Table Design
This question involves the proposed table design of a database. It will be a single user Access database. Please comment on the table design.
An ERD and report is attached.
I am designing a database that will be used to track the emails that are contained in PDFs. Numerous emails are printed to a single PDF file. Each PDF contains numerous emails. The PDFs are not going to be stored in a database. Only the file path and file name will be tracked. This will be a single user database.
Sent e-mails. The following will be tracked:
1) The date and time the e-mails were sent.
2) The sender’s first and last name.
3) The text of the message body will be copied into a field.
E-mail Images. The following will be tracked:
1) An image of every e-mail. A multipage PDF will contain an image of every e-mail.
2) The e-mail image file path.
Here is a sample report:
Sender: Mary Smith
Date: 1-1-14
Time: 4:00 p.m.
File c:\email\file1.pdf
Email Contents: .. text from e-mail..
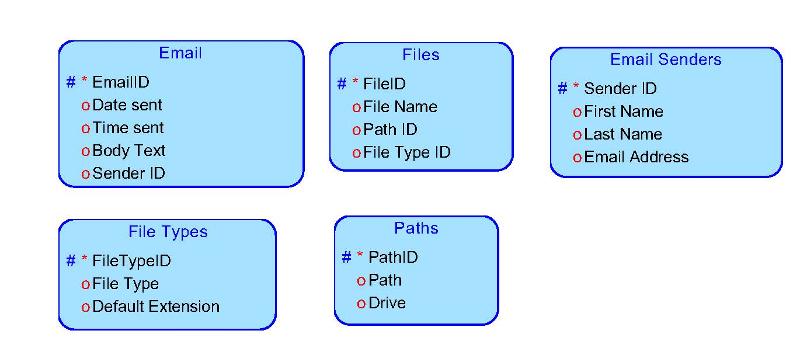
Proposed Tables
Email
EmailID
DateSent
TimeSent
SenderID
EmailSenders
SenderID
FirstName
LastName
EmailAddress
Files
FileID
File
FileTypes
FileTypeID
DefaultExt
Paths
PathID
Path
ENTITIES
Entity: Email
Description: The particular email message that is being tracked.
Rules:
The text of the message body will be copied into a field.
Attributes:
Email ID --An arbitrary unique sequential number assigned to every email. arbitrary unique sequential number assigned to every email.
Date sent --The date on which the email was sent.
Time sent --The time that the email was sent.
Body Text --The text contained in the email message.
SenderID --Identifier that specifies the individual who sent the file..
Entity: Email Senders
Description: The individual who sent the email.
Attributes:
Sender ID --An arbitrary unique sequential number assigned to the individual who sent the file.
First Name --The first name of the individual who sent the file.
Last Name --The first name of the individual who sent the file.
Email Address -- The sender’s email address.
Entity: Files
Description: A standard-format PDF file used to hold emails.
Rules:
Only PDFs will be used. No Excel, Word, etc. files will be used.
Numerous emails are printed to a single PDF file.
All emails in a single PDF.
PDFs are currently not stored in a database; they are stored as standard PDF files.
Files may have zero to many associated comments.
Attributes:
File Id --arbitrary unique sequential number assigned to every file name. File names alone may not be unique, since the same file name could be stored in different paths.
File Name --The name of a standard-format PDF file used to hold emails.
Path Id --identifier that specifies the drive and path to the file.
File Type Id --Physical file type; typically this will correlate to the file extension, but that’s not actually required. For example, a ‘[.]txt’ file could actually [.]csv-format data and vice-versa.
Entity: File Types
Description: Physical file type; typically this will correlate to the file extension, but that’s not actually required. For example, a ‘[.]txt’ file could actually [.]csvformat
data and vice-versa.
Rules:
The File Type will probably be limited to PDF and .jpg.
99% of the time only PDF will be used.
There is almost zero chance that .DOC and a .DOCX will be used.
File Type ID --Arbitrary unique sequential number assigned to each unique File Type
Default Extension --default extension for this type of file: ‘PDF’ for pdf files.
File Type --Standardized description of the the file type: ‘PDF’.
Entity: Paths
Description: The path of a file. Example: c:\email\. This does NOT include the file name, which is part of the file data.
Attributes:
Path Id --arbitrary unique sequential number assigned to each unique path.
Path --the remainder of the physical path to the file
Drive --The “drive” name; may be a single letter, a share, a volume mount point, etc.
Here is the ERD
 report.pdf
report.pdf
An ERD and report is attached.
I am designing a database that will be used to track the emails that are contained in PDFs. Numerous emails are printed to a single PDF file. Each PDF contains numerous emails. The PDFs are not going to be stored in a database. Only the file path and file name will be tracked. This will be a single user database.
Sent e-mails. The following will be tracked:
1) The date and time the e-mails were sent.
2) The sender’s first and last name.
3) The text of the message body will be copied into a field.
E-mail Images. The following will be tracked:
1) An image of every e-mail. A multipage PDF will contain an image of every e-mail.
2) The e-mail image file path.
Here is a sample report:
Sender: Mary Smith
Date: 1-1-14
Time: 4:00 p.m.
File c:\email\file1.pdf
Email Contents: .. text from e-mail..
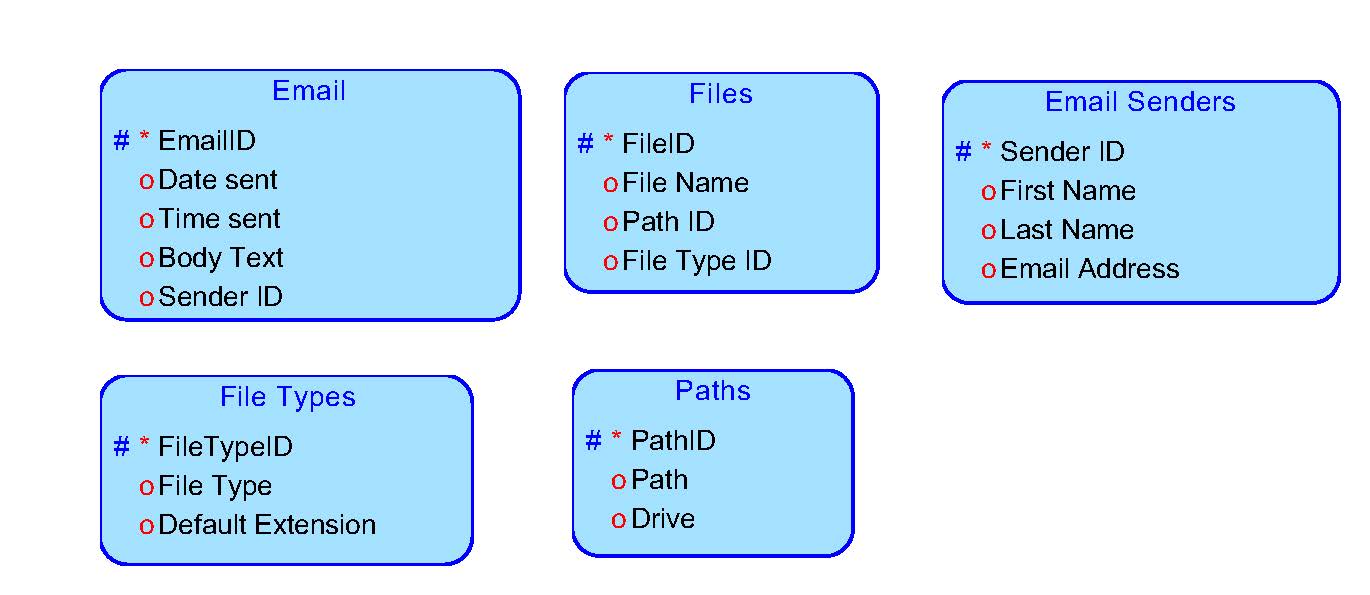
Proposed Tables
EmailID
DateSent
TimeSent
SenderID
EmailSenders
SenderID
FirstName
LastName
EmailAddress
Files
FileID
File
FileTypes
FileTypeID
DefaultExt
Paths
PathID
Path
ENTITIES
Entity: Email
Description: The particular email message that is being tracked.
Rules:
The text of the message body will be copied into a field.
Attributes:
Email ID --An arbitrary unique sequential number assigned to every email. arbitrary unique sequential number assigned to every email.
Date sent --The date on which the email was sent.
Time sent --The time that the email was sent.
Body Text --The text contained in the email message.
SenderID --Identifier that specifies the individual who sent the file..
Entity: Email Senders
Description: The individual who sent the email.
Attributes:
Sender ID --An arbitrary unique sequential number assigned to the individual who sent the file.
First Name --The first name of the individual who sent the file.
Last Name --The first name of the individual who sent the file.
Email Address -- The sender’s email address.
Entity: Files
Description: A standard-format PDF file used to hold emails.
Rules:
Only PDFs will be used. No Excel, Word, etc. files will be used.
Numerous emails are printed to a single PDF file.
All emails in a single PDF.
PDFs are currently not stored in a database; they are stored as standard PDF files.
Files may have zero to many associated comments.
Attributes:
File Id --arbitrary unique sequential number assigned to every file name. File names alone may not be unique, since the same file name could be stored in different paths.
File Name --The name of a standard-format PDF file used to hold emails.
Path Id --identifier that specifies the drive and path to the file.
File Type Id --Physical file type; typically this will correlate to the file extension, but that’s not actually required. For example, a ‘[.]txt’ file could actually [.]csv-format data and vice-versa.
Entity: File Types
Description: Physical file type; typically this will correlate to the file extension, but that’s not actually required. For example, a ‘[.]txt’ file could actually [.]csvformat
data and vice-versa.
Rules:
The File Type will probably be limited to PDF and .jpg.
99% of the time only PDF will be used.
There is almost zero chance that .DOC and a .DOCX will be used.
File Type ID --Arbitrary unique sequential number assigned to each unique File Type
Default Extension --default extension for this type of file: ‘PDF’ for pdf files.
File Type --Standardized description of the the file type: ‘PDF’.
Entity: Paths
Description: The path of a file. Example: c:\email\. This does NOT include the file name, which is part of the file data.
Attributes:
Path Id --arbitrary unique sequential number assigned to each unique path.
Path --the remainder of the physical path to the file
Drive --The “drive” name; may be a single letter, a share, a volume mount point, etc.
Here is the ERD
 report.pdf
report.pdf
Kyle Abrahams, PMP
You're keeping track of the senders, what about recipients?
ASKER
A recipients table will be added later. These proposed tables only cover the essential information that must be tracked. If you look at the other open question (Modeling), you'll notice that the next step is to track subjects and topics.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Thank you, Kyle.