Port STP Change on Meraki MS320 Locking Up Entire Network
We have been troubleshooting an ongoing STP issue* (see bottom of post) for three weeks. It is causing disconnects across the network for phones, desktop and Citrix connections.
IMPACT (Who)
All LAN end users across the board are impacted. WAN users have no issue whatsoever.
SYMPTOMS (What)
- Jittery or dropped VoIP calls
- Disconnected Citrix sessions
- Network lag on physical desktops
- Coreswitch1 misses heartbeats so Coreswitch2 is taking over as VRRP master and then it flips back again
TIMELINE (When)
Every night, starting at about 2200 and lasting until about 1030. It may take place every 6 minutes like clockwork, or it will happen intermittently every half hour or every couple of hours. It may start around 2200 or as late as 0030 and the issue definitely stops at/around 1030 and doesn't start again until the evening.
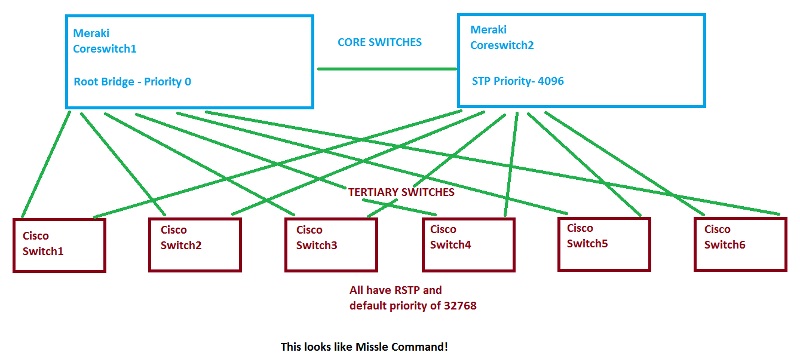
TOPOLOGY
Coreswitch1 is the STP root bridge
Coreswitch2 has 4096 priority
All tertiary swtiches have priority of 32768 with RSTP turned on
I drew this to simply explain the network layout in regards to STP
TROUBLESHOOTING
- Meraki event logs show these events (xlsx attached). Their logs don't have that much info in the way of details. It seems that whatever is causing the STP changes is making Coreswitch1 miss a heartbeat so Coreswitch2 is taking over as VRRP master and then flipping back. This is more of a symptom of the STP changes (I think)
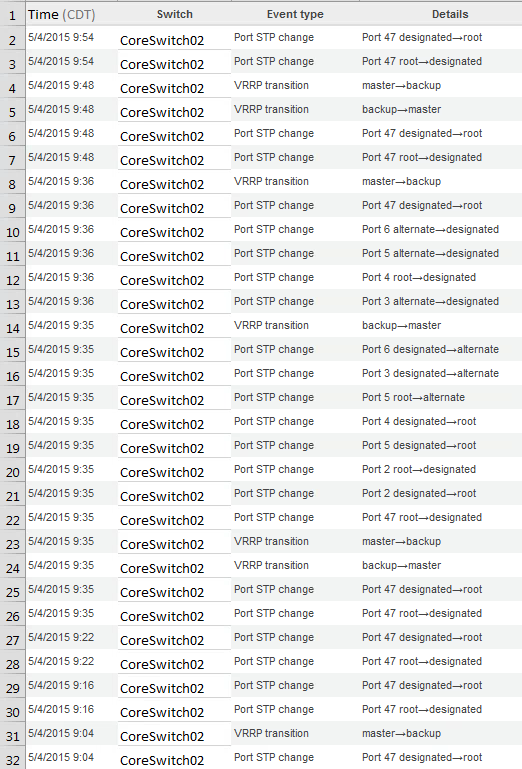
- From the Meraki switches - Turned on STP port guard on each port that the tertiary switches connect to. i.e.- Tertiaryswitch1 plugs into Coreswitch1 on port 1. I turned STP port guard on for all tertiary connections. After doing this, I still observed the "flipping" on Coreswitch2. This makes me think that the issue is on Coreswitch2 or a device connected to it, but not coming from the tertiary switches. Perhaps I incorrectly ran that test?
- Disconnected all other (known) network devices on the tertiary switches like access points, printers, etc. and still observed the issue.
- Ran a packet capture on the core switches immediately after the triggering event happened. Running it just a tad late, I got the STP changes but not the event that triggered them. I'll try to run another capture tonight and try to get it started just before the issue starts.
-Meraki support asked me to turn on portfast on all of the tertiary switches. I did that today and will wait until the event timeline starts again tonight to see if it helps.
I've been talking to Meraki support and they haven't been able to put their finger on the issue. I don't even know where to look. Is it coming from the tertiary switches, the ESXi hosts, a "rogue" device, etc.? Any help would be greatly appreciated
*Note: I am fairly certain this is an STP issue since that's what the logs point to, and that's what Meraki support says, but am certainly open to hearing if there is another issue causing the problem.
events.xlsx
IMPACT (Who)
All LAN end users across the board are impacted. WAN users have no issue whatsoever.
SYMPTOMS (What)
- Jittery or dropped VoIP calls
- Disconnected Citrix sessions
- Network lag on physical desktops
- Coreswitch1 misses heartbeats so Coreswitch2 is taking over as VRRP master and then it flips back again
TIMELINE (When)
Every night, starting at about 2200 and lasting until about 1030. It may take place every 6 minutes like clockwork, or it will happen intermittently every half hour or every couple of hours. It may start around 2200 or as late as 0030 and the issue definitely stops at/around 1030 and doesn't start again until the evening.
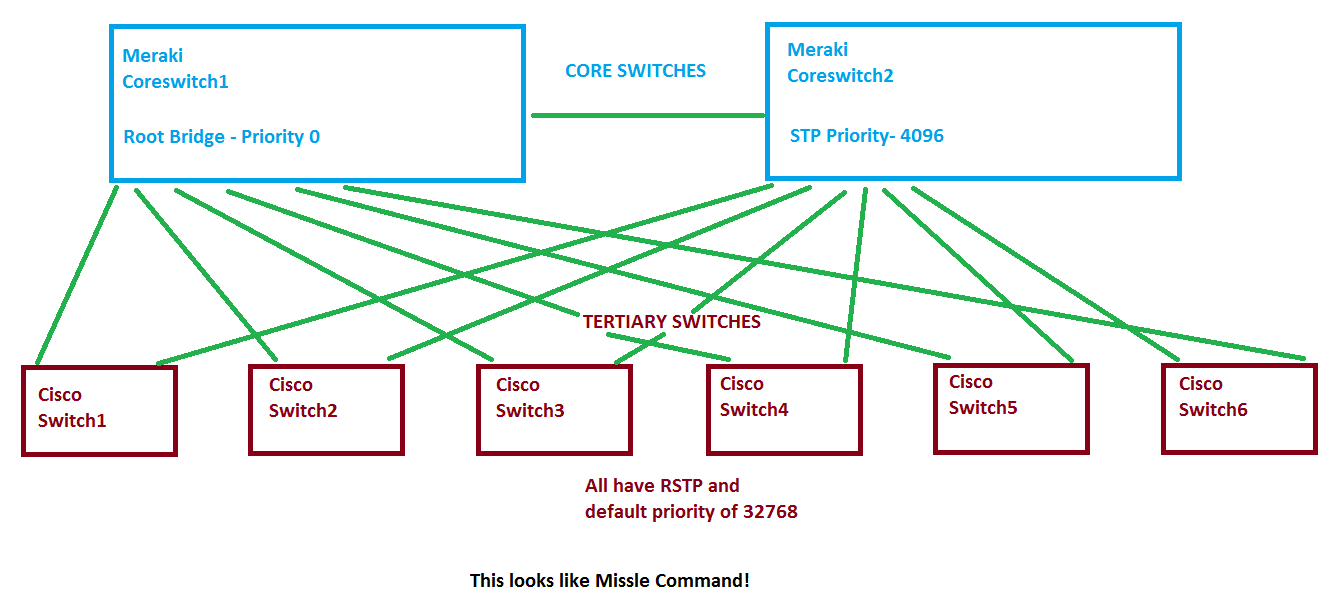
TOPOLOGY
Coreswitch1 is the STP root bridge
Coreswitch2 has 4096 priority
All tertiary swtiches have priority of 32768 with RSTP turned on
I drew this to simply explain the network layout in regards to STP
TROUBLESHOOTING
- Meraki event logs show these events (xlsx attached). Their logs don't have that much info in the way of details. It seems that whatever is causing the STP changes is making Coreswitch1 miss a heartbeat so Coreswitch2 is taking over as VRRP master and then flipping back. This is more of a symptom of the STP changes (I think)
- From the Meraki switches - Turned on STP port guard on each port that the tertiary switches connect to. i.e.- Tertiaryswitch1 plugs into Coreswitch1 on port 1. I turned STP port guard on for all tertiary connections. After doing this, I still observed the "flipping" on Coreswitch2. This makes me think that the issue is on Coreswitch2 or a device connected to it, but not coming from the tertiary switches. Perhaps I incorrectly ran that test?
- Disconnected all other (known) network devices on the tertiary switches like access points, printers, etc. and still observed the issue.
- Ran a packet capture on the core switches immediately after the triggering event happened. Running it just a tad late, I got the STP changes but not the event that triggered them. I'll try to run another capture tonight and try to get it started just before the issue starts.
-Meraki support asked me to turn on portfast on all of the tertiary switches. I did that today and will wait until the event timeline starts again tonight to see if it helps.
I've been talking to Meraki support and they haven't been able to put their finger on the issue. I don't even know where to look. Is it coming from the tertiary switches, the ESXi hosts, a "rogue" device, etc.? Any help would be greatly appreciated
*Note: I am fairly certain this is an STP issue since that's what the logs point to, and that's what Meraki support says, but am certainly open to hearing if there is another issue causing the problem.
events.xlsx
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Per your suggestions, I implemented these changes:
- Root guard enabled on all access ports on tertiary switches
- BPDU Guard enables on all access ports on tertiary switches
- Port Fast enabled on all access ports on tertiary switches
- Root guard enabled on all ports of core switches except for link on 47 and uplink
I do have a problem as a result. One of the tertiary switches can only have a single cable plugged into the core. If I plug in the redundant trunk cable, the network goes down. It seems that the Cisco switch thinks it is the root bridge and therefore has no Root or Alternate STP port. The ports are configured just like the rest of the tertiary switches. I opened a new question here: https://www.experts-exchange.com/questions/28669867/Switch-is-causing-network-outage.html
- Root guard enabled on all access ports on tertiary switches
- BPDU Guard enables on all access ports on tertiary switches
- Port Fast enabled on all access ports on tertiary switches
- Root guard enabled on all ports of core switches except for link on 47 and uplink
I do have a problem as a result. One of the tertiary switches can only have a single cable plugged into the core. If I plug in the redundant trunk cable, the network goes down. It seems that the Cisco switch thinks it is the root bridge and therefore has no Root or Alternate STP port. The ports are configured just like the rest of the tertiary switches. I opened a new question here: https://www.experts-exchange.com/questions/28669867/Switch-is-causing-network-outage.html
ASKER
Great info!
Yes, port 47 connects between each core switch
Yes, ports 1-6 on core switches are tertiary connections
My tertiary switches are SGE2010's and SG500x's.
A few questions to clarify:
1 - Can I have root guard turned on for the ports connecting printers, copiers and access points?
2 - The GUI port options are below for each switch. I can telnet into the SGE2010s but they only have a menu selection option. The SG500x's have a traditional Cisco ios prompt via SSH.
So, you're saying to enable root guard on every access port on the tertiary switches?
1 - What about the ports on the core switches that connect ESXi hosts, edge SIP devices, WAN/firewall uplink, etc.?
2 - I had turned root guard on in the core switches to the tertiary switch ports but still saw the problem. Does that mean the issue is coming from another device on the core switches other than the tertiary devices?
1 - Turn PortFast on in every access port on the tertiary switches?