DELETE Duplicates in SQL Server 2008
I have a database that has one table that has 30 fields. The first field is an integer that is a Primary Key and can not contain duplicates. The second column can contain duplicates only because it can contain ‘NONE’. Same with the third field it can contain duplicates and again only it can contain ‘NONE’. My database has about 130,000 records in the Main_Table.
The problem is that there are duplicates in the second and third fields that need be removed. ‘NONE’ is not to be considered a duplicate.
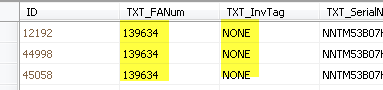 I know that I will have to do at least two statements or queries. The first one, deleting the duplicates in the second field, and the second query, to delete the duplicates in the third field.
I know that I will have to do at least two statements or queries. The first one, deleting the duplicates in the second field, and the second query, to delete the duplicates in the third field.
Any Ideas?
The problem is that there are duplicates in the second and third fields that need be removed. ‘NONE’ is not to be considered a duplicate.
I know that I will have to do at least two statements or queries. The first one, deleting the duplicates in the second field, and the second query, to delete the duplicates in the third field.Any Ideas?
ASKER
This does not take into account that I have duplicates of 'NONE' that I don't want deleted.
use thread above and add on to your queries
AND <> 'None'
AND <> 'None'
ASKER
I have my first SQL written and finding that the second column has 2821 duplicates, far more than I wish to delete by hand. And the third column has 9883 duplicates, again far more than I wish to do by hand.
The only way that I seem to get the PK is to do a MIN beings that there are no duplicates in the ID (PK) field.
The next step states “Select the duplicate key values into a holding table.” does this mean that I need to make a table in the database that I am going to write these records to? And if so do I need all 30 fields or just the PK and duplicate record and count?
Am I on the right track?
SELECT MIN(ID) AS PK, TXT_InvTag, COUNT(TXT_InvTag) AS Expr2
FROM ITRACK_Main
GROUP BY TXT_InvTag
HAVING (COUNT(TXT_InvTag) > 1) AND (TXT_InvTag <> N'NONE')The only way that I seem to get the PK is to do a MIN beings that there are no duplicates in the ID (PK) field.
The next step states “Select the duplicate key values into a holding table.” does this mean that I need to make a table in the database that I am going to write these records to? And if so do I need all 30 fields or just the PK and duplicate record and count?
Am I on the right track?
<The first field is an integer that is a Primary Key and can not contain duplicates. >
in you post what is the dups what you need to delete? based on smaller ID is priority? what about the rest columns?
in you post what is the dups what you need to delete? based on smaller ID is priority? what about the rest columns?
Something like this perhaps:
DELETE i
FROM ITRACK_Main i
INNER JOIN (SELECT TXT_InvTag,
MIN(ID) ID
FROM ITRACK_Main
WHERE TXT_InvTag <> N'NONE'
) d ON i.ID = d.ID
looks like it is not about record deletion - rather update ("delete" ) data in the 2 columns...
us1975mc: please clarify your question
us1975mc: please clarify your question
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
That did it. It waa just getting the things in the right order.
Thanks!
US1975MC
Thanks!
US1975MC
http://support.microsoft.com/kb/139444