lconnell
asked on
RegEx N'th Occurrence
I have a file that has values separated by spaces. I only want to grab the third space on each line. How would I do that?
ASKER
Sublime Text Editor, also would be nice to know for VIM.
That did not work when using the RegEx search in Sublime.
That did not work when using the RegEx search in Sublime.
I don't know if you saw the edit in my comment, but can you clarify what you are after? It seems weird that you would want the third space. I suspect what you meant was what follows the third space.
ASKER
So I want to edit a file using multi-selection. I have 100 lines of the following text.
data1 data2 data3 data4 data5
...
...
...
I want to use Sublime or any editor to find the 3rd space so I can edit every line at once at that space. So this way I can modify data4 on every line at one time to say "test_data4". Data4 can be any value that's why I want to match at the third space.
data1 data2 data3 data4 data5
...
...
...
I want to use Sublime or any editor to find the 3rd space so I can edit every line at once at that space. So this way I can modify data4 on every line at one time to say "test_data4". Data4 can be any value that's why I want to match at the third space.
OK, I see where I went wrong. This should be correct now:
This pattern assumes that a line never starts with a space.
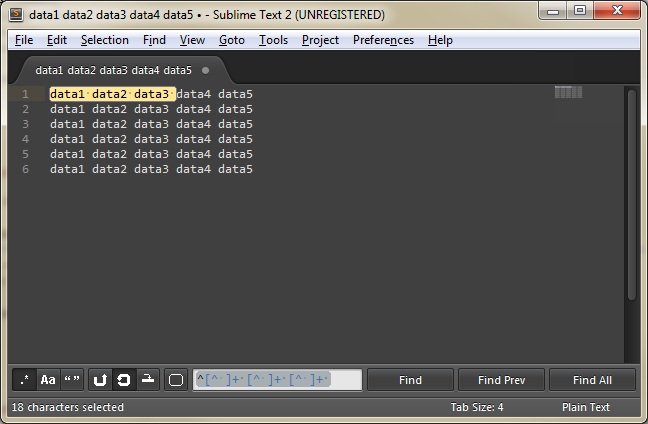
^[^ ]+ [^ ]+ [^ ]+ This pattern assumes that a line never starts with a space.
Here's an alternative pattern
You can then use the regex Replace method against the \1 capture group
\w+ \w+ \w+ (\w+)You can then use the regex Replace method against the \1 capture group
@aikimark
There's no perceived benefit to using the "word character" class over "not a space". In the worst case the pattern won't match if there are any characters other than alphabetic, numeric, or underscores.
There's no perceived benefit to using the "word character" class over "not a space". In the worst case the pattern won't match if there are any characters other than alphabetic, numeric, or underscores.
@kaufmed
I realize that. Normally, I would use the not-a-space pattern. But you'd already used it and I find that \w+ is simpler to type than [^ ]+
Three characters versus five characters.
What I hope I've added is the grouping of the fourth 'word' that will allow the Replace method to be used.
I realize that. Normally, I would use the not-a-space pattern. But you'd already used it and I find that \w+ is simpler to type than [^ ]+
Three characters versus five characters.
What I hope I've added is the grouping of the fourth 'word' that will allow the Replace method to be used.
It looks like my pattern needed tweaking. It should be: (\w+ \w+ \w+ )(\w+)( .*?\r\n)
Example:
Example:
Dim strData As String
Dim oRE As Object
Dim oMatches As Object, oM As Object
Set oRE = CreateObject("vbscript.regexp")
oRE.Global = True
oRE.Pattern = "(\w+ \w+ \w+ )(\w+)( .*?\r\n)"
strData = "data1 data2 data3 data4 data5" & vbCrLf
strData = strData & "data21 data22 data23 data24 data25" & vbCrLf
strData = strData & "data31 data32 data33 data34 data35" & vbCrLf
If oRE.test(strData) Then
Debug.Print oRE.Replace(strData, "$1test_$2$3")
End Ifdata1 data2 data3 test_data4 data5
data21 data22 data23 test_data24 data25
data31 data32 data33 test_data34 data35
Yes. It is possible to use the not-a-space pattern: ([^ ]+ [^ ]+ [^ ]+ )([^ ]+)( .*?\r\n)
vim pattern:
:%s/^\(\([^ ]* \)\{3\}\)\([^ ]*\)/\1test_\3/ASKER
Thanks for the assistance everyone. So there is still a problem here. I only want to select the actual white space in the third column, not the text up to the 3rd white space.
@lconnell
Please test the code I posted
Please test the code I posted
ASKER
aikimark, it does not work. It actually doesn't match anything.
It actually doesn't match anything.Does your actual data reflect the sample data you posted?
Have you changed my code to read your data or are you expecting my sample code to change your file data? The code shows how to use regular expression to do a replace. I used string literals that was meant to simulate the data you used in your example.
The problem you face is that ST uses the Boost regex engine, which does not support arbitrary-length lookbehinds, which is what you would need in order to effectively skip over the first two spaces without actually including them in the match. The only thing you can do at this point is to do a find/replace as aikimark described above, except that you would capture the whole string, not just the last non-space:
e.g.
Find
Replace
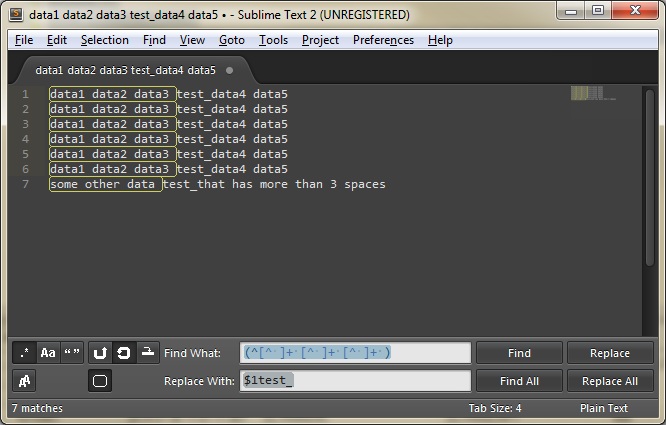
e.g.
Find
(^[^ ]+ [^ ]+ [^ ]+ )Replace
$1test_ASKER
Perfect, that works fine using the replace with what is already highlighted. Can you explain the actual regex?
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Great explanation and examples
You might try:
Open in new window
Also, I took your question quite literally (as a regex would!), so I'm sure the above isn't exactly what you are looking for. Can you clarify what you are after?