MS Access 2003 Parsing Memo Field VBA
Hi,
I need to parse a text (MS Access memo field) that is comma separated with double quotation marks as text delimiters AND commas as part of some text entries themselves. Overall data volume is about 300k records with 3800 chars in 500 columns. I need to extract about 50 columns from all records.
Looping through the records themselves and overall data handling is ok. I am now searching for the best performing way to parse through a single text record, figure out if I have the correct column, extract the data and then get the next column from the text. The index and order of the columns is known, of course.
Sample data:
1, "2", 3, "4," ,"5", ",6,a"
Commas after 4 and before and after 6 are NOT delimiters.
For example, I need to extract the second ("2") and sixth (",6,a") column.
Did somebody already solve this or something comparable in some smooth way?
Best
finaris
I need to parse a text (MS Access memo field) that is comma separated with double quotation marks as text delimiters AND commas as part of some text entries themselves. Overall data volume is about 300k records with 3800 chars in 500 columns. I need to extract about 50 columns from all records.
Looping through the records themselves and overall data handling is ok. I am now searching for the best performing way to parse through a single text record, figure out if I have the correct column, extract the data and then get the next column from the text. The index and order of the columns is known, of course.
Sample data:
1, "2", 3, "4," ,"5", ",6,a"
Commas after 4 and before and after 6 are NOT delimiters.
For example, I need to extract the second ("2") and sixth (",6,a") column.
Did somebody already solve this or something comparable in some smooth way?
Best
finaris
Can you post the desired output from your sample?
Are we dealing with elements in which the commas and double quotes are important for the field values?
Are we dealing with elements in which the commas and double quotes are important for the field values?
ASKER
Hi boag2000,
thanks for your reply, but this is not what I want, since commas being part of the field values (and not meant as field delimiters) are recognized as field delimiters. However, being able to "split" the string into an array at once as suggested would be very good since I then do not need to parse every single line for searching the correct columns but can simply select the correct columns (by id) from the array. Question is now whether it is possible to handle with the additional commas as field values instead of being delimiters. Maybe there is an option to use some weird REGEX with the split function?
Hi jerryb30,
the result for columns 2 and 6 of my sample string should be
Double quotes here are meant to be part of the field value.
The commas are relevant for the field values whereas the double quotes are not relevant in the end. However I can not remove them beforehand because they are the only way for me to find the commas being part of the field values. Not all columns have double quotes (the ones with commas being part of the field values as wel as some others too).
All the best
finaris
thanks for your reply, but this is not what I want, since commas being part of the field values (and not meant as field delimiters) are recognized as field delimiters. However, being able to "split" the string into an array at once as suggested would be very good since I then do not need to parse every single line for searching the correct columns but can simply select the correct columns (by id) from the array. Question is now whether it is possible to handle with the additional commas as field values instead of being delimiters. Maybe there is an option to use some weird REGEX with the split function?
Hi jerryb30,
the result for columns 2 and 6 of my sample string should be
"2" for column 2
",6,a" for column 6
Double quotes here are meant to be part of the field value.
The commas are relevant for the field values whereas the double quotes are not relevant in the end. However I can not remove them beforehand because they are the only way for me to find the commas being part of the field values. Not all columns have double quotes (the ones with commas being part of the field values as wel as some others too).
All the best
finaris
finaris ,
I am confused, you say you want:
"2" for column 2
",6,a" for column 6
This is exactly what my sample shows:
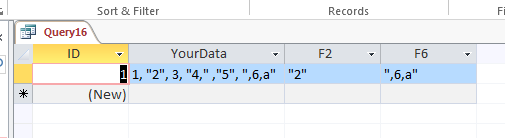
Can you clearly explain *exactly" what is lacking in my sample?
In other words, instead of explaining what you want in detail, ,...simply post a clear "Graphical" example of the *exact* output you need.
I am confused, you say you want:
"2" for column 2
",6,a" for column 6
This is exactly what my sample shows:
Can you clearly explain *exactly" what is lacking in my sample?
In other words, instead of explaining what you want in detail, ,...simply post a clear "Graphical" example of the *exact* output you need.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
Does Access not have a way to handle this? What could be faster would be to open the file in Excel. Tell Excel it is comma separated with " as the text qualifier, then save it in tab separated format and it should open straight into Access with no issues.
ASKER
Hi boag2000,
you mixed up the delimiter chars, the comma is the separator, not the double quote. And the ",6,a" is the sixth column, not the eights (or should be).
Hi Tommy,
Working with Excel is not an option since I only have 2003 (and I am not allowed to use a different version) and we have more than 65k rows. Furthermore, Excel has the the same problem with the number of columns.
Your first suggestion is what I have implemented today - which is the "long way". However, there are still some issues that have not been understood yet. I will get back to you tomorrow.
Thanks to you guys!
you mixed up the delimiter chars, the comma is the separator, not the double quote. And the ",6,a" is the sixth column, not the eights (or should be).
Hi Tommy,
Working with Excel is not an option since I only have 2003 (and I am not allowed to use a different version) and we have more than 65k rows. Furthermore, Excel has the the same problem with the number of columns.
Your first suggestion is what I have implemented today - which is the "long way". However, there are still some issues that have not been understood yet. I will get back to you tomorrow.
Thanks to you guys!
Still confused...
You asked for: ",6,a"
My query displays: ",6,a"
...How is anything "Mixed up"?
Le's for get columns for now, as I can make the values appear in any column you like...
I am not trying to be argumentative here..its just that my query displays the values you asked for...
JeffCoachman
You asked for: ",6,a"
My query displays: ",6,a"
...How is anything "Mixed up"?
Le's for get columns for now, as I can make the values appear in any column you like...
I am not trying to be argumentative here..its just that my query displays the values you asked for...
JeffCoachman
:-O
Database136-1-.mdb