WeThotUWasAToad
asked on
Combine variable data from multiple redundant rows in Excel
Hello,
Is there a way to capture data from non-blank cells when multiple redundant rows exist in an Excel (2013) spreadsheet?
As an example, suppose you have a spreadsheet with a large number of rows which was created by pasting the contents of several other spreadsheets containing lists of contacts. And suppose you know that, as a result of combining the spreadsheets, some contacts are listed more than once but the redundant listings contain variable amounts of data which you don't want to lose.
For example, the following screenshot contains seven fictitious entries with typical contact data categories:
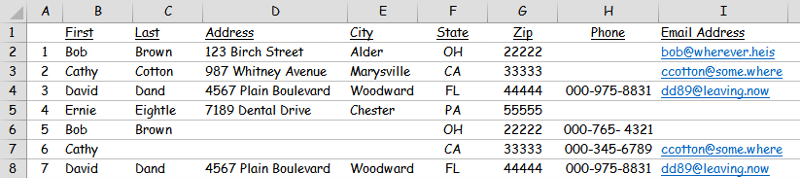 but notice that, based on email address, entries #2 & #6 are the same contact:
but notice that, based on email address, entries #2 & #6 are the same contact:
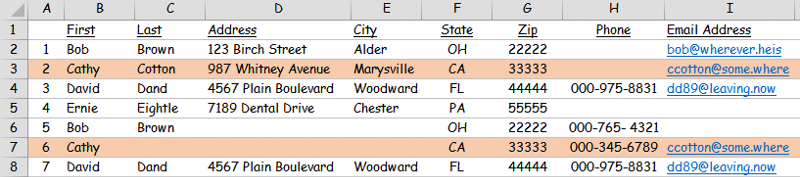 However, you don't want to simply delete the first or the second occurrence because each of them contains data not present in the other (ie #2 includes last name & address while #6 includes phone number.
However, you don't want to simply delete the first or the second occurrence because each of them contains data not present in the other (ie #2 includes last name & address while #6 includes phone number.
For this particular contact, the best outcome would be a single entry which contains data in all fields.
As I wrote this question, I realized that a formula which consolidates data in this way would necessarily require some rules — and therefore, may not be solvable with a simple Excel formula. :
1) it should be based primarily on col H or I (phone or email address) since those are the most unique and therefore most reliable indicators as to whether or not two or more rows are redundant. For example, #1 & #5 are "probably" the same person (based on matching name & zip) but it's not 100% certain:
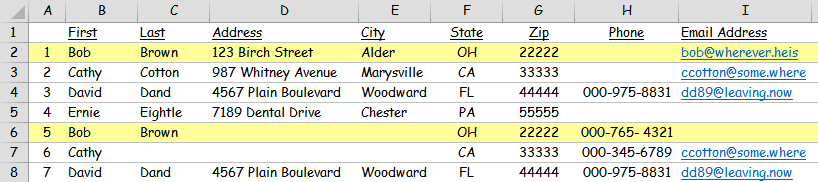
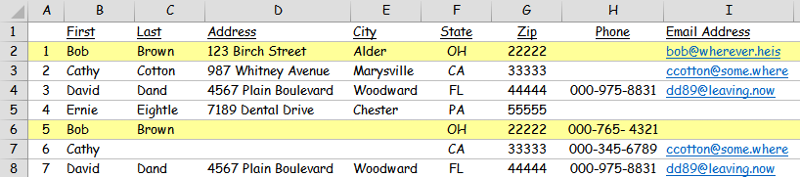 2) some type of rule would be required for rows which although known to match (based on phone number and email address), contain differences in some other field, say "Address" for example.
2) some type of rule would be required for rows which although known to match (based on phone number and email address), contain differences in some other field, say "Address" for example.
3) are there other rules which I have not thought of?
Thanks
Is there a way to capture data from non-blank cells when multiple redundant rows exist in an Excel (2013) spreadsheet?
As an example, suppose you have a spreadsheet with a large number of rows which was created by pasting the contents of several other spreadsheets containing lists of contacts. And suppose you know that, as a result of combining the spreadsheets, some contacts are listed more than once but the redundant listings contain variable amounts of data which you don't want to lose.
For example, the following screenshot contains seven fictitious entries with typical contact data categories:
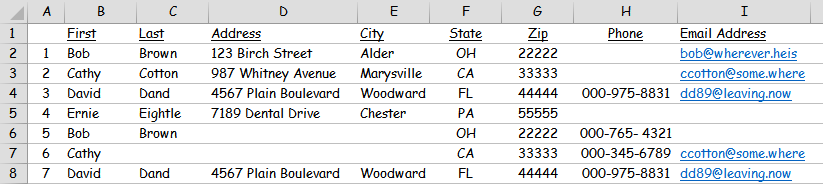 but notice that, based on email address, entries #2 & #6 are the same contact:
but notice that, based on email address, entries #2 & #6 are the same contact: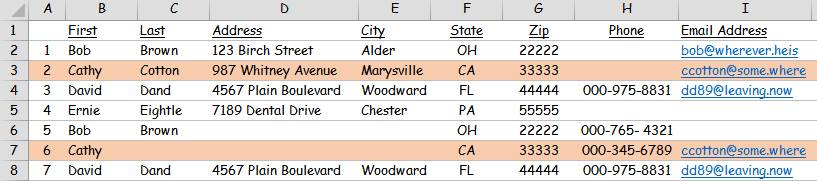 However, you don't want to simply delete the first or the second occurrence because each of them contains data not present in the other (ie #2 includes last name & address while #6 includes phone number.
However, you don't want to simply delete the first or the second occurrence because each of them contains data not present in the other (ie #2 includes last name & address while #6 includes phone number.For this particular contact, the best outcome would be a single entry which contains data in all fields.
As I wrote this question, I realized that a formula which consolidates data in this way would necessarily require some rules — and therefore, may not be solvable with a simple Excel formula. :
1) it should be based primarily on col H or I (phone or email address) since those are the most unique and therefore most reliable indicators as to whether or not two or more rows are redundant. For example, #1 & #5 are "probably" the same person (based on matching name & zip) but it's not 100% certain:
 2) some type of rule would be required for rows which although known to match (based on phone number and email address), contain differences in some other field, say "Address" for example.
2) some type of rule would be required for rows which although known to match (based on phone number and email address), contain differences in some other field, say "Address" for example.3) are there other rules which I have not thought of?
Thanks
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER