Suspect RAID Card failing
We have a HP DL385 G2 rackmount server running VMWare ESX 4.1.
It has 2 RAID cards, the internal (P400) seems to be going fine but in the last few days we've had the P800 (512MB BBWC) connected to a MSA60 with what seems to be it halting. A while back after a reboot the server hung not long after the VM guests came back online however a hard-reset fixed it. I know of a case with another HP RAID card having issues with heavy I/O halting it (which seemed similar) however even after a full Firmware update today it happened 4 hours later.
Now we also have a Seagate ES drive (1TB) in the MSA that has twice today been marked as faulty. I'm at a loss to it being an error as only today (the 5th crash tonight since Monday night) it showed as failed twice (remove, reseat, re-sync & ok).
Can anyone give me a heads up possibly with any advice to what it could be? Is it as simple as an actual HDD failing (the one in question is a 1TB RAID1 set) or is there issues with the RAID controller?
I've already cut back the caching to 75% read, 25% write & disabled the Array acceleration on the RAID1 as mentioned above as preventative measures as well as lowering the load on the server but have to now think about moving images to another VM Server or making other arrangements!
Screenshot of system post failure: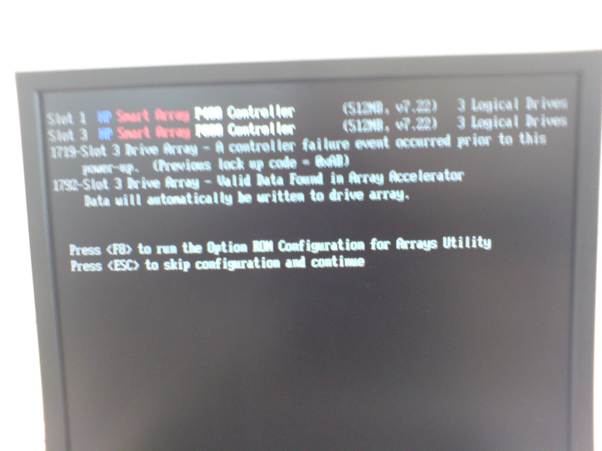
Diagnostics report of HP RAID ACU: report-4e82d645-000065bc-0000000.zip
It has 2 RAID cards, the internal (P400) seems to be going fine but in the last few days we've had the P800 (512MB BBWC) connected to a MSA60 with what seems to be it halting. A while back after a reboot the server hung not long after the VM guests came back online however a hard-reset fixed it. I know of a case with another HP RAID card having issues with heavy I/O halting it (which seemed similar) however even after a full Firmware update today it happened 4 hours later.
Now we also have a Seagate ES drive (1TB) in the MSA that has twice today been marked as faulty. I'm at a loss to it being an error as only today (the 5th crash tonight since Monday night) it showed as failed twice (remove, reseat, re-sync & ok).
Can anyone give me a heads up possibly with any advice to what it could be? Is it as simple as an actual HDD failing (the one in question is a 1TB RAID1 set) or is there issues with the RAID controller?
I've already cut back the caching to 75% read, 25% write & disabled the Array acceleration on the RAID1 as mentioned above as preventative measures as well as lowering the load on the server but have to now think about moving images to another VM Server or making other arrangements!
Screenshot of system post failure:
Diagnostics report of HP RAID ACU: report-4e82d645-000065bc-0000000.zip
ASKER
All is in a controlled environment (inc. temperature) without cabinet shift. I'll check the backplane seating however it definitely seems to happen more often when one VM (which does use that RAID1) is running.
I did consider about the P800 seating & will have a look.
I did consider about the P800 seating & will have a look.
Does sound like the card is failing, although the MSA60 has firmware it's pretty dumb. One thing to try is make sure the MSA60 is on the port that doesn't go through the P800's expander (although an expander failure shouldn't cause a card lockup) the port furthest away from the LEDs is the one that bypasses the expander.
1. Backup contents of the MSA60.
2. Shutdown server and MSA60
3. Remove ALL Disks from the MSA60 (just unplug no need to remove from chassis)
4. Power on Server, does the error still occur?
We've had a similar fault with an MSA60, and the backplane needed replacing.
2. Shutdown server and MSA60
3. Remove ALL Disks from the MSA60 (just unplug no need to remove from chassis)
4. Power on Server, does the error still occur?
We've had a similar fault with an MSA60, and the backplane needed replacing.
ASKER
The error only occurs after a crash. A reboot is fine. (We did a maintenance update on ESX (in Maintenance mode) so it behaved itself and the reboot message on the controller only specified about the Rebuilding of the RAID1 array in progress.
The error only occurs after a crash.
Your ESX server crashes?
Could just be a hung controller in the MSA60.
Update firmwares if applicable.
Your ESX server crashes?
Could just be a hung controller in the MSA60.
Update firmwares if applicable.
ASKER
It's a sort of weird one.
(Almost) All guests become unresponsive in the vSphere client, (option to power off only but it stops at 95% in the GUI), sometimes some guests are still running but most times I have to reset or power it down because the ESX console can't finish the shutdown procedure (since it still sees the guests as running).
All firmware was updated yesterday including the ROMPAQ (individually), SAS HDD firmware & the ILO2 controller (via HP's Firmware Update 9.90 DVD) . I'm yet to see a firmware update for the MSA.
I can only assume slightly that one Array is at fault as it seems the more logical answer at present until enough evidence suggests otherwise (but of course I have to look for that specific evidence first). We have a HP authorized engineer coming in a few hours to bounce the ideas around with him also but it's not a black & white fault really.. :(
(Almost) All guests become unresponsive in the vSphere client, (option to power off only but it stops at 95% in the GUI), sometimes some guests are still running but most times I have to reset or power it down because the ESX console can't finish the shutdown procedure (since it still sees the guests as running).
All firmware was updated yesterday including the ROMPAQ (individually), SAS HDD firmware & the ILO2 controller (via HP's Firmware Update 9.90 DVD) . I'm yet to see a firmware update for the MSA.
I can only assume slightly that one Array is at fault as it seems the more logical answer at present until enough evidence suggests otherwise (but of course I have to look for that specific evidence first). We have a HP authorized engineer coming in a few hours to bounce the ideas around with him also but it's not a black & white fault really.. :(
Even if the MSA60 caught fire the controller should not lock up. Same goes for individual disks, it's either an undocumented bug or the controller is going faulty.
ASKER
The Engineer stated that Although it being odd, the Disk was not a HP Part so wouldn't be supported. The most logical explanation was that it was the disk that failed (prior without error & lately stating an error) which knocked things out.
On the ESX side of things we can only assume that as ESX seen a datastore as unresponsive it got angsty & started to play up (in simple terms).
With the failed disk removed we've restarted the VM Guest used on that specific datastore and so far so good...
On the ESX side of things we can only assume that as ESX seen a datastore as unresponsive it got angsty & started to play up (in simple terms).
With the failed disk removed we've restarted the VM Guest used on that specific datastore and so far so good...
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Yeah - it's weird as the previous HP Firmware DVD actually upgraded the Seagate firmware on those disks as part of their release. They may not be "HP Certified" Disks ($400 Vs $1,200 at the time), but like for like they are the same albeit any extra Firmware tweaks HP put on.
It's madness in a way as the 4 other 3.5" SATA HP Certified disks of all the same size (250GB), all ordered at the same time are 2x Seagate & 2x Western Digital..
We have desktop/laptop standard 2.5" HDD's in the server itself (in the hot-plug trays) and had the odd minor fault (false-negative over-temp issue) but an eject and re-seat has worked fine. One did it twice at the start of the year & nothing since. (That is run of the P400 controller).
So far so good tonight with it running. Hopefully the server behaves itself once the faulty HDD comes back from RMA.
It's madness in a way as the 4 other 3.5" SATA HP Certified disks of all the same size (250GB), all ordered at the same time are 2x Seagate & 2x Western Digital..
We have desktop/laptop standard 2.5" HDD's in the server itself (in the hot-plug trays) and had the odd minor fault (false-negative over-temp issue) but an eject and re-seat has worked fine. One did it twice at the start of the year & nothing since. (That is run of the P400 controller).
So far so good tonight with it running. Hopefully the server behaves itself once the faulty HDD comes back from RMA.
ASKER
The actual issue (found at the end of 2011) was that the I/O controller on the MSA itself was faulty.
We found this out after the entire controller failed.
Since replacement we have had no more issues whatsoever.
We found this out after the entire controller failed.
Since replacement we have had no more issues whatsoever.
One thing that has caught me out in a RAID array is the backplane actually deciding it's getting too hot and then switching some of the hard drives off to protect me from catastrophe - causing a raid failure in the process.
It's unlikely for all these drives to fail at the same time, I'd look at potentially replacing the cables and/or backplane/chassis. Of course, the controller could still be at fault, but usually when they fault, they just stop working altogether.