How to implement Parallel Executions in SSIS?


Published:
Browse All Articles > How to implement Parallel Executions in SSIS?
I have a large data set and a SSIS package. How can I load this file in multi threading?
Balanced Data Distribution by
Scenario
The client provided a large file of 5 million rows which is example raw file. In production environment, the file would be larger. I have to think about how to load it with minimal timing possibly.Solutions
In order to load this file in good performance, it requires many factors. I have been thought about structure of table, indexes, storage, ETL system... In this article, I would like to share how we can load a raw data file in multi threading.Microsoft provided many approaches that we can optimize our ETL system. From SQL Server 2014, Microsoft provided a data transformation component for Microsoft SQL Server Integration Services that named Balance Data Distribution that will allow us to speed up the transformation process.
Environment
Microsoft SQL Server 2014 - 12.0.2269.0 (X64) Jun 10 2015 03:35:45 Copyright (c) Microsoft CorporationEnterprise Edition (64-bit) on Windows NT 6.3 <X64> (Build 10586: )
Data Tools for Visual Studio 2013
Install Balanced Data Distribution component that downloaded above
Implementation
Create database
This step is to create a database that named as Sales_Retail. This database has a PRIMARY file group and nice other file groups. The purpose is to use partitioned table feature in SQL Server Enterprise Edition.
USE [master]
GO
IF NOT EXISTS (SELECT name FROM sys.databases WHERE name = N'Sales_Retail')
BEGIN
CREATE DATABASE [Sales_Retail]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'Sales_Retail', FILENAME = N'D:\DataSQL2014\Sales_Retail.mdf' , SIZE = 5120KB , MAXSIZE = UNLIMITED, FILEGROWTH = 10240KB ),
FILEGROUP [Sales2007]
( NAME = N'Sales2007', FILENAME = N'D:\DataSQL2014\Sales2007.ndf' , SIZE = 10240KB , MAXSIZE = 1048576KB , FILEGROWTH = 1024KB ),
FILEGROUP [Sales2008]
( NAME = N'Sales2008', FILENAME = N'D:\DataSQL2014\Sales2008.ndf' , SIZE = 10240KB , MAXSIZE = 1048576KB , FILEGROWTH = 1024KB ),
FILEGROUP [Sales2009]
( NAME = N'Sales2009', FILENAME = N'D:\DataSQL2014\Sales2009.ndf' , SIZE = 10240KB , MAXSIZE = 1048576KB , FILEGROWTH = 1024KB ),
FILEGROUP [Sales2010]
( NAME = N'Sales2010', FILENAME = N'D:\DataSQL2014\Sales2010.ndf' , SIZE = 10240KB , MAXSIZE = 1048576KB , FILEGROWTH = 1024KB ),
FILEGROUP [Sales2011]
( NAME = N'Sales2011', FILENAME = N'D:\DataSQL2014\Sales2011.ndf' , SIZE = 10240KB , MAXSIZE = 1048576KB , FILEGROWTH = 1024KB ),
FILEGROUP [Sales2012]
( NAME = N'Sales2012', FILENAME = N'D:\DataSQL2014\Sales2012.ndf' , SIZE = 10240KB , MAXSIZE = 1048576KB , FILEGROWTH = 1024KB ),
FILEGROUP [Sales2013]
( NAME = N'Sales2013', FILENAME = N'D:\DataSQL2014\Sales2013.ndf' , SIZE = 73728KB , MAXSIZE = 1048576KB , FILEGROWTH = 1024KB ),
FILEGROUP [Sales2014]
( NAME = N'Sales2014', FILENAME = N'D:\DataSQL2014\Sales2014.ndf' , SIZE = 235520KB , MAXSIZE = 1048576KB , FILEGROWTH = 1024KB ),
FILEGROUP [Sales2015]
( NAME = N'Sales2015', FILENAME = N'D:\DataSQL2014\Sales2015.ndf' , SIZE = 1048576KB , MAXSIZE = 1048576KB , FILEGROWTH = 1024KB ),
( NAME = N'Sales2015_1', FILENAME = N'D:\DataSQL2014\Sales2015_1.ndf' , SIZE = 168960KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )
LOG ON
( NAME = N'Sales_Retail_log', FILENAME = N'D:\DataSQL2014\Sales_Retail_log.mdf' , SIZE = 634880KB , MAXSIZE = 2048GB , FILEGROWTH = 10240KB )
END
GO
GO
ALTER DATABASE [Sales_Retail] SET RECOVERY SIMPLE
GO
ALTER DATABASE [Sales_Retail] SET MULTI_USER
GO
ALTER DATABASE [Sales_Retail] SET PAGE_VERIFY CHECKSUM
GOCreate a table
Because we want to create a partition table so we need to create a partition function and partition scheme before. Understanding the partitioned table in SQL Server, click hereCreate a partition function
USE Sales_Retail
GO
CREATE PARTITION FUNCTION SalesRetailRange(Datetime)
AS RANGE LEFT FOR VALUES('2007-01-01'
,'2008-01-01'
,'2009-01-01'
,'2010-01-01'
,'2011-01-01'
,'2012-01-01'
,'2013-01-01'
,'2014-01-01')
GO
Create a partition scheme
--- Create a partition scheme
CREATE PARTITION SCHEME SalesRetailScheme AS PARTITION SalesRetailRange TO ([Sales2007],[Sales2008]
,Sales2009,Sales2010,Sales2011,Sales2012,Sales2013,Sales2014,Sales2015)
GO
Create a table
This table is partitioned by OrderDate column. Whenever Sales data is imported into this table, it bases on the value of OrderData to determined which partition?
IF OBJECT_ID('Sales') IS NOT NULL
DROP TABLE Sales
GO
CREATE TABLE Sales
(
SalesOrderID int NOT NULL IDENTITY (1, 1) NOT FOR REPLICATION,
OrderDate datetime NOT NULL, -- Partion column
DueDate datetime NULL,
ShipDate datetime NULL,
Status tinyint NULL,
SalesOrderNumber nvarchar(50),
CustomerID nvarchar(50),
SalesPersonID nvarchar(50),
TerritoryID nvarchar(50),
BillToAddressID nvarchar(50),
ShipToAddressID nvarchar(50),
ShipMethodID nvarchar(50),
CreditCardID nvarchar(50),
CreditCardApprovalCode nvarchar(15) NULL,
CurrencyRateID nvarchar(50),
SubTotal nvarchar(50),
TaxAmt nvarchar(50),
Freight nvarchar(50),
TotalDue nvarchar(50),
Comment nvarchar(128) NULL,
CarrierTrackingNumber nvarchar(25) NULL,
OrderQty nvarchar(50) NULL,
UnitPrice nvarchar(50) NULL,
UnitPriceDiscount nvarchar(50) NULL,
LineTotal nvarchar(50),
SnapshotDate Datetime
) ON SalesRetailScheme([OrderDate])
GO
Create a SSIS Package
- Create a SSIS project named as Balanced_Data_Distribution
- Create a SSIS package named as Load_Sales_With_BDD
- Create a OLEDBConnection in Connection Manager Panel that connects to Sales_Retail database
- Create a flat file connection such Sales that connects to the raw file. In my example, I tried to generated 5 million rows of Sales data from AdventureWork2014 database.
![BDD_Connections.PNG]()
- Drag and drop Execute SQL Task component. This task truncates table Sales_Retail before importing data from the raw file
- Drag and dop Data Flow Task component and double click on it to go to Data Flow tab
- Drag and drop Raw File Source component named as Sales
- Connection Manager tab
- Flat file connection managers: Sales
- Columns tab: select all columns
- Connection Manager tab
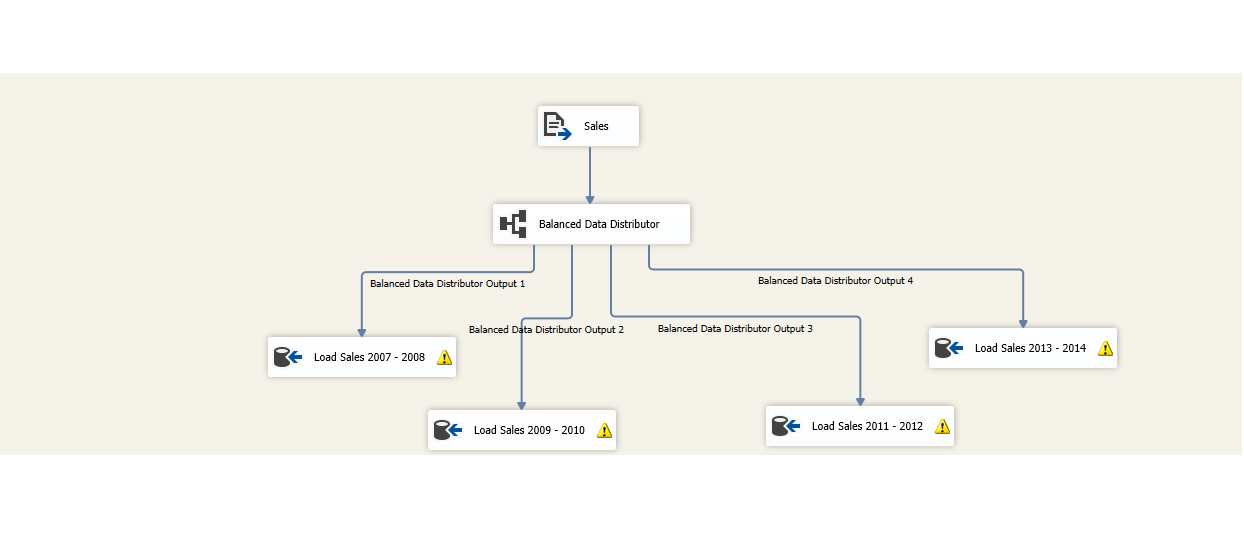
- Drag and drop Balanced Data Distribution component. This allows us to split input data into multiple flows in Data Flows area.
- Drag and drop OLEDB Destination named Load Sale 2007-2008
- Drag and drop OLEDB Destination named Load Sale 2009-2010
- Drag and drop OLEDB Destination named Load Sale 2011-2012
- Drag and drop OLEDB Destination named Load Sale 2013-2014
![BDD_Header.PNG]()
- Drag and drop Raw File Source component named as Sales
- Create a SSIS package named as Load_Sales_Without_BDD
- This step is to create a new package but we will not use Balance Data Distribution. It will be likely:
![Load_Sales_Without_BDD.PNG]()
- This step is to create a new package but we will not use Balance Data Distribution. It will be likely:

Execute the package
Case 1: In this case, we tested with DefaultBufferMaxRows is 100,000 and DefaultBufferSize is 100MBElapsed time = 2 minutes 17 seconds
Case 2: In this case, we tested with DefaultBufferMaxRows is 10,000 and DefaultBufferSize is 10MB
Elapsed time = 51 seconds
In theory, if we increase number of rows and buffer size, it would be run faster. However, the results were not our expectation, more rows and more buffer size lead bad performance. This was because of the system executing the package. In my example, I tried to execute on my laptop (Win 10 Pro, Core i7 (2 cores) and 8GB RAM). It was not able to write data enough fast when number of rows of the package increased and caused the I/O subsystem issue
Case 3: In this case, we tested Load_Sales_Without_BDD.dtx
Elapsed time = 55 seconds
Case 4: In this case, we tested Load_Sales_Without_BDD.dtx
Elapsed time = 2 minutes and 27 seconds.
Conclusions
Obviously, there is no difference significantly between With Balance Data Distribution and Without Balanced Distribution Data in my testing. However, what if the raw data file will be larger and larger ~100 million rows even more and you can execute the package on multi-core and multi-processor machines.If data set is large and requires several buffers to hold the data, Balanced Data Distribution component can effectively process buffers of data in parallel by using separate threads.
In this article, I would like to demonstrate how to implement Balanced Data Distribution component in SSIS. At this time, I can not answer that it is the best component to split input data into multi threading (flows) but it will be useful in some cases.
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (0)