mjacobs2929
asked on
VFP - Parameterised Views - "sql: where clause is invalid" - Why?
trying to pass arbitrary filter code to a parameterised view. It's rejecting even simple obvious valid examples.
I have a global variable (startit.filt_expr) which holds the filter code and the parameter in the view is simply ?startit.filt_expr
I can manually perform "Select * from ADDRESS WHERE CUSTOMER INTO DBF WHATEVER" no problem
but if startit.filt_expr is set to "ADDRESS.CUSTOMER", or just "CUSTOMER" or "ADDRESS.CUSTOMER=.T." or just "CUSTOMER=.T." and I try
"USE ADDRESS_USER_QUERY" (the name of the parameterised view) it fails every time with the error message
"SQL: WHERE clause is invalid" despite the fact that I can see startit.filt_expr is still happily sitting there waiting to be used.
Looks like I'm missing a step of misunderstanding how the parameterised views work.
Kindly enlighten me!
I have a global variable (startit.filt_expr) which holds the filter code and the parameter in the view is simply ?startit.filt_expr
I can manually perform "Select * from ADDRESS WHERE CUSTOMER INTO DBF WHATEVER" no problem
but if startit.filt_expr is set to "ADDRESS.CUSTOMER", or just "CUSTOMER" or "ADDRESS.CUSTOMER=.T." or just "CUSTOMER=.T." and I try
"USE ADDRESS_USER_QUERY" (the name of the parameterised view) it fails every time with the error message
"SQL: WHERE clause is invalid" despite the fact that I can see startit.filt_expr is still happily sitting there waiting to be used.
Looks like I'm missing a step of misunderstanding how the parameterised views work.
Kindly enlighten me!
ASKER
aha. Thanks for the link. That's the kind of view I'm talking about. I have no problem with the "standard" parameterized views.
from the link, it looks like point 4
"
4. Since using macro-substitution in Views was not "intended" functionality (and is not documented), you still cannot use the much improved View/Query Designer when working with macro-substituted parameters (huge bummer), these views must be created via code (or a cool utility such as View Editor or EView).
"
might be the key to my problem. I'm using the view designer to try to create the view so instead of a field name I'm using an expression (startit.filt_expr) and then choosing the logical condition popdown to select "Is True" and compiling the result into my dbc. The code looked kosher
"CREATE SQL VIEW "ADDRESS_USER_QUERY" ;
AS SELECT * FROM vizbiz!address Address_a WHERE ( ?startit.filt_expr )"
but looking more closely (having read that point 4) I've just spotted that "Address_a" which doesn't look like it could work
surely it should be simply:
"CREATE SQL VIEW "ADDRESS_USER_QUERY" ;
AS SELECT * FROM vizbiz!address WHERE ( ?startit.filt_expr )"
or am I still missing something?
from the link, it looks like point 4
"
4. Since using macro-substitution in Views was not "intended" functionality (and is not documented), you still cannot use the much improved View/Query Designer when working with macro-substituted parameters (huge bummer), these views must be created via code (or a cool utility such as View Editor or EView).
"
might be the key to my problem. I'm using the view designer to try to create the view so instead of a field name I'm using an expression (startit.filt_expr) and then choosing the logical condition popdown to select "Is True" and compiling the result into my dbc. The code looked kosher
"CREATE SQL VIEW "ADDRESS_USER_QUERY" ;
AS SELECT * FROM vizbiz!address Address_a WHERE ( ?startit.filt_expr )"
but looking more closely (having read that point 4) I've just spotted that "Address_a" which doesn't look like it could work
surely it should be simply:
"CREATE SQL VIEW "ADDRESS_USER_QUERY" ;
AS SELECT * FROM vizbiz!address WHERE ( ?startit.filt_expr )"
or am I still missing something?
Read all points.
You're still missing that a) you can't expand object.property and b) you need & as in &?cFilter
Then in regard to 2. you have to define the variable before creating the view:
lcFilter = ".T." && htat can be some useful expression later on
CREATE SQL VIEW ADDRESS_USER_QUERY AS SELECT * FROM vizbiz!address WHERE ?&lcFilter
If you do this in VFP8 or earlier in regard to point 2 you then would need to make sure lcFilter is NOT existing before creating the view.
But the most important point is you have to combine ? and & to get macro substitution via view parameters.
Bye, Olaf.
PS: And forget the view designer anyway. The inabilities don't just start with parameters, you can't even do UNION with the designer. You're much better off putting together your query code in a PRG and then put CREATE SQL VIEW Viewname AS in front of it.
You're still missing that a) you can't expand object.property and b) you need & as in &?cFilter
Then in regard to 2. you have to define the variable before creating the view:
lcFilter = ".T." && htat can be some useful expression later on
CREATE SQL VIEW ADDRESS_USER_QUERY AS SELECT * FROM vizbiz!address WHERE ?&lcFilter
If you do this in VFP8 or earlier in regard to point 2 you then would need to make sure lcFilter is NOT existing before creating the view.
But the most important point is you have to combine ? and & to get macro substitution via view parameters.
Bye, Olaf.
PS: And forget the view designer anyway. The inabilities don't just start with parameters, you can't even do UNION with the designer. You're much better off putting together your query code in a PRG and then put CREATE SQL VIEW Viewname AS in front of it.
It should be possible to define the WHERE expression in EVALUATE function: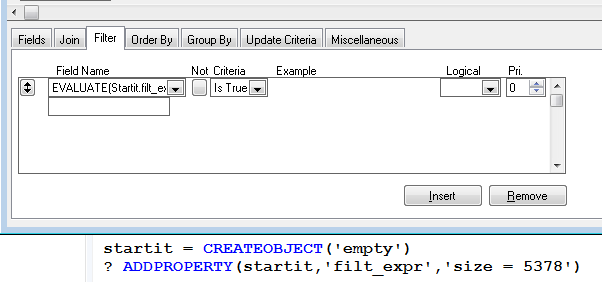 Of course, you have to design the WHERE clause in the code:
Of course, you have to design the WHERE clause in the code:
Additional problems can raise when you change the filter expression... In such case REQUERY() does not work and you have to close and reopen the view by USE command.
Do you still think SQL views are good option? To create a cursor sounds better to me.
Of course, you have to design the WHERE clause in the code:
SELECT Files.path, Files.size, Files.dat;
FROM ;
files;
WHERE EVALUATE(Startit.filt_expr) Additional problems can raise when you change the filter expression... In such case REQUERY() does not work and you have to close and reopen the view by USE command.
Do you still think SQL views are good option? To create a cursor sounds better to me.
ASKER
Olaf, I know you can't use & with a global variable but that's what I needed.
Fortunately pcelba's reminder to use EVAL gets around the problem.
However, using
CREATE SQL VIEW "ADDRESS_USER_QUERY" AS SELECT * FROM vizbiz!address WHERE EVALUATE(STARTIT.FILT_EXPR
I can now create the view, and, if I browse the dbc, it has all the right properties and looks proper.
But the damn thing doesn't work anyway!
It picks up every record in the table, instead of just "Customers" or whatever else I feed into STARTIT.FILT_EXPR
Incidentally, I take the point about not using the view designer. What I do is let it do the bulk of the work, then cut and paste it into my own code and modify accordlingly. Which is how I got the above to create the view.
on the question of using Cursors, I'll come back to you on that later but the chief problem is that the data in the cursor needs to behave EXACTLY as the underlying data in the relevant forms. Which means, for example, it has to have all the relevant indexes, relate properly to the other tables in the database, and so on. Seems easier to me just to create it as a dbf and then use it, temporarily, like the master table from which it originated, do the dirty, update the master table with any changes, delete the temp and bob's yer father's brother. If cursors can be made to do all that without significant recoding of what I've already got working, I would be happy to learn the new trick.
In a sense, that (trying to learn a new trick) is what the attempted parameterised view is all about. I already have perfectly satisfactory home grown code which can create appropriate updateable queries based on user driven arbitrary filter code, from either free or dbc tables but I'm trying to explore whether using PVs might be more efficient or offer other advantages.
Fortunately pcelba's reminder to use EVAL gets around the problem.
However, using
CREATE SQL VIEW "ADDRESS_USER_QUERY" AS SELECT * FROM vizbiz!address WHERE EVALUATE(STARTIT.FILT_EXPR
I can now create the view, and, if I browse the dbc, it has all the right properties and looks proper.
But the damn thing doesn't work anyway!
It picks up every record in the table, instead of just "Customers" or whatever else I feed into STARTIT.FILT_EXPR
Incidentally, I take the point about not using the view designer. What I do is let it do the bulk of the work, then cut and paste it into my own code and modify accordlingly. Which is how I got the above to create the view.
on the question of using Cursors, I'll come back to you on that later but the chief problem is that the data in the cursor needs to behave EXACTLY as the underlying data in the relevant forms. Which means, for example, it has to have all the relevant indexes, relate properly to the other tables in the database, and so on. Seems easier to me just to create it as a dbf and then use it, temporarily, like the master table from which it originated, do the dirty, update the master table with any changes, delete the temp and bob's yer father's brother. If cursors can be made to do all that without significant recoding of what I've already got working, I would be happy to learn the new trick.
In a sense, that (trying to learn a new trick) is what the attempted parameterised view is all about. I already have perfectly satisfactory home grown code which can create appropriate updateable queries based on user driven arbitrary filter code, from either free or dbc tables but I'm trying to explore whether using PVs might be more efficient or offer other advantages.
ASKER
and, just to eliminate the possibility that EVAL produces different results from ?&filt_expr I set up a public variable "filt_expr" and tried creating the view that way. It worked to the extent of creating the view without complaint but failed the same way as EVAL - the view doesn't appear to take any notice of the filter code...
A dot in a name isn't possible, so a "name" like STARTIT.FILT_EXPR is sepcifying a property of an object.
You haven't understood this.
It doesn't depend on STARTIT.FILT_EXPR being public, it's not a variable, it's a property of a variable. STARTIT is an object with property FILT_EXPR.
And as said you can't use this in the view definition nor execution. You can stay with any code setting this property, but you need to define the view using a simple string variable lcFilter and use ?&lcFilter in the view definition and set lcFilter = STARTIT.FILT_EXPR before using/executing the view.
Bye, Olaf.
PS: A simple example:
_screen.Tag = "messagebox('hello world')"
lcCode = _screen.Tag
&lcCode && works
&_screen.Tag && causes error
You can't use the macro substitution operator & on a property of an object.
that doesn't work with object properties, you can't do &Thisform.Macroexpression,you'll need it in a variable lcMacroExpression = Thisform.Macroexpression, then you can do &lcMacroexpression. The same applies to your startit object with the filt_expr property. That won't work.
You haven't understood this.
It doesn't depend on STARTIT.FILT_EXPR being public, it's not a variable, it's a property of a variable. STARTIT is an object with property FILT_EXPR.
And as said you can't use this in the view definition nor execution. You can stay with any code setting this property, but you need to define the view using a simple string variable lcFilter and use ?&lcFilter in the view definition and set lcFilter = STARTIT.FILT_EXPR before using/executing the view.
Bye, Olaf.
PS: A simple example:
_screen.Tag = "messagebox('hello world')"
lcCode = _screen.Tag
&lcCode && works
&_screen.Tag && causes error
You can't use the macro substitution operator & on a property of an object.
In regard of cursors:
You use views, views are (a form of) cursors already, mostly called view cursor, but you can simply say cursor in short.
a query INTO DBF does not copy any index. So if you could live without indexed query results you can also live without indexed cursor.
If not, that's no problem, because cursors ARE dbfs, you can simply Index them.
Bye, Olaf.
You use views, views are (a form of) cursors already, mostly called view cursor, but you can simply say cursor in short.
a query INTO DBF does not copy any index. So if you could live without indexed query results you can also live without indexed cursor.
If not, that's no problem, because cursors ARE dbfs, you can simply Index them.
Bye, Olaf.
The STARTIT.FILT_EXPR works in the view but it has to be in the EVALUATE() AND everytime you change the expression you have to close and reopen the view by USE command. The macro could also work with exactly same problems...
You may think about different approach. How many records do you have in your table?
If there are less than let say 10000 records in the local table then I would recommend simple SET FILTER. Table placed on a network share is not so good for SET FILTER but it depends on the network speed and number of concurrent users.
SET FILTER can use macro substitution in the definition and it has one big advantage (for you): It works on the original table, so all indexes are available and all changes are immediately saved. (This advantage can easily become disadvantage under certain circumstances.)
So instead of view creation simply issue following command:
lcFilter = "CUSTOMER=.T."
SELECT YourTableAlias
SET FILTER TO &lcFilter
and that's it.
Of course, one disadvantage exists: the filter is ignored by SQL commands and you have to add it all WHERE relevant clauses...
You may think about different approach. How many records do you have in your table?
If there are less than let say 10000 records in the local table then I would recommend simple SET FILTER. Table placed on a network share is not so good for SET FILTER but it depends on the network speed and number of concurrent users.
SET FILTER can use macro substitution in the definition and it has one big advantage (for you): It works on the original table, so all indexes are available and all changes are immediately saved. (This advantage can easily become disadvantage under certain circumstances.)
So instead of view creation simply issue following command:
lcFilter = "CUSTOMER=.T."
SELECT YourTableAlias
SET FILTER TO &lcFilter
and that's it.
Of course, one disadvantage exists: the filter is ignored by SQL commands and you have to add it all WHERE relevant clauses...
ASKER
sorry Olaf, I obviously didn't make myself clear. STARTIT.FILT_EXPR is indeed a property of my global object STARTIT. That's why I refer to it as a global variable but I realise that is sloppy use of language and can easily be confused with "public variable". Clear?
And, on the cursor issue, the point is, I can't live without indexes or properly related tables, so one way or the other I need to index them.
On the substantive issue, I'm not getting any clue as to why the view, having been constructed as above (using either WHERE EVAL(STARTIT.FILT_EXPR OR WHERE ?&Filt_Expr) still fails to do the job. I create sql or foxpro queries like that routinely with no problem, so why would it not work as part of a DBC View? I take the point about having to reuse the view every time the filter code changes but that's not a problem. The problem is that the view doesn't even work the first time it's opened.
Incidentally, in answer to the suggestion about using filters, I generally deprecate them except for trivial inquiries or searching for subsets within queries. The tables I work with tend to have up to a million records and frequently over 100k so queries are imperative, especially in networked applications.
And, as I suggested earlier, I'm not really looking for a solution to a problem. I already have code that works very efficiently at pulling whatever I want out of one or more of the relevant tables. My quest is to learn about a new tool, or rather an old tool in a new context (for me) viz, the use of parameters to pass arbitrary filter code to the view. The hope is that it will streamline my code and perhaps make it more robust. For example I won't have to take responsibility for updating the data in the base table and it will improve network accessibility.
Can I ask either of you if you've actually got this form of parameterised query in one of your own working application or are we just theorising about what OUGHT to happen?
And, on the cursor issue, the point is, I can't live without indexes or properly related tables, so one way or the other I need to index them.
On the substantive issue, I'm not getting any clue as to why the view, having been constructed as above (using either WHERE EVAL(STARTIT.FILT_EXPR OR WHERE ?&Filt_Expr) still fails to do the job. I create sql or foxpro queries like that routinely with no problem, so why would it not work as part of a DBC View? I take the point about having to reuse the view every time the filter code changes but that's not a problem. The problem is that the view doesn't even work the first time it's opened.
Incidentally, in answer to the suggestion about using filters, I generally deprecate them except for trivial inquiries or searching for subsets within queries. The tables I work with tend to have up to a million records and frequently over 100k so queries are imperative, especially in networked applications.
And, as I suggested earlier, I'm not really looking for a solution to a problem. I already have code that works very efficiently at pulling whatever I want out of one or more of the relevant tables. My quest is to learn about a new tool, or rather an old tool in a new context (for me) viz, the use of parameters to pass arbitrary filter code to the view. The hope is that it will streamline my code and perhaps make it more robust. For example I won't have to take responsibility for updating the data in the base table and it will improve network accessibility.
Can I ask either of you if you've actually got this form of parameterised query in one of your own working application or are we just theorising about what OUGHT to happen?
Have you taken everything into account, including the VFP version and whether to put ?& or &? in front of the variable and whether to define the variable before creating the view or not? Simply reread.
I have done such views and it works, of course.
You can name the view parameter different, but you can't use STARTIT.FILT_EXPR in the view definition, you can simply set viewparameter = STARTIT.FILT_EXPR and that solves that problem without changing any code addressing STARTIT.FILT_EXPR so far. So you can stay with your global variable and it's properties, just copy the value to the view parameter when using it. What's so difficult about this?
Now why didn't I came up with such a sample in the first place? a) Don't know what VFP version you have b) You should know the how and why, so I still strongly recommend to read the wiki article.
OK?
What Pavel says is important of course, a view always is a snapshot of data only refreshing via REQUERY, not just by changing the view parameter, but you have well understood that implication already, I think.
So what's stopping you? What did you try and why didn't you post your code so far for our review? It's quite fruitless to come back and say "it doesn't work".
You're more following Pavels idea to use evaluate, because it works in the view designer, too. Fine:
Works, too. But you can't do EVALUATE("companyname like 'A%'"), so you are limited with evaluate.
Bye, Olaf.
PS: Gendbc (Home()+"Tools\Gendbc\gend
If you want to test queries I prefer sql server management studio or Access over VFPs view designer.
I have done such views and it works, of course.
* View definition
*-----------------
* a view on northwind data
Open Database _samples+"northwind\northwind.dbc"
* optional: a seperate view database
* (could also be in the same database as the tables, I just don't want to modify the northwind sample database)
Cd GetEnv("TEMP")
Create Database myviews
* creating the view parameter before the view (important for VFP9)
lcFilter = ".T."
* creating the view using &? (important for VFP9)
Create SQL View v_sample as Select * from northwind!customers where &?lcFilter
* View usage
*-----------
* using the view with arbitrary where clausea
lcFilter = "companyname like 'A%'"
Use v_sample in 0 alias v_customerswithA
lcFilter = "city = 'London'"
Use v_sample in 0 alias v_londoncustomersYou can name the view parameter different, but you can't use STARTIT.FILT_EXPR in the view definition, you can simply set viewparameter = STARTIT.FILT_EXPR and that solves that problem without changing any code addressing STARTIT.FILT_EXPR so far. So you can stay with your global variable and it's properties, just copy the value to the view parameter when using it. What's so difficult about this?
Now why didn't I came up with such a sample in the first place? a) Don't know what VFP version you have b) You should know the how and why, so I still strongly recommend to read the wiki article.
OK?
What Pavel says is important of course, a view always is a snapshot of data only refreshing via REQUERY, not just by changing the view parameter, but you have well understood that implication already, I think.
So what's stopping you? What did you try and why didn't you post your code so far for our review? It's quite fruitless to come back and say "it doesn't work".
You're more following Pavels idea to use evaluate, because it works in the view designer, too. Fine:
Set Database To myviews
Create SQL View v_sample2 as Select * from northwind!customers where Evaluate(?gcFilter)
Public gcFilter
gcFilter = "city = 'London'"
Use v_sample2 in 0 alias v_londoncustomers2Works, too. But you can't do EVALUATE("companyname like 'A%'"), so you are limited with evaluate.
Bye, Olaf.
PS: Gendbc (Home()+"Tools\Gendbc\gend
If you want to test queries I prefer sql server management studio or Access over VFPs view designer.
mjacobs, you are trying to use something which is not well documented or which is even not recommended... You have to realize such code can result into less app stability because it was not tested so heavily as other parts of VFP.
I have to say I am avoiding views in my apps because I prefer cursors. Cursors do not need database and they are also more stable. I am creating all necessary indexes on cursors because it is very fast. (Some of them are created in time when needed.)
It seems Olaf has better experience at the view field and I agree macro substitution is better than EVALUATE() because it can use Rushmore optimization. (OTOH, the LIKE operator has non-SQL equivalent.)
100.000 or even millions of records sounds too many for today's operating systems and networks. Networks are fast and reliable enough but Microsoft is degrading shared file access (DBFs especially) to something "not supported or even worst"... The preferred way is client-server access.
Relevant way of FoxPro application usage is local desktop app or VFP used as an OLE server.
I have to say I am avoiding views in my apps because I prefer cursors. Cursors do not need database and they are also more stable. I am creating all necessary indexes on cursors because it is very fast. (Some of them are created in time when needed.)
It seems Olaf has better experience at the view field and I agree macro substitution is better than EVALUATE() because it can use Rushmore optimization. (OTOH, the LIKE operator has non-SQL equivalent.)
100.000 or even millions of records sounds too many for today's operating systems and networks. Networks are fast and reliable enough but Microsoft is degrading shared file access (DBFs especially) to something "not supported or even worst"... The preferred way is client-server access.
Relevant way of FoxPro application usage is local desktop app or VFP used as an OLE server.
Pavel, you're right, there also is the LIKE() function, but you also put your fingers on the most important advantage of macro substitution vs evaluate: Rushmore won't optimize EVALUATE("field=value"), even if it can optimize field = value.
I also rather like the successor of view, the cursoradapter. It still lacks a visual query designer, but as already said other tools have nice replacements and in the end you should be able to write SQL.
Advantages of views/CAs are repeatable queries with a defined result cursor schema, you don't repeat yourself, in that aspect also views have their advantages over directly using SQL.
The only project I used views with macro substitution was for their advantages as grid recordsource and for a less complex search mechanism, a rather small project. It was easier for the customer (also a VFP developer) to maintain the queries as views than in code, though you have maximum freedom to define any query in a variable and execute it as &lcSQL.
Bye, Olaf.
I also rather like the successor of view, the cursoradapter. It still lacks a visual query designer, but as already said other tools have nice replacements and in the end you should be able to write SQL.
Advantages of views/CAs are repeatable queries with a defined result cursor schema, you don't repeat yourself, in that aspect also views have their advantages over directly using SQL.
The only project I used views with macro substitution was for their advantages as grid recordsource and for a less complex search mechanism, a rather small project. It was easier for the customer (also a VFP developer) to maintain the queries as views than in code, though you have maximum freedom to define any query in a variable and execute it as &lcSQL.
Bye, Olaf.
ASKER
apologies for delay in responding. Should have mentioned that I was away last week on family business.
I'm still struggling to get any kind of view to behave as Olaf says it should but given other comments in the thread, I think I'm losing interest in pursuing that route.
I'm intrigued by two comments pcelba makes.
First about Cursors, which I've rarely used, you tell me that they're "more stable" than views. That interests me as I too have not been impressed with how the views work. They seem to be inherently prone to failed updates in particular. So can you expand on that greater stability?
Also, as I've never trodden that path, a key concern would be the ability to rename the cursor to the arbitrary name I would need within the app (for purposes of relations and indexing). Can we do that with cursors?
More significantly, you say:
"Microsoft is degrading shared file access (DBFs especially) to something "not supported or even worst"... The preferred way is client-server access."
This was news to me. Where can I read up on it?
I might be partly shielded as the larger datasets involved are running on a very solid Novell network and thus not vulnerable to Microsoft tweaking. That said, I have a number of other clients using the software on windows networks (some of which don't even use windows servers)
I'm still struggling to get any kind of view to behave as Olaf says it should but given other comments in the thread, I think I'm losing interest in pursuing that route.
I'm intrigued by two comments pcelba makes.
First about Cursors, which I've rarely used, you tell me that they're "more stable" than views. That interests me as I too have not been impressed with how the views work. They seem to be inherently prone to failed updates in particular. So can you expand on that greater stability?
Also, as I've never trodden that path, a key concern would be the ability to rename the cursor to the arbitrary name I would need within the app (for purposes of relations and indexing). Can we do that with cursors?
More significantly, you say:
"Microsoft is degrading shared file access (DBFs especially) to something "not supported or even worst"... The preferred way is client-server access."
This was news to me. Where can I read up on it?
I might be partly shielded as the larger datasets involved are running on a very solid Novell network and thus not vulnerable to Microsoft tweaking. That said, I have a number of other clients using the software on windows networks (some of which don't even use windows servers)
Cursors are handled in memory or on the local drive. And they are open exclusively so they are fast and reliable BUT you have some extra work to create cursors and update DBF data when needed.
If you would ask if there are some bugs in cursor processing then I have to say "not everything is 100% gold" and VFP is not bug free... Cursors created by SQLEXEC() are not so reliable as cursors created by CREATE CURSOR command... SQLEXEC() creates a cursor which is closer to the view than to standard cursor and it happened to me (under certain circumstances) that SEEK() function failed on such cursor. The reason is unknown and LOCATE solved the problem... which was in indexing probably.
You can assign any alias to the cursor, you can create indexes on cursors (even on read/only ones), you can use relations between cursors etc. etc. You cannot open one cursor in two data sessions (as any other exclusively open file).
Olaf pointed to Cursor Adapters which is let say OO extension to cursors.
Microsoft decided to cease DBF support around year 2000 when they removed VFP from Visual Studio. We don't need any explicit paper saying this but it surely exists. You may test it yourself: Call Microsoft support and ask about certain problem with DBF file created in FoxPro...
Microsoft also removed DBF support from Office 2013.
Microsoft is not testing shared file access sufficiently in new Windows versions thus Windows Vista and 7 were damaging DBF and CDX files accessed from more computers (it also happened to shared Excel sheets and Access databases). Just google for SMB2 and oplocks and you'll see.
Client-server is ideal topology even for FoxPro applications. The main advantage is local data access. Visual FoxPro can work as OLE server (with no CAL fees) and the speed is very good even on weak servers and slow networks. It just needs different coding similar to C-S applications.
You are happy man if your Novell network works without problems on Windows clients! Some Novell drivers for W7 were not so stable and DBF files damage was described in the past.
Visual FoxPro applications will work another 10-15 years and then users may use some OS virtualization like they do now for 16bit applications under 64bit OS.
Xbase++ and Lianja seems to be possible FoxPro followers but who knows...
If you would ask if there are some bugs in cursor processing then I have to say "not everything is 100% gold" and VFP is not bug free... Cursors created by SQLEXEC() are not so reliable as cursors created by CREATE CURSOR command... SQLEXEC() creates a cursor which is closer to the view than to standard cursor and it happened to me (under certain circumstances) that SEEK() function failed on such cursor. The reason is unknown and LOCATE solved the problem... which was in indexing probably.
You can assign any alias to the cursor, you can create indexes on cursors (even on read/only ones), you can use relations between cursors etc. etc. You cannot open one cursor in two data sessions (as any other exclusively open file).
Olaf pointed to Cursor Adapters which is let say OO extension to cursors.
Microsoft decided to cease DBF support around year 2000 when they removed VFP from Visual Studio. We don't need any explicit paper saying this but it surely exists. You may test it yourself: Call Microsoft support and ask about certain problem with DBF file created in FoxPro...
Microsoft also removed DBF support from Office 2013.
Microsoft is not testing shared file access sufficiently in new Windows versions thus Windows Vista and 7 were damaging DBF and CDX files accessed from more computers (it also happened to shared Excel sheets and Access databases). Just google for SMB2 and oplocks and you'll see.
Client-server is ideal topology even for FoxPro applications. The main advantage is local data access. Visual FoxPro can work as OLE server (with no CAL fees) and the speed is very good even on weak servers and slow networks. It just needs different coding similar to C-S applications.
You are happy man if your Novell network works without problems on Windows clients! Some Novell drivers for W7 were not so stable and DBF files damage was described in the past.
Visual FoxPro applications will work another 10-15 years and then users may use some OS virtualization like they do now for 16bit applications under 64bit OS.
Xbase++ and Lianja seems to be possible FoxPro followers but who knows...
If you say "I too have not been impressed with how the views work. They seem to be inherently prone to failed updates in particular." you're misconceiving update conflicts with failing data writing.
If you use DBFs directly and bind to them without using buffering, you're always directly writing your changes to the tables, you're working with a update strategy not scaling well for many users, and an update strategy making the last change win. Concurrent updates - and that doesn't mean the small chance of updates in the same split second, are not revealed by directly binding to DBFs.
Client/server always makes a big cut/separation of the three layers of applications: 1. database, 2. business logic (code, the core application working on loaded data) and 3. frontend (the presentation layer, User interface. Also called tiers.
The main thing to prevent is having the frontend directly talk to the database, but that's one main easy way of working with VFP. It just doesn't scale well for multi user applications.
A webserver like Pavel uses for his VFP applications typically has a frontend in the browser and code and data stay close together on the server side. This way you rather have a series of scripts on a webserver than an EXE, no states are preserved, each request from the browser will trigger a restart and build up of code needed to create the html page for presentation and a tear down of all the objects. To make this have the look and feel of a desktop app you have to learn quite a lot of things about html/css/javascript and ajax.
The other major client/server design is you forget about DBFs and put your data in a database server. You load things into cursors the one or other way and views are one of them. You stay with a VFP EXE and can keep all your code logic, just instead of binding to DBFs you bind to data loaded into cursors and you have the additional task to store the data back into the database server.
As you like relations you'd not like any of these two scenarios, because neither way you can just make the relations of DBFs do the automatic navigation between parent and child or main and detail data. You don't see live data, as you always will make requests to pull a current state and only update central data at times you save. That can also be autosave, but the main thing is you don't do it live. Neither by saving every second nor by reloading the browser page every second. This aspect of non live data is making both approaches scale better for more users and more data.
If you like what you do, then stay with just the two tiers of user interface/forms, code, and data tightly coupled, but the file protocol problems and non scalable applications will limit what you do and you better only do single/few user applications this way.
The ext level then is having both a database server, a web server or application server and a frontend, eg browser. This way of decoupling things helps to build a service oriented architecture for a bigger company where functionalities overlap in applications and you reuse not by building applications with the same code, but by centralising operations and making them available from many frontends or tiers. Same data, same code, many users and devices/platforms. Ideally. It's typically a long way to go there.
One thing is for sure: This all needs other ways of thinking about solutions, other strategies of problem solving.
Bye, Olaf.
If you use DBFs directly and bind to them without using buffering, you're always directly writing your changes to the tables, you're working with a update strategy not scaling well for many users, and an update strategy making the last change win. Concurrent updates - and that doesn't mean the small chance of updates in the same split second, are not revealed by directly binding to DBFs.
Client/server always makes a big cut/separation of the three layers of applications: 1. database, 2. business logic (code, the core application working on loaded data) and 3. frontend (the presentation layer, User interface. Also called tiers.
The main thing to prevent is having the frontend directly talk to the database, but that's one main easy way of working with VFP. It just doesn't scale well for multi user applications.
A webserver like Pavel uses for his VFP applications typically has a frontend in the browser and code and data stay close together on the server side. This way you rather have a series of scripts on a webserver than an EXE, no states are preserved, each request from the browser will trigger a restart and build up of code needed to create the html page for presentation and a tear down of all the objects. To make this have the look and feel of a desktop app you have to learn quite a lot of things about html/css/javascript and ajax.
The other major client/server design is you forget about DBFs and put your data in a database server. You load things into cursors the one or other way and views are one of them. You stay with a VFP EXE and can keep all your code logic, just instead of binding to DBFs you bind to data loaded into cursors and you have the additional task to store the data back into the database server.
As you like relations you'd not like any of these two scenarios, because neither way you can just make the relations of DBFs do the automatic navigation between parent and child or main and detail data. You don't see live data, as you always will make requests to pull a current state and only update central data at times you save. That can also be autosave, but the main thing is you don't do it live. Neither by saving every second nor by reloading the browser page every second. This aspect of non live data is making both approaches scale better for more users and more data.
If you like what you do, then stay with just the two tiers of user interface/forms, code, and data tightly coupled, but the file protocol problems and non scalable applications will limit what you do and you better only do single/few user applications this way.
The ext level then is having both a database server, a web server or application server and a frontend, eg browser. This way of decoupling things helps to build a service oriented architecture for a bigger company where functionalities overlap in applications and you reuse not by building applications with the same code, but by centralising operations and making them available from many frontends or tiers. Same data, same code, many users and devices/platforms. Ideally. It's typically a long way to go there.
One thing is for sure: This all needs other ways of thinking about solutions, other strategies of problem solving.
Bye, Olaf.
ASKER
both very interesting responses.
I'll go away and study the pros and cons of re-engineering to the CS model.
Just a couple of questions and comments and I'll wrap this one up and split the points between you.
Olaf, when you refer to a database server, are we talking about something like the various flavours of SQL, and alternatives like Oracle?
Pcelba, your reference to cursors seems to imply that, when created, they automatically include the indexes defined for the dbf. Or am I overinterpreting what you wrote? If it is true then that would be a significant improvement on my own code where I have to recreate the indexes on every query before moving on to "real" activity.
And, on the question of Novell clients; yes the first W7 client was a mess but they fixed that after a couple of months. The current W8 client appears to be flawless. Been using it on a number of stations for about 18 months with only a single glitch - it doesn't integrate as well as previous versions with the windows login screen but the effect is trivial.
I'll go away and study the pros and cons of re-engineering to the CS model.
Just a couple of questions and comments and I'll wrap this one up and split the points between you.
Olaf, when you refer to a database server, are we talking about something like the various flavours of SQL, and alternatives like Oracle?
Pcelba, your reference to cursors seems to imply that, when created, they automatically include the indexes defined for the dbf. Or am I overinterpreting what you wrote? If it is true then that would be a significant improvement on my own code where I have to recreate the indexes on every query before moving on to "real" activity.
And, on the question of Novell clients; yes the first W7 client was a mess but they fixed that after a couple of months. The current W8 client appears to be flawless. Been using it on a number of stations for about 18 months with only a single glitch - it doesn't integrate as well as previous versions with the windows login screen but the effect is trivial.
Good to know Novell is back!
Cursors are created as "naked"... So you have to create all necessary indexes and relations again. But it is very fast. (Of course, temp folder must reside on local drive.)
FoxPro working on a web server is represented by ActiveVFP: http://activevfp.codeplex.com/
We are using VFP client-server app where VFP is used on both sides:
1) Server running as a multi-threaded VFP OLE application
2) Fat clients under standard VFP run-time
But it needed some extra effort to make it working all together...
Clients are calling functions on a server and data are returned as strings. So all query results are converted to strings, zipped, and returned to clients and clients must unzip, create indexes and use... Even this level of complexity does not degrade the performance comparing to SQL Server. Clients can access the server via almost any network starting on LAN and ending on modem connections. Thanks to the fact data access is local (on the server) 150 concurrent users does not mean any problem. 2 GB limitation is solved by DBF files fragmentation.
I am sure this application will work another 10 years.
And if I imagine the cost of software licenses represents just ONE copy of Visual FoxPro then I understand why Microsoft does not support FoxPro any more.
Cursors are created as "naked"... So you have to create all necessary indexes and relations again. But it is very fast. (Of course, temp folder must reside on local drive.)
FoxPro working on a web server is represented by ActiveVFP: http://activevfp.codeplex.com/
We are using VFP client-server app where VFP is used on both sides:
1) Server running as a multi-threaded VFP OLE application
2) Fat clients under standard VFP run-time
But it needed some extra effort to make it working all together...
Clients are calling functions on a server and data are returned as strings. So all query results are converted to strings, zipped, and returned to clients and clients must unzip, create indexes and use... Even this level of complexity does not degrade the performance comparing to SQL Server. Clients can access the server via almost any network starting on LAN and ending on modem connections. Thanks to the fact data access is local (on the server) 150 concurrent users does not mean any problem. 2 GB limitation is solved by DBF files fragmentation.
I am sure this application will work another 10 years.
And if I imagine the cost of software licenses represents just ONE copy of Visual FoxPro then I understand why Microsoft does not support FoxPro any more.
ASKER
downloaded ActiveVFP for a look. But are you really saying that a user working, for example, in my Sales Invoice module, would have to pull all the data they might need to work with across the network before they could interrogate it?
I have, for instance, a neat report which builds its own query (which, like the cursors, is stored locally) and presents a year on year comparison of performance by an arbitrary number of sales reps by code and account. I've just tested that on the Novell net and it took 15 seconds to create the query of 40,000 records (from a table with 850,000)
What sort of time would it take to perform that task using the model you describe?
I have, for instance, a neat report which builds its own query (which, like the cursors, is stored locally) and presents a year on year comparison of performance by an arbitrary number of sales reps by code and account. I've just tested that on the Novell net and it took 15 seconds to create the query of 40,000 records (from a table with 850,000)
What sort of time would it take to perform that task using the model you describe?
To speed up something which takes 15 seconds does not make sense in this case.
OTOH, you may test how long takes the query when executed at the server directly and then send just the result to a client. It should show certain difference.
OTOH, you may test how long takes the query when executed at the server directly and then send just the result to a client. It should show certain difference.
ASKER
No, I was asking how long such a query might have taken on your VFP based fat client/server model. I'm guessing it would be lot longer than 15 seconds.
Can't, of course, run the same query directly on the Novell server, but on my own workstation the query took 8 seconds, so the network latency approximately halves the speed, But 15 seconds for a complex query like that is acceptable.
On a Windoze network, the latency reduces the speed further, to about one third.
Not sure that clarifies anything but the critical question remains, if we were to throw a similar task at your fat client/server version, all other things being equai, how long would you expect it to take, zipping 40,000 records from a table of 850,000, pulling them across the network, unzipping, reassembling and reindexing them for the fat client. If the honest answer is something less than 30 seconds, I could still be interested. Anything above that and I can't justify the drop in performance.
Can't, of course, run the same query directly on the Novell server, but on my own workstation the query took 8 seconds, so the network latency approximately halves the speed, But 15 seconds for a complex query like that is acceptable.
On a Windoze network, the latency reduces the speed further, to about one third.
Not sure that clarifies anything but the critical question remains, if we were to throw a similar task at your fat client/server version, all other things being equai, how long would you expect it to take, zipping 40,000 records from a table of 850,000, pulling them across the network, unzipping, reassembling and reindexing them for the fat client. If the honest answer is something less than 30 seconds, I could still be interested. Anything above that and I can't justify the drop in performance.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
thanks chaps. Plenty to think about and new tricks to learn.
Just in answer to Pcelba's question re why the 40,000 records are needed. It's a fairly typical requirement for users of my software that they spend a considerable amount of time performing fine grained analysis. In the Sales Rep year on year example they need to know the volume and value of sales, by product, made by each rep to each of their accounts for the most recent 12 months and to see the results for the previous 12 months alongside. That requires every single line item, for both periods, to be retrieved for the analysis to be possible. Furthermore, all the data has to available prior to the start of the analysis, so we can't cheat by starting it and allowing the remaining data to arrive later. Nor, indeed, given that the network query only takes 15 seconds, do we need to.
My conclusion, following this enlightening thread, is that I'll stick with the pure VFP for this particular application. It's already close on 2 million lines of code and the prospect of re-engineering that for Client Server looks like it would be far more effort than it's worth, particularly as my target market are SMEs with, typically, fewer than 50 workstations, for whom the VFP on a LAN seems to be more than adequate. But I do work on other projects and some of those do indeed need scaling to, potentially, millions of users, so I'm going to start the process of migrating that kind of development to the Client Server model.
I now propose to close this question and split the points.
Thanks a lot for sharing your insights.
Just in answer to Pcelba's question re why the 40,000 records are needed. It's a fairly typical requirement for users of my software that they spend a considerable amount of time performing fine grained analysis. In the Sales Rep year on year example they need to know the volume and value of sales, by product, made by each rep to each of their accounts for the most recent 12 months and to see the results for the previous 12 months alongside. That requires every single line item, for both periods, to be retrieved for the analysis to be possible. Furthermore, all the data has to available prior to the start of the analysis, so we can't cheat by starting it and allowing the remaining data to arrive later. Nor, indeed, given that the network query only takes 15 seconds, do we need to.
My conclusion, following this enlightening thread, is that I'll stick with the pure VFP for this particular application. It's already close on 2 million lines of code and the prospect of re-engineering that for Client Server looks like it would be far more effort than it's worth, particularly as my target market are SMEs with, typically, fewer than 50 workstations, for whom the VFP on a LAN seems to be more than adequate. But I do work on other projects and some of those do indeed need scaling to, potentially, millions of users, so I'm going to start the process of migrating that kind of development to the Client Server model.
I now propose to close this question and split the points.
Thanks a lot for sharing your insights.
Yes, the application port is always very expensive... but that's the life.
I also like Olaf's comments.
Thanks for the points.
I also like Olaf's comments.
Thanks for the points.
First, thanks for closing this, it was a nice discussion.
>fine grained analysis
As a user you'd typically not do analysis of so many records in a form, but by exporting them to eg Excel and work on them there. Well Excel is always the bad reputation example, there are other things like software specialised on statistical analysis.
I also have to do some of these yearly exports and wonder, if it wouldn't be faster to already aggregate most of the data in the different ways the need to view on them. But it's true you only get the ideas of what to look at, if you don't just get monthly or even just quartley key values and still don't know what to change to make the next quarter or year a bigger business success.
I assume it's that way, because scrolling through 4000 grid lines will not give you an overview, you'll use that data to look at it from different angles and management doing that isn't bad at it, they just should sometimes work more directly with database experts. Another hint, what technology offers for this kind of number crunching is a different form of MSSQL databases: Online Analytical Processing (OLAP) Cubes.
Bye, Olaf.
>fine grained analysis
As a user you'd typically not do analysis of so many records in a form, but by exporting them to eg Excel and work on them there. Well Excel is always the bad reputation example, there are other things like software specialised on statistical analysis.
I also have to do some of these yearly exports and wonder, if it wouldn't be faster to already aggregate most of the data in the different ways the need to view on them. But it's true you only get the ideas of what to look at, if you don't just get monthly or even just quartley key values and still don't know what to change to make the next quarter or year a bigger business success.
I assume it's that way, because scrolling through 4000 grid lines will not give you an overview, you'll use that data to look at it from different angles and management doing that isn't bad at it, they just should sometimes work more directly with database experts. Another hint, what technology offers for this kind of number crunching is a different form of MSSQL databases: Online Analytical Processing (OLAP) Cubes.
Bye, Olaf.
First an example of a working view parameter:
SELECT * from ADDRESS WHERE CITY = ?lcCity
This view query could be used after setting lcCity = "NY" and will result in ...WHERE CITY = "NY".
So you see the view parameter is only taken as a value, in the same way as if the view query would be part of your code and could see all variables: SELECT * from ADDRESS WHERE CITY = lcCity
If you want to use an expression you need to combine this with &. Like macro substitution that doesn't work with object properties, you can't do &Thisform.Macroexpression,
So use a simple variable, and then read about macro substitution in views.
You also shouldn't put clauses like INTO DBF into a view. If you want to persist the data the view queries into a DBF simply use COPY TO on the view cursor. Well, or repeat the USE of the view, the data should already be persisted in the table(s) the view queries. And you can use the view cursor as controlsource, browse it etc like any DBF. No need to really create one on HDD.
Defining a view query with INTO DBF you are creating a copy of a copy of a book before reading it, if BOOK = underlying table, 1st copy = view query, 2nd copy = INTO DBF.
Bye. Olaf.