Disaster Recovery Solution Design

Definitions
Business Impact Analysis (BIA). The BIA helps identify and prioritize information systems and components critical to supporting the organization’s mission/business processes [1].
Business continuity planning (BCP). BCP is to reduce the organization’s business risk.
Disaster Recovery Plan (DRP). A policy that defines how people and resources will be protected in a disaster, and how the organization will recover from the disaster. DRP is a just a subset of BCP.
Recovery Time Objective (RTO). This is the (worst case and achievable) length of time it should take to recover an application back to full service.
Recovery Point Objective (RPO). This is the (worst case and achievable) duration of processing that can be lost as a result of a disaster.
Service level agreement (SLA). The agreement, between a service provider and the customer(s) /user(s) that defines minimum performance targets for a service and how they will be measured. The uptime and availability requirements are a key component of the SLA.
Risk
An event that may have an effect on the daily operations of a given entity is called a risk. The effect could vary from downtime and disrupting the usual operations to losing money and sensitive information. Risks of not having proper BCP/DRP [2]:
- Inability to maintain critical customer services.
- Damage to market share, reputation or brand.
- Failure to protect the company assets, including in personnel.
- Business control failure.
- Failure to meet legal or regulatory requirements.
Risk management
Risk management requires an understanding of how security measures are implemented in the environment and how a threat can affect the daily operations. As a result, we need to understand the business operations and what kind of risk to which they might be exposed.
Failure to manage given risks will result, at least, in disruption of normal operations and can escalate to loss of data, loss of money, legal issues, or bankruptcy in some cases. The risk management goal is to reduce the presented risk to an acceptable level.
These levels will vary from one organization to another, depending on how big the environment and how much budget is given for the mitigation of those risks. The target is to identify, control, and minimize the loss caused by risk, and where possible, to prevent any risk. Given this, we must pay attention to the cost. When planning for risk management, you should balance between the impact of a risk and the cost of protective measures [3].
BCP/DRP
The DRP (Disaster Recovery Plan) is a policy that defines how an organization will recover from a disaster, whether it’s a natural or manmade disaster. The DRP should protect both people and assets of a given organization. DRP first should ensure the security of the people at all cost, then its plans for business continuity.
Business continuity plan (BCP) decides which services are sensitive to the risk of regular operations to continue. BCPs typically contain disaster recovery plans (DRPs), which are primarily used to restore specific IT services quickly. The BCP development process consists of the following steps:
- Develop a BCP policy statement.
- Conduct a BIA.
- Identify preventive controls.
- Develop recovery strategies.
- Develop an IT contingency plan.
- Perform BCP/DRP training and testing.
- Perform BCP/DRP maintenance.
Recovery Strategy
A recovery strategy is a combination of preventive, detective and corrective measures. The selection of a recovery strategy is a factor of:
- The criticality of the business process and the applications supporting the processes
- Cost
- RTO
- RPO
DR Solution Design Criteria
A list of criteria is focused on determining the correct solution for a given DR environment. There are five points of consideration, which are listed below:
- Data integrity
- Operational impact
- Investment in existing infrastructure
- Compliance
- Support for recovery processes
Data integrity
Data integrity is the paramount concern when determining any form of a disaster recovery related solution. Data is a company’s most vital asset. If a solution cannot preserve and guarantee the integrity of data placed in its trust, then the solution is of no value to an organization. Any solution must preserve the integrity of data under all operating conditions.
Due to the type of data processing activity that the organization undertakes such as OnLine Transaction Processing, it is strongly recommended that every effort is made to ensure that there is no data loss in the event of a disaster scenario. The decision criterion used to evaluate the data integrity of a particular solution is, which solution offers the lowest potential for data loss.
Operational impact
The operational impact of a solution must be considered highly. A solution that is at odds with existing operational processes or structures will only serve to damage an organization. A solution must not adversely impact existing procedures, instead, it should aim to streamline and improve operational efficiency wherever possible.
An organization must not be scared of changing operational procedures where appropriate, but a solution must not be more difficult to operate or increase the burden on resources in the course of business as usual. The decision criterion used to evaluate the operational impact of a particular solution is:
- How complicated will the solution be to manage?
- How will the solution affect the current working practices of the organization?
- How many procedures will need to be changed?
- How many new procedures will need to be introduced?
The more procedures that need to be introduced or changed, and the complexity of the new procedures will have a negative impact on the operational effectiveness (e.g.: “how easy the team finds their jobs”) of the team at an organization.
Planning for the worst is a necessity in any Operational Risk Management (ORM) strategy. Although extreme events are unlikely, they are often devastating enough to warrant some sort of plan of action. Some examples of extreme events include:
- The total DoS of your network and other systems.
- The total loss of systems through natural disasters.
- Data theft.
To mitigate the risk of these worst-case scenarios, consider the following strategies:
- Identify the threats.
- Identify the motivations of these threats.
- Determine what assets in your organization are the most critical and susceptible to extreme scenarios.
- Determine controls that will help prevent or mitigate an extreme scenario.
- Identify what exactly you risk by failing to prevent an extreme event.
Investment in existing infrastructure
Most organizations have a considerable investment in existing IT infrastructures. It is never desirable to implement solutions that require the replacement of large proportions of the existing infrastructure. Businesses aim to make the most of assets within their lifetime.
However, a business still needs to recognize that IT assets do have finite life spans and that technological advancement can realize savings in areas of maintenance cost avoidance or improvement in operational efficiency. Any solution must be sensitive to this.
The decision criterion used to evaluate the investment in the existing infrastructure of a particular solution is [4]:
- How much of the existing infrastructure is re-used?
- How much value is obtained from the existing infrastructure? (e.g.: activating a license key to switch on functionality) as opposed to purchasing all-new hardware/software components.)
- Is any new hardware purchase able to add business, operational, or technical benefit?
Note that this requirement does not necessarily remove the need for the procurement of new hardware. Rather, it seeks to balance the need for new hardware against the use of existing hardware.
Compliance
The key goal of the compliance element is to ensure that any disaster recovery processes enable the organization to meet RTO, RPO, and SLAs (which are legally) required by either the government or by ruling/influencing bodies within their industry sector. Any design should enable these to be met.
Compliance law is effectively the way in which governments are able to force businesses to provide a means of recovery so that the funds of shareholders and customers are safeguarded from the effects of a disaster at the company.
Notice: An auditor should always be present as an observer when DR plans are tested to ensure that the test meets the required targets for restoration, ensure that recovery procedures are effective and efficient, and report on the results, as appropriate.
Support for recovery processes
It is strongly recommended that an operationally simple solution that ensures data integrity is the most appropriate for the organization. For example, a consistent approach to data replication across all environments will help to simplify the recovery plan and will also help towards making the maintenance of such a plan more straightforward, which is vital if the recovery plan is to remain up-to-date and relevant to the organization.
The decision criterion used to evaluate the support for recovery processes of a particular solution is:
- How easy is it to recover the systems in the event of a disaster?
- How much special training and/or additional skills are required to recover the systems in the event of a disaster?
- Which solution has most knowledge capital available to the organization?
- Risks of not having proper BC/DR Plan.
- Inability to maintain critical customer services.
- Damage to market share, reputation or brand.
- Failure to protect the company assets, including intellectual properties and personnel.
- Business control failure.
- Failure to meet legal or regulatory requirements.
Use cases
There are multiple Disaster Recovery Strategies that can be used for Data availability and protection such as:
- Oracle Data Guard (A)
- SAN replication (B)
- Stretched Cluster (C)
In this paper, we will discuss the different DR solutions based on Data protection, Data availability and Data recoverability between the main production site and disaster recovery site [5].
 Data Guard (A)
Data Guard (A)
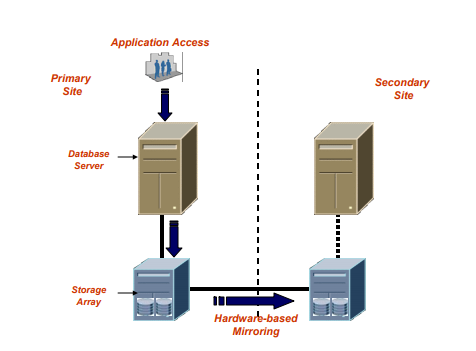 SAN Replication (B)
SAN Replication (B)
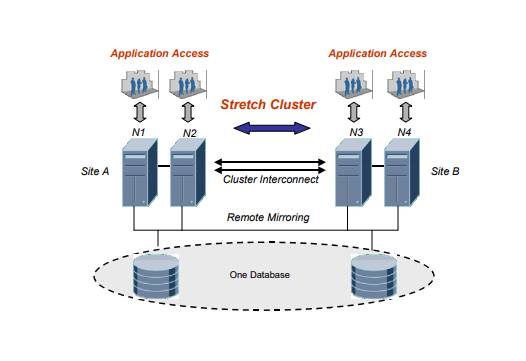 Stretched Cluster (C)
Stretched Cluster (C)
Table 1 below shows a comparison between the three solutions.
| Property/Solution |
Oracle Data Guard (A) |
SAN Replication (B) |
Stretched Cluster (C) |
| Amount of transferring data |
Minimal |
Huge |
Huge |
| Effectiveness in Protecting From Data Corruption |
Excellent |
Poor |
Poor |
| Connectivity |
MPLS/Leased line |
MPLS/Fiber |
Dark Fiber |
| Required Bandwidth |
Minimal |
Large |
Large |
| High Availability |
Active/Passive |
Active/Passive |
Active/Active |
| Effectiveness in Protecting from Network outages |
Excellent |
Excellent |
Good |
| Replicated Data |
DB Transactions only |
All data |
All data |
| Failover |
Harder failover for consumers |
Harder failover for consumers |
Easy failover for consumers |
| Block Corruption |
Not Reflected |
Reflected |
Reflected |
| Utilization |
Resource under-utilization |
Resource under-utilization |
Better utilization of resources |
| Configuration |
Reconfiguring during failover |
Reconfiguring during failover |
No Reconfiguration |
| Usefulness of Standby Database |
Could be used for reporting while in standby mode |
Could not be used without failover |
No need failover |
| Whole Refreshment |
Required less time |
Required long time |
Required less time |
| Acquisition and Service Costs |
Low |
High |
High |
| Fast automatic recovery after an outage |
Excellent |
Good |
Excellent |
| Latency |
Can tolerate latency |
Can exceed 1 second |
Can't tolerate latency. Round trip latencies on the management network between the Cluster Witness Server and both management servers between the two sites should not exceed 1 second. |
Table 1
Conclusion
The DR solution design should handle the design itself, a justification for the design, and a list of pre-requisites that will need to be in place in order for the design to function correctly in production.
The DR solutions need maintenance and evaluation on a timely basis. They should be reevaluated at least once a year to make sure of its effectiveness, changes will be made as necessary. The failover to the DR sites should be tested every time and another using both graceful and forceful methods to ensure the solution readiness in case of a real disaster.
References:
[1] Management of Information Security By Michael E. Whitman, Herbert J. Mattord
[2] https://www.coursehero.com/file/10973865/ch6-4-na/
[3] https://www.nr.no/~abie/RA_by_Jenkins.pdf
[4] https://core.ac.uk/download/pdf/82383972.pdf
[5] Oracle: http://castle.eiu.edu/~a_illia/DisasterRecovery(Ray).pdf
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (0)