Indexes - is EXEC sp_updatestats sufficient?
Hi
I have a large couple of tables which are constantly growing
I need to increase performance as the speeds accessing data are slow
I try and run EXEC sp_updatestats whenever i can
Does this create indexes, and will it help with performance
If not, please can someone help me with the code to run to create indexes?
version: SQL server 2012 business intelligence
The specs are currently quite low, and we plan to upgrade in future, but its a dedicated DB server VM, with 1GB ram (I KNOW!) intel xenon quade core 2.5GHZ CPU
Running on win 2008 R2
I need to squeeze as much performance as possible out of it
I have a large couple of tables which are constantly growing
I need to increase performance as the speeds accessing data are slow
I try and run EXEC sp_updatestats whenever i can
Does this create indexes, and will it help with performance
If not, please can someone help me with the code to run to create indexes?
version: SQL server 2012 business intelligence
The specs are currently quite low, and we plan to upgrade in future, but its a dedicated DB server VM, with 1GB ram (I KNOW!) intel xenon quade core 2.5GHZ CPU
Running on win 2008 R2
I need to squeeze as much performance as possible out of it
ASKER
Thanks
>Do you currently have any indexes on your tables?
No, just the primary key Index that were automatically created
You said
> If not, you will need to look at your query plans to determine where indexes may be beneficial.
Lots of my queries are done based on Dates, i.e. we want to get the latest update (date/time)
And also - show me date specific data
Here are the results of your script
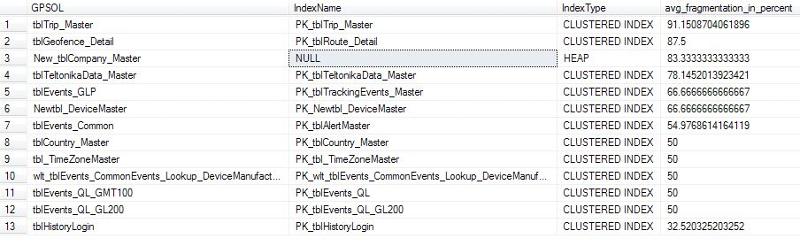
I would appreciate your feedback and what you would do next?
>Do you currently have any indexes on your tables?
No, just the primary key Index that were automatically created
You said
> If not, you will need to look at your query plans to determine where indexes may be beneficial.
Lots of my queries are done based on Dates, i.e. we want to get the latest update (date/time)
And also - show me date specific data
Here are the results of your script

I would appreciate your feedback and what you would do next?
You need to start by rebuilding those indexes. Anything where the fragmentation is above around 30% you need to rebuild. You can do the rebuild by running the following for each table:
You should also set up a SQL Agent job to periodically check fragmentation levels and run a REBUILD/REORGANIZE as needed.
USE <your_database>;
GO
ALTER INDEX ALL ON <your_table_name>
REBUILD WITH (FILLFACTOR = 80, SORT_IN_TEMPDB = ON,
STATISTICS_NORECOMPUTE = ON);
GOYou should also set up a SQL Agent job to periodically check fragmentation levels and run a REBUILD/REORGANIZE as needed.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Thanks guys
Scott, sorry for the delay...new arrival in family
Attached are the 2 results you have asked for
I'm not exactly sure what i'm looking at sorry, but grateful for the advice
1st-results.xlsx
2nd-result.xlsx
Scott, sorry for the delay...new arrival in family
Attached are the 2 results you have asked for
I'm not exactly sure what i'm looking at sorry, but grateful for the advice
1st-results.xlsx
2nd-result.xlsx
Let's focus on the largest tables first, since they have the biggest impact:
tblEvents_Common =~ 1,962,316 rows
tblCommonTrackingData =~ 1,205,914 rows
tblMSMQ_TrackingMaster =~ 926,256 rows
wlt_tblEvents_CommonEvents
The second query lists index usage. Unfortunately SQL has only been up continuously for 4 days, but, even so, some needed index changes are clear.
The clustered index is by far the most important index for performance. Some need changed. You may get some push back since too many people have been fed this myth about "always" using an identity for the clustering key.
But for best performance, you need to change the clustered indexes as follows:
tblCommonTrackingData == vpkDeviceID
tblTrip_Master == vpkDeviceID
wlt_tblEvents_CommonEvents
If you want, you can add that table's own identity column, which is the current clustering key, as the second/last column of the new clustering index so you can explicitly define the clus index as "UNIQUE", but it's not really necessary, SQL will make each key unique itself when it needs to.
We'll need to look at queries that use these tables:
tblEvents_Common
tblMSMQ_TrackingMaster
to determine if they need a different clus index.
The basic steps to change the clus index are:
1) script out drops and creates for all existing index(es)
2) modify the create scripts to make the existing pk clus index a pk nonclus index (don't run them yet, just make the script changes)
3) drop all nonclus index(es)
4) drop the current clus index
5) create the new clus index
6) recreate the pk as nonclus
7) recreate all other non clus index(es)
Some one will probably say "We don't want to change the clus index, what else can we do to improve performance?". You would have to create lots of nonclus, covering indexes, which would eventually make individual queries run faster, but overall the system will have a much higher load than it does now.
tblEvents_Common =~ 1,962,316 rows
tblCommonTrackingData =~ 1,205,914 rows
tblMSMQ_TrackingMaster =~ 926,256 rows
wlt_tblEvents_CommonEvents
The second query lists index usage. Unfortunately SQL has only been up continuously for 4 days, but, even so, some needed index changes are clear.
The clustered index is by far the most important index for performance. Some need changed. You may get some push back since too many people have been fed this myth about "always" using an identity for the clustering key.
But for best performance, you need to change the clustered indexes as follows:
tblCommonTrackingData == vpkDeviceID
tblTrip_Master == vpkDeviceID
wlt_tblEvents_CommonEvents
If you want, you can add that table's own identity column, which is the current clustering key, as the second/last column of the new clustering index so you can explicitly define the clus index as "UNIQUE", but it's not really necessary, SQL will make each key unique itself when it needs to.
We'll need to look at queries that use these tables:
tblEvents_Common
tblMSMQ_TrackingMaster
to determine if they need a different clus index.
The basic steps to change the clus index are:
1) script out drops and creates for all existing index(es)
2) modify the create scripts to make the existing pk clus index a pk nonclus index (don't run them yet, just make the script changes)
3) drop all nonclus index(es)
4) drop the current clus index
5) create the new clus index
6) recreate the pk as nonclus
7) recreate all other non clus index(es)
Some one will probably say "We don't want to change the clus index, what else can we do to improve performance?". You would have to create lots of nonclus, covering indexes, which would eventually make individual queries run faster, but overall the system will have a much higher load than it does now.
ASKER
Thanks Scott
I have been reading lots, and watching lots of videos, and I actually now see where your advice is coming from
I've just done the one table for now, and removed the Primary key and created 2 indexes
Can you comment if this is correct (and if there is indeed no primary key needed now?)
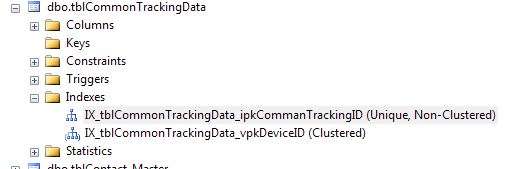
I did some performance tests before and after by running an SP
before the changes i got 17 secs for first run, then between 8-11 secs for subsequent runs
After the updates (and restarting sql service) I got 3 seconds for first run and 1 sec for all other runs
Thank you so much for your help, I feel really empowered now!
I have been reading lots, and watching lots of videos, and I actually now see where your advice is coming from
I've just done the one table for now, and removed the Primary key and created 2 indexes
Can you comment if this is correct (and if there is indeed no primary key needed now?)
I did some performance tests before and after by running an SP
before the changes i got 17 secs for first run, then between 8-11 secs for subsequent runs
After the updates (and restarting sql service) I got 3 seconds for first run and 1 sec for all other runs
Thank you so much for your help, I feel really empowered now!
ASKER
WOW
I just tested my web app
Before the upgrades it was taking 4 mins and 48 seconds to log in
It now takes 10 seconds to login!!!!
I'm hoping that primary key question i asked isn't needed as i'm loving the new speeds
I just tested my web app
Before the upgrades it was taking 4 mins and 48 seconds to log in
It now takes 10 seconds to login!!!!
I'm hoping that primary key question i asked isn't needed as i'm loving the new speeds
ASKER
...also
You mentioned
Is there any easy way to see what queries are using these?
You mentioned
We'll need to look at queries that use these tables:
tblEvents_Common
tblMSMQ_TrackingMaster
to determine if they need a different clus index.
Is there any easy way to see what queries are using these?
Great! Glad it's working out so well. [The biggest thing is that you were willing to try a different clus index key. Too many people won't differ from the "expert recommendation" to "always" use identity as the clus key.]
To find table uses for other two tables, you can scan for those table names in rows of a system view that hold all db source code. Naturally this only applies to code stored in the db, such as stored procs, functions, triggers, etc.:
USE [db_name]
SELECT *
FROM sys.sql_modules
WHERE
definition LIKE '%tblEvents[_]Common%' OR
definition LIKE '%tblMSMQ_TrackingMaster%'
There's nothing per se wrong with having a PK on the table. You can have one if you want it. Just make sure the PK is not clustered. Create the proper clustered index first, then add the PK. [You should always create a clus index first anyway.]
>> Before the upgrades it was taking 4 mins and 48 seconds to log in
It now takes 10 seconds to login!!!! <<
That's a FANTASTIC improvement ... but, frankly, 10 secs (just) to login is still too long, unless an awful lot is going on in the login process.
To find table uses for other two tables, you can scan for those table names in rows of a system view that hold all db source code. Naturally this only applies to code stored in the db, such as stored procs, functions, triggers, etc.:
USE [db_name]
SELECT *
FROM sys.sql_modules
WHERE
definition LIKE '%tblEvents[_]Common%' OR
definition LIKE '%tblMSMQ_TrackingMaster%'
There's nothing per se wrong with having a PK on the table. You can have one if you want it. Just make sure the PK is not clustered. Create the proper clustered index first, then add the PK. [You should always create a clus index first anyway.]
>> Before the upgrades it was taking 4 mins and 48 seconds to log in
It now takes 10 seconds to login!!!! <<
That's a FANTASTIC improvement ... but, frankly, 10 secs (just) to login is still too long, unless an awful lot is going on in the login process.
ASKER
Thanks scott
you've earnt the 500 points so i'll start a new question for the 10 login time
But before I do, what data would you need to see
i.e. should i run a SQL profiler and then paste in the results to the new question???
There is a quite a bit more that just a username and pass look up, but i would like to get it under that time
In chrome half the time seems to be sending the request (the animation on the tab goes one way) and the other half is receiving data (the animation changes direction)
Not sure if this is relevant?
you've earnt the 500 points so i'll start a new question for the 10 login time
But before I do, what data would you need to see
i.e. should i run a SQL profiler and then paste in the results to the new question???
There is a quite a bit more that just a username and pass look up, but i would like to get it under that time
In chrome half the time seems to be sending the request (the animation on the tab goes one way) and the other half is receiving data (the animation changes direction)
Not sure if this is relevant?
I'd address all the other large tables first. Until you get the correct clustered indexes, you're pushing a boulder up a hill anyway. Once all large tables have the best clus index, then you can work further on the logon process, if needed.
Do you currently have any indexes on your tables? They may simply need rebuilding. If not, you will need to look at your query plans to determine where indexes may be beneficial. You will of course need to take into account the extra disk capacity needed to store any indexes, and also potential extra tempdb space needed to rebuild them.
For starters you can tun the following script against each user database to check the fragmentation levels of any existing indexes:
Open in new window