Recognize Font from Image
Hi,
I have a tool that generates an image with Text and other images.
I want to know the font that was generated on the image that I have.
What is the best way to do that?
I have a tool that generates an image with Text and other images.
I want to know the font that was generated on the image that I have.
What is the best way to do that?
A quick-and-dirty technique is to copy/paste the text into Word. It will show the font name and size. Regards, Joe
ASKER
This did not give me the required results.
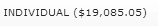

ASKER
This is actually an image. No text selection is possible.
> generates an image with Text
Based on your posted images, I'm guessing there really isn't "Text" there — it's likely just a raster image (bitmap/graphic). In order to create text from that, you need to run OCR on it. For example, attached is a PDF searchable image file that I created from your first image. It contains both the image and the text created by OCR. You may open the PDF in Adobe Reader (or whatever PDF reader/viewer you use), select and copy the text, then paste it into Word. I did that — Word reports it as Courier 5-point. I'll do your second image in a few minutes. Regards, Joe
Sync--ScrShot4.pdf
Based on your posted images, I'm guessing there really isn't "Text" there — it's likely just a raster image (bitmap/graphic). In order to create text from that, you need to run OCR on it. For example, attached is a PDF searchable image file that I created from your first image. It contains both the image and the text created by OCR. You may open the PDF in Adobe Reader (or whatever PDF reader/viewer you use), select and copy the text, then paste it into Word. I did that — Word reports it as Courier 5-point. I'll do your second image in a few minutes. Regards, Joe
Sync--ScrShot4.pdf
> This is actually an image. No text selection is possible.
Our messages crossed — your statement above confirms my suspicion. I just converted your second image to a PDF searchable image file. It is attached. As with the first one, it contains both the image and the text created by OCR. I did a copy/paste from my PDF viewer into Word, and Word reports it as Courier 5.5-point. Regards, Joe
Sync--ScrShot1.pdf
Our messages crossed — your statement above confirms my suspicion. I just converted your second image to a PDF searchable image file. It is attached. As with the first one, it contains both the image and the text created by OCR. I did a copy/paste from my PDF viewer into Word, and Word reports it as Courier 5.5-point. Regards, Joe
Sync--ScrShot1.pdf
ASKER
It cannot be Courier. The Letters in Courier look different and have different SERIFS.
You are correct. The particular software I used to create the PDF searchable image file obviously created Courier text. It is clear that neither of those is Courier — my bad in my haste to respond. I have lots of OCR software. I'll try some other packages to see if any of them creates the actual font.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
ok. You are correct. It looks the same. Thanks.
Can you tell me the OCR package you used?
Can you tell me the OCR package you used?
ABBYY FineReader Professional:
http://finereader.abbyy.com/professional/
I used version 11, but the current version is 12. I haven't upgraded to 12 because this is a secondary OCR tool for me, although in this case it did a better job than my primary OCR. But that's why I have several different OCR packages — results vary by document. Regards, Joe
http://finereader.abbyy.com/professional/
I used version 11, but the current version is 12. I haven't upgraded to 12 because this is a secondary OCR tool for me, although in this case it did a better job than my primary OCR. But that's why I have several different OCR packages — results vary by document. Regards, Joe
ASKER
Thank you Joe. This is a paid tool. Do you know of any free tools for this kind in functionality?
I know many free OCR tools. What I don't know is how well they will do in creating a file with the correct font. You would have to try all of them to see if any work. Keep in mind that two expensive packages did not do well, while the third one did. With that caveat, here are some free OCR tools that you can experiment with:
(1) Tesseract OCR Engine, an open source product now maintained by Google:
http://code.google.com/p/tesseract-ocr/
It has numerous add-ons:
http://code.google.com/p/tesseract-ocr/wiki/AddOns
(2) FreeOCR, which uses a compiled version of the Tesseract engine:
http://www.paperfile.net/
(3) GOCR/JOCR, an open source OCR package developed under the GNU Public License:
http://jocr.sourceforge.net/
(4) OCR Desktop, which is not open source, but is free for personal use (needs to be registered in order to turn off popups and advertising):
http://www.ocrtools.com/fi/prdOCRFree.aspx
(5) SimpleOCR, which is not open source, but is free, with both an end-user version:
http://www.simpleocr.com/
and a royalty-free SDK:
http://www.simpleocr.com/Info.asp#SDK
(6) Boxoft Free OCR (I use several Boxoft free tools):
http://www.boxoft.com/free-ocr/
(7) Google Drive/Docs has an option to perform OCR on uploaded files, but the last time I tried it (a while ago, so it might be better now), the resulting PDF did not hide the text layer, so the file looked ugly.
One other caveat. While today's OCR is very accurate, it is not 100%. There are always issues like the number "0" and the upper case letter "O"; the number "1" and the lower case letter "l"; and words like "modern", where the "r" and the "n" can be nearly touching in a proportional font, thereby causing the OCR to think it's "modem". Regards, Joe
(1) Tesseract OCR Engine, an open source product now maintained by Google:
http://code.google.com/p/tesseract-ocr/
It has numerous add-ons:
http://code.google.com/p/tesseract-ocr/wiki/AddOns
(2) FreeOCR, which uses a compiled version of the Tesseract engine:
http://www.paperfile.net/
(3) GOCR/JOCR, an open source OCR package developed under the GNU Public License:
http://jocr.sourceforge.net/
(4) OCR Desktop, which is not open source, but is free for personal use (needs to be registered in order to turn off popups and advertising):
http://www.ocrtools.com/fi/prdOCRFree.aspx
(5) SimpleOCR, which is not open source, but is free, with both an end-user version:
http://www.simpleocr.com/
and a royalty-free SDK:
http://www.simpleocr.com/Info.asp#SDK
(6) Boxoft Free OCR (I use several Boxoft free tools):
http://www.boxoft.com/free-ocr/
(7) Google Drive/Docs has an option to perform OCR on uploaded files, but the last time I tried it (a while ago, so it might be better now), the resulting PDF did not hide the text layer, so the file looked ugly.
One other caveat. While today's OCR is very accurate, it is not 100%. There are always issues like the number "0" and the upper case letter "O"; the number "1" and the lower case letter "l"; and words like "modern", where the "r" and the "n" can be nearly touching in a proportional font, thereby causing the OCR to think it's "modem". Regards, Joe
ASKER
Thanks Joe :-)
You're welcome. Good luck on the project! Regards, Joe
https://www.myfonts.com/WhatTheFont/