Bill H
asked on
Large Scanning document solution
hey guys, we have a probably have a 150 banker boxes of documents that we are storing in our file room.
We are looking to go digital with these and have them searchable.
Can you recommend a solution to scan these in and make them searchable?
We are looking to go digital with these and have them searchable.
Can you recommend a solution to scan these in and make them searchable?
Dave Baldwin
Yes, hire one of the legal/medical record scanning services. They do it every day but I would do short run first to make sure you can OCR the results.
ASKER
Looking to do this in house please.
Several issues to consider:
Do you have a preference for outsourcing it or doing it yourself?
If outsourcing, are you willing to send the docs offsite or do you need someone to do it on-premise?
If doing it yourself, do you already have scanners or will you buy them as part of the project?
If doing it yourself, you'll want to understand a lot about the source docs, such as:
How many thousands of pages are in the 150 banker boxes?
Are you concerned about new docs coming in or just the existing docs in the file room? If the former, how many pages per day of new paper are coming in?
Are the docs all single-sided? If not, what percentage of the docs are double-sided? In other words, would a duplex scanner be helpful?
Are the docs all (or mostly) black and white? In other words, is color scanning needed?
Are the docs all (or mostly) letter size? Any small/odd-size docs? Or large ones? Any legal size? Any wider than 8.5"?
Most software these days can create PDF Searchable Image files, meaning a PDF file contains the scanned raster image (bitmap/graphic), as well as the text created from the OCR process. And most scanners sold these days bundle such software.
Of course, budget is always an issue. My experience of more than 20 years in the high-end document management/imaging space taught me that "backfile conversion" (which is what we call scanning existing paper in the DMS arena) is always more costly and less successful than we'd like. In fact, many of my customers during those 20+ years opted not to do any backfile conversion, while others did it only for one to two year's worth of paper — they let the rest of the paper die a natural death, depending on the mandatory document retention requirements and associated periodic destruction policies.
If you want to go forward with an in-house approach, I'll be happy to give you some hardware and software recommendations after you give me more info about the source docs. Regards, Joe
Do you have a preference for outsourcing it or doing it yourself?
If outsourcing, are you willing to send the docs offsite or do you need someone to do it on-premise?
If doing it yourself, do you already have scanners or will you buy them as part of the project?
If doing it yourself, you'll want to understand a lot about the source docs, such as:
How many thousands of pages are in the 150 banker boxes?
Are you concerned about new docs coming in or just the existing docs in the file room? If the former, how many pages per day of new paper are coming in?
Are the docs all single-sided? If not, what percentage of the docs are double-sided? In other words, would a duplex scanner be helpful?
Are the docs all (or mostly) black and white? In other words, is color scanning needed?
Are the docs all (or mostly) letter size? Any small/odd-size docs? Or large ones? Any legal size? Any wider than 8.5"?
Most software these days can create PDF Searchable Image files, meaning a PDF file contains the scanned raster image (bitmap/graphic), as well as the text created from the OCR process. And most scanners sold these days bundle such software.
Of course, budget is always an issue. My experience of more than 20 years in the high-end document management/imaging space taught me that "backfile conversion" (which is what we call scanning existing paper in the DMS arena) is always more costly and less successful than we'd like. In fact, many of my customers during those 20+ years opted not to do any backfile conversion, while others did it only for one to two year's worth of paper — they let the rest of the paper die a natural death, depending on the mandatory document retention requirements and associated periodic destruction policies.
If you want to go forward with an in-house approach, I'll be happy to give you some hardware and software recommendations after you give me more info about the source docs. Regards, Joe
A photocopier with built-in scanning solution? If you are looking for a new copier at the present time then this might be the way to go.
ASKER
Joe,
Inhouse - we have not purchased scanners yet, we will need to get this. These are old documents, nothing really knew coming in. I think they are all singled singed mostly and just text. Color not needed.
Inhouse - we have not purchased scanners yet, we will need to get this. These are old documents, nothing really knew coming in. I think they are all singled singed mostly and just text. Color not needed.
How many pages? A rough estimate is fine.
Are they all (or mostly) letter size? Any small/odd-size? Or large ones? Any legal size? Any wider than 8.5"?
What is the total budget for hardware and software?
Are they all (or mostly) letter size? Any small/odd-size? Or large ones? Any legal size? Any wider than 8.5"?
What is the total budget for hardware and software?
ASKER
Hmm..not sure, there is a lot, lets say a 500,000?
Mostly standard letter size.
No budget yet, we've never done this before.
Mostly standard letter size.
No budget yet, we've never done this before.
It sounds like a project without a critical deadline, but for the sake of planning, let's say you want to complete the scanning in around six months. With 22 work days in a month, that's 132 days - allowing for some holidays and days where the scanning takes a back seat, let's call it 125 days. With 500K pages, that's 4,000 per day. Let's further say that you want to achieve it with just one scanner, meaning you should get a scanner with a duty cycle of 4,000 pages per day. For that duty cycle, I recommend the Fujitsu fi-7160 or the Kodak i2400:
http://www.fujitsu.com/us/products/computing/peripheral/scanners/fi/workgroup/fi7160/index.html
http://www.amazon.com/Fujitsu-Fi-7160-Sheetfed-Document-PA03670-B055/dp/B00GY2GHAK
http://graphics.kodak.com/DocImaging/US/en/Products/Document_Scanners/Desktop/i2400_Scanner/index.htm
http://www.amazon.com/Kodak-GD9466-i2400-Scanner/dp/B004X6BPFQ
Both come with bundled software that can scan directly to PDF searchable files (via the included OCR). But they also both have ISIS and TWAIN drivers, meaning that nearly all third-party scanning/imaging software can support these scanners, so if you wind up not liking the bundled software, or needing features that the bundled software doesn't have, you can easily purchase other software that will work fine with these scanners.
Regards, Joe
http://www.fujitsu.com/us/products/computing/peripheral/scanners/fi/workgroup/fi7160/index.html
http://www.amazon.com/Fujitsu-Fi-7160-Sheetfed-Document-PA03670-B055/dp/B00GY2GHAK
http://graphics.kodak.com/DocImaging/US/en/Products/Document_Scanners/Desktop/i2400_Scanner/index.htm
http://www.amazon.com/Kodak-GD9466-i2400-Scanner/dp/B004X6BPFQ
Both come with bundled software that can scan directly to PDF searchable files (via the included OCR). But they also both have ISIS and TWAIN drivers, meaning that nearly all third-party scanning/imaging software can support these scanners, so if you wind up not liking the bundled software, or needing features that the bundled software doesn't have, you can easily purchase other software that will work fine with these scanners.
Regards, Joe
ASKER
Joe,
Thanks. Now the question is where to store the data and search the documents?
Thanks. Now the question is where to store the data and search the documents?
A typical letter size page scanned to a searchable PDF at 300 DPI in B&W (which, in most cases, works very well for performing accurate OCR) requires around 50KB, with the typical compression used by modern software. So 500K pages will require around 25GB. That's not a lot of storage these days, so you may store it anywhere you want, perhaps on a shared network folder so everyone can access it.
If you want superb searching ability, I strongly recommend dtSearch:
http://www.dtsearch.com/
I have been using it for around 20 years — extraordinarily good piece of software!
When it indexes documents that are mixed binary and text files (such as a PDF Searchable Image file that has been created by scanning and OCR), it has an option to filter out the binary. This makes the index much smaller than other products which also index the binary code (for no good reason). dtSearch has an interesting filtering algorithm that scans a binary file for anything that looks like text using multiple encoding detection methods. The algorithm detects sequences of text with different encodings or formats, and ignores the binary. This is perfect for PDF Searchable Image files created by OCR.
It has built-in viewers for most common file types (PDF, of course — see below), but can also launch an external program automatically when the hit is on a file type for which it doesn't have a viewer. You can control whether or not the external viewer is launched on a case-by-case basis, that is, you can have different actions for each and every file type.
It has special handling for PDF files, allowing you either to view the PDF file in place (in dtSearch) or in a separate instance of Adobe Reader (and in both cases, hits are highlighted). Also, to improve performance, there's an option that lets you tell dtSearch to automatically open Adobe Reader for PDF files (the point is that Adobe Reader runs embedded in dtSearch and it opens PDF files much more quickly if Adobe Reader is already running separately when a PDF is opened in dtSearch).
It has extensive search options, including stemming, phonic, fuzzy, synonym, any words, all words, Boolean, and, of course, exact/specific phrases. Here's the search request dialog:
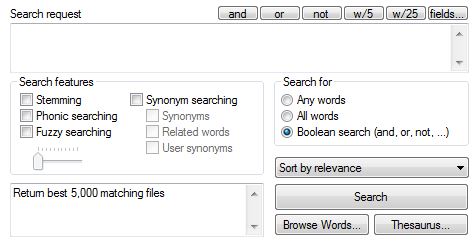
It utilizes the Windows Task Scheduler to update indexes. I currently have 44 indexes set up and I have it configured to update (a subset of) them every day in the wee hours. Of course, you may set it up to update the indexes as frequently/infrequently as you want (and you may specify which ones get updated – if some data is static, there's no need to update its index). You may have any number of indexes, each of which may index any number of folders/files, and searches may take place on one or more of the indexes. I often build an index on the fly for a folder/subfolders that I want to search – indexing is very fast (as is searching).
As a disclaimer, I want to emphasize that I have no affiliation with any of the companies mentioned in these posts, and no financial interest in them whatsoever. I am simply a happy user/customer. Regards, Joe
If you want superb searching ability, I strongly recommend dtSearch:
http://www.dtsearch.com/
I have been using it for around 20 years — extraordinarily good piece of software!
When it indexes documents that are mixed binary and text files (such as a PDF Searchable Image file that has been created by scanning and OCR), it has an option to filter out the binary. This makes the index much smaller than other products which also index the binary code (for no good reason). dtSearch has an interesting filtering algorithm that scans a binary file for anything that looks like text using multiple encoding detection methods. The algorithm detects sequences of text with different encodings or formats, and ignores the binary. This is perfect for PDF Searchable Image files created by OCR.
It has built-in viewers for most common file types (PDF, of course — see below), but can also launch an external program automatically when the hit is on a file type for which it doesn't have a viewer. You can control whether or not the external viewer is launched on a case-by-case basis, that is, you can have different actions for each and every file type.
It has special handling for PDF files, allowing you either to view the PDF file in place (in dtSearch) or in a separate instance of Adobe Reader (and in both cases, hits are highlighted). Also, to improve performance, there's an option that lets you tell dtSearch to automatically open Adobe Reader for PDF files (the point is that Adobe Reader runs embedded in dtSearch and it opens PDF files much more quickly if Adobe Reader is already running separately when a PDF is opened in dtSearch).
It has extensive search options, including stemming, phonic, fuzzy, synonym, any words, all words, Boolean, and, of course, exact/specific phrases. Here's the search request dialog:
It utilizes the Windows Task Scheduler to update indexes. I currently have 44 indexes set up and I have it configured to update (a subset of) them every day in the wee hours. Of course, you may set it up to update the indexes as frequently/infrequently as you want (and you may specify which ones get updated – if some data is static, there's no need to update its index). You may have any number of indexes, each of which may index any number of folders/files, and searches may take place on one or more of the indexes. I often build an index on the fly for a folder/subfolders that I want to search – indexing is very fast (as is searching).
As a disclaimer, I want to emphasize that I have no affiliation with any of the companies mentioned in these posts, and no financial interest in them whatsoever. I am simply a happy user/customer. Regards, Joe
ASKER
Joe thanks so much for this information.
I want to present an outsourced solution as well. Do you think it's more cost effective?
I want to present an outsourced solution as well. Do you think it's more cost effective?
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Joe, those look like really cheap scanners?
DTsearch looks good. But then i need a SAN to store all the data and backups of it as well.
DTsearch looks good. But then i need a SAN to store all the data and backups of it as well.
"Cheap" is a relative term. Some folks call those scanners too expensive. Based on your volume, I think they can do the job. But if you want scanners that are less "cheap", the sky is the limit. When I worked for 20+ years in the high-end document management/imaging space (million dollar systems), I was partial to Kodak scanners back then, often costing more than six figures. These days, Kodak desktop scanners range from a list price of $400-$3,500; departmental scanners from $4,500-$8,500; and production scanners with unlimited duty cycles as high as $80,000. I asked earlier what your budget is and you said you don't have one yet, so I made recommendations on the least expensive scanners that I think can handle your volume. But if you want better scanners, by all means go for it.
Of course you need to store the data somewhere (and of course you need to back it up). It doesn't have to be a SAN, but it does have to be some form of shared storage that all of your users can access. That's true whether or not you choose to go with dtSearch. Regards, Joe
Of course you need to store the data somewhere (and of course you need to back it up). It doesn't have to be a SAN, but it does have to be some form of shared storage that all of your users can access. That's true whether or not you choose to go with dtSearch. Regards, Joe