Event ID 509 NTDS ISAM
Hi,
I have a server 2012r2 box which runs as a VM on Dell PowerEdge hardware. Most days I get at least one entry saying the following in the logs:
Critical Errors in Event Logs in Last 24 Hours
NTDS ISAM Event ID: 509
NTDS (668) NTDSA: A request to read from the file "C:\Windows\NTDS\ntds.dit"
Last occurrence: 30 November 2014 10:55:11 Total occurrences: 1
Obviously this is quite alarming as you think that you may have disk faults developing. The first time this came up I ran a disk check on the physical host server that this VM runs in and it found no faults on the server's hard disks?
I have looked into other reports of this on the web and can't see that any of the issues of this type relate to my hardware configuration (most seem to have occurred on Server 2008 and relate to hardware issues).
Is this one of those errors that just gets reported randomly and can be ignored or is there something else more serious going on?
I did wonder if it was only occurring when the server backup was going on, but that is not the case as some times the errors occur before or after the backup window?
Any help appreciated.
Siv
I have a server 2012r2 box which runs as a VM on Dell PowerEdge hardware. Most days I get at least one entry saying the following in the logs:
Critical Errors in Event Logs in Last 24 Hours
NTDS ISAM Event ID: 509
NTDS (668) NTDSA: A request to read from the file "C:\Windows\NTDS\ntds.dit"
Last occurrence: 30 November 2014 10:55:11 Total occurrences: 1
Obviously this is quite alarming as you think that you may have disk faults developing. The first time this came up I ran a disk check on the physical host server that this VM runs in and it found no faults on the server's hard disks?
I have looked into other reports of this on the web and can't see that any of the issues of this type relate to my hardware configuration (most seem to have occurred on Server 2008 and relate to hardware issues).
Is this one of those errors that just gets reported randomly and can be ignored or is there something else more serious going on?
I did wonder if it was only occurring when the server backup was going on, but that is not the case as some times the errors occur before or after the backup window?
Any help appreciated.
Siv
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Dan,
This is the disk information from the Host Server:
Storage
Hard drives
Dell VIRTUAL DISK SCSI Disk Device
Interface SAS(Serial Attached SCSI)
Capacity 3725 GB
Real size 3,999,724,126,720 bytes
RAID Type None
S.M.A.R.T
S.M.A.R.T not supported
Partition 0
Partition ID Disk #0, Partition #0
File System NTFS
Volume Serial Number 0EB61270
Size 349 MB
Used Space 289 MB (82%)
Free Space 60 MB (18%)
Partition 1
Partition ID Disk #0, Partition #1
Disk Letter C:
File System NTFS
Volume Serial Number 8ABEA64B
Size 2047 GB
Used Space 1167 GB (56%)
Free Space 880 GB (44%)
The SAS system has two 2TB drives attached in a striped configuration I think. Haven't touched this box for a while and support it remotely. Whatever it is the Host O/S sees it as single 4GB Drive of which about 3.7GB is usable.
As I mentioned we did a Scandisk on this drive on the host box and it came back with no errors, so I am not 100% convinced there is a hardware problem!?
Siv
This is the disk information from the Host Server:
Storage
Hard drives
Dell VIRTUAL DISK SCSI Disk Device
Interface SAS(Serial Attached SCSI)
Capacity 3725 GB
Real size 3,999,724,126,720 bytes
RAID Type None
S.M.A.R.T
S.M.A.R.T not supported
Partition 0
Partition ID Disk #0, Partition #0
File System NTFS
Volume Serial Number 0EB61270
Size 349 MB
Used Space 289 MB (82%)
Free Space 60 MB (18%)
Partition 1
Partition ID Disk #0, Partition #1
Disk Letter C:
File System NTFS
Volume Serial Number 8ABEA64B
Size 2047 GB
Used Space 1167 GB (56%)
Free Space 880 GB (44%)
The SAS system has two 2TB drives attached in a striped configuration I think. Haven't touched this box for a while and support it remotely. Whatever it is the Host O/S sees it as single 4GB Drive of which about 3.7GB is usable.
As I mentioned we did a Scandisk on this drive on the host box and it came back with no errors, so I am not 100% convinced there is a hardware problem!?
Siv
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Dan,
Thanks for the information ... noted. You seem to be of the opinion it is a disk fault starting, even though when we did a full chkdisk it didn't find any bad sectors on the host machine?
Are you sure it couldn't be something else that's clobbering the CPU, Disk or RAM when the NTDS writes are occurring?
Siv
Thanks for the information ... noted. You seem to be of the opinion it is a disk fault starting, even though when we did a full chkdisk it didn't find any bad sectors on the host machine?
Are you sure it couldn't be something else that's clobbering the CPU, Disk or RAM when the NTDS writes are occurring?
Siv
ASKER
I have checked the VM AV and it's definitely ignoring all the NTDS folders.
This error occurred when a physical drive failed in a SCSI RAID array.
In a remote location you can use the LSI MegaCli utility to check the status of the server RAID
In a remote location you can use the LSI MegaCli utility to check the status of the server RAID
In my experience, events like these tend to lead to a failed disk. My concern for your setup is a stripe set. When the disk fails, you server (and all the guests) are lost. No recovery kinda thing.
It could be a SMART failure being reported, which is why I recommend looking at the controller to see what it sees. You probably have an embedded PERC of sorts in the server, I would take a look during a reboot or use Server Admin to see if there are any hardware events in the OMSA log.
If you search for "event id 509 NTDS ISAM" you'll find plenty of people going thru various tests and coming to a disk issue of some sorts.
Dan
It could be a SMART failure being reported, which is why I recommend looking at the controller to see what it sees. You probably have an embedded PERC of sorts in the server, I would take a look during a reboot or use Server Admin to see if there are any hardware events in the OMSA log.
If you search for "event id 509 NTDS ISAM" you'll find plenty of people going thru various tests and coming to a disk issue of some sorts.
Dan
ASKER
Guys,
OK thanks, gulp! I was convinced it wasn't hardware, but will have to look at the drives via the Dell Perc boot time screens.
I hope you're wrong as it's a long drive!
Siv
OK thanks, gulp! I was convinced it wasn't hardware, but will have to look at the drives via the Dell Perc boot time screens.
I hope you're wrong as it's a long drive!
Siv
Siv, can you please confirm if these errors are occurring within the VM or on the host itself?
I agree with Dan's points, you will want to make a backup of this machine as it does sound like there could be an issue with the drives somewhere.
I agree with Dan's points, you will want to make a backup of this machine as it does sound like there could be an issue with the drives somewhere.
ASKER
Errors are only appearing on the VM. Just so you have the full picture I have the following setup:
ACMHost is the bare metal server and is running Server 2012r2 Standard with the Hyper-V role and Remote Access.
ACMServer is the first VM and is Server 2012r2 Standard running the Server Essentials Role and also has DHCP and basically behaves like an old SBS Server. It also has SQL Server 2014 running on it.
ACMMail is a second VM running Server 2012r2 Standard and is running Exchange Server 2013.
The NTDS errors only are coming up on ACMServer which is the first VM which I treat like the PDC of old.
Siv
ACMHost is the bare metal server and is running Server 2012r2 Standard with the Hyper-V role and Remote Access.
ACMServer is the first VM and is Server 2012r2 Standard running the Server Essentials Role and also has DHCP and basically behaves like an old SBS Server. It also has SQL Server 2014 running on it.
ACMMail is a second VM running Server 2012r2 Standard and is running Exchange Server 2013.
The NTDS errors only are coming up on ACMServer which is the first VM which I treat like the PDC of old.
Siv
ASKER
I lied I have just checked the event logs on the bare metal box and I do get the occasional fault reported:
Log Name: System
Source: disk
Date: 16/11/2014 08:01:58
Event ID: 7
Task Category: None
Level: Error
Keywords: Classic
User: N/A
Computer: ACMHostServer
Description:
The device, \Device\Harddisk0\DR0, has a bad block.
Event Xml:
<Event xmlns="http://schemas.microsoft.com/win/2004/08/events/event">
<System>
<Provider Name="disk" />
<EventID Qualifiers="49156">7</Even
<Level>2</Level>
<Task>0</Task>
<Keywords>0x80000000000000
<TimeCreated SystemTime="2014-11-16T08:
<EventRecordID>8089</Event
<Channel>System</Channel>
<Computer>ACMHostServer</C
<Security />
</System>
<EventData>
<Data>\Device\Harddisk0\DR
<Binary>030080000100000000
</EventData>
</Event>
Which I find really frustrating as when I first got the NTDS error I ran check disk on the bare metal box and it gave a clean bill of health!!
Siv
Log Name: System
Source: disk
Date: 16/11/2014 08:01:58
Event ID: 7
Task Category: None
Level: Error
Keywords: Classic
User: N/A
Computer: ACMHostServer
Description:
The device, \Device\Harddisk0\DR0, has a bad block.
Event Xml:
<Event xmlns="http://schemas.microsoft.com/win/2004/08/events/event">
<System>
<Provider Name="disk" />
<EventID Qualifiers="49156">7</Even
<Level>2</Level>
<Task>0</Task>
<Keywords>0x80000000000000
<TimeCreated SystemTime="2014-11-16T08:
<EventRecordID>8089</Event
<Channel>System</Channel>
<Computer>ACMHostServer</C
<Security />
</System>
<EventData>
<Data>\Device\Harddisk0\DR
<Binary>030080000100000000
</EventData>
</Event>
Which I find really frustrating as when I first got the NTDS error I ran check disk on the bare metal box and it gave a clean bill of health!!
Siv
In that case you really need to look at either installing more drives for redundancy or at the very least have a decent DR strategy.
As for the errors in the logs on the ACMServer VM, we'll need some more info on how the VMs have been configured, as in how much RAM is installed on the host and how much of it has been assigned to the VMs, total amount of vCPUs assigned to the VMs, speed of SAS drives (I'm guessing 7200rpm here), VHD or VHDX files, dynamically expanding or fixed size drives, etc.
The NTDS 509 error implies disk I/O bottlenecks so you'll need to check if the ACMMail VM or host itself is doing anything disk intensive around the times you see these errors.
As for the errors in the logs on the ACMServer VM, we'll need some more info on how the VMs have been configured, as in how much RAM is installed on the host and how much of it has been assigned to the VMs, total amount of vCPUs assigned to the VMs, speed of SAS drives (I'm guessing 7200rpm here), VHD or VHDX files, dynamically expanding or fixed size drives, etc.
The NTDS 509 error implies disk I/O bottlenecks so you'll need to check if the ACMMail VM or host itself is doing anything disk intensive around the times you see these errors.
I lied I have just checked the event logs on the bare metal box and I do get the occasional fault reportedWell there you go! Make sure you have proper backups of your VMs.
Does your host have any free slots for more hard drives?
ASKER
The two VMs are configured with 4 CPUs threads each, as the server has 2 eight core E5530 Xeons running at 2.4 GHz with 16 logical processors. I also have a couple of Windows 7 VMs that run for some remote users using 1 virtual CPU each.
Server has 32 GB RAM and ACMServer has a start up RAM of 16GB and ACMMail has a Start Up RAM of 10GB.
I find that ACMServer's assigned memory will drop to around 5GB once it's been running for a few minutes. ACMMail tends to creep up to around 15GB.
When I configured the servers I was convinced that the ACMServer would need more RAM than ACMMail as It was the Essentials box and runs SQL Server 2014 as well and we do use the SQL server for a key database application that I wrote. Some how it manages to run happily in 5GB? Go figure?
SAS drives are 5400 rpm so a bit slow but are what came with it from Dell?
Drives are VHDX. The C: drive of each VM is on IDE Controller 0 and the data drive is on a SCSI Controller and they are both configured as dynamically expanding. ACM Server's O/S disk is maxed at 127GB and is currently using 50GB. Its Data disk is maxed at 1TB and is using 813GB.
I have a backup disk (external USB) that is attached in the VM to the SCSI Controller as Disk 2 which is a physical 2TB USB3 drive.
I have ACMMail and the two Windows 7 VMs start after ACMServer by 5 minutes staggering so the sequence on booting the bare metal is ACMServer starts immediately, ACMMail 5 minutes later, then the two Win7 VMs 5 minutes each after that.
Siv
Server has 32 GB RAM and ACMServer has a start up RAM of 16GB and ACMMail has a Start Up RAM of 10GB.
I find that ACMServer's assigned memory will drop to around 5GB once it's been running for a few minutes. ACMMail tends to creep up to around 15GB.
When I configured the servers I was convinced that the ACMServer would need more RAM than ACMMail as It was the Essentials box and runs SQL Server 2014 as well and we do use the SQL server for a key database application that I wrote. Some how it manages to run happily in 5GB? Go figure?
SAS drives are 5400 rpm so a bit slow but are what came with it from Dell?
Drives are VHDX. The C: drive of each VM is on IDE Controller 0 and the data drive is on a SCSI Controller and they are both configured as dynamically expanding. ACM Server's O/S disk is maxed at 127GB and is currently using 50GB. Its Data disk is maxed at 1TB and is using 813GB.
I have a backup disk (external USB) that is attached in the VM to the SCSI Controller as Disk 2 which is a physical 2TB USB3 drive.
I have ACMMail and the two Windows 7 VMs start after ACMServer by 5 minutes staggering so the sequence on booting the bare metal is ACMServer starts immediately, ACMMail 5 minutes later, then the two Win7 VMs 5 minutes each after that.
Siv
Sounds like you're using dynamic memory - FYI this isn't supported in Exchange 2013. Have a read of the Exchange memory requirements and recommendations section in this link for further information.
I generally recommend going with fixed size drives over dynamically expanding drives as this can easily lead to overprovisioning if you don't keep a running tally of the total maximum sizes of the VHD files. Performance difference is debatable but I still opt to go with fixed size VHDs for a production environment.
5400rpm SAS drives? Can you please post part numbers for these drives if possible so we can confirm? If they are indeed 5400rpm drives then that might explain why they were set up in a RAID0 array as this gives the best possible performance, however as mentioned above (many times may I add) RAID0 has no redundancy. If one drive fails you lose your entire array and you'll have to rely on backups to restore your environment.
The main concern here is whether the corruption has been passed on to your backups as well. How are you backing up your VMs? Have you checked the backup logs to ensure your VMs are backing up without issues?
If you have free slots on the host for more drives then I would suggest you pick up 4x higher speed drives (7200rpm at minimum) and configure them in a RAID10 array and move everything onto this new array.
I generally recommend going with fixed size drives over dynamically expanding drives as this can easily lead to overprovisioning if you don't keep a running tally of the total maximum sizes of the VHD files. Performance difference is debatable but I still opt to go with fixed size VHDs for a production environment.
5400rpm SAS drives? Can you please post part numbers for these drives if possible so we can confirm? If they are indeed 5400rpm drives then that might explain why they were set up in a RAID0 array as this gives the best possible performance, however as mentioned above (many times may I add) RAID0 has no redundancy. If one drive fails you lose your entire array and you'll have to rely on backups to restore your environment.
The main concern here is whether the corruption has been passed on to your backups as well. How are you backing up your VMs? Have you checked the backup logs to ensure your VMs are backing up without issues?
If you have free slots on the host for more drives then I would suggest you pick up 4x higher speed drives (7200rpm at minimum) and configure them in a RAID10 array and move everything onto this new array.
ASKER
I think if these drives are going down I am definitely going to back up the VMs and the System state of the bare metal box and replace the drives and do a restore.
As you indicated I will probably go for a 3 disk RAID 5. The owners are a charity for the aged and don't have huge sums to pay out and this server was only purchased (2nd Hand) in June 2014 so I can imagine they are not keen to fork out the kind of amounts that would be needed to implement your ideal disk setup, but I think a RAID 5 would be a good compromise.
As you indicated I will probably go for a 3 disk RAID 5. The owners are a charity for the aged and don't have huge sums to pay out and this server was only purchased (2nd Hand) in June 2014 so I can imagine they are not keen to fork out the kind of amounts that would be needed to implement your ideal disk setup, but I think a RAID 5 would be a good compromise.
ASKER
I just rechecked and actually I misread my utility that reports hardware details, the 5400 RPM drive is the external 2 TB USB 3.0 Toshiba Backup drive. I can't post the main drive details, I just have a small application that gives details from hardware configuration and it gives only the following:
Storage
Hard drives
Dell VIRTUAL DISK SCSI Disk Device
Interface SAS(Serial Attached SCSI)
Capacity 3725 GB
Real size 3,999,724,126,720 bytes
RAID Type None
S.M.A.R.T
S.M.A.R.T not supported
Partition 0
Partition ID Disk #0, Partition #0
File System NTFS
Volume Serial Number 0EB61270
Size 349 MB
Used Space 289 MB (82%)
Free Space 60 MB (18%)
Partition 1
Partition ID Disk #0, Partition #1
Disk Letter C:
File System NTFS
Volume Serial Number 8ABEA64B
Size 2047 GB
Used Space 1169 GB (57%)
Free Space 878 GB (43%)
TOSHIBA External USB 3.0 USB Device
Manufacturer TOSHIBA
Heads 16
Cylinders 243,201
Tracks 62,016,255
Sectors 3,907,024,065
SATA type SATA-II 3.0Gb/s
Device type Fixed
ATA Standard ATA8-ACS
Serial Number 24NAPL4QT
Firmware Version Number AY000U
LBA Size 48-bit LBA
Power On Count Unknown
Power On Time Unknown
Speed 5400 RPM
Features S.M.A.R.T., APM, NCQ
Max. Transfer Mode SATA II 3.0Gb/s
Used Transfer Mode SATA II 3.0Gb/s
Interface USB (SATA)
Capacity 1863 GB
Real size 2,000,398,931,968 bytes
RAID Type None
S.M.A.R.T
Status Unknown
Partition 0
Partition ID Disk #2, Partition #0
Size 1.81 TB
Optical Drives
TSSTcorp DVD+-RW TS-H653J ATA Device
Media Type DVD Writer
Name TSSTcorp DVD+-RW TS-H653J ATA Device
Availability Running/Full Power
Capabilities Random Access, Supports Writing, Supports Removable Media
Read capabilities CD-R, CD-RW, CD-ROM, DVD-RAM, DVD-ROM, DVD-R, DVD-RW, DVD+R, DVD+RW, DVD-R DL, DVD+R DL
Write capabilities CD-R, CD-RW, DVD-RAM, DVD-R, DVD-RW, DVD+R, DVD+RW, DVD-R DL, DVD+R DL
Config Manager Error Code Device is working properly
Config Manager User Config FALSE
Drive D:
Media Loaded FALSE
SCSI Bus 0
SCSI Logical Unit 0
SCSI Port 0
SCSI Target Id 0
Status OK
Siv
Storage
Hard drives
Dell VIRTUAL DISK SCSI Disk Device
Interface SAS(Serial Attached SCSI)
Capacity 3725 GB
Real size 3,999,724,126,720 bytes
RAID Type None
S.M.A.R.T
S.M.A.R.T not supported
Partition 0
Partition ID Disk #0, Partition #0
File System NTFS
Volume Serial Number 0EB61270
Size 349 MB
Used Space 289 MB (82%)
Free Space 60 MB (18%)
Partition 1
Partition ID Disk #0, Partition #1
Disk Letter C:
File System NTFS
Volume Serial Number 8ABEA64B
Size 2047 GB
Used Space 1169 GB (57%)
Free Space 878 GB (43%)
TOSHIBA External USB 3.0 USB Device
Manufacturer TOSHIBA
Heads 16
Cylinders 243,201
Tracks 62,016,255
Sectors 3,907,024,065
SATA type SATA-II 3.0Gb/s
Device type Fixed
ATA Standard ATA8-ACS
Serial Number 24NAPL4QT
Firmware Version Number AY000U
LBA Size 48-bit LBA
Power On Count Unknown
Power On Time Unknown
Speed 5400 RPM
Features S.M.A.R.T., APM, NCQ
Max. Transfer Mode SATA II 3.0Gb/s
Used Transfer Mode SATA II 3.0Gb/s
Interface USB (SATA)
Capacity 1863 GB
Real size 2,000,398,931,968 bytes
RAID Type None
S.M.A.R.T
Status Unknown
Partition 0
Partition ID Disk #2, Partition #0
Size 1.81 TB
Optical Drives
TSSTcorp DVD+-RW TS-H653J ATA Device
Media Type DVD Writer
Name TSSTcorp DVD+-RW TS-H653J ATA Device
Availability Running/Full Power
Capabilities Random Access, Supports Writing, Supports Removable Media
Read capabilities CD-R, CD-RW, CD-ROM, DVD-RAM, DVD-ROM, DVD-R, DVD-RW, DVD+R, DVD+RW, DVD-R DL, DVD+R DL
Write capabilities CD-R, CD-RW, DVD-RAM, DVD-R, DVD-RW, DVD+R, DVD+RW, DVD-R DL, DVD+R DL
Config Manager Error Code Device is working properly
Config Manager User Config FALSE
Drive D:
Media Loaded FALSE
SCSI Bus 0
SCSI Logical Unit 0
SCSI Port 0
SCSI Target Id 0
Status OK
Siv
What's more important here is the speed of the disks. Try and get the fastest possible drives that funds permit if you're going to go with RAID5 as there's a bit of performance hit when compared to other levels of RAID.
Have a read of this article which has a very good explanation of the write penalty when using RAID5.
Is OpenManage Server Administrator not installed on the host?
Have a read of this article which has a very good explanation of the write penalty when using RAID5.
Is OpenManage Server Administrator not installed on the host?
ASKER
Thanks for your help guys, I am going to replace the bare metal server's hard drives with a three disk RAID Array as soon as I can get down to the office in Wales and the disks ordered.
Not a problem, good luck!
ASKER
Hi,
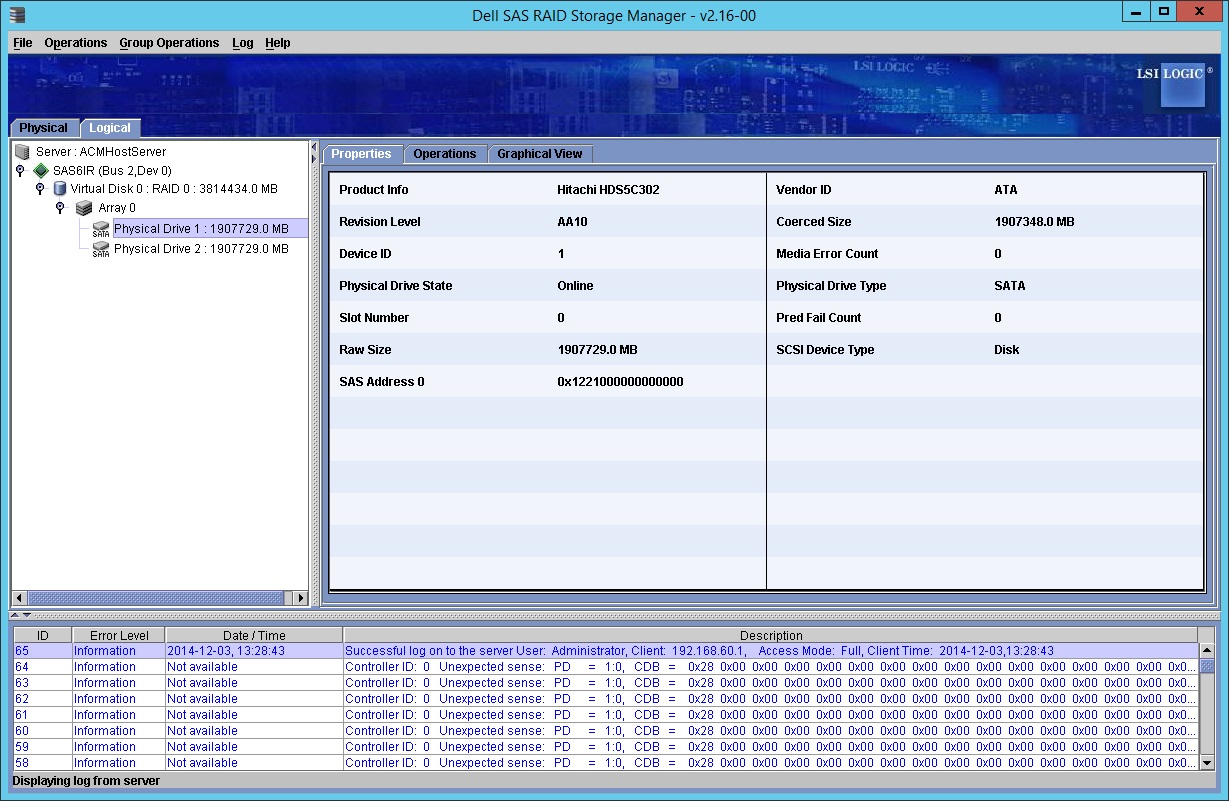
Before going down to the site I decided to load the Dell SAS RAID storage manager software to see if it could give me some more detailed information about the array and what the drive issues are and it appears that it believes there are no issues with the drives in the array?
Disk 1
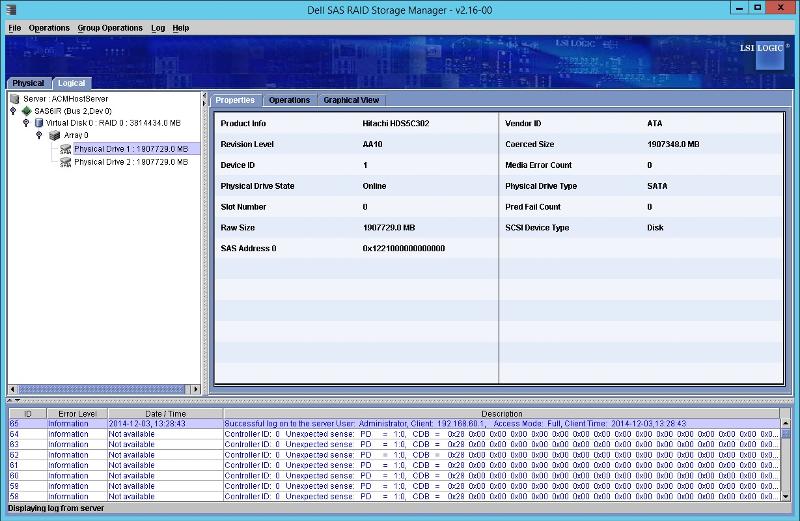
Disk 2
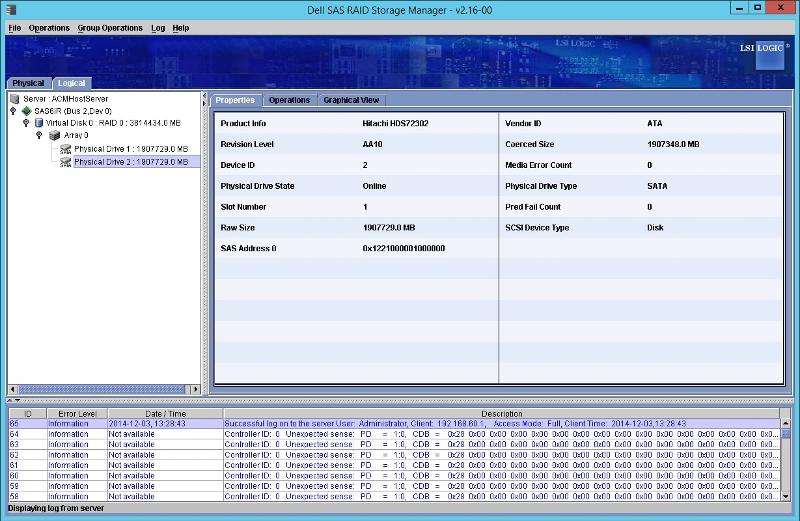
So maybe the NTDS Errors are a wild goose chase?
Before going down to the site I decided to load the Dell SAS RAID storage manager software to see if it could give me some more detailed information about the array and what the drive issues are and it appears that it believes there are no issues with the drives in the array?
Disk 1
Disk 2

So maybe the NTDS Errors are a wild goose chase?
Not if warning logs are being generated constantly. Did you run a consistency check in the RAID software to see if there were any errors?
ASKER
The question is, can I trust the Storage Manager software?
Also I discovered that the Dell SAS 6ir only supports RAID 0 or 1, so my best option if I do replace the disks would be to go for RAID 1
Siv
Also I discovered that the Dell SAS 6ir only supports RAID 0 or 1, so my best option if I do replace the disks would be to go for RAID 1
Siv
ASKER
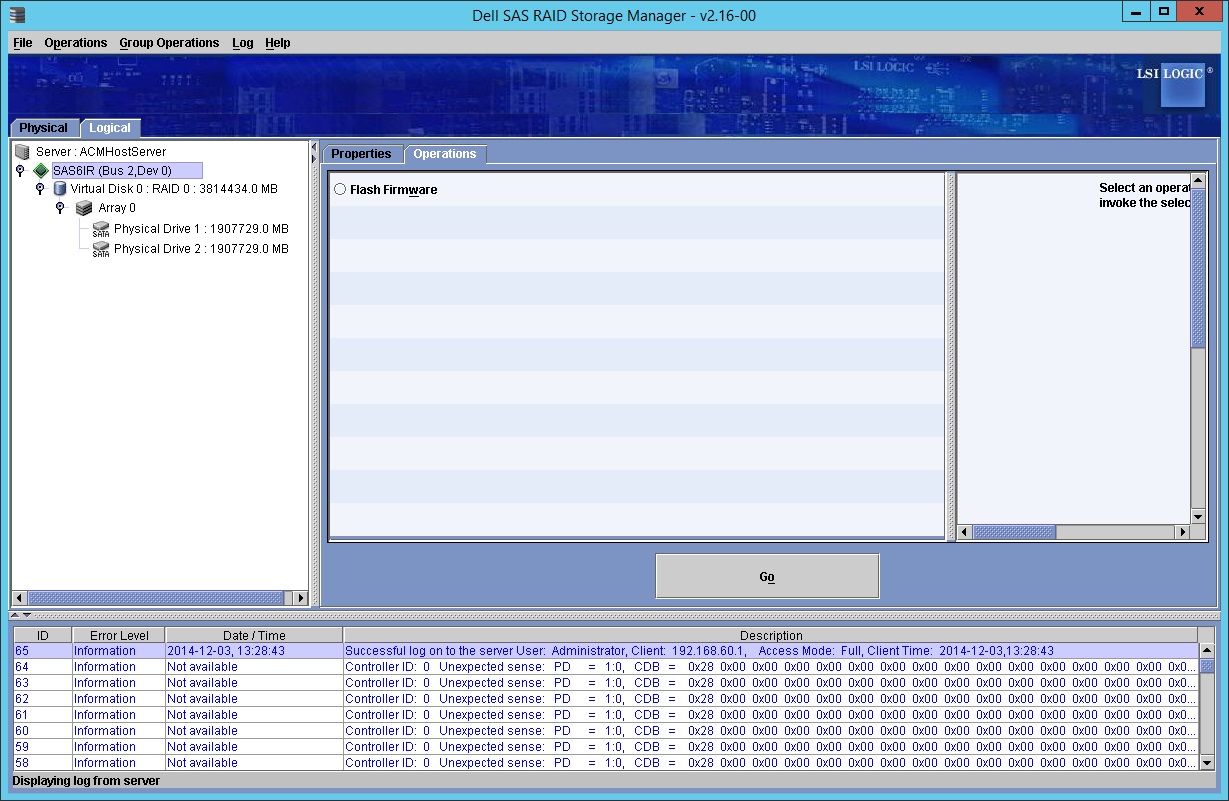
I was hoping to run some tests but the software doesn't allow me to do it. It mentions that there is the option to run a "patrol Read" and it gives these instructions:
Running a Patrol Read
The Dell PERC 5/i controller and the Dell PERC 6/i controller supports the patrol read feature. Patrol read provides a dynamic check on the virtual disk to confirm the disk is functioning properly. Patrol read runs in the background, adjusting its performance based on the patrol read settings and the i/o load on the controller. A patrol read can be used for all RAID levels and for all hotspare drives. To start a patrol read, follow these steps:
1.Click a controller icon in the left panel of the Dell SAS RAID Storage Manager window.
1.Select Operations -> Patrol Read.
To change the Patrol Read settings, follow these steps:
1.Click a controller icon in the left panel of the Dell SAS RAID Storage Manager window.
1.Select the Operations tab in the right panel, and select Set Patrol Read Properties.
1.Select an Operation Mode for patrol read. The options are
◦Auto: Patrol read runs automatically at the time interval you specify on this screen.
◦Manual: Patrol read runs only when you manually start it by selecting Start Patrol Read from the controller Options panel.
◦Disabled: Patrol read does not run at all.
1.(Optional) Specify a maximum count of physical drives to include in the patrol read. The count must be between 0 and 255.
1.(Optional) Select the virtual disks on this controller that you want to exclude from the patrol read. The existing virtual disks are listed in the gray box. To exclude a virtual disk, check the box next to it.
1.(Optional) Change the frequency at which the patrol read runs. The default frequency is 7 days (604800 seconds), which is suitable for most configurations.
However when I follow the procedure the only thing I am offered in the "Operations" tab is "Flash Firmware":
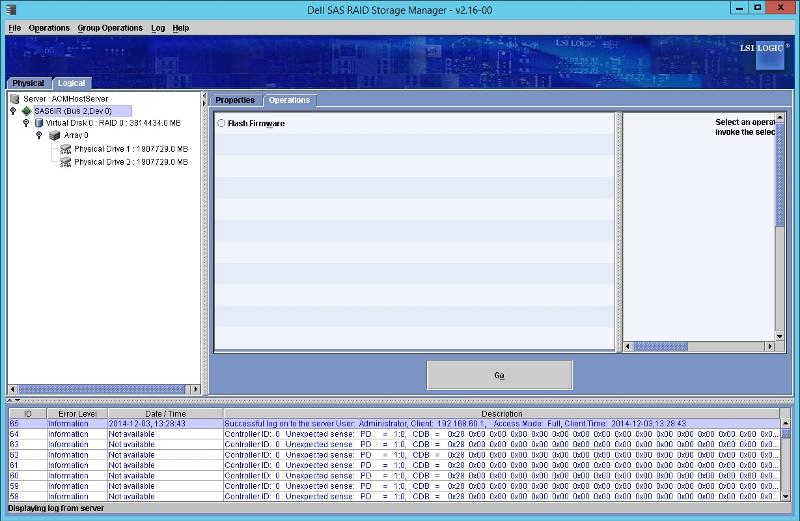
Running a Patrol Read
The Dell PERC 5/i controller and the Dell PERC 6/i controller supports the patrol read feature. Patrol read provides a dynamic check on the virtual disk to confirm the disk is functioning properly. Patrol read runs in the background, adjusting its performance based on the patrol read settings and the i/o load on the controller. A patrol read can be used for all RAID levels and for all hotspare drives. To start a patrol read, follow these steps:
1.Click a controller icon in the left panel of the Dell SAS RAID Storage Manager window.
1.Select Operations -> Patrol Read.
To change the Patrol Read settings, follow these steps:
1.Click a controller icon in the left panel of the Dell SAS RAID Storage Manager window.
1.Select the Operations tab in the right panel, and select Set Patrol Read Properties.
1.Select an Operation Mode for patrol read. The options are
◦Auto: Patrol read runs automatically at the time interval you specify on this screen.
◦Manual: Patrol read runs only when you manually start it by selecting Start Patrol Read from the controller Options panel.
◦Disabled: Patrol read does not run at all.
1.(Optional) Specify a maximum count of physical drives to include in the patrol read. The count must be between 0 and 255.
1.(Optional) Select the virtual disks on this controller that you want to exclude from the patrol read. The existing virtual disks are listed in the gray box. To exclude a virtual disk, check the box next to it.
1.(Optional) Change the frequency at which the patrol read runs. The default frequency is 7 days (604800 seconds), which is suitable for most configurations.
However when I follow the procedure the only thing I am offered in the "Operations" tab is "Flash Firmware":
Those "Unexpected Sense..." entries are typically indicative of bad blocks on a HDD.
Look for event ID 113, a warning, in your event log, it will contain the complete data set about the error.
Dan
Look for event ID 113, a warning, in your event log, it will contain the complete data set about the error.
Dan
ASKER
Dan,
I get no results from the system log for event 113?
Siv
I get no results from the system log for event 113?
Siv
OK, still those RAID controller events are disk errors. Don't know why there aren't any in the event logs, but the errors have been recorded by the controller.
I would believe what the controller has in its event log.
Dan
I would believe what the controller has in its event log.
Dan
ASKER
In the help for the Storage Manager software it says that 0x0028 is:
0x0028 Info Rebuild rate changed to %d%%
Siv
0x0028 Info Rebuild rate changed to %d%%
Siv
ASKER
I checked the application log and there are 113 event IDs and they are the same 64 entries as appear in the Storage Manager Screen:
Log Name: Application
Source: MR_MONITOR
Date: 03/12/2014 13:27:50
Event ID: 113
Task Category: 2.
Level: Information
Keywords: Classic
User: N/A
Computer: ACMHostServer
Description:
Controller ID: 0 Unexpected sense: PD= 1:0, CDB = 0x28 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 , Sense = 0x70 0x00 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 .
Event Xml:
<Event xmlns="http://schemas.microsoft.com/win/2004/08/events/event">
<System>
<Provider Name="MR_MONITOR" />
<EventID Qualifiers="0">113</EventI
<Level>4</Level>
<Task>2</Task>
<Keywords>0x80000000000000
<TimeCreated SystemTime="2014-12-03T13:
<EventRecordID>4897</Event
<Channel>Application</Chan
<Computer>ACMHostServer</C
<Security />
</System>
<EventData>
<Data>Controller ID: 0 Unexpected sense: PD= 1:0, CDB = 0x28 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 , Sense = 0x70 0x00 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 </Data>
</EventData>
</Event>
Log Name: Application
Source: MR_MONITOR
Date: 03/12/2014 13:27:50
Event ID: 113
Task Category: 2.
Level: Information
Keywords: Classic
User: N/A
Computer: ACMHostServer
Description:
Controller ID: 0 Unexpected sense: PD= 1:0, CDB = 0x28 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 , Sense = 0x70 0x00 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 .
Event Xml:
<Event xmlns="http://schemas.microsoft.com/win/2004/08/events/event">
<System>
<Provider Name="MR_MONITOR" />
<EventID Qualifiers="0">113</EventI
<Level>4</Level>
<Task>2</Task>
<Keywords>0x80000000000000
<TimeCreated SystemTime="2014-12-03T13:
<EventRecordID>4897</Event
<Channel>Application</Chan
<Computer>ACMHostServer</C
<Security />
</System>
<EventData>
<Data>Controller ID: 0 Unexpected sense: PD= 1:0, CDB = 0x28 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 , Sense = 0x70 0x00 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 </Data>
</EventData>
</Event>
ASKER
I looked up the other error code 0x70 and in the help it gives this:
0x0070 Info PD removed: %s
I don't know what that means?
Siv
0x0070 Info PD removed: %s
I don't know what that means?
Siv
ASKER
I had a look in the Intel document and the error seems to break down as this:
Error Code Sense Key Additional Sense Code Add. Sense Code Qualifier
0x70 0x03 0x11 0x00
Looking up the meaning of the sense codes I reckon if I am understanding the document these errors are the 4th one below:
3 3 0 Medium Error - write fault
3 0C FF Medium Error - write recovery time limit exceeded
3 10 0 Medium Error - ID CRC error
3 11 0 Medium Error - unrecovered read error
3 11 1 Medium Error - read retries exhausted
Medium Error - unrecovered read error
Unless 11 is not an 0x value but is hex in which case our additional sense code is 17 which doesn't appear in the Medium Errors section as a value?
Siv
Error Code Sense Key Additional Sense Code Add. Sense Code Qualifier
0x70 0x03 0x11 0x00
Looking up the meaning of the sense codes I reckon if I am understanding the document these errors are the 4th one below:
3 3 0 Medium Error - write fault
3 0C FF Medium Error - write recovery time limit exceeded
3 10 0 Medium Error - ID CRC error
3 11 0 Medium Error - unrecovered read error
3 11 1 Medium Error - read retries exhausted
Medium Error - unrecovered read error
Unless 11 is not an 0x value but is hex in which case our additional sense code is 17 which doesn't appear in the Medium Errors section as a value?
Siv
If you read the first link I posted and go to the entries that were accepted, you see referenced to sense key 3 errors.
You have the same thing showing:
Dan
You have the same thing showing:
<EventData>
<Data>Controller ID: 0 Unexpected sense: PD= 1:0, CDB = 0x28 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 , Sense = 0x70 0x00 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 </Data>
</EventData>
Dan
ASKER
I've just reloaded the Storage Manager and there have been no further entries logged and I don't know how long ago these errors are from, could it be that there were these 60 odd errors when the drives were manufactured and since then there have been no more?
Siv
Siv
Your event log entry is from today:
Dan
Log Name: Application
Source: MR_MONITOR
Date: 03/12/2014 13:27:50
Event ID: 113
Task Category: 2.
Level: Information
Keywords: Classic
User: N/A
Computer: ACMHostServer
Dan
ASKER
Dan,
They only appeared today because until then I didn't have the SAS Monitor application installed, so I think these are what is in the SAS logs since the machine was installed in June 2014.
Although the machine is second hand I changed the RAID setup when I installed it as they needed more than 2TB which is what it had when they purchased it. The Sellers told us it had 4TB storage, well it did but not when configured as RAID 1. So I was forced to rebuild the array then. So I imagine the SAS Controller would clear the logs at that point. If the logs remain even if the array is altered then these will be all the errors since the machine was created by Dell which is probably 3 years ago.
Siv
They only appeared today because until then I didn't have the SAS Monitor application installed, so I think these are what is in the SAS logs since the machine was installed in June 2014.
Although the machine is second hand I changed the RAID setup when I installed it as they needed more than 2TB which is what it had when they purchased it. The Sellers told us it had 4TB storage, well it did but not when configured as RAID 1. So I was forced to rebuild the array then. So I imagine the SAS Controller would clear the logs at that point. If the logs remain even if the array is altered then these will be all the errors since the machine was created by Dell which is probably 3 years ago.
Siv
ASKER
I replaced the faulty drives with two brand new Toshiba 2TB drives and configured them the same as before in a RAID 0 stripe set. I was hoping to get 4TB drives and do a mirror but the pricing was unacceptable to the client.
I restored the system from backups and all was running fine for a couple of days then this morning I got this again in the reports:
NTDS ISAM
NTDS (592) NTDSA: A request to read from the file "C:\Windows\NTDS\ntds.dit"
Last occurrence: 10 December 2014 03:28:49
Also in the same report I had this:
NTDS General
Active Directory Domain Services could not disable the software-based disk write cache on the following hard disk.
Hard disk: c:
Data might be lost during system failures.
Last occurrence: 10 December 2014 05:43:38
So I am wondering if the NTDS Error was always a red herring and the actual error I should have been focussing on was the hard disk bad block warnings that were periodically appearing in the logs?
My thinking now is that the reason the NTDS error is coming up is because the write caching is enabled on the ACMServer's C: drive and it is this fact that means occasionally when the system wants to write to the disk, the write request is cached and somehow NTDS knows that the actual write didn't occur for 20 seconds?
My question, if anyone's listening in, is what are the implications of turning off the write caching, will that impact performance of the server at all or will it improve it?
Siv
I restored the system from backups and all was running fine for a couple of days then this morning I got this again in the reports:
NTDS ISAM
NTDS (592) NTDSA: A request to read from the file "C:\Windows\NTDS\ntds.dit"
Last occurrence: 10 December 2014 03:28:49
Also in the same report I had this:
NTDS General
Active Directory Domain Services could not disable the software-based disk write cache on the following hard disk.
Hard disk: c:
Data might be lost during system failures.
Last occurrence: 10 December 2014 05:43:38
So I am wondering if the NTDS Error was always a red herring and the actual error I should have been focussing on was the hard disk bad block warnings that were periodically appearing in the logs?
My thinking now is that the reason the NTDS error is coming up is because the write caching is enabled on the ACMServer's C: drive and it is this fact that means occasionally when the system wants to write to the disk, the write request is cached and somehow NTDS knows that the actual write didn't occur for 20 seconds?
My question, if anyone's listening in, is what are the implications of turning off the write caching, will that impact performance of the server at all or will it improve it?
Siv
Write caching is typically transparent to the OS. When it is enabled (as it should be) the disk cache is sending the "all is written" signal to the OS, so the OS thinks the data is successfully written to an actual disk. Then a few 100 milliseconds later the disk cache is flushed to disk.
Turning off write caching will directly impact the performance of a server, especially when it is a file server. You cannot disable write caching on a volume unless that volume is a separate set of disks. So, since you have only 2 disks in a R0 setup and probably have partitioned that disk set up, disabling write caching may possibly satisfy AD but very much annoy and file services hosted on this server.
I do not like a server having its main disks in a RAID0 set. Also, it would be better to have a set of disks that supported the other services hosted on it.
For example:
- disk controller 1
--- disk set 1 = OS, AD db, DNS files, DHCP db
- disk controller 2
--- disk set 2 = file shares, SQL db files, website files, etc.
At least here, you could disable write caching and not effect the performance of disk intensive services like file sharing.
As for the error that is coming up now... I would verify that the disk controller has the latest BIOS, firmware and OS drivers installed.
But the error can also mean that the disk set was busy doing something else when the AD services requested a read on the "ntds.dit" file. I would use performance monitor to look at the amount of pressure on the disks.
Here are some reference links for monitoring disk performance:
1. http://technet.microsoft.com/en-us/library/cc938959.aspx
2. http://blogs.technet.com/b/askcore/archive/2012/02/07/measuring-disk-latency-with-windows-performance-monitor-perfmon.aspx
3. http://blogs.technet.com/b/askcore/archive/2012/03/16/windows-performance-monitor-disk-counters-explained.aspx
Dan
Turning off write caching will directly impact the performance of a server, especially when it is a file server. You cannot disable write caching on a volume unless that volume is a separate set of disks. So, since you have only 2 disks in a R0 setup and probably have partitioned that disk set up, disabling write caching may possibly satisfy AD but very much annoy and file services hosted on this server.
I do not like a server having its main disks in a RAID0 set. Also, it would be better to have a set of disks that supported the other services hosted on it.
For example:
- disk controller 1
--- disk set 1 = OS, AD db, DNS files, DHCP db
- disk controller 2
--- disk set 2 = file shares, SQL db files, website files, etc.
At least here, you could disable write caching and not effect the performance of disk intensive services like file sharing.
As for the error that is coming up now... I would verify that the disk controller has the latest BIOS, firmware and OS drivers installed.
But the error can also mean that the disk set was busy doing something else when the AD services requested a read on the "ntds.dit" file. I would use performance monitor to look at the amount of pressure on the disks.
Here are some reference links for monitoring disk performance:
1. http://technet.microsoft.com/en-us/library/cc938959.aspx
2. http://blogs.technet.com/b/askcore/archive/2012/02/07/measuring-disk-latency-with-windows-performance-monitor-perfmon.aspx
3. http://blogs.technet.com/b/askcore/archive/2012/03/16/windows-performance-monitor-disk-counters-explained.aspx
Dan
ASKER
Dan,
Thanks for coming back. I will have a root through those documents. We normally do the backup at 9:00 PM and the differential backups take around 11 minutes. I suspect it occasionally does a full backup and that might have still been running at 03:28. The only other thing that might have some bearing the Anti-Virus (ESET File Security v4.5 For Windows Server). I checked and it does have the NTDS folder excluded from scanning and active protection.
Siv
Thanks for coming back. I will have a root through those documents. We normally do the backup at 9:00 PM and the differential backups take around 11 minutes. I suspect it occasionally does a full backup and that might have still been running at 03:28. The only other thing that might have some bearing the Anti-Virus (ESET File Security v4.5 For Windows Server). I checked and it does have the NTDS folder excluded from scanning and active protection.
Siv
It's also best practice to move your AD database files to a separate VHD file on a virtual SCSI controller for better durability (according to Microsoft).