BeyondBGCM
asked on
PCL and PDF
I have a PCL file which i want to compare with PDF file , can you please tell me , how can i do that .
I have done , a lot of googling for that , but no freeware does that, and i can not read the PCL file in my C# code (itextsharp) .
i have to compare PCL file with PDF and find the difference in both of them , and write it to a separate file .
I have done , a lot of googling for that , but no freeware does that, and i can not read the PCL file in my C# code (itextsharp) .
i have to compare PCL file with PDF and find the difference in both of them , and write it to a separate file .
I see two approaches. Either (1) convert the PCL file to a PDF file or (2) print the PDF file to a PCL file. Then do the comparison — PDF to PDF or PCL to PCL. To convert the PCL file to a PDF file, I agree with pony10us' recommendation of WinPCLtoPDF from Columbia University. It is discussed in more detail in an EE thread starting here:
https://www.experts-exchange.com/questions/28351592/convert-a-prn-file-to-a-pdf.html?anchorAnswerId=39823107#a39823107
To convert the PDF file to a PCL file, open the file in Adobe Reader or Acrobat (or whatever PDF reader/viewer you prefer) and print it to a PCL-based printer, ticking the box that says "Print to file":
 It will make the comparison better if you print it to the same PCL-based printer as the PDF file, or at least one that uses the same PCL version. If you know what that is, great; if not, you could take a look at the PCL file with a plain text editor to try to figure it out (as discussed in the EE thread that I mentioned above). Regards, Joe
It will make the comparison better if you print it to the same PCL-based printer as the PDF file, or at least one that uses the same PCL version. If you know what that is, great; if not, you could take a look at the PCL file with a plain text editor to try to figure it out (as discussed in the EE thread that I mentioned above). Regards, Joe
https://www.experts-exchange.com/questions/28351592/convert-a-prn-file-to-a-pdf.html?anchorAnswerId=39823107#a39823107
To convert the PDF file to a PCL file, open the file in Adobe Reader or Acrobat (or whatever PDF reader/viewer you prefer) and print it to a PCL-based printer, ticking the box that says "Print to file":
It will make the comparison better if you print it to the same PCL-based printer as the PDF file, or at least one that uses the same PCL version. If you know what that is, great; if not, you could take a look at the PCL file with a plain text editor to try to figure it out (as discussed in the EE thread that I mentioned above). Regards, Joe
ASKER
hi
http://www.columbia.edu/~em36/pcltopdf.html
I have downloaded this , and tried converting the pcl file to PDF , but , when i try to read the converted PDF file in C# application , it doesn't read properly , and gives some vague text.
so , i couldn't use this tool ,
coming to your second comment, how can i compare two PCL files , using C# , as this is not only comparison, but also finding out what is not matching , and sending that mismatch to another file.
http://www.columbia.edu/~em36/pcltopdf.html
I have downloaded this , and tried converting the pcl file to PDF , but , when i try to read the converted PDF file in C# application , it doesn't read properly , and gives some vague text.
so , i couldn't use this tool ,
coming to your second comment, how can i compare two PCL files , using C# , as this is not only comparison, but also finding out what is not matching , and sending that mismatch to another file.
ASKER
hi
I have tried several license software to read a PCL file and convert it to PDF files, but i can not read that converted file in C# application(itextsharp), then where my problem starts ....
because if there is a single character not read properly, it can make comparison go wrong .
I have tried several license software to read a PCL file and convert it to PDF files, but i can not read that converted file in C# application(itextsharp), then where my problem starts ....
because if there is a single character not read properly, it can make comparison go wrong .
>> ... how can i compare two PCL files ...
This would only be meaningful if the two PCL files had been created using the same (or very similar) printer driver, using the same print options.
As an example (and assuming that you want to compare the text characters in the print jobs):
And similar considerations would have to apply to comparing a PDF file with another PDF file created by conversion from a PCL print job file.
For example, the original PDF might contain text objects, but the converted one might contain only the PDF equivalent of a PCL raster-image, if the PCL print job used that technique.
This would only be meaningful if the two PCL files had been created using the same (or very similar) printer driver, using the same print options.
As an example (and assuming that you want to compare the text characters in the print jobs):
One driver (or set of options) may print text using a combination of text characters with cursor positioning and printer-resident font selection sequences.
A different driver (or set of options) may print the same text using a combination of text characters with cursor positioning and a down-loaded soft font; in this case, the text characters in the file are likely to be unintelligible as plain text, since they (and the soft font) will have been 'obfuscated'.
Yet another driver (or set of options) may print text by converting it (on the host workstation) into one, or a series of (printer-format) images; so the text could not be later extracted from this, other than by using Optical Character Recognition techniques.
And similar considerations would have to apply to comparing a PDF file with another PDF file created by conversion from a PCL print job file.
For example, the original PDF might contain text objects, but the converted one might contain only the PDF equivalent of a PCL raster-image, if the PCL print job used that technique.
>> ... you could take a look at the PCL file with a plain text editor to try to figure it out ...
Or you could use the PRN File Analyse tool in the PCL Paraphernalia application, available via http://www.pclparaphernalia.eu
Or you could use the PRN File Analyse tool in the PCL Paraphernalia application, available via http://www.pclparaphernalia.eu
What is the actual goal here? Are you trying to determine why a printed version of a document doesn't match the same document when viewed on screen?
ASKER
yes , there is a team, which compares the PCL files received from one source and PDF files received from another source ,and tries to compare whether the contents , images , spaces , font , are exactly matching with one another , and if even a single thing is not matching , it has to be reported in a PDF file , line by line .
> I have downloaded this , and tried converting the pcl file to PDF , but , when i try to read the converted PDF file in C# application , it doesn't read properly , and gives some vague text.
I've had no problems using this tool to convert PCL to PDF. But I'm sure its performance can vary depending on the PCL file.
> i can not read that converted file in C# application (itextsharp)
Can a PDF reader/viewer open it? If so, then the problem is with the C# program and/or iTextSharp.
> tries to compare whether the contents , images , spaces , font , are exactly matching with one another , and if even a single thing is not matching , it has to be reported in a PDF file , line by line
I can understand having "a team" do this manually. But based on the complexities of PCL and PDF files, I doubt that you'll be able to write a program to perform the comparison as well as your team of humans. Just my opinion, of course. Regards, Joe
I've had no problems using this tool to convert PCL to PDF. But I'm sure its performance can vary depending on the PCL file.
> i can not read that converted file in C# application (itextsharp)
Can a PDF reader/viewer open it? If so, then the problem is with the C# program and/or iTextSharp.
> tries to compare whether the contents , images , spaces , font , are exactly matching with one another , and if even a single thing is not matching , it has to be reported in a PDF file , line by line
I can understand having "a team" do this manually. But based on the complexities of PCL and PDF files, I doubt that you'll be able to write a program to perform the comparison as well as your team of humans. Just my opinion, of course. Regards, Joe
ASKER
Or you could use the PRN File Analyse tool in the PCL Paraphernalia application, available via http://www.pclparaphernalia.eu
what this tool does ,
what this tool does ,
The PRN File Analyse tool analyses a file containing PCL, interpreting the contents, so that you can see what PCL sequences are in the file; it makes things rather clearer than looking at the file using a text editor! For example:
It is not a PCL Viewer application.
... and I agree with Joe Winograd's conclusions as to whether or not you'd ever be able to do any meaningful comparisons of PCL and PDF documents
Offset Type Sequence Description
------------- --------------------- ---------------- ----------------------------------------------------
0000000000 PCL Parameterised <Esc>&l0O Orientation: Portrait
0000000005 PCL Parameterised <Esc>&u600D Unit-of-Measure (600 PCL units per inch)
0000000012 PCL Parameterised <Esc>&a0L Left Margin (column 0)
0000000017 PCL Parameterised <Esc>&l0E Top Margin (0 lines)
0000000022 PCL Parameterised <Esc>(19U Primary Font: Symbol Set (19U = Windows Latin 1 (CP 1252))
0000000027 PCL Parameterised <Esc>(s1p Primary Font: Spacing: Proportional
0000000032 10v Primary Font: Height (10 points)
0000000035 0s Primary Font: Style (Upright, solid)
0000000037 0b Primary Font: Stroke Weight: Medium
0000000039 16602T Primary Font: Typeface (16602 = Arial)
0000000045 PCL Parameterised <Esc>*p600x Cursor Position Horizontal (600 PCL units)
0000000052 600Y Cursor Position Vertical (600 PCL units)
0000000056 Data Exactly the same image data (A) with different raste
0000000107 r resolutions specified.
0000000132 PCL Parameterised <Esc>*p600x Cursor Position Horizontal (600 PCL units)
0000000139 750Y Cursor Position Vertical (750 PCL units)
0000000143 Data Printer scales up to printer resolution.
0000000183 PCL Parameterised <Esc>*p600x Cursor Position Horizontal (600 PCL units)
0000000190 1800Y Cursor Position Vertical (1800 PCL units)
0000000195 Data Image A @75 dpi
. . .
. . .It is not a PCL Viewer application.
... and I agree with Joe Winograd's conclusions as to whether or not you'd ever be able to do any meaningful comparisons of PCL and PDF documents
ASKER
with all different comments , what i can judge that, it is a difficult scenario, but , i am sure this is not rocket science , and there is a solution for this certainly,
if i convert PDF to PCL as given in one of the comments, will i be able to compare and find the difference
because i have tried reading PCL file in text format ,it is not possible to convert it to human readable format.
if i convert PDF to PCL as given in one of the comments, will i be able to compare and find the difference
because i have tried reading PCL file in text format ,it is not possible to convert it to human readable format.
ASKER
I appriciate all your efforts , for looking into the problem, though we are not close to the solution , but you people tried to reach to one , i understand , this is a new problem , but let us keep our ideas flow , and i will be more happy , if we can reach to a working solution , since it is my first interaction with Expert Exchange , I want to be optimistic , with the solutions.
> i am sure this is not rocket science
No...it's more difficult than rocket science. :)
> if i convert PDF to PCL as given in one of the comments, will i be able to compare and find the difference
Maybe, but as I stated in my first comment <http:#a39901930>, you should print the PDF to the same PCL-based printer that the PCL file came from in order to have the best hope for a successful comparison.
> it is my first interaction with Experts Exchange
Welcome to the EE community! We try very hard to help folks, but sometimes there just isn't an answer. The good news is that there usually is a solution. It is rare for a problem to go unsolved, but it does happen occasionally.
I'm going offsite now for several hours. I'll check back into this thread as soon as I return to see how you're doing. Regards, Joe
No...it's more difficult than rocket science. :)
> if i convert PDF to PCL as given in one of the comments, will i be able to compare and find the difference
Maybe, but as I stated in my first comment <http:#a39901930>, you should print the PDF to the same PCL-based printer that the PCL file came from in order to have the best hope for a successful comparison.
> it is my first interaction with Experts Exchange
Welcome to the EE community! We try very hard to help folks, but sometimes there just isn't an answer. The good news is that there usually is a solution. It is rare for a problem to go unsolved, but it does happen occasionally.
I'm going offsite now for several hours. I'll check back into this thread as soon as I return to see how you're doing. Regards, Joe
if you follow Joe says about printing the PDF to PCL file using the same print/driver you might be able to use the old DOS program fc with the /b (binary) switch. The program is still in Windows 7 and on server 2008r2 (I checked both)
With any of the suggestions made so far, it is quite likely that differences may be introduced by the conversion process:
For PCL->PDF, there are various utilities available, but from what I've read in the past, none of them can correctly handle every PCL construct.
For PDF->PCL, as pony10us and others have pointed out, you'd need to use the same printer driver as used to generate the PCL file to have any chance of comparison, but even then I suspect that there would be major differences, because the PDF reader (from which the print action is invoked) is perhaps likely to process the various objects (text, images, headers, footers, etc.) in a completely different order to the application (Word, etc.) from which the original PCL file was generated.
ASKER
if you follow Joe says about printing the PDF to PCL file using the same print/driver you might be able to use the old DOS program fc with the /b (binary) switch. The program is still in Windows 7 and on server 2008r2 (I checked both)
can you please tell me whether it can also tell me what is not matching , and give me the results , in another file. in human readable format.
The DOS fc (file compare) command (see http://technet.microsoft.com/en-us/library/bb490904.aspx ), when used with the /b (binary) switch, will compare two files on a byte-by-byte basis, and report the differences.
The report is made to 'standard output', which can be redirected to a file using the DOS > (redirection) operator
The report is made to 'standard output', which can be redirected to a file using the DOS > (redirection) operator
And the output of fc is intended primarily to be human readable
Using the following:
New Text Document 1.txt:
Help Me
1
2
3
4
5
6
7
8
9
0
me
New Text Document 2.txt
help Me
1
2
3
4
5
6
7
8
9
0
me
I ran fc /N "New Text Document 1.txt" "New Text Document 2.txt"
(The /N switch numbers the lines)
Results:
Comparing files New Text Document1.txt and NEW TEXT DOCUMENT2.TXT
***** New Text Document1.txt
1: Help Me
2: 1
***** NEW TEXT DOCUMENT2.TXT
1: help Me
2: 1
*****
Line 1 was different due to the case of the "H" and it will give the line after that is the same.
Adding the case insensitive switch /C:
fc /C /N "New Text Document 1.txt" "New Text Document 2.txt"
Results:
Comparing files New Text Document1.txt and NEW TEXT DOCUMENT2.TXT
FC: no differences encountered
This was on a text file but will show you an example that the results are human readable.
Using the following:
New Text Document 1.txt:
Help Me
1
2
3
4
5
6
7
8
9
0
me
New Text Document 2.txt
help Me
1
2
3
4
5
6
7
8
9
0
me
I ran fc /N "New Text Document 1.txt" "New Text Document 2.txt"
(The /N switch numbers the lines)
Results:
Comparing files New Text Document1.txt and NEW TEXT DOCUMENT2.TXT
***** New Text Document1.txt
1: Help Me
2: 1
***** NEW TEXT DOCUMENT2.TXT
1: help Me
2: 1
*****
Line 1 was different due to the case of the "H" and it will give the line after that is the same.
Adding the case insensitive switch /C:
fc /C /N "New Text Document 1.txt" "New Text Document 2.txt"
Results:
Comparing files New Text Document1.txt and NEW TEXT DOCUMENT2.TXT
FC: no differences encountered
This was on a text file but will show you an example that the results are human readable.
Hi Beyond,
I use a file manager called Total Commander:
http://www.ghisler.com/
It has an excellent file compare feature. It does an "intelligent" comparison, such as resynchronizing the comparison if entire lines are missing. It gives human readable output, with the differences in a red font. It has Next Difference and Previous Difference buttons so that it's easy to navigate through the changes. Here's what the comparison panel looks like:
 I have a proposal for you. Post a sample PCL and the corresponding PDF, i.e., samples of the files that you'd like to compare (make sure there is no sensitive/private information). I'll convert both ways (PCL-to-PDF, PDF-to-PCL), then use Total Commander to do the comparisons, and will post the results for you. I'm not confident that this will work well, but it's a worthwhile experiment to run. Regards, Joe
I have a proposal for you. Post a sample PCL and the corresponding PDF, i.e., samples of the files that you'd like to compare (make sure there is no sensitive/private information). I'll convert both ways (PCL-to-PDF, PDF-to-PCL), then use Total Commander to do the comparisons, and will post the results for you. I'm not confident that this will work well, but it's a worthwhile experiment to run. Regards, Joe
I use a file manager called Total Commander:
http://www.ghisler.com/
It has an excellent file compare feature. It does an "intelligent" comparison, such as resynchronizing the comparison if entire lines are missing. It gives human readable output, with the differences in a red font. It has Next Difference and Previous Difference buttons so that it's easy to navigate through the changes. Here's what the comparison panel looks like:
I have a proposal for you. Post a sample PCL and the corresponding PDF, i.e., samples of the files that you'd like to compare (make sure there is no sensitive/private information). I'll convert both ways (PCL-to-PDF, PDF-to-PCL), then use Total Commander to do the comparisons, and will post the results for you. I'm not confident that this will work well, but it's a worthwhile experiment to run. Regards, Joe
ASKER
Are you certain that it is a PCL file?
.prn are "normally" PostScript but not always so just checking. It really depends on the printer driver used when you print to file. I know, again it comes back to the driver. :)
.prn are "normally" PostScript but not always so just checking. It really depends on the printer driver used when you print to file. I know, again it comes back to the driver. :)
I've no idea what the content of the sample1.prn file is, but it's certainly not PCL.
pony10us,
I haven't looked at that file yet, but to answer your question, a PRN file is a PCL file if you do a "Print to file" to a PCL-based printer; a PRN file is a PS file if you do a "Print to file" to a PS-based printer. Regards, Joe
I haven't looked at that file yet, but to answer your question, a PRN file is a PCL file if you do a "Print to file" to a PCL-based printer; a PRN file is a PS file if you do a "Print to file" to a PS-based printer. Regards, Joe
The sample1.prn file is actually a .xps (XML Paper Specification file), created by the PCL2PDF application (evaluation version).
You can also treat it like a .zip file, in order to see the internal construction.
You can also treat it like a .zip file, in order to see the internal construction.
Joe,
I understand that. I just wanted to be sure BeyondBGCM realized it.
I understand that. I just wanted to be sure BeyondBGCM realized it.
>> ... a PRN file is a PCL file ...
All file extensions are merely conventions to allow simple mapping of applications to file types.
A .prn file (or a .bmp file, or a .exe file, etc.) can contain anything you like; it just becomes rather difficult to open such files if they don't contain what the file extension naming convention suggests they should.
Having said that, I agree with Joe Winograd that the .prn extension is normally associated with print files (usually captured using the 'print to file' option); they will contain PCL5, or PCL3GUI, or PostScript, or PCL XL, or whatever is the Page Description Language used by the printer driver which creates them.
All file extensions are merely conventions to allow simple mapping of applications to file types.
A .prn file (or a .bmp file, or a .exe file, etc.) can contain anything you like; it just becomes rather difficult to open such files if they don't contain what the file extension naming convention suggests they should.
Having said that, I agree with Joe Winograd that the .prn extension is normally associated with print files (usually captured using the 'print to file' option); they will contain PCL5, or PCL3GUI, or PostScript, or PCL XL, or whatever is the Page Description Language used by the printer driver which creates them.
Beyond,
As far as I can tell, <sample1.prn> is neither PCL nor PS (WinPCLtoPDF converts it to garbage). Also, I looked at the PDF file. It is fairly complex, with rows, columns, shaded areas, etc. I do not believe you'll have much luck in comparing a PCL file to it (in order to detect the differences).
What are you really trying to achieve here? Compare a filled-in form to an empty one in order to extract the data? Compare one resident's filled-in form to another resident's filled-in form? Make sure the same resident hasn't submitted the same form multiple times? Once we understand exactly what you're trying to achieve, we may be able to come up with better ways to do it, but I don't think comparing PCL and PDF files is going to work for you.
Why are you receiving PCL files? Can you stop that? Perhaps have people send filled-in PDF files? I think you need a different approach to solving the problem. Regards, Joe
As far as I can tell, <sample1.prn> is neither PCL nor PS (WinPCLtoPDF converts it to garbage). Also, I looked at the PDF file. It is fairly complex, with rows, columns, shaded areas, etc. I do not believe you'll have much luck in comparing a PCL file to it (in order to detect the differences).
What are you really trying to achieve here? Compare a filled-in form to an empty one in order to extract the data? Compare one resident's filled-in form to another resident's filled-in form? Make sure the same resident hasn't submitted the same form multiple times? Once we understand exactly what you're trying to achieve, we may be able to come up with better ways to do it, but I don't think comparing PCL and PDF files is going to work for you.
Why are you receiving PCL files? Can you stop that? Perhaps have people send filled-in PDF files? I think you need a different approach to solving the problem. Regards, Joe
A screenshot of the sample1.prn file, opened as a .xps file using the Windows 8.1 XPS Viewer:

... and a view of the file as seen by WinZip, if treated as a .zip file:
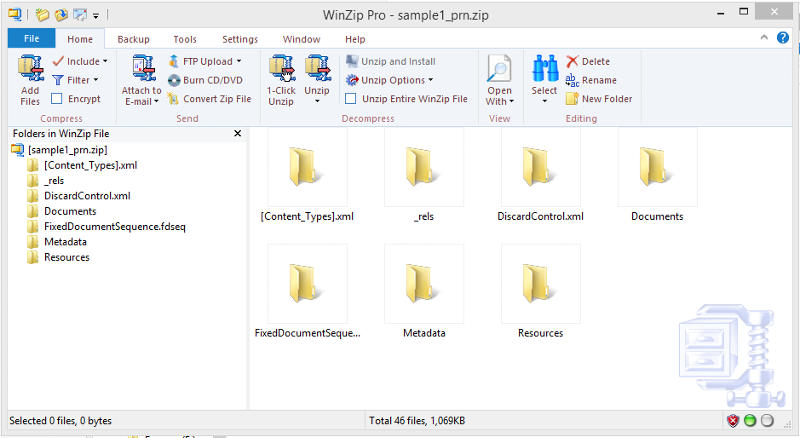
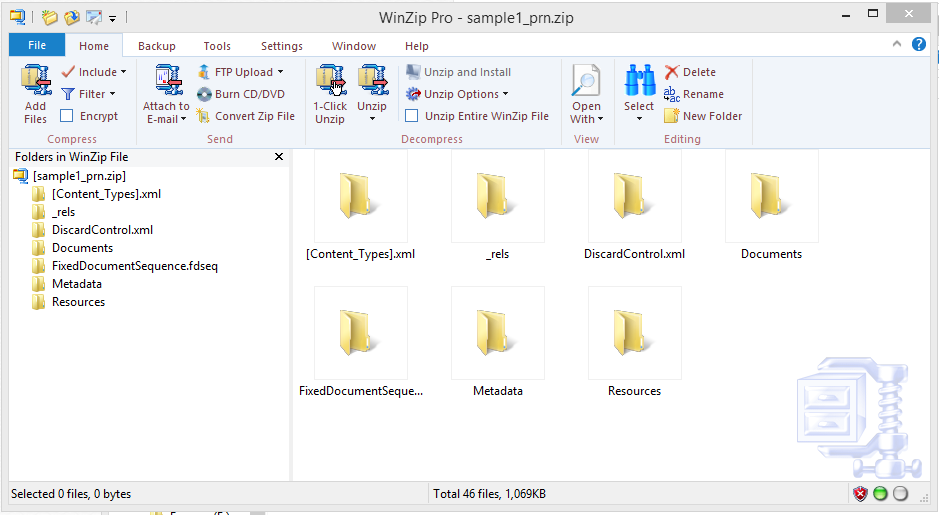
... I think you need a different approach to solving the problem ...
I couldn't agree more.
Ah, XPS...great catch, DansDadUK! I just printed the PDF to the MS XPS Document Writer in W7. There's no hope in comparing the two XPS files. Likewise, I printed the XPS file to the Adobe PDF print driver — also no hope in comparing the two PDF files. Regards, Joe
... I think you need a different approach to solving the problem ...
I couldn't agree more.
I also agree. It seems that the comparison should occur prior to creation of the .prn file.
The only thing that should be different between the stored document and the printed version (even if you print to file) is that the latter gets code added to tell the specific printer what you want it to do such as duplex, landscape, etc.
> It seems that the comparison should occur prior to creation of the .prn file.
My hip-shot is that he should discard the whole idea of printing to a PRN file. I'd be tempted to have the residents fill in the PDF form and then process the FDF data. This would provide a reliable way of doing the comparisons and is something that he should be able to do relatively easily in his C# code with the iTextSharp library. Regards, Joe
My hip-shot is that he should discard the whole idea of printing to a PRN file. I'd be tempted to have the residents fill in the PDF form and then process the FDF data. This would provide a reliable way of doing the comparisons and is something that he should be able to do relatively easily in his C# code with the iTextSharp library. Regards, Joe
ASKER
hi
this is the same file , but since the uploader of your site doesn't accept PCL file(it throws error while uploading it) , i had to change it to PRN .
sample1--2-.prn
this is the same file , but since the uploader of your site doesn't accept PCL file(it throws error while uploading it) , i had to change it to PRN .
sample1--2-.prn
ASKER
Joe , it would have been great, if they could have changed their requirements , but they don't like it , you know the customers they resist change in their requirement.
> this is the same file
OK, this one really is a PCL file and WinPCLtoPDF converts it pretty well. The PDF file created by WinPCLtoPDF is attached. That said, I still don't see any way to do a meaningful comparison.
You haven't answered my earlier questions: What you are you really trying to achieve here? Compare a filled-in form to an empty one in order to extract the data? Compare one resident's filled-in form to another resident's filled-in form? Make sure the same resident hasn't submitted the same form multiple times? As I said before, once we understand exactly what you're trying to achieve, we may be able to come up with better ways to do it, but I don't think comparing PCL and PDF files is going to work.
I understand that customers resist change, but if you are a consultant to this customer, I believe that your best consultancy service to them would be to recommend changing their approach to this problem. Sometimes customers don't like to hear what their consultants have to say, but in this case, I think you and your customer will both be well-served with a different approach. Of course, I'd like to understand the "real" problem better, as in the questions I asked above. Regards, Joe
sample1--2-converted-by-WinPCLto.pdf
OK, this one really is a PCL file and WinPCLtoPDF converts it pretty well. The PDF file created by WinPCLtoPDF is attached. That said, I still don't see any way to do a meaningful comparison.
You haven't answered my earlier questions: What you are you really trying to achieve here? Compare a filled-in form to an empty one in order to extract the data? Compare one resident's filled-in form to another resident's filled-in form? Make sure the same resident hasn't submitted the same form multiple times? As I said before, once we understand exactly what you're trying to achieve, we may be able to come up with better ways to do it, but I don't think comparing PCL and PDF files is going to work.
I understand that customers resist change, but if you are a consultant to this customer, I believe that your best consultancy service to them would be to recommend changing their approach to this problem. Sometimes customers don't like to hear what their consultants have to say, but in this case, I think you and your customer will both be well-served with a different approach. Of course, I'd like to understand the "real" problem better, as in the questions I asked above. Regards, Joe
sample1--2-converted-by-WinPCLto.pdf
ASKER
ok, i apologise , for not answering your question, actually i had answered that questions very early that , i need to find out the difference between PCL and PDF files from 2 different sources , and send the difference in a seperate file (whether it is a Font , word, spacing , image ) in other words byte by byte .
any approach is welcome , they are only interested in finding out what is the difference , if it is not , then simple no change , else what is the change .
they are doing it presently manually , and this is a lot of work for them (and not very intelligent too ). so that is where i am looking out for a solution.
any approach is welcome , they are only interested in finding out what is the difference , if it is not , then simple no change , else what is the change .
they are doing it presently manually , and this is a lot of work for them (and not very intelligent too ). so that is where i am looking out for a solution.
ASKER
when i say manually , i mean , they print the PCL file , and print the PDF file and then they compare manually , which you can understand , not a wise use of time and paper.
A few more comments:
The new sample1--2-.prn file does indeed contain PCL; it basically defines a PCL macro, executes it, then issues a FormFeed:
A more verbose analysis, showing the content of the macro, is attached.
This shows that within the macro, a large number of other macros (not defined in this PCL, as far as I can see from a quick glance) are executed; if the macros are not present, the printer will ignore the execute calls, but if they were present, the output could be totally different!
I still have to agree with Joe Winograd and pony10us that comparing PCL with PDF (of necessity involving converting one or the other to the same format for comparison purposes) is not really feasible.
You could employ a large team of programmers for several years, and (in my opinion) the end result would be that you might end up with something that worked 10% of the time, but no more.
The only way I can see of doing comparisons at this stage would perhaps be if it was done on the basis of rasterising both printouts, then comparing the raster (bitmap) images - but this would not satisfy your requirement of noting differences in fonts, spacing, etc. at the object level.
sample1--2-.prn-analysis.txt
The new sample1--2-.prn file does indeed contain PCL; it basically defines a PCL macro, executes it, then issues a FormFeed:
Offset Type Sequence Description
------------- --------------------- ---------------- ----------------------------------------------------
0000000000 PCL Parameterised <Esc>&f24367Y Macro Control ID (identifer = 24367)
0000000009 PCL Parameterised <Esc>&f0X Macro Control: Start Macro Definition
Comment Preference options inhibit display of macro contents
0000025146 PCL Parameterised <Esc>&f1X Macro Control: Stop Macro Definition
0000025151 PCL Parameterised <Esc>&f9X Macro Control: Make Macro Temporary
0000025156 PCL Parameterised <Esc>&f2X Macro Control: Execute Macro
0000025161 PCL Control Code 0x0c <FF>: Form FeedA more verbose analysis, showing the content of the macro, is attached.
This shows that within the macro, a large number of other macros (not defined in this PCL, as far as I can see from a quick glance) are executed; if the macros are not present, the printer will ignore the execute calls, but if they were present, the output could be totally different!
I still have to agree with Joe Winograd and pony10us that comparing PCL with PDF (of necessity involving converting one or the other to the same format for comparison purposes) is not really feasible.
You could employ a large team of programmers for several years, and (in my opinion) the end result would be that you might end up with something that worked 10% of the time, but no more.
The only way I can see of doing comparisons at this stage would perhaps be if it was done on the basis of rasterising both printouts, then comparing the raster (bitmap) images - but this would not satisfy your requirement of noting differences in fonts, spacing, etc. at the object level.
sample1--2-.prn-analysis.txt
ASKER
I still have to agree with Joe Winograd and pony10us that comparing PCL with PDF (of necessity involving converting one or the other to the same format for comparison purposes) is not really feasible.
hi
does everyone agree on this , if yes, can i take meaning that , there is no direct or indirect solution for this .
I think that Joe summarised it best with his comment:
No...it's more difficult than rocket science. :)
ASKER
I still want to thank you people for putting at least for your efforts , and i think some one from HP team , who has developed this , can help us to find the soultion.:)
> there is no direct or indirect solution for this
If you are defining the problem as comparing a PCL to a PDF, then the above statement is correct. But what I am trying to emphasize is that this is not the "real" problem. I'm attempting to get at the heart of the "real" problem.
The form is the MINIMUM DATA SET (MDS) — VERSION 2.0, FOR NURSING HOME RESIDENT ASSESSMENT AND CARE SCREENING, BASIC ASSESSMENT TRACKING FORM, published by the Centers for Medicare and Medicaid Services (CMS). The one you posted is the October 1995 version. Here's a link to the latest version, September 2000 (with some updates as late as May 2005):
http://www.cms.gov/Medicare/Quality-Initiatives-Patient-Assessment-Instruments/NursingHomeQualityInits/downloads/MDS20MDSAllforms.pdf
Look at the form. Someone (probably a CMS auditor) is filling in the data for each resident in a nursing home. So, what is the real problem — are two CMS auditors filling in the forms independently, and then the CMS wants to compare them in order to see where the auditors vary in their opinions? Or maybe a CMS auditor is filling in one form and an external (non-government) auditor is filling in another form, and then the CMS wants to compare those?
Whatever the situation is, the CMS needs to take a different approach if they want to compare forms. I think data (via FDF) is probably the way to go, but I'd need to know more about the situation in order to make an intelligent recommendation. Regards, Joe
If you are defining the problem as comparing a PCL to a PDF, then the above statement is correct. But what I am trying to emphasize is that this is not the "real" problem. I'm attempting to get at the heart of the "real" problem.
The form is the MINIMUM DATA SET (MDS) — VERSION 2.0, FOR NURSING HOME RESIDENT ASSESSMENT AND CARE SCREENING, BASIC ASSESSMENT TRACKING FORM, published by the Centers for Medicare and Medicaid Services (CMS). The one you posted is the October 1995 version. Here's a link to the latest version, September 2000 (with some updates as late as May 2005):
http://www.cms.gov/Medicare/Quality-Initiatives-Patient-Assessment-Instruments/NursingHomeQualityInits/downloads/MDS20MDSAllforms.pdf
Look at the form. Someone (probably a CMS auditor) is filling in the data for each resident in a nursing home. So, what is the real problem — are two CMS auditors filling in the forms independently, and then the CMS wants to compare them in order to see where the auditors vary in their opinions? Or maybe a CMS auditor is filling in one form and an external (non-government) auditor is filling in another form, and then the CMS wants to compare those?
Whatever the situation is, the CMS needs to take a different approach if they want to compare forms. I think data (via FDF) is probably the way to go, but I'd need to know more about the situation in order to make an intelligent recommendation. Regards, Joe
> some one from HP team , who has developed this
What has HP developed? As I mentioned above, the form is a standard government form, an old version of MDS 2.0, from the CMS. When you say that HP developed "this", what is "this"?
What has HP developed? As I mentioned above, the form is a standard government form, an old version of MDS 2.0, from the CMS. When you say that HP developed "this", what is "this"?
I think there is a key element that has been overlooked:
Being from 2 different sources will almost certainly introduce variances as the odds that both sources have the exact same printer is almost nill.
Now if you are only trying to compare the difference between the actual form you could try stripping the PCL code from that file and comparing but I really don't know if that would even do the job.
I guess the real question is why is a different font, word spacing, etc. so important? I could see a difference in the image might be important. What is the final disposition of the two files? Electronic filing of one and disposal of the other?
Ultimately, I have to agree to a point with:
This is a task that, if it is possible (most everything is), it could take years and a team to develop.
difference between PCL and PDF files from 2 different sources
Being from 2 different sources will almost certainly introduce variances as the odds that both sources have the exact same printer is almost nill.
Now if you are only trying to compare the difference between the actual form you could try stripping the PCL code from that file and comparing but I really don't know if that would even do the job.
I guess the real question is why is a different font, word spacing, etc. so important? I could see a difference in the image might be important. What is the final disposition of the two files? Electronic filing of one and disposal of the other?
Ultimately, I have to agree to a point with:
No...it's more difficult than rocket science. :)
This is a task that, if it is possible (most everything is), it could take years and a team to develop.
ASKER
there are many questions i see around, few of them i can answer here .
1. just ignore the forms i have sent , as that is a sample form , i have picked up from a sample i had , and is not the real problem files.
2.HP means , Hewlett Packard , which has developed the PCL format (an industry standard).
3. other approach i have in my mind , is that , i need to find out the code , which converts the PCL file into PDF (as many license softwares do) ,and then use that code to drive my own logic to compare PDF .
but having said that , the code which these companies are using , is hard to get , only if any open source is helping us , where we can read those dlls and use for our purpose.
1. just ignore the forms i have sent , as that is a sample form , i have picked up from a sample i had , and is not the real problem files.
2.HP means , Hewlett Packard , which has developed the PCL format (an industry standard).
3. other approach i have in my mind , is that , i need to find out the code , which converts the PCL file into PDF (as many license softwares do) ,and then use that code to drive my own logic to compare PDF .
but having said that , the code which these companies are using , is hard to get , only if any open source is helping us , where we can read those dlls and use for our purpose.
> just ignore the forms i have sent...is not the real problem files
Wish you hadn't done that...or, at the very least, let us know that's what you did, when you did it.
> HP means , Hewlett Packard , which has developed the PCL format (an industry standard).
Well, of course HP developed PCL, but I don't think HP will be much help to you now.
> other approach i have in my mind , is that , i need to find out the code , which converts the PCL file into PDF (as many license softwares do) ,and then use that code to drive my own logic to compare PDF
OK, it seems we can't stop you from thinking that the problem is comparing a PCL file to a PDF file. Since the form you provided was "a sample...not the real problem files", we don't have a clue what the real problem is. If you'd like to acquire the source code that converts PCL into PDF (WinPCLtoPDF), I suggest you contact the author, Edward Mendelson, whose email address is em36 [at] columbia [dot] edu (disguised slightly to avoid the spambots).
I, for one, think that we have taken this EE question as far as we can. Good luck in your efforts. Regards, Joe
Wish you hadn't done that...or, at the very least, let us know that's what you did, when you did it.
> HP means , Hewlett Packard , which has developed the PCL format (an industry standard).
Well, of course HP developed PCL, but I don't think HP will be much help to you now.
> other approach i have in my mind , is that , i need to find out the code , which converts the PCL file into PDF (as many license softwares do) ,and then use that code to drive my own logic to compare PDF
OK, it seems we can't stop you from thinking that the problem is comparing a PCL file to a PDF file. Since the form you provided was "a sample...not the real problem files", we don't have a clue what the real problem is. If you'd like to acquire the source code that converts PCL into PDF (WinPCLtoPDF), I suggest you contact the author, Edward Mendelson, whose email address is em36 [at] columbia [dot] edu (disguised slightly to avoid the spambots).
I, for one, think that we have taken this EE question as far as we can. Good luck in your efforts. Regards, Joe
ASKER
]we don't have a clue what the real problem is. If you'd like to acquire the source code that converts
I think , you didn't get what i meant , the real problem file has no fixed format , it can be anyting , since i can not share the real problem file ,because it is sensitive .
and the problem solution should be general, which should address any type of PCL file with corrosponding PDF file .
thanks for sharing the email address , i will try that , hope to get a good response.
{kind=link}
ASKER
I liked this, yet, I have a habit of believing everything is possible, may be not now , but later , so i can't give up this ....
and i agreed that this problem has no easy solution , but each difficult problem is source of real growth ....
and i sincerly appriciate , your support , because i see the efforts .
and i agreed that this problem has no easy solution , but each difficult problem is source of real growth ....
and i sincerly appriciate , your support , because i see the efforts .
All I can say now is "good luck", but I believe that you will ultimately be disappointed.
...everything is possible, may be not now , but later...
I agree. That's what keeps us moving forward.
address any type of PCL file
This one I am not sure I fully agree with. I have a complete list of codes that IBM uses and also calls Printer Control Language. While they are quite similar to HP's there are some differences.
In any case, the PDF would not have the PCL code which is why I mentioned striping the from the PCL file prior to comparison. Using FC probably won't work since the PCL code will be at the beginning causing a line by line comparison to always be off.
ASKER
In any case, the PDF would not have the PCL code which is why I mentioned striping the from the PCL file prior to comparison
ok, so do you mean , I should have a code to read the PCL file(it is hardest but most certain) , which gives us the PDF equivalent text, and then compare it with original PDF .....
... read the PCL file(it is hardest but most certain) ...
But it is by no means "certain"; see my comments in post 39903046
ASKER
I can accept that , the solution to this problem is not easy , yet since this is a requirement which we have to accomplish any how.
my approach to this problem is - I should be able to read PCL files and able to convert them into PDF , in this process i can start comparing the converted text and images with original PDF .
I know it is very difficult , but i will have to do it . if you can suggest me some good API which can help me to do that , it will be great.
my approach to this problem is - I should be able to read PCL files and able to convert them into PDF , in this process i can start comparing the converted text and images with original PDF .
I know it is very difficult , but i will have to do it . if you can suggest me some good API which can help me to do that , it will be great.
> I should be able to read PCL files and able to convert them into PDF
Already been discussed, but to reiterate, use WinPCLtoPDF for this:
http://www.columbia.edu/~em36/pcltopdf.html
As I already mentioned, the author is Edward Mendelson, whose email address is em36 [at] columbia [dot] edu (disguised slightly to avoid the spambots).
> i can start comparing the converted text and images with original PDF...suggest me some good API which can help me to do that
Take a look at ByteScout's PDF Extractor SDK:
http://bytescout.com/products/developer/pdfextractorsdk/index.html
It allows you to convert the PDF to text, as well as extract the images from a PDF. Once the text and images are extracted, you may be able to compare them. This SDK has worked well for me (although not perfectly), but I've used it only for text extraction, not images. Here are two other text extractors that I've used in programs...they also work well, but also not perfectly:
A-PDF Text Extractor Command Line:
http://www.a-pdf.com/text/cmd.htm
Xpdf library:
http://www.foolabs.com/xpdf/download.html
Xpdf contains numerous modules. The one you want is pdftotext, which I've used in many programs. Here are two examples in EE articles:
https://www.experts-exchange.com/Software/Misc/A_11173-How-To-Rename-Move-a-Batch-of-PDF-Files-Based-on-Contents-of-the-Files.html
https://www.experts-exchange.com/Software/Misc/A_11211-How-To-Split-Rename-Move-a-Batch-of-PDF-Files-Based-on-Contents-of-the-Files.html
Regards, Joe
Already been discussed, but to reiterate, use WinPCLtoPDF for this:
http://www.columbia.edu/~em36/pcltopdf.html
As I already mentioned, the author is Edward Mendelson, whose email address is em36 [at] columbia [dot] edu (disguised slightly to avoid the spambots).
> i can start comparing the converted text and images with original PDF...suggest me some good API which can help me to do that
Take a look at ByteScout's PDF Extractor SDK:
http://bytescout.com/products/developer/pdfextractorsdk/index.html
It allows you to convert the PDF to text, as well as extract the images from a PDF. Once the text and images are extracted, you may be able to compare them. This SDK has worked well for me (although not perfectly), but I've used it only for text extraction, not images. Here are two other text extractors that I've used in programs...they also work well, but also not perfectly:
A-PDF Text Extractor Command Line:
http://www.a-pdf.com/text/cmd.htm
Xpdf library:
http://www.foolabs.com/xpdf/download.html
Xpdf contains numerous modules. The one you want is pdftotext, which I've used in many programs. Here are two examples in EE articles:
https://www.experts-exchange.com/Software/Misc/A_11173-How-To-Rename-Move-a-Batch-of-PDF-Files-Based-on-Contents-of-the-Files.html
https://www.experts-exchange.com/Software/Misc/A_11211-How-To-Split-Rename-Move-a-Batch-of-PDF-Files-Based-on-Contents-of-the-Files.html
Regards, Joe
ASKER
Joe,
I can extract images and Text from PDF tyhrough some Open Source APIs, but , i don't have still , how to read PCL files, the example(http://www.columbia.edu/~em36/pcltopdf.html). you have shared with me , i have tried many times, it gives me PDF file from PCL , but it doesn't allow me to read converted PDF file in my C# programme.
I can extract images and Text from PDF tyhrough some Open Source APIs, but , i don't have still , how to read PCL files, the example(http://www.columbia.edu/~em36/pcltopdf.html). you have shared with me , i have tried many times, it gives me PDF file from PCL , but it doesn't allow me to read converted PDF file in my C# programme.
> but it doesn't allow me to read converted PDF file in my C# programme.
This has nothing to do with the converter. The converter may be run by your C# program as a command line call. I don't know C#, but I'm sure it has the ability to run a command line program. For example, one language I use a lot has a RunWait statement, which means to run the command line program and wait until it is done. I'll be shocked if C# does not have something similar. So all you have to do in your C# program is execute a command line call to <WinPCLtoPDF.exe>. Here's a description of its command line parameters:
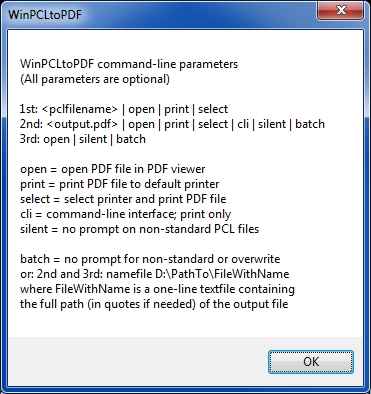 Then your C# program can read the PDF file created by WinPCLtoPDF via any PDF-reading library that you'd like to use. Regards, Joe
Then your C# program can read the PDF file created by WinPCLtoPDF via any PDF-reading library that you'd like to use. Regards, Joe
This has nothing to do with the converter. The converter may be run by your C# program as a command line call. I don't know C#, but I'm sure it has the ability to run a command line program. For example, one language I use a lot has a RunWait statement, which means to run the command line program and wait until it is done. I'll be shocked if C# does not have something similar. So all you have to do in your C# program is execute a command line call to <WinPCLtoPDF.exe>. Here's a description of its command line parameters:
Then your C# program can read the PDF file created by WinPCLtoPDF via any PDF-reading library that you'd like to use. Regards, Joe
ASKER
i think you are not getting my point when i say , i am not able to read the converted PDF file in C# , C# is a powerful language , but any language , can not read the PDF which is converted by above tool.... just try that.
ASKER
I have been in touch with Edward, and , what he suggests , that he has written the code for reading PCL files in VC++, and that is one of the solution , to read the PCL file.
can you help me to write this program , if you can suggests some good reading to hint the same , will be also great.
can you help me to write this program , if you can suggests some good reading to hint the same , will be also great.
I think you are not getting my point when I say that this has nothing to do with the PCL converter. The converter makes a PDF file. Period. Then you'll need a tool (callable from a procedural language, such as C#) that can read a PDF. There are lots of libraries out there that can read PDFs. I've mentioned several of them in a previous post (http:#a39924762), such as ByteScout's PDF Extractor SDK, A-PDF's Text Extractor Command Line, and Xpdf's pdftotext. In your very first post, you mentioned iTextSharp and said that it cannot read a PCL file. Of course it can't! So use WinPCLtoPDF to convert it from PCL to PDF and then use iTextSharp to read the converted PDF.
In summary, you have two choices to read a PDF: (1) use a program/subroutine that someone else has already written (as suggested several times in this thread) or (2) write your own code to read a PDF. Do you understand that these are your two choices? Is there anything not clear about these two choices?
Likewise, you have two choices to read a PCL: (1) use a program/subroutine that someone else has already written (the only one I'm aware of is WinPCLtoPDF, as suggested several times in this thread) or (2) write your own code to read a PCL. Do you understand that these are your two choices? Is there anything not clear about these two choices?
Regards, Joe
In summary, you have two choices to read a PDF: (1) use a program/subroutine that someone else has already written (as suggested several times in this thread) or (2) write your own code to read a PDF. Do you understand that these are your two choices? Is there anything not clear about these two choices?
Likewise, you have two choices to read a PCL: (1) use a program/subroutine that someone else has already written (the only one I'm aware of is WinPCLtoPDF, as suggested several times in this thread) or (2) write your own code to read a PCL. Do you understand that these are your two choices? Is there anything not clear about these two choices?
Regards, Joe
ASKER
In your very first post, you mentioned iTextSharp and said that it cannot read a PCL file. Of course it can't! So use WinPCLtoPDF to convert it from PCL to PDF and then use iTextSharp to read the converted PDF.
I know i can not read PCL file in itext Sharp, I know i can not read PCL file in itext sharp
I know i can not read PCL file in itextsharp :)
I have used this option , before posting my question on EE, and found that converted PDF file is not possible to read using Itext Sharp, I have written this thing more than 10 times here .
I know i can not read PCL file in itext Sharp, I know i can not read PCL file in itext sharp
I know i can not read PCL file in itextsharp :)
I have used this option , before posting my question on EE, and found that converted PDF file is not possible to read using Itext Sharp, I have written this thing more than 10 times here .
ASKER
ok, let's close this thread. it is not leading to solution , WINPCLTOPDF , converted PDF , can not be read by ItextSharp
WINPCLTOPDF , converted PDF , can not be read by ItextSharp
WINPCLTOPDF , converted PDF , can not be read by ItextSharp
WINPCLTOPDF , converted PDF , can not be read by ItextSharp
WINPCLTOPDF , converted PDF , can not be read by ItextSharp
WINPCLTOPDF , converted PDF , can not be read by ItextSharp
WINPCLTOPDF , converted PDF , can not be read by ItextSharp
ASKER
I am repeatedly saying , i have spent over a month , and tried all solutions which you people are suggesting , before coming to EE , including WinPCLTOPDF , and found it not working .
> I have been in touch with Edward, and , what he suggests , that he has written the code for reading PCL files in VC++, and that is one of the solution , to read the PCL file.
Our messages just crossed. Here's the thing — I don't see why it's a problem to call WinPCLtoPDF on the command line in C#. Surely C# can do that. If you simply Google "c# command line calls", you'll figure it out. Here's just one example:
http://social.msdn.microsoft.com/Forums/vstudio/en-US/c9a884f3-3333-455f-9218-f2c8e978b8b5/how-to-invoke-command-line-from-c?forum=csharpgeneral
All you have to do is execute a command line like this in your program:
winpcltopdf.exe <sourcepcl> <convertedpdf> batch
where <sourcepcl> is the input PCL file and <convertedpdf> is the converted PDF file created by WinPCLtoPDF and "batch" is a parameter that tells WinPCLtoPDF it is running in a batch file and to suppress prompts and error messages. Regards, Joe
Our messages just crossed. Here's the thing — I don't see why it's a problem to call WinPCLtoPDF on the command line in C#. Surely C# can do that. If you simply Google "c# command line calls", you'll figure it out. Here's just one example:
http://social.msdn.microsoft.com/Forums/vstudio/en-US/c9a884f3-3333-455f-9218-f2c8e978b8b5/how-to-invoke-command-line-from-c?forum=csharpgeneral
All you have to do is execute a command line like this in your program:
winpcltopdf.exe <sourcepcl> <convertedpdf> batch
where <sourcepcl> is the input PCL file and <convertedpdf> is the converted PDF file created by WinPCLtoPDF and "batch" is a parameter that tells WinPCLtoPDF it is running in a batch file and to suppress prompts and error messages. Regards, Joe
Our messages crossed again. Simple question for you: Do you know how to run a command line program in your C# program? If not, figure that out, and then use that technique to run the command line WinPCLtoPDF with appropriate parameters. Regards, Joe
> WINPCLTOPDF , converted PDF , can not be read by ItextSharp
WinPCLtoPDF is the only PCL to PDF conversion tool that I know of. I see two choices for you: (1) Try something besides iTextSharp to see if it can read the PDF created by WinPCLtoPDF. Btw, I've had no problems getting good ol' Adobe Reader to read PDFs created by WinPCLtoPDF. (2) Write your own code to convert the PCL to a PDF that iTextSharp can handle. Perhaps Edward's code is a good starting point, if he's willing to provide it. Regards, Joe
WinPCLtoPDF is the only PCL to PDF conversion tool that I know of. I see two choices for you: (1) Try something besides iTextSharp to see if it can read the PDF created by WinPCLtoPDF. Btw, I've had no problems getting good ol' Adobe Reader to read PDFs created by WinPCLtoPDF. (2) Write your own code to convert the PCL to a PDF that iTextSharp can handle. Perhaps Edward's code is a good starting point, if he's willing to provide it. Regards, Joe
ASKER
Joe,
I don't want to mention that , I am an ex Microsoft Employee, with 10 years of experience in .net , so i know how to call a Command Line app from C# and little beyond this level . :)
I don't know ,why i am stretching this thread so much , somewhere i have a habbit of not giving up so easily(it's not good always).
(1) Try something besides iTextSharp to see if it can read the PDF created by WinPCLtoPDF.
iTextSharp is the only freeware , and it works wonderfully with other things , but only in this case it doesn't.
Btw, I've had no problems getting good ol' Adobe Reader to read PDFs created by WinPCLtoPDF.
this will not work if i open it in any high level languages such as C# ,JAVA.
(2) Write your own code to convert the PCL to a PDF that iTextSharp can handle. Perhaps Edward's code is a good starting point, if he's willing to provide it. Regards, Joe
Yes , this is the one solution, where i can look into it , if you can help me in this . it will be great.
Our messages crossed again. Simple question for you: Do you know how to run a command line program in your C# program? If not, figure that out, and then use that technique to run the command line WinPCLtoPDF with appropriate parameters. Regards, Joe
I don't want to mention that , I am an ex Microsoft Employee, with 10 years of experience in .net , so i know how to call a Command Line app from C# and little beyond this level . :)
I don't know ,why i am stretching this thread so much , somewhere i have a habbit of not giving up so easily(it's not good always).
(1) Try something besides iTextSharp to see if it can read the PDF created by WinPCLtoPDF.
iTextSharp is the only freeware , and it works wonderfully with other things , but only in this case it doesn't.
Btw, I've had no problems getting good ol' Adobe Reader to read PDFs created by WinPCLtoPDF.
this will not work if i open it in any high level languages such as C# ,JAVA.
(2) Write your own code to convert the PCL to a PDF that iTextSharp can handle. Perhaps Edward's code is a good starting point, if he's willing to provide it. Regards, Joe
Yes , this is the one solution, where i can look into it , if you can help me in this . it will be great.
>> ... read the PDF created by WinPCLtoPDF.
>> ... iTextSharp is the only freeware , and it works wonderfully with other things , but only in this case it doesn't ...
In what way doesn't it work?
>> ...Write your own code to convert the PCL to a PDF ...
Unless you find some-one who's already done this, and is willing to provide you with the code (free or not), then I reckon you'll still be working on this (without complete satisfaction with the results) in 10 years time!
Why can you not provide some simple sample files (one PCL, the other PDF) which demonstrate the type of comparison you want, so that we have a (better) understanding of what you are trying to achieve?
Surely you can generate sample test files which don't contain sensitive data?
>> ... iTextSharp is the only freeware , and it works wonderfully with other things , but only in this case it doesn't ...
In what way doesn't it work?
Does it return an error message (e.g. indicating that the PDF file is corrupt)?
Or is it that it just doesn't return the data in a form which you want it?
Or what?
... and if you open the (converted) PDF file manually with (say) Adobe Reader, does it process the file OK?
>> ...Write your own code to convert the PCL to a PDF ...
Unless you find some-one who's already done this, and is willing to provide you with the code (free or not), then I reckon you'll still be working on this (without complete satisfaction with the results) in 10 years time!
Why can you not provide some simple sample files (one PCL, the other PDF) which demonstrate the type of comparison you want, so that we have a (better) understanding of what you are trying to achieve?
Surely you can generate sample test files which don't contain sensitive data?
If you use a PDF analyser (e.g. http://download.cnet.com/PDF-Analyzer/3000-10250_4-10946543.html ), what does this tell you about the structures of your native PDF and converted-PCL-to-PDF files?
If the structures are radically different, then you'll never be able to do a meaningful comparison.
If the structures are radically different, then you'll never be able to do a meaningful comparison.
ASKER
>> ... read the PDF created by WinPCLtoPDF.
>> ... iTextSharp is the only freeware , and it works wonderfully with other things , but only in this case it doesn't ...
In what way doesn't it work?
•Does it return an error message (e.g. indicating that the PDF file is corrupt)?
yes, it returns some garbage code , which is not possible to read.
•Or is it that it just doesn't return the data in a form which you want it?
yes, it returns some garbage code , which is not possible to read.
•Or what?
•... and if you open the (converted) PDF file manually with (say) Adobe Reader, does it process the file OK?
yes, I can read it properly in that case.
>> ...Write your own code to convert the PCL to a PDF ...
Unless you find some-one who's already done this, and is willing to provide you with the code (free or not), then I reckon you'll still be working on this (without complete satisfaction with the results) in 10 years time!
it's scary.
Why can you not provide some simple sample files (one PCL, the other PDF) which demonstrate the type of comparison you want, so that we have a (better) understanding of what you are trying to achieve?
Surely you can generate sample test files which don't contain sensitive data?
>> ... iTextSharp is the only freeware , and it works wonderfully with other things , but only in this case it doesn't ...
In what way doesn't it work?
•Does it return an error message (e.g. indicating that the PDF file is corrupt)?
yes, it returns some garbage code , which is not possible to read.
•Or is it that it just doesn't return the data in a form which you want it?
yes, it returns some garbage code , which is not possible to read.
•Or what?
•... and if you open the (converted) PDF file manually with (say) Adobe Reader, does it process the file OK?
yes, I can read it properly in that case.
>> ...Write your own code to convert the PCL to a PDF ...
Unless you find some-one who's already done this, and is willing to provide you with the code (free or not), then I reckon you'll still be working on this (without complete satisfaction with the results) in 10 years time!
it's scary.
Why can you not provide some simple sample files (one PCL, the other PDF) which demonstrate the type of comparison you want, so that we have a (better) understanding of what you are trying to achieve?
Surely you can generate sample test files which don't contain sensitive data?
ASKER
Why can you not provide some simple sample files (one PCL, the other PDF) which demonstrate the type of comparison you want, so that we have a (better) understanding of what you are trying to achieve?
Surely you can generate sample test files which don't contain sensitive data?
let me talk to my business team , if they can provide that to me.
Surely you can generate sample test files which don't contain sensitive data?
let me talk to my business team , if they can provide that to me.
To reinforce the point about the amount of effort involved in creating software to parse complex documents, it is worth noting that it is estimated that the iText library (used for creating and manipulating PDF files) took an estimated 250 man-years of effort to date.
>> ... Does it return an error message (e.g. indicating that the PDF file is corrupt)?
>> ... yes, it returns some garbage code , which is not possible to read.
Can you provide examples of this 'garbage code'?
>> ... Does it return an error message (e.g. indicating that the PDF file is corrupt)?
>> ... yes, it returns some garbage code , which is not possible to read.
Can you provide examples of this 'garbage code'?
ASKER
Why can you not provide some simple sample files (one PCL, the other PDF) which demonstrate the type of comparison you want, so that we have a (better) understanding of what you are trying to achieve?
Surely you can generate sample test files which don't contain sensitive data?
Surely you can generate sample test files which don't contain sensitive data?
I am sending this second time . Please check the attachement , change the extension to PCL from PRN
sample1.PDF
sample1.prn
The latest sample1.prn file which you have provided is exactly the same as the sample--2-.prn file which you attached in an earlier response.
As I stated in my earlier response (see https://www.experts-exchange.com/questions/28379182/PCL-and-PDF.html?anchorAnswerId=39909019#a39909019 ):
I note also that the PCL does not define a page size, or left margin, or unit of measure, etc., so cannot be considered as a full PCL print job; all of these attributes will use whatever is set as the default on the target printer.
Also, the new sample1.pdf file is not a 'native' PDF file, and is not the same as the original sample1.pdf file posted in a previous response; it was created by the PCL2PDF application, although we don't know what the source PCL file was.
So we've still got nothing with which to make any meaningful comparison.
And you still haven't explained just what you mean by:
... yes, it returns some garbage code , which is not possible to read.
Most modern programming languages can read anything; what may be more difficult is in interpreting what you have read.
As I stated in my earlier response (see https://www.experts-exchange.com/questions/28379182/PCL-and-PDF.html?anchorAnswerId=39909019#a39909019 ):
It defines a PCL macro, executes it, then issues a FormFeed
A more verbose analysis (attached to that earlier response) shows that within the macro, a large number (253) of other macros (not defined in this PCL!) are executed; if the macros are not present, the printer will ignore the execute calls, but if they were present, the output could be totally different!
I note also that the PCL does not define a page size, or left margin, or unit of measure, etc., so cannot be considered as a full PCL print job; all of these attributes will use whatever is set as the default on the target printer.
Also, the new sample1.pdf file is not a 'native' PDF file, and is not the same as the original sample1.pdf file posted in a previous response; it was created by the PCL2PDF application, although we don't know what the source PCL file was.
So we've still got nothing with which to make any meaningful comparison.
And you still haven't explained just what you mean by:
... yes, it returns some garbage code , which is not possible to read.
Most modern programming languages can read anything; what may be more difficult is in interpreting what you have read.
To try to illustrate the point about the missing macros in the PCL file, I've created dummy definitions for each of them.
For each of these dummy macros, the definition:
For example:
I've then added these definitions to the start of the provided sample1.prn file, and prefixed them with a few standard PCL escape sequences:
and saved it as sample1_x01.prn (attached).
If you send the contents of this file to a (colour) PCL printer, you'll see the macro identifiers printed (in red) in the majority of the boxes on the form,
sample1-x01.prn
sample1-x01.prn-analysis.txt
sample1-x01.prn-analysis-verbose.txt
For each of these dummy macros, the definition:
Selects colour index 6
Selects the secondary font
Prints the macro identifier number
Selects the primary font
Selects colour index 7
For example:
Offset Type Sequence Description
------------- --------------------- ---------------- ----------------------------------------------------
0000000039 PCL Parameterised <Esc>&f504Y Macro Control ID (identifer = 504)
0000000046 PCL Parameterised <Esc>&f0X Macro Control: Start Macro Definition
0000000051 PCL Parameterised <Esc>*v6S Foreground Colour (index = 6)
0000000056 PCL Control Code 0x0e <SO>: Shift Out - select Secondary font
0000000056 Data 504
0000000060 PCL Control Code 0x0f <SI>: Shift In - select Primary font
0000000061 PCL Parameterised <Esc>*v7S Foreground Colour (index = 7)
0000000066 PCL Parameterised <Esc>&f1X Macro Control: Stop Macro DefinitionI've then added these definitions to the start of the provided sample1.prn file, and prefixed them with a few standard PCL escape sequences:
0000000000 PCL Simple <Esc>E Printer Reset
0000000002 PCL Parameterised <Esc>*r-3U Simple Colour: 3-Plane CMY Palette
0000000008 PCL Parameterised <Esc>*v7S Foreground Colour (index = 7)
0000000013 PCL Parameterised <Esc>&l2A Page Size: Letter
0000000018 PCL Parameterised <Esc>)0N Secondary Font: Symbol Set (0N = ISO 8859-1 Latin 1)
0000000022 PCL Parameterised <Esc>)s0p Secondary Font: Spacing: Fixed
0000000027 20h Secondary Font: Pitch (20 characters per inch)
0000000030 0s Secondary Font: Style (Upright, solid)
0000000032 0b Secondary Font: Stroke Weight: Medium
0000000034 4099T Secondary Font: Typeface (4099 = Courier)and saved it as sample1_x01.prn (attached).
If you send the contents of this file to a (colour) PCL printer, you'll see the macro identifiers printed (in red) in the majority of the boxes on the form,
sample1-x01.prn
sample1-x01.prn-analysis.txt
sample1-x01.prn-analysis-verbose.txt
ASKER
hi DansDadUK
can we focus on the below conditions .
1. There is a PCL file which i sent .
2. There is a PDF file of the same PCL file , that i sent .
3. now i have to compare these 2 files such that
a. it tells me , if both are matching exactly bit by bit .
b. if it is not matching , then it should tell me , where and what is not matching (text , image, font, spacing, style).
4. to accomplish above , we can adopt any way.
a. convert PCL to PDF and then compare both .
b. directly read PCL and then compare with PDF .
c. or something else.
can we have a discussion on the points given above. with the files i have sent.
can we focus on the below conditions .
1. There is a PCL file which i sent .
2. There is a PDF file of the same PCL file , that i sent .
3. now i have to compare these 2 files such that
a. it tells me , if both are matching exactly bit by bit .
b. if it is not matching , then it should tell me , where and what is not matching (text , image, font, spacing, style).
4. to accomplish above , we can adopt any way.
a. convert PCL to PDF and then compare both .
b. directly read PCL and then compare with PDF .
c. or something else.
can we have a discussion on the points given above. with the files i have sent.
>> 1. There is a PCL file which i sent .
>> 2. There is a PDF file of the same PCL file , that i sent .
Are you saying that the supplied sample1.pdf file (which appears to have been generated using PCL2PDF) was generated from the sample1.prn file?
If so, what is the point of attempting to make any comparison between these two files? All it may show you is how good (or not) PCL2PDF is at the conversion process.
>> 3. now i have to compare these 2 files such that
a. it tells me , if both are matching exactly bit by bit .
b. if it is not matching , then it should tell me , where and what is not matching (text , image, font, spacing, style).
As we've said before, you cannot directly compare PCL with PDF; you have to either:
>> 4. to accomplish above , we can adopt any way.
a. convert PCL to PDF and then compare both .
To repeat - you can't directly compare PCL with PDF, so you need two PDF files to compare.
>> b. directly read PCL and then compare with PDF .
To repeat - you can't directly compare PCL (however you read it) with PDF, without either converting the PCL to PDF (then either saving it as a file, or holding an image somehow in memory), then comparing the converted data with the other PDF file, or converting BOTH files to a different format (e.g. raster).
And you have still not answered my previous question, where you refer to having tried to 'read' a converted (PCL to) PDF file, but that .... it returns some garbage code , which is not possible to read ....
What do you mean by this; please provide a real example!
What does it return;what did you expect it to return?
And finally, a few more comments on your supplied PCL file:
>> 2. There is a PDF file of the same PCL file , that i sent .
Are you saying that the supplied sample1.pdf file (which appears to have been generated using PCL2PDF) was generated from the sample1.prn file?
If so, what is the point of attempting to make any comparison between these two files? All it may show you is how good (or not) PCL2PDF is at the conversion process.
>> 3. now i have to compare these 2 files such that
a. it tells me , if both are matching exactly bit by bit .
b. if it is not matching , then it should tell me , where and what is not matching (text , image, font, spacing, style).
As we've said before, you cannot directly compare PCL with PDF; you have to either:
Convert one of the files (using an application of your choice) into a file of the other format, then compare that with the original file of the other format.
But with your latest two files, you say that one of them (the PCL file) has already been converted to the other format (the PDF file) - so what other PDF file are you going to try to compare with this generated PDF file?
ORBut with your latest two files, you say that one of them (the PCL file) has already been converted to the other format (the PDF file) - so what other PDF file are you going to try to compare with this generated PDF file?
Convert both files into some other format (e.g raster) then compare the two files generated by that conversion process.
Of course, raster format will have no knowledge of text, images, fonts, spacing - only pixels.
Of course, raster format will have no knowledge of text, images, fonts, spacing - only pixels.
>> 4. to accomplish above , we can adopt any way.
a. convert PCL to PDF and then compare both .
To repeat - you can't directly compare PCL with PDF, so you need two PDF files to compare.
>> b. directly read PCL and then compare with PDF .
To repeat - you can't directly compare PCL (however you read it) with PDF, without either converting the PCL to PDF (then either saving it as a file, or holding an image somehow in memory), then comparing the converted data with the other PDF file, or converting BOTH files to a different format (e.g. raster).
And you have still not answered my previous question, where you refer to having tried to 'read' a converted (PCL to) PDF file, but that .... it returns some garbage code , which is not possible to read ....
What do you mean by this; please provide a real example!
What does it return;what did you expect it to return?
And finally, a few more comments on your supplied PCL file:
A PCL file using macros is highly unlikely to have been generated by a standard printer driver - it is much more likely to have been generated by some bespoke software application.
The sample PCL file, which (attempts to) execute a large number of macros which have not been defined in that file, appears to be using macros to define variable text - this is a most unusual use of macros.
ASKER
1. i have sent those 2 files as a sample , you imagine that PCL and PDF , both are coming from 2 different sources .
2. Now business wants to confirm , whether it has any difference, which i have mentioned earlier.
3. Now can you please share any way (preferably in C#) , to give me if there is any difference in both of them.
a. if you convert it first to PDF, and then do it , then how would you do it
because , i want to know if there is any font mismatch or text content mismatch.
let us focus on point 3 now.
2. Now business wants to confirm , whether it has any difference, which i have mentioned earlier.
3. Now can you please share any way (preferably in C#) , to give me if there is any difference in both of them.
a. if you convert it first to PDF, and then do it , then how would you do it
because , i want to know if there is any font mismatch or text content mismatch.
let us focus on point 3 now.
ASKER
And you have still not answered my previous question, where you refer to having tried to 'read' a converted (PCL to) PDF file, but that .... it returns some garbage code , which is not possible to read ....
I have tried various evaluation softwares to convert PCL file to PDF file , and then tried reading converted PDF file in itextsharp. and it gives me .
1. Text which has wrong chareacters (such as v replaced by p, q replaced by h)
2. removes spaces .
I request you to please do it yourself itextsharp is a freeware ,and evaluation softwares are there online
>> ... Text which has wrong chareacters (such as v replaced by p, q replaced by h) ...
This could be because the original PCL used downloaded soft fonts; what is normal practice is for drivers to download only the characters required, but to 'obfuscate' them (to deter font licence contraventions), so that it is not possible to reconstruct the plain text from the obfuscated sequences (other than by recognising the 'signature' of each downloaded character in each of the possible fonts you may be using).
I think that PDF sometimes uses a similar mechanism, using Embedded Subset fonts.
>> ... removes spaces ...
No idea what might cause this, other than the 'obfuscation' mechanism - the original spaces may have been encoded as non-graphic characters (e.g the <NUL> control-code character).
>> ... I request you to please do it yourself itextsharp is a freeware ,and evaluation softwares are there online ...
I don't have time to try to do any of this at present.
This could be because the original PCL used downloaded soft fonts; what is normal practice is for drivers to download only the characters required, but to 'obfuscate' them (to deter font licence contraventions), so that it is not possible to reconstruct the plain text from the obfuscated sequences (other than by recognising the 'signature' of each downloaded character in each of the possible fonts you may be using).
I think that PDF sometimes uses a similar mechanism, using Embedded Subset fonts.
>> ... removes spaces ...
No idea what might cause this, other than the 'obfuscation' mechanism - the original spaces may have been encoded as non-graphic characters (e.g the <NUL> control-code character).
>> ... I request you to please do it yourself itextsharp is a freeware ,and evaluation softwares are there online ...
I don't have time to try to do any of this at present.
> Now can you please share any way (preferably in C#) , to give me if there is any difference in both of them.
The answer is NO, unless you want to undertake a substantial custom development project that will require a great deal of effort and cost a lot money, and even then I would not guarantee perfect results. Just one person's opinion, of course. Regards, Joe
The answer is NO, unless you want to undertake a substantial custom development project that will require a great deal of effort and cost a lot money, and even then I would not guarantee perfect results. Just one person's opinion, of course. Regards, Joe
I'll do the project, for £10,000,000.
But I may be dead before it's complete!
But I may be dead before it's complete!
A bit of background on font obfuscation:
Similar considerations apply to obfuscation with other types of font (e.g. PCL5, webFont).
In general, if obfuscated fonts are in use within a 'document', you cannot retrieve the original plain text within that document without a significant investment in (attempting to) break the obfuscation mechanism.
PageTech (see http://www.pagetech.com/pcl-to-text.php ) offer various PCL-to-Text and PCL-to-PDF functions (for a price).
They claim to be able to extract text from obfuscated PCL print streams (see http://pclhelp.com/pcl-to-pdf/text-extraction-pcltool-sdk-simple-pcl-parsers-pcl-emulators/ ) - I suspect that they can only do this for certain fonts and/or characters.
PCL XL (PCL6): http://h30499.www3.hp.com/t5/Black-and-White/PCLXL-Soft-Font-Offset-by-3/td-p/4608007
Similar considerations apply to obfuscation with other types of font (e.g. PCL5, webFont).
In general, if obfuscated fonts are in use within a 'document', you cannot retrieve the original plain text within that document without a significant investment in (attempting to) break the obfuscation mechanism.
PageTech (see http://www.pagetech.com/pcl-to-text.php ) offer various PCL-to-Text and PCL-to-PDF functions (for a price).
They claim to be able to extract text from obfuscated PCL print streams (see http://pclhelp.com/pcl-to-pdf/text-extraction-pcltool-sdk-simple-pcl-parsers-pcl-emulators/ ) - I suspect that they can only do this for certain fonts and/or characters.
> the iText library (used for creating and manipulating PDF files) took an estimated 250 man-years of effort to date.
And is nearly one million lines of code (almost 1.2 million including comments):
https://www.ohloh.net/p/itext/analyses/latest/languages_summary
Regards, Joe
And is nearly one million lines of code (almost 1.2 million including comments):
https://www.ohloh.net/p/itext/analyses/latest/languages_summary
Regards, Joe
Judging by the recent lack of response from the question author, it seems that he might finally have accepted the points we've been making.
ASKER
though , i feel the solution, i have in mind , is possible , yet , is not easy one , and it's a professional development cycle , which will take long time , to complete that .
if you like to close this , thread , you have my agreement. I will open a new thread if i get a new angle to this.
if you like to close this , thread , you have my agreement. I will open a new thread if i get a new angle to this.
I don't want to speak for DansDadUK, but my opinion is that we've taken this one as far as we can. If he agrees, I think your idea is a good one — close this question, then open a new one when the time is right. Of course, as the asker, you must be the one to close it. Regards, Joe
ASKER
how to close this , without accepting the solution , please help .....
>> ... how to close this ...
You could ask for the question to be deleted (in which case all trace of it will disappear).
Or you could accept one of your own comments as the 'solution'.
With either of these courses of action, you would be required to give your reasons for not accepting any other 'solution'.
Although there has been no 'solution' acceptable to you (the consensus being that there is no feasible, cost-effective, solution), it would seem churlish not to accept some of the good advice that has been posted, and therefore to accept multiple comments as the 'solution'.
You could ask for the question to be deleted (in which case all trace of it will disappear).
Or you could accept one of your own comments as the 'solution'.
With either of these courses of action, you would be required to give your reasons for not accepting any other 'solution'.
Although there has been no 'solution' acceptable to you (the consensus being that there is no feasible, cost-effective, solution), it would seem churlish not to accept some of the good advice that has been posted, and therefore to accept multiple comments as the 'solution'.
I'm in complete agreement with DansDadUK's post (http:#a39985645), especially after looking up "churlish" in the dictionary. :) Cheers, Joe
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
>> ... there is a solution to this problem ...
No: there is no feasible cost-effective solution to the problem you have outlined.
>> ... and i will post it on this thread when i find it ...
I trust that you'll also post back when (after wasting an enormous amount of time and effort) you admit defeat in your quest.
No: there is no feasible cost-effective solution to the problem you have outlined.
>> ... and i will post it on this thread when i find it ...
I trust that you'll also post back when (after wasting an enormous amount of time and effort) you admit defeat in your quest.
ASKER
I trust that you'll also post back when (after wasting an enormous amount of time and effort) you admit defeat in your quest.
:)
ASKER
No: there is no feasible cost-effective solution to the problem you have outlined.
cost effective , i don't know , but feasible solution ,yes
>> ... but feasible solution ,yes ...
What is feasible about committing yourself to perhaps several hundred man-years of effort to produce something that will not work in anything like 100% of cases?
What is feasible about committing yourself to perhaps several hundred man-years of effort to produce something that will not work in anything like 100% of cases?
BeyondBGCM,
I do not believe that you will ever have much success in comparing a PCL file to a PDF file. You have never been willing to share any of the "real" PDF files you receive, so maybe it's possible if you are receiving very simple PDFs. But the PDF specification is extremely complex, and if you are receiving arbitrarily general PDFs, you will not be able to compare them successfully to PCLs. I feel strongly that your time/effort/energy/money would be much better spent in looking for a different approach to solving the underlying problem, which you've also never been willing to share. There must be a way to change the problem definition so that you can achieve the outcome you need without requiring that the solution be based on a successful comparison of a PCL to a PDF.
In any case, considering the amount of effort that DansDadUK, pony10us, and I put into this thread trying to help you, it's really hard to believe that you're not willing to split the points among us, even if you do accept your own answer as the solution. I don't want to speak for DansDadUK or pony10us, but for me, it's not actually the points that matter — it's the principle...and the message you'll send to the EE community by not awarding any points to folks who have tried very hard to help you. You're the customer and you may do as you please, but I suggest that you give it some thought. Regards, Joe
I do not believe that you will ever have much success in comparing a PCL file to a PDF file. You have never been willing to share any of the "real" PDF files you receive, so maybe it's possible if you are receiving very simple PDFs. But the PDF specification is extremely complex, and if you are receiving arbitrarily general PDFs, you will not be able to compare them successfully to PCLs. I feel strongly that your time/effort/energy/money would be much better spent in looking for a different approach to solving the underlying problem, which you've also never been willing to share. There must be a way to change the problem definition so that you can achieve the outcome you need without requiring that the solution be based on a successful comparison of a PCL to a PDF.
In any case, considering the amount of effort that DansDadUK, pony10us, and I put into this thread trying to help you, it's really hard to believe that you're not willing to split the points among us, even if you do accept your own answer as the solution. I don't want to speak for DansDadUK or pony10us, but for me, it's not actually the points that matter — it's the principle...and the message you'll send to the EE community by not awarding any points to folks who have tried very hard to help you. You're the customer and you may do as you please, but I suggest that you give it some thought. Regards, Joe
ASKER
There are few reasons for this
1. I believe there are many people who are doing this kind of work , like GhostPCL , and few more open source . and it is possible .
2.only thing is that , it is not an easy solution , hence we need to think differently or out of our usual way of thinking.
3.I am still working on this problem , talking to HP people to give us the right direction for this.
1. I believe there are many people who are doing this kind of work , like GhostPCL , and few more open source . and it is possible .
2.only thing is that , it is not an easy solution , hence we need to think differently or out of our usual way of thinking.
3.I am still working on this problem , talking to HP people to give us the right direction for this.
OK, I see your decision — it just closed with 100 comments and 0 points. Cheers, Joe
A couple of last notes from me.
There will never be a complete solution to this issue.
PCL = Printer Control Language
PDF = Portable Document Format
Once a file has been sent to a printer file (created a PCL) it obtains the information required for the printer that it was intended for. So for example, your default printer is an HP4000 it will pick up the settings for that printer.
The PDF will not have any of the printer information if it was created on a system that does not have an HP4000. Instead, it may have information for say a Canon iR.
The PDF will also have formating such as fonts that may not be available for the printer on the system that created the PCL file.
Basically speaking, unless the PDF and PCL were both created on the same system there WILL be differences.
I guess the real question still is what is the purpose. If you have a PCL then someone had to have the original PDF and sent it to a printer file. If you are attempting to compare a PDF that was sent to you then who created the PCL? if it was the same place that sent you the PCL then they must have created it using the original PDF and therefore it is the same.
Either way the PCL must have been created from the PDF so the only difference would have to be the printer control language that was added.
There will never be a complete solution to this issue.
PCL = Printer Control Language
PDF = Portable Document Format
Once a file has been sent to a printer file (created a PCL) it obtains the information required for the printer that it was intended for. So for example, your default printer is an HP4000 it will pick up the settings for that printer.
The PDF will not have any of the printer information if it was created on a system that does not have an HP4000. Instead, it may have information for say a Canon iR.
The PDF will also have formating such as fonts that may not be available for the printer on the system that created the PCL file.
Basically speaking, unless the PDF and PCL were both created on the same system there WILL be differences.
I guess the real question still is what is the purpose. If you have a PCL then someone had to have the original PDF and sent it to a printer file. If you are attempting to compare a PDF that was sent to you then who created the PCL? if it was the same place that sent you the PCL then they must have created it using the original PDF and therefore it is the same.
Either way the PCL must have been created from the PDF so the only difference would have to be the printer control language that was added.
>> ... I guess the real question still is what is the purpose ...
Despite over 100 comments in this thread, including many questions, we've never received a straightforward answer to this (although between us we've stated unequivocally that we don't believe there is any solution to the question as posed).
The closest we've got to a requirement is that the author wants to extract details of text (i.e. which characters), and the precise font and spacing used with the text, and also (unspecified) details of images embedded in the print stream, in order to compare these 'attributes' and 'properties' with the (nearest) equivalent extracted from a separate PDF document.
Note that with some PCL print streams, it is impossible to directly retrieve plain text, because it is either:
>> ... If you have a PCL then someone had to have the original PDF and sent it to a printer file ...
Not strictly true:
Despite over 100 comments in this thread, including many questions, we've never received a straightforward answer to this (although between us we've stated unequivocally that we don't believe there is any solution to the question as posed).
The closest we've got to a requirement is that the author wants to extract details of text (i.e. which characters), and the precise font and spacing used with the text, and also (unspecified) details of images embedded in the print stream, in order to compare these 'attributes' and 'properties' with the (nearest) equivalent extracted from a separate PDF document.
Note that with some PCL print streams, it is impossible to directly retrieve plain text, because it is either:
'obfuscated' - 'undoing' the obfuscation generally requires manual intervention to view and interpret at least some of the printed output, then using specialist software to make use of the results of that interpretation in order to properly analyse the file.
or
in encapsulated raster format, which again requires some intervention (perhaps using Optical Character Recognition software to view the printed page (or a PCL-viewer screen image equivalent); and this would be unlikely to accurately identify the font in use.
>> ... If you have a PCL then someone had to have the original PDF and sent it to a printer file ...
Not strictly true:
The original source document could have been produced using a different application (e.g. Word), then 'converted' to a Page Description Language (e.g. PCL5e, PCL5c, PCL XL, PCL3GUI, PCLm, etc.) document using one (of many) possible printer drivers;
Or there may not even be a source document; one of the (incomplete) sample .pcl files attached by the author was almost certainly produced directly by some sort of bespoke application (rather than by using a common application and a standard printer driver): it made extensive use of PCL macros, something which no standard printer driver has used, in my (nearly 25 years) experience of PCL usage.
@DansDadUK:
After reading your reply I have to say that you are correct. Several things that I had forgot. You hinted at OCR which made me think about an issue I am currently working on here. We receive scanned .PDF documents that we sometimes need to convert to Word documents complete with formating. For that we are looking at a couple of products from Nuance.
You also pointed to a couple of reasons that make sense about not having an "original" PDF as I stated. Those are also very good points.
And finally, you make me feel old. I started in this business in 1978 (35+ years ago) :(
After reading your reply I have to say that you are correct. Several things that I had forgot. You hinted at OCR which made me think about an issue I am currently working on here. We receive scanned .PDF documents that we sometimes need to convert to Word documents complete with formating. For that we are looking at a couple of products from Nuance.
You also pointed to a couple of reasons that make sense about not having an "original" PDF as I stated. Those are also very good points.
And finally, you make me feel old. I started in this business in 1978 (35+ years ago) :(
@pony10us
... I started (as a trainee programmer) in 1970 (and was made redundant and decided to retire in 2009); I'll be 65 this year.
So my (approaching) 25 years of PCL experience only started after about 20 years of mainframe (G2, G3, VME, SCL, S3) and Unix (SVR4) support work.
... I started (as a trainee programmer) in 1970 (and was made redundant and decided to retire in 2009); I'll be 65 this year.
So my (approaching) 25 years of PCL experience only started after about 20 years of mainframe (G2, G3, VME, SCL, S3) and Unix (SVR4) support work.
So then I guess I am not quite there. I am only (almost) 59. That's great that you keep involved. I am looking forward to retirement in about 5 years. I started with IBM's System 360/370 series. We sure have seen some changes.
>> ... We sure have seen some changes ...
My phone has far more processing power, and memory, than the first mainframe I worked with (an ICL 1902 with 16 Kwords (24-bit, with 6-bit characters) of memory; programs written using an assembler language called Plan).
Although there have been huge changes, many of these are still based on principles established during the early mainframe days, and just made more practical by the advances in processing power; both Unix and Arpanet (forerunner of internet) date from 1969 or thereabouts.
My phone has far more processing power, and memory, than the first mainframe I worked with (an ICL 1902 with 16 Kwords (24-bit, with 6-bit characters) of memory; programs written using an assembler language called Plan).
Although there have been huge changes, many of these are still based on principles established during the early mainframe days, and just made more practical by the advances in processing power; both Unix and Arpanet (forerunner of internet) date from 1969 or thereabouts.
>> ... I am still working on this problem ...
It is now more than 6 months since you made this statement (having apparently been sure of finding a solution).
Would you care to share with us your progress?
It is now more than 6 months since you made this statement (having apparently been sure of finding a solution).
Would you care to share with us your progress?
>> ... :) all i can say is , there is a solution to this problem , and i will post it on this thread when i find it , so that you can help others in this direction....... nothing more to say ...
>> ... I am still working on this problem ...
It is now 12 months since you made these statements (having apparently been sure of finding a solution).
Would you care to let us (and others) know whether or not you found any solution?
Or have you given up trying to do so?
>> ... I am still working on this problem ...
It is now 12 months since you made these statements (having apparently been sure of finding a solution).
Would you care to let us (and others) know whether or not you found any solution?
Or have you given up trying to do so?
A PCL (Printer Control Lanuguage) file is a document that tells a printer what to do such as compressed print, line spacing etc. Generaly created by the print driver.
A PDF (Portable Document Foramt) is an Adobe document. For lack of a better description it is like a Word or Excel document.
Am I missing something here?
You could look at this to see if it will work:
http://www.columbia.edu/~em36/pcltopdf.html