Storage savings with Microsoft SQL Server


Database Expert with 15+ years experience (SQL, Access, Power BI).
Published:
Edited by: Andrew Leniart
Browse All Articles > Storage savings with Microsoft SQL Server
This article shows how to use different types of data compression in SQL Server and they drawbacks.
Importance of data compression is often underestimated especially in case of big data warehouses. Moreover, many people think that compression causes higher CPU usage because data must be uncompressed before using it. I will show you that in many cases the CPU usage is not higher but lower in case of data compression.
Let's see the numbers. How much storage can be saved and how much CPU should we pay in case of different types of data compression in SQL Server. From SQL Server 2016 we can choose between 4 types of data compression:
Columnstore compression evolved to the suitable level for many environments in SQL Server 2016 with less constraints, bugs and issues. I know that columnstore index is not a simple compression method but a whole technology stack but in this case, let's take it as a compression type.
Unfortunately, description and analysing of operation of different compression technologies are out of the scope of this article. Maybe later in a different article, I will analyze them separately.
Let's do a test on ContosoDWdata warehouse data on SQL Server 2017 with compatibility level 140. We produce a test table as a copy of FactOnlineSales with the following code:
Now we will measure:
Let's turn on statistics first:
Now let's see all the command what we use to measure CPU usage in case of compressions.
1. Simple rebuild of an uncompressed heap:
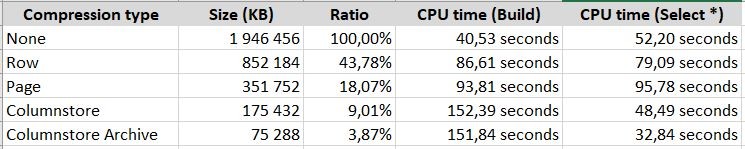
What do these columns mean?
You can see that ROW and PAGE compression is used much more CPU in building phase and also in scanning operations. However, it can save significant storage spaces.
But in case of COLUMNSTORE and COLUMNSTORE ARCHIVE only the build phase is more expensive (3-4 times) but reading data from these storage structures consume much less CPU resource then other compression types meanwhile they save more than 10 times the storage space (this means that reading uses even less IO operations).
You can see that scanning of columnar stored data uses less CPU than uncompressed data. This is thanks to Batch mode operations (but more about this later).
I recommend using columnstore indexes (normal or archive) in case of big SQL data warehouses especially in Fact tables because a repeat of dimension keys can be compressed very efficiently.
Let's see the numbers. How much storage can be saved and how much CPU should we pay in case of different types of data compression in SQL Server. From SQL Server 2016 we can choose between 4 types of data compression:
- ROW
- PAGE
- COLUMNSTORE
- COLUMNSTORE ARCHIVE
Columnstore compression evolved to the suitable level for many environments in SQL Server 2016 with less constraints, bugs and issues. I know that columnstore index is not a simple compression method but a whole technology stack but in this case, let's take it as a compression type.
Unfortunately, description and analysing of operation of different compression technologies are out of the scope of this article. Maybe later in a different article, I will analyze them separately.
Let's do a test on ContosoDWdata warehouse data on SQL Server 2017 with compatibility level 140. We produce a test table as a copy of FactOnlineSales with the following code:
select *
into dbo.FactOnlineSales_test
from dbo.FactOnlineSalesNow we will measure:
- how much time rebuilding of this table takes in different compressions
- elapsed time, cpu time of rebuild
- elapsed time, cpu time of a full scan of the table
Let's turn on statistics first:
set statistics time on
set statistics io onselect AVG(CAST(CHECKSUM(*) as float)) from dbo.FactOnlineSales_testNow let's see all the command what we use to measure CPU usage in case of compressions.
1. Simple rebuild of an uncompressed heap:
alter table dbo.FactOnlineSales_test
rebuild
with (data_compression = none)alter table dbo.FactOnlineSales_test
rebuild
with (data_compression = row)alter table dbo.FactOnlineSales_test
rebuild
with (data_compression = page)create clustered columnstore index CCI_FactOnlineSales_test on dbo.FactOnlineSales_test
with (data_compression = columnstore)create clustered columnstore index CCI_FactOnlineSales_test on dbo.FactOnlineSales_test
with (data_compression = columnstore_archive)What do these columns mean?
- Compression type: this is the name of compression type
- Size (KB): the full size of table (heap) or clustered index in kilobytes
- Ratio: this is a percentage ratio of the size to the uncompressed size
- CPU time (build): this is the CPU amount to be used to build or rebuild the table
- CPU time (select *): this is the consumed CPU amount to execute a full scan on the table
You can see that ROW and PAGE compression is used much more CPU in building phase and also in scanning operations. However, it can save significant storage spaces.
But in case of COLUMNSTORE and COLUMNSTORE ARCHIVE only the build phase is more expensive (3-4 times) but reading data from these storage structures consume much less CPU resource then other compression types meanwhile they save more than 10 times the storage space (this means that reading uses even less IO operations).
You can see that scanning of columnar stored data uses less CPU than uncompressed data. This is thanks to Batch mode operations (but more about this later).
I recommend using columnstore indexes (normal or archive) in case of big SQL data warehouses especially in Fact tables because a repeat of dimension keys can be compressed very efficiently.
Database Expert with 15+ years experience (SQL, Access, Power BI).
Have a question about something in this article? You can receive help directly from the article author. Sign up for a free trial to get started.
Comments (0)