Error Parsing a Tab Delimited Text file
windows server 2003 - Railo 3.1 - MySQL 5
I ran into an error parsing a tab delimited text file and need some help solving it. The error is:
Element at position [4] doesn't exist in array
Stacktrace The Error Occurred in
C:\www\IDX\MCNMLS\test.cfm
19: <cfset MLSNum = trim(rec[2])>
20: <cfset PhotoLabel = trim(rec[3])>
21: <cfset DateLastModified = trim(rec[4])>
22: <cfset PhotoOrder = trim(rec[5])>
23: <cfset DisplayAsPortrait = trim(rec[6])>
I attached a screenshot of the area of the textfile where the error occurs and my code. I think its because there are empty fields? Any help appreciated! Thanks
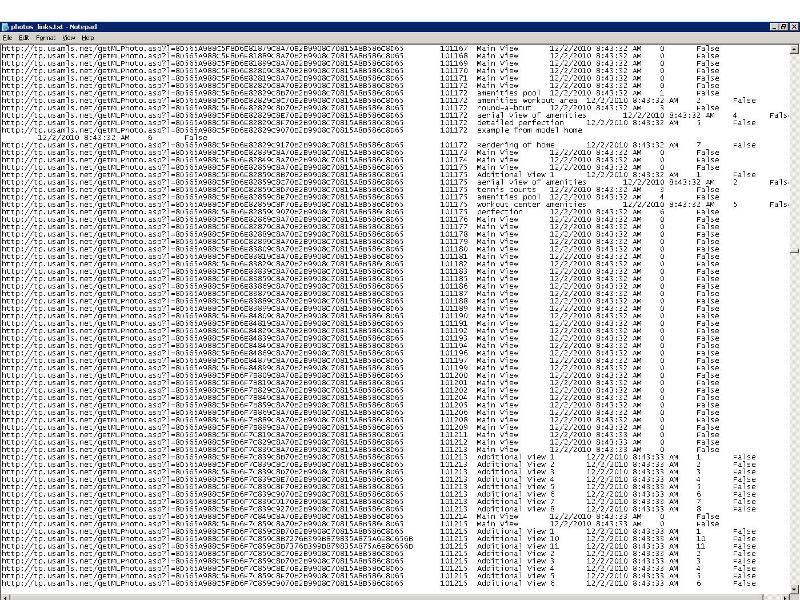
I ran into an error parsing a tab delimited text file and need some help solving it. The error is:
Element at position [4] doesn't exist in array
Stacktrace The Error Occurred in
C:\www\IDX\MCNMLS\test.cfm
19: <cfset MLSNum = trim(rec[2])>
20: <cfset PhotoLabel = trim(rec[3])>
21: <cfset DateLastModified = trim(rec[4])>
22: <cfset PhotoOrder = trim(rec[5])>
23: <cfset DisplayAsPortrait = trim(rec[6])>
I attached a screenshot of the area of the textfile where the error occurs and my code. I think its because there are empty fields? Any help appreciated! Thanks
<cfquery name="qryphotolinks" datasource="MCNMLS">
DELETE FROM PhotoLinks
</cfquery>
<cffile action="read" file="#ExpandPath( './ftp/txt/photos_links.txt' )#" variable="txtFile">
<cfset rowCounter = 0>
<cfloop index="record" list="#Replace(Replace(Replace(txtFile,'''','''''','all'),'|','','all'),chr(9),'| ','all')#" delimiters="#chr(13)##chr(10)#">
<cfset rowCounter = rowCounter + 1>
<cfif rowCounter neq 1>
<cfset rec = listToArray(record,"|",true) >
<cfset PhotoLink = trim(rec[1])>
<cfset MLSNum = trim(rec[2])>
<cfset PhotoLabel = trim(rec[3])>
<cfset DateLastModified = trim(rec[4])>
<cfset PhotoOrder = trim(rec[5])>
<cfset DisplayAsPortrait = trim(rec[6])>
<cfquery name="qryInsertphotolinks" datasource="MCNMLS">
INSERT INTO PhotoLinks (PhotoLink,MLSNum,PhotoLabel,DateLastModified,PhotoOrder,DisplayAsPortrait)
VALUES (
<cfqueryparam cfsqltype="CF_SQL_VARCHAR" value="#PhotoLink#">,
<cfqueryparam cfsqltype="CF_SQL_INTEGER" value="#MLSNum#" null="#NOT isNumeric(MLSNum)#">,
<cfqueryparam cfsqltype="CF_SQL_VARCHAR" value="#PhotoLabel#">,
<cfqueryparam cfsqltype="CF_SQL_VARCHAR" value="#DateLastModified#">,
<cfqueryparam cfsqltype="CF_SQL_VARCHAR" value="#PhotoOrder#">,
<cfqueryparam cfsqltype="CF_SQL_VARCHAR" value="#DisplayAsPortrait#">
)
</cfquery>
</cfif>
</cfloop>ASKER
Hi gdemaria, I changed the code, attached, and about 15 seconds into parsing the file it errors out:
500 Servlet Exception
[show] java.lang.OutOfMemoryError
java.lang.OutOfMemoryError
I probably made a mistake in updating the code as you suggested, can you have another look? Thanks!
500 Servlet Exception
[show] java.lang.OutOfMemoryError
java.lang.OutOfMemoryError
I probably made a mistake in updating the code as you suggested, can you have another look? Thanks!
<cfsetting requestTimeOut = "12000">
<cfquery name="qryphotolinks" datasource="MCNMLS">
DELETE FROM PhotoLinks
</cfquery>
<cffile action="read" file="#ExpandPath( './ftp/txt/photos_links.txt' )#" variable="txtFile">
<cfset rowCounter = 0>
<cfloop index="record" list="#txtFile#" delimiters="#chr(13)##chr(10)#">
<cfset rowCounter = rowCounter + 1>
<cfif rowCounter neq 1>
<cfset rec = listToArray(record,chr(9),true) >
<cfif arrayLen(rec) neq 6>
<cfdump var="#rec#">
</cfif>
<cfset PhotoLink = trim(rec[1])>
<cfset MLSNum = trim(rec[2])>
<cfset PhotoLabel = trim(rec[3])>
<cfset DateLastModified = trim(rec[4])>
<cfset PhotoOrder = trim(rec[5])>
<cfset DisplayAsPortrait = trim(rec[6])>
<cfquery name="qryInsertphotolinks" datasource="MCNMLS">
INSERT INTO PhotoLinks (PhotoLink,MLSNum,PhotoLabel,DateLastModified,PhotoOrder,DisplayAsPortrait)
VALUES (
<cfqueryparam cfsqltype="CF_SQL_VARCHAR" value="#PhotoLink#">,
<cfqueryparam cfsqltype="CF_SQL_INTEGER" value="#MLSNum#" null="#NOT isNumeric(MLSNum)#">,
<cfqueryparam cfsqltype="CF_SQL_VARCHAR" value="#PhotoLabel#">,
<cfqueryparam cfsqltype="CF_SQL_VARCHAR" value="#DateLastModified#">,
<cfqueryparam cfsqltype="CF_SQL_VARCHAR" value="#PhotoOrder#">,
<cfqueryparam cfsqltype="CF_SQL_VARCHAR" value="#DisplayAsPortrait#">
)
</cfquery>
</cfif>
</cfloop>ASKER
I might add that this text file has approx 90k records in it.
Is there a reason you can't use MySQL's import tool? With large imports, I usually prefer that instead of looping.
http://dev.mysql.com/doc/refman/5.1/en/load-data.html
http://dev.mysql.com/doc/refman/5.1/en/load-data.html
The out of memory issue is a different issue (you're run out of server memory)
So seems like your code is now working ?
So seems like your code is now working ?
good idea agx, importing that size file would be much faster
Ooops, hit return too soon.
I was going to add figure out the initial error first. Once you have it working, consider trying mySQL's bulk import tool instead.
I was going to add figure out the initial error first. Once you have it working, consider trying mySQL's bulk import tool instead.
ASKER
Thanks, I'm working on the java heap space error...as soon as I figure that out I will try the parse again.
Were you getting OOM errors with the original code or just after adding the debugging stuff? Sometimes I've had problems when I have too much debugging/cfdumps in a page. If it's the debugging code, try aborting after the dump so you can figure out the error 1st:
<cfif arrayLen(rec) neq 6>
<cfdump var="#rec#">
<cfabort> <!==== abort here
</cfif>
<cfif arrayLen(rec) neq 6>
<cfdump var="#rec#">
<cfabort> <!==== abort here
</cfif>
ASKER
Ok just to test the parsing code, I deleted all but afew hundred records from the text file, left in the one where my code failed originally, and it still errors out with the updated code: Element at position [4] doesn't exist in array.
As best I can tell thats the first empty space it hits.
As best I can tell thats the first empty space it hits.
ASKER
OOM Just after adding the debugging. Originally I was just getting the "Element at position [4] doesn't exist in array." error.
I'm wondering if gdemaria might be right about the file "containing.. a random carriage return or extra tab". If it's not confidential - can you attach a sample of the text file that errors out?
When the element at position 4 doesn't exist, you should see the CFDUMP of the values... what do those values look like? Does it look like a full row of data?
ASKER
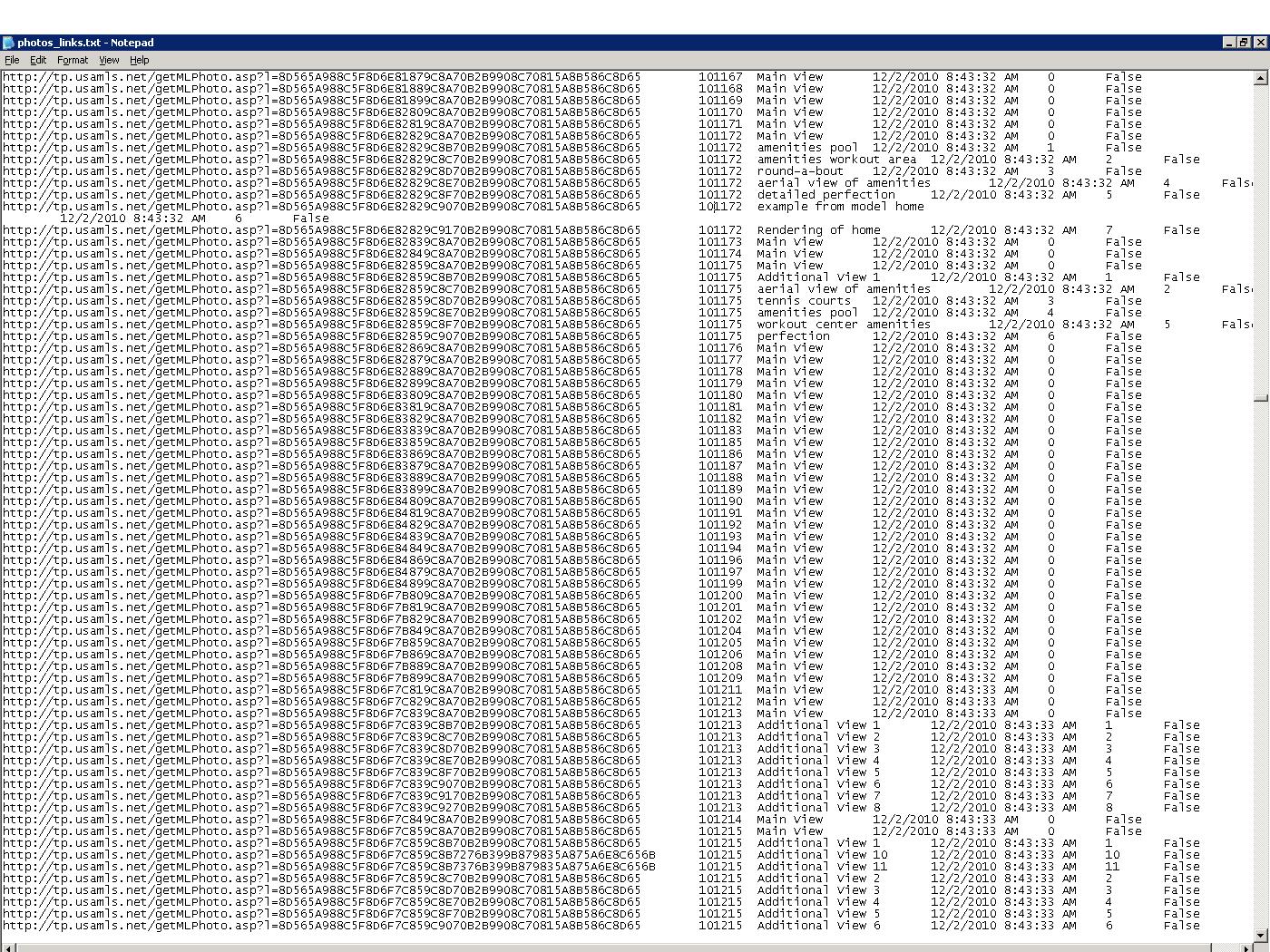
Heres the text file photos-links.txt
ASKER
actually here the full text file, the first one I loaded was the one I deleted records from and also deleted some carriage returns at the end of the last field name. photos-links.txt
.... 101172 example from model home <!=== extra character ??
67 12/2/2010 8:43:32 AM 6 False
Yeah, I can see an extra chr(13) in there just like gdemaria said.
116 [ascii = 104] = h
117 [ascii = 111] = o
118 [ascii = 109] = m
119 [ascii = 101] = e
120 [ascii = 13] = <!--- extra new line --->
1 [ascii = 9] =
2 [ascii = 49] = 1
3 [ascii = 50] = 2
67 12/2/2010 8:43:32 AM 6 False
Yeah, I can see an extra chr(13) in there just like gdemaria said.
116 [ascii = 104] = h
117 [ascii = 111] = o
118 [ascii = 109] = m
119 [ascii = 101] = e
120 [ascii = 13] = <!--- extra new line --->
1 [ascii = 9] =
2 [ascii = 49] = 1
3 [ascii = 50] = 2
I can't download that 2nd file for some reason. But in the 1st file there's definitely extra line feed causing the problem here:
.... 101172 example from model home <!=== extra character ??
67 12/2/2010 8:43:32 AM 6 False
.... 101172 example from model home <!=== extra character ??
67 12/2/2010 8:43:32 AM 6 False
agx has it pin-pointed. "Example from model home[CR]..."
Where is your data coming from? Can it go through a cleaning before being written to the file to ensure there are no extra carriage returns or tabs within the text that will conflict with the delimiters?
ASKER
the file is downloaded daily from an MLS Provider. So I dont really have any control over it, I just have to work with what they provide.
As a courtesy, you may want to report the problem to them... the data is not good and they should be made aware of it.
What you could do is try to add intelligence to your code, it could be tricky. If you don't have all the fields, you need to read the next line and then get the 2nd half of your variables from it.
Alternatively, if the data isn't so important that you get EVERY row, you can just consider it a bad row and skip it.
That's the easy way, just change your CFIF to wrap around the insert so you skip over the insert when the data is not good.
ASKER
yeah I also noticed that when importing the text file with navicat it adds a 7th field that has no name or data in it.
ASKER
" just change your CFIF to wrap around the insert so you skip over the insert when the data is not good." Can you provide an example? that would be much appreciated...thanks
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
> Looks like they always end lines with the column delimiter (tab) then a new line. So you could replace that with a plain chr(10). Then any new lines left over could be ignored,.
Nice! That will help fix most issues.
Combine that with the CFIF to skip the insert if there is still an issue and you have a pretty solid solution
Nice! That will help fix most issues.
Combine that with the CFIF to skip the insert if there is still an issue and you have a pretty solid solution
ASKER
It works!, and adds all the records! great work guys! Thank you very, very much!
ASKER
Thanks again!
ASKER
Agx, Question... how did you see these characters in the text file?
116 [ascii = 104] = h
117 [ascii = 111] = o
118 [ascii = 109] = m
119 [ascii = 101] = e
120 [ascii = 13] = <!--- extra new line --->
1 [ascii = 9] =
2 [ascii = 49] = 1
3 [ascii = 50] = 2
116 [ascii = 104] = h
117 [ascii = 111] = o
118 [ascii = 109] = m
119 [ascii = 101] = e
120 [ascii = 13] = <!--- extra new line --->
1 [ascii = 9] =
2 [ascii = 49] = 1
3 [ascii = 50] = 2
Using an old fashioned loop ;-) Not tested, but it was something along the lines of
<cfset theLine = "abc#chr(10)#efg#chr(32)#b
<cfloop from="1" to="#len(theLine)#" index="x">
<cfset theChar = mid(theLine, x, 1)>
#x# [ascii = #asc(theChar)#] = #theChar#<br>
</cfloop>
<cfset theLine = "abc#chr(10)#efg#chr(32)#b
<cfloop from="1" to="#len(theLine)#" index="x">
<cfset theChar = mid(theLine, x, 1)>
#x# [ascii = #asc(theChar)#] = #theChar#<br>
</cfloop>
.. with <cfoutput> tags of course.
ASKER
nice! thanks agx!
Welcome :)
<cfloop index="record" list="#Replace(Replace(Rep
<cfset rowCounter = rowCounter + 1>
<cfif rowCounter neq 1>
<cfset rec = listToArray(record,"|",tru
Change to something like this......
<cfloop index="record" list="#txtFile#" delimiters="#chr(13)##chr(
<cfset rowCounter = rowCounter + 1>
<cfif rowCounter neq 1>
<cfset rec = listToArray(record,chr(9),
<cfif arrayLen(rec) neq 12> <!-------- the number of columns you expect.....
<cfdump var="#rec#">
</cfif>
You can test the array to see if it holds the right number of entries and dump out when it does not.
You may find that text fields in your file contains a random carriage return or extra tab...