTE, HierarchyId data type; thus the only problem remaining is to pick the right one.
In this article I will demonstrate and compare four different approaches to get descendants of a node from trees implemented as self-referencing tables. For flexibility the solutions will be implemented as a User Defined Functions meeting the following requirements
- it will take two parameters
- primary key of the root node from which to start the search
- maximum distance from the root node (when -1 then search without depth limit)
- it will return a table containing full sub-tree including the specified root node up to the specified depth limit
- output will include node primary key, primary key of parent node and distance
First we need to create test data structures and populate it with some test data:
The above code will create a simple Nodes table with
- nodeId - primary key for the table
- nodeParent - self referencing to nodeId
- nodeValue - in real life scenario it could be a foreign key to data table or instead of that many columns could be used storing record information.
Then the table is populated with test data. The CreateAbcTree stored procedure which does the job is using CTE and for that reason it will run only on SQL 2005 or newer. The created data is structured like this:
![Data Structure]() In total there are 69632 nodes with one root and 14 nodes at first level. Sub-trees staring from those 14 node have different depths and sizes and on each level there is different number of nodes.
In total there are 69632 nodes with one root and 14 nodes at first level. Sub-trees staring from those 14 node have different depths and sizes and on each level there is different number of nodes.
![Data Statistics]()
Finally an index is created on the nodeParent column to improve performance. The test environment is ready.
Now is time to present possible solutions.
1. Old school solution with a loop - possible since SQL Server 2000
How does it work?
Line 8: A temporary table is created which can store node key and it's relative distance from sub-tree root. The node in question is inserted into the temporary table as a start point
Line 16: In a loop for most recently added records to the temporary table search for their 1 level descendants and add them to the temporary table.
Line 27: Use temporary table to return relevant nodes from table
2. Recursive query using Common Table Expression - novelty in SQL Server 2005
How does it work?
Line 5: A CTE is defined
Line 7: Root level is defined
Line 11: Recursive level is defined
Line 13: and joined with root level
Line 17: resulting table is returned
Already at this point one advantage of CTE over Loop is visible - the clarity of code.
NOTE: because such CTE is treated as single query I was able use an inline table-valued function to make the code even clearer.
3. XML Data Type - Available since 2005 version of MS SQL Server
How does it work?
This time we need to have two functions. One that will be called recursively and will return XML. And than another one that will use the XML data and return table with results.
Line 3: WITH in this line sets function option and has nothing to do with WITH defining CTE from previous snippet
Line 9: The GetXmlTree() function is called recursively
Line 26: Sub-tree is computed by GetXmlTree() and stored in a variable
Line 30: cross apply is used to effectively join Nodes table with XML data stored in @xml
4. Using HierarchyId Data Type - only SQL Server 2008
It is not that obvious how a HierarchyId column works but explaining it's mechanics is beyond the scope of this article. If you have never used it before, don't worry. For this Article, we just want to see its practical benefits in action. However if you are interested please check references at the bottom of this article where you will find links to sites explaining it.
Firstly we will have to add a new column to the Nodes table and compute it's values for all existing rows. The initial query is time consuming - took my poor laptop over 2 hours - but it is only due to the fact that the table was not designed to use HierarchyId from the very beginning and now the existing structure has to be translated into a new construct. That translation is the first script. Once the table has been converted write operations on it will have only a very little, negligible overhead as a trade-off for performance at read time.
How does it work?
Line 3: new column is added named nodeHid
Line 5: root node is assigned root HierarchyId value
Line 10: temporary table is populated with records for which HierarchyId may be computed (at each run only one child per nod may be added)
Line 18: while there is something left
Line 20: compute new HierarchyIds
Line 25: remove records already processed from temporary table
Line 27: find more records that need and can be processed
Line 37: add index on nodeHid to improve performance
Now we can create a function that will operate on the newly created HierarchyId column
How does it work?
Line 6: HierarchyId of the sub-tree root is found
Line 11: output is created
Line 15: condition to see if the node is descendant of a potential parent
Ok, so we have 4 functions now, all performing a sub-tree search on the same table. To test them we will call them in the following manner
Line 1: The cache is flushed to help with fair performance measuring
Line 5: The test node is selected
Line 7: We use one of the test functions to find the full sub-tree (-1) for the @testNode
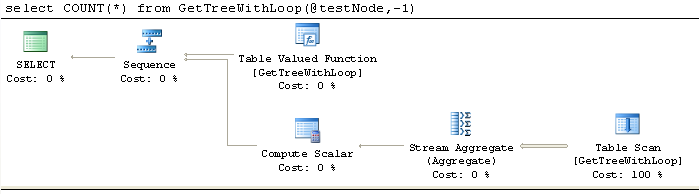
So what is different? First let's have a look at execution plans. Three functions (Loop, Xml and HierarchyId) have very similar and simple plan. Here is how it looks like for the loop function
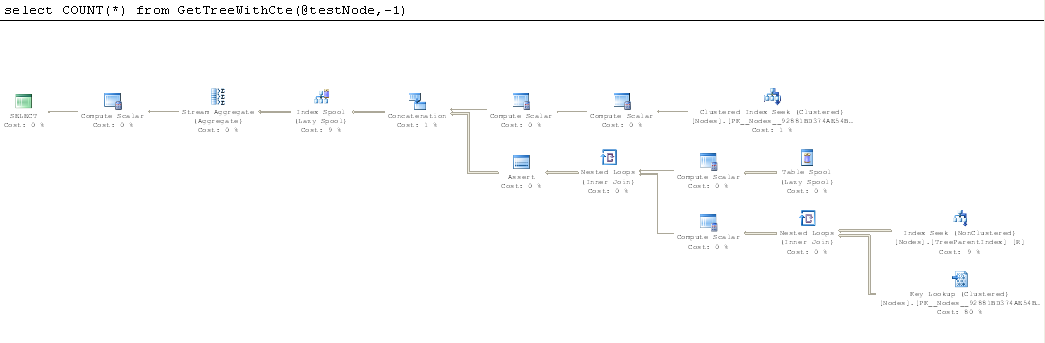
![GetTreeWithLoop Actual Execution Plan]() but plan for function using CTE is completely different.
but plan for function using CTE is completely different.
![GetTreeWithCte Acutal Execution Plan]() For a batch of four functions in question relative cost is as follow:
For a batch of four functions in question relative cost is as follow:
1% GetTreeWithLoop()
97% GetTreeWithCte()
1% GetTreeWithXml()
1% GetTreeWithHierarchyId()
But these are only estimated execution plans, and yet to be "put to the test".
To compare real performance, we need a more quantitative approach. So, I selected 6 test nodes:
node 2 with sub-tree of 1 and max depth of 0
node 5 with sub-tree of 16 and max depth of 3
node 8 with sub-tree of 176 and max depht of 6
node 11 with sub-tree of 1792 and max depth of 9
node 14 with sub-tree of 8192 and max depth of 12
node 1 with sub-tree of 69632 and max depth of 14
and computed sub-tree count for each one of them 15 times with each of 4 functions. For each node and function I recorded the average server's CPU time needed to process the request.
Here are the results:
![Sub-tree search performance]() As you may see there wasn't much difference until around 1500 nodes. Beyond that point XML version's time goes through the roof and for that reason I excluded it from further computation of relative values.
As you may see there wasn't much difference until around 1500 nodes. Beyond that point XML version's time goes through the roof and for that reason I excluded it from further computation of relative values.
![Sub-tree search relative performance]() From this graph you may clearly see that the old school Loop solution can still compete with the two more modern approaches as its relative performance to the others is stable regardless of the sub-tree size. More so, it seems to be exactly in the middle between the two. You may also see that CTE based solution seems to be fastest for small trees and HierarchyId for large ones with transition point around 1500 nodes and 8 levels. But you must not forget that in this test scenario depth grows with size as well, and in business scenarios we typically have only few levels.
From this graph you may clearly see that the old school Loop solution can still compete with the two more modern approaches as its relative performance to the others is stable regardless of the sub-tree size. More so, it seems to be exactly in the middle between the two. You may also see that CTE based solution seems to be fastest for small trees and HierarchyId for large ones with transition point around 1500 nodes and 8 levels. But you must not forget that in this test scenario depth grows with size as well, and in business scenarios we typically have only few levels.
So let's see how the performance compares for sub-trees of different sizes but equal depths.
![Sub-tree search performance - 3 levels]() It is worth noticing all the solutions have almost linear relation between size and time. Again XML method despite looking all right with small sub-trees goes through the roof at the other and of the graph. And again for that reason I excluded it from further computation of relative values.
It is worth noticing all the solutions have almost linear relation between size and time. Again XML method despite looking all right with small sub-trees goes through the roof at the other and of the graph. And again for that reason I excluded it from further computation of relative values.
![Sub-tree search relative performance - 3 levels]() Here you may clearly see that time-wise, out of the three CTE approach is the worst yet we are talking about 0.2-0.3 second difference to the best option at any size so it still may be preferable solution due to it's clean and compact syntax.
Here you may clearly see that time-wise, out of the three CTE approach is the worst yet we are talking about 0.2-0.3 second difference to the best option at any size so it still may be preferable solution due to it's clean and compact syntax.
And how about Loop vs. HierarchyId? On free level sub-trees their performance is very close. with Loop having small advantage for sub-trees up to around 2500 nodes and HierarchyId on bigger ones. So is the overhead worth implementing HierarchyId? On such shallow trees probably not, but when you look at previous graphs it looks like the new type has a lot to offer when it comes to much deeper structures.
References
2005 FOR XML queries on MSDN
Retrieving hierarchical data on Sql Server Central
HierarchyId on MSDN
More about HierarchyId on Technet
Excelent article about comparing performance of queries on SQL Server
Just look how often here on EE people ask questions about tree operations on database level.
It is true that for many years it was hard to implement common tree functions in relational database systems but in 2005 MS SQL Server implemented Common Table Expressions (defined by SQL:1999 standard) which made truly recursive queries possible. In that same version XML data type has been added and later in version 2008 HierarchyId data type emerged, designed especially to make operations on trees easier.
Nowadays Transact-SQL gives us plenty of tools to deal with data structured as trees: sub-queries, recursive stored procedures, cursors, XML data type, temporary tables, CTE, HierarchyId data type; thus the only problem remaining is to pick the right one.
In this article I will demonstrate and compare four different approaches to get descendants of a node from trees implemented as self-referencing tables. For flexibility the solutions will be implemented as a User Defined Functions meeting the following requirements
- it will take two parameters
- primary key of the root node from which to start the search
- maximum distance from the root node (when -1 then search without depth limit)
- it will return a table containing full sub-tree including the specified root node up to the specified depth limit
- output will include node primary key, primary key of parent node and distance
First we need to create test data structures and populate it with some test data:
create table Nodes (
nodeId int identity primary key
,nodeParent int
,nodeValue varchar(32)
);
go
create procedure CreateAbcTree @depth int
as
begin
declare @abc table (letter varchar(24))
declare @counter int
set @counter = 0
while @counter < @depth
begin
insert into @abc
select char(ascii(isnull(max(letter),Char(ASCII('A')-1)))+1) from @abc
set @counter = @counter +1
end
insert into Nodes (nodeParent, nodeValue) values (0,'');
with newnode as
(
select convert(varchar(24),letter) letter, 1 as Level from @abc
union all
select convert(varchar(24),nt.letter + abc.letter), Level+1
from newnode nt
inner join @abc abc on nt.Level<@depth
and abc.letter<=char(ascii(right(nt.letter,1)))
--and char(ascii(right(nt.letter,1)))<>'A'
and nt.level<=ascii(right(nt.letter,1))-ascii('A')
)
insert into Nodes (nodeParent, nodeValue)
select 0, letter
from newnode
update T1 set nodeParent = T2.nodeId
from nodes T1
inner join nodes T2
on len(T1.nodevalue)>0 and LEFT(T1.nodeValue, len(T1.nodevalue)-1) = T2.nodeValue
end
go
exec CreateAbcTree 14
create nonclustered index TreeParentIndex on Nodes(nodeParent)The above code will create a simple Nodes table with
- nodeId - primary key for the table
- nodeParent - self referencing to nodeId
- nodeValue - in real life scenario it could be a foreign key to data table or instead of that many columns could be used storing record information.
Then the table is populated with test data. The CreateAbcTree stored procedure which does the job is using CTE and for that reason it will run only on SQL 2005 or newer. The created data is structured like this:
 In total there are 69632 nodes with one root and 14 nodes at first level. Sub-trees staring from those 14 node have different depths and sizes and on each level there is different number of nodes.
In total there are 69632 nodes with one root and 14 nodes at first level. Sub-trees staring from those 14 node have different depths and sizes and on each level there is different number of nodes.
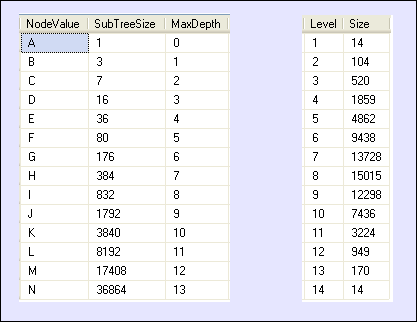
Finally an index is created on the nodeParent column to improve performance. The test environment is ready.
Now is time to present possible solutions.
1. Old school solution with a loop - possible since SQL Server 2000
create function GetTreeWithLoop (
@node int
,@maxDepth int
)
returns @output table (nodeId int, nodeParent int, nodeValue varchar(32), nodeDistance int)
as
begin
declare @tmp table (nodeId int primary key, nodeDistance int)
insert into @tmp (nodeId, nodeDistance)
select nodeId, 0
from nodes where nodeId = @node
declare @level tinyint;
set @level = 0
while
exists(select null from @tmp where nodeDistance = @level)
and (@maxDepth<0 or @level<@maxDepth)
begin
insert into @tmp (nodeId, nodeDistance)
select N.nodeId, @level + 1
from Nodes N
inner join @tmp T on T.nodeDistance = @level and N.nodeParent = T.nodeId
set @level = @level+1
end
insert into @output
select N.nodeId, N.nodeParent, N.nodeValue, T.nodeDistance
from nodes N
inner join @tmp T on N.nodeId = T.nodeId
return
endHow does it work?
Line 8: A temporary table is created which can store node key and it's relative distance from sub-tree root. The node in question is inserted into the temporary table as a start point
Line 16: In a loop for most recently added records to the temporary table search for their 1 level descendants and add them to the temporary table.
Line 27: Use temporary table to return relevant nodes from table
2. Recursive query using Common Table Expression - novelty in SQL Server 2005
create function GetTreeWithCte (@node int, @maxDepth int)
returns table
as
return (
with SubTree as
(
select nodeId, nodeParent, nodeValue, 0 as nodeDistance
from nodes
where nodeId = @node
union all
select R.nodeId, R.nodeParent, R.nodeValue, T.nodeDistance+1
from nodes R
inner join SubTree T
on (@maxDepth<0 or T.nodeDistance<@maxDepth)
and R.nodeParent = T.nodeId
)
select * from SubTree
);
goHow does it work?
Line 5: A CTE is defined
Line 7: Root level is defined
Line 11: Recursive level is defined
Line 13: and joined with root level
Line 17: resulting table is returned
Already at this point one advantage of CTE over Loop is visible - the clarity of code.
NOTE: because such CTE is treated as single query I was able use an inline table-valued function to make the code even clearer.
3. XML Data Type - Available since 2005 version of MS SQL Server
create function GetXmlTree (@node int, @maxLevel int, @level int)
returns xml
with returns null on null input
begin
return (
select
nodeId as [@nodeId]
,@level as [@nodeDistance]
,dbo.GetXmlTree(nodeId, @maxLevel, 1+@level)
from nodes
where (@maxLevel<0 or @level<=@maxLevel)
and (
(@level=0 and nodeId=@node)
or (@level>0 and nodeParent=@node)
)
for xml path('node'), type
)
end
go
create function GetTreeWithXml (@node int, @maxDepth int)
returns @output table (nodeId int, nodeParent int, nodeValue varchar(32), nodeDistance int)
as
begin
declare @xml xml
set @xml = dbo.GetXmlTree(@node,@maxDepth,0)
insert into @output
select N.nodeId, N.nodeParent, N.nodeValue
,xmlNode.value('@nodeDistance', 'int')
from Nodes N
cross apply @xml.nodes('//*[@nodeId]') XmlNodes(xmlNode)
where xmlNode.value('@nodeId','int') = nodeId
return
end
goHow does it work?
This time we need to have two functions. One that will be called recursively and will return XML. And than another one that will use the XML data and return table with results.
Line 3: WITH in this line sets function option and has nothing to do with WITH defining CTE from previous snippet
Line 9: The GetXmlTree() function is called recursively
Line 26: Sub-tree is computed by GetXmlTree() and stored in a variable
Line 30: cross apply is used to effectively join Nodes table with XML data stored in @xml
4. Using HierarchyId Data Type - only SQL Server 2008
It is not that obvious how a HierarchyId column works but explaining it's mechanics is beyond the scope of this article. If you have never used it before, don't worry. For this Article, we just want to see its practical benefits in action. However if you are interested please check references at the bottom of this article where you will find links to sites explaining it.
Firstly we will have to add a new column to the Nodes table and compute it's values for all existing rows. The initial query is time consuming - took my poor laptop over 2 hours - but it is only due to the fact that the table was not designed to use HierarchyId from the very beginning and now the existing structure has to be translated into a new construct. That translation is the first script. Once the table has been converted write operations on it will have only a very little, negligible overhead as a trade-off for performance at read time.
-- Transform our Nodes table to use HierarchyID (needs SQL2008)
alter table Nodes add nodeHid HierarchyId
go
update Nodes set nodeHid = hierarchyid::GetRoot()
where nodeParent = 0
declare @tmp table (id int, parentHid HierarchyId)
insert into @tmp
select nodeId, nodeHid from (
select T1.nodeId, T2.nodeHid, ROW_NUMBER() over(partition by t1.nodeParent order by t1.nodeParent, t1.nodeId) as rownum
from Nodes T1
inner join Nodes T2 on T2.nodeHid is not null and T1.nodeParent = T2.nodeId
where T1.nodeHid is null
) numbered where rownum=1
while exists(select null from @tmp)
begin
update N set nodeHid = parentHid.GetDescendant((select max(nodeHid) from nodes I where I.nodeHid.GetAncestor(1) = parentHid), null)
from Nodes N
inner join @tmp T on N.nodeId = T.id
delete from @tmp
insert into @tmp
select nodeId, nodeHid from (
select T1.nodeId, T2.nodeHid, ROW_NUMBER() over(partition by t1.nodeParent order by t1.nodeParent, t1.nodeId) as rownum
from Nodes T1
inner join Nodes T2 on T2.nodeHid is not null and T1.nodeParent = T2.nodeId
where T1.nodeHid is null
) numbered where rownum=1
end
go
create unique nonclustered index TreeHierarchicalIndex on Nodes(nodeHid)How does it work?
Line 3: new column is added named nodeHid
Line 5: root node is assigned root HierarchyId value
Line 10: temporary table is populated with records for which HierarchyId may be computed (at each run only one child per nod may be added)
Line 18: while there is something left
Line 20: compute new HierarchyIds
Line 25: remove records already processed from temporary table
Line 27: find more records that need and can be processed
Line 37: add index on nodeHid to improve performance
Now we can create a function that will operate on the newly created HierarchyId column
create function GetTreeWithHierarchyId (@node int, @maxDepth int)
returns @output table (nodeId int, nodeParent int, nodeValue varchar(32), nodeDistance int)
as
begin
declare @parent HierarchyId
set @parent = (
select nodeHid
from Nodes
where nodeId = @node
)
insert into @output
select N.nodeId, N.nodeParent, N.nodeValue
, N.nodeHid.GetLevel()-@parent.GetLevel() nodeDistance
from Nodes N
Where N.nodeHid.IsDescendantOf(@parent)=1
and (@maxDepth<0 or N.nodeHid.GetLevel()-@parent.GetLevel()<=@maxDepth)
return
endHow does it work?
Line 6: HierarchyId of the sub-tree root is found
Line 11: output is created
Line 15: condition to see if the node is descendant of a potential parent
Ok, so we have 4 functions now, all performing a sub-tree search on the same table. To test them we will call them in the following manner
DBCC FREEPROCCACHE
DBCC DROPCLEANBUFFERS
declare @testNode int
set @testNode = 14
select COUNT(*) from GetTreeWithLoop(@testNode,-1)
-- DBCC FREEPROCCACHE can impact performance on your Production Servers.
-- It is used here on a Test Machine to generate the results so we can compare fairly. Line 1: The cache is flushed to help with fair performance measuring
Line 5: The test node is selected
Line 7: We use one of the test functions to find the full sub-tree (-1) for the @testNode
So what is different? First let's have a look at execution plans. Three functions (Loop, Xml and HierarchyId) have very similar and simple plan. Here is how it looks like for the loop function
 but plan for function using CTE is completely different.
but plan for function using CTE is completely different.
 For a batch of four functions in question relative cost is as follow:
For a batch of four functions in question relative cost is as follow:
1% GetTreeWithLoop()
97% GetTreeWithCte()
1% GetTreeWithXml()
1% GetTreeWithHierarchyId()
But these are only estimated execution plans, and yet to be "put to the test".
To compare real performance, we need a more quantitative approach. So, I selected 6 test nodes:
node 2 with sub-tree of 1 and max depth of 0
node 5 with sub-tree of 16 and max depth of 3
node 8 with sub-tree of 176 and max depht of 6
node 11 with sub-tree of 1792 and max depth of 9
node 14 with sub-tree of 8192 and max depth of 12
node 1 with sub-tree of 69632 and max depth of 14
and computed sub-tree count for each one of them 15 times with each of 4 functions. For each node and function I recorded the average server's CPU time needed to process the request.
Here are the results:
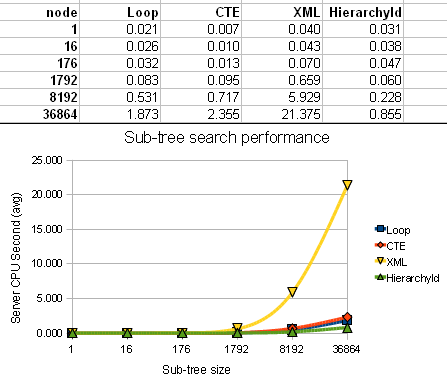 As you may see there wasn't much difference until around 1500 nodes. Beyond that point XML version's time goes through the roof and for that reason I excluded it from further computation of relative values.
As you may see there wasn't much difference until around 1500 nodes. Beyond that point XML version's time goes through the roof and for that reason I excluded it from further computation of relative values.
 From this graph you may clearly see that the old school Loop solution can still compete with the two more modern approaches as its relative performance to the others is stable regardless of the sub-tree size. More so, it seems to be exactly in the middle between the two. You may also see that CTE based solution seems to be fastest for small trees and HierarchyId for large ones with transition point around 1500 nodes and 8 levels. But you must not forget that in this test scenario depth grows with size as well, and in business scenarios we typically have only few levels.
From this graph you may clearly see that the old school Loop solution can still compete with the two more modern approaches as its relative performance to the others is stable regardless of the sub-tree size. More so, it seems to be exactly in the middle between the two. You may also see that CTE based solution seems to be fastest for small trees and HierarchyId for large ones with transition point around 1500 nodes and 8 levels. But you must not forget that in this test scenario depth grows with size as well, and in business scenarios we typically have only few levels.
So let's see how the performance compares for sub-trees of different sizes but equal depths.
 It is worth noticing all the solutions have almost linear relation between size and time. Again XML method despite looking all right with small sub-trees goes through the roof at the other and of the graph. And again for that reason I excluded it from further computation of relative values.
It is worth noticing all the solutions have almost linear relation between size and time. Again XML method despite looking all right with small sub-trees goes through the roof at the other and of the graph. And again for that reason I excluded it from further computation of relative values.
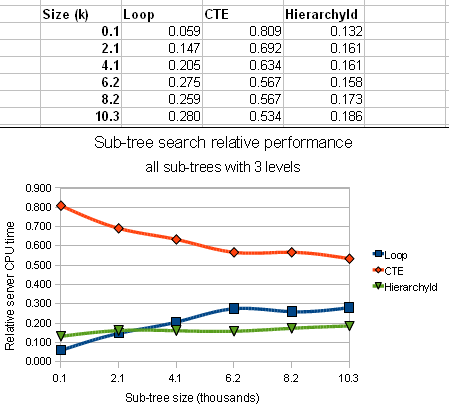 Here you may clearly see that time-wise, out of the three CTE approach is the worst yet we are talking about 0.2-0.3 second difference to the best option at any size so it still may be preferable solution due to it's clean and compact syntax.
Here you may clearly see that time-wise, out of the three CTE approach is the worst yet we are talking about 0.2-0.3 second difference to the best option at any size so it still may be preferable solution due to it's clean and compact syntax.
And how about Loop vs. HierarchyId? On free level sub-trees their performance is very close. with Loop having small advantage for sub-trees up to around 2500 nodes and HierarchyId on bigger ones. So is the overhead worth implementing HierarchyId? On such shallow trees probably not, but when you look at previous graphs it looks like the new type has a lot to offer when it comes to much deeper structures.
References
2005 FOR XML queries on MSDN
Retrieving hierarchical data on Sql Server Central
HierarchyId on MSDN
More about HierarchyId on Technet
Excelent article about comparing performance of queries on SQL Server
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (2)
Commented:
And glad to have you here at Experts-Exchange, especially writing articles. Will be sure to look out for you in the SQL zones.
Respectfully yours,
Kevin
Commented:
updated link to:
Comparing SQL Query Optimisations : Fair and consistent benchmarking