I think I need dynamic table names but want to avoid dynamic SQL?
In my scenario, each user can rapidly generate search result hits, about 1 million records per user. Each record is made up of a SetID and a ResultID, setID being tinyint, ResultID being int.
The records are generated by calling a stored procedure, each call using a new setID.
The most cost is observed during insertion and deletion. I found in the end having no indexes at all gives the best performance for what I am doing. Each user activity generates about 100k records and the delete handles about the same amount.
Initially I had a userID on the row as well but found the insert/deletions were far more time consuming the larger the table became. Since there is no scope to ever need to query across Users on this table, one of the ways I found I got better performance was to remove the UserID and create the table dynamically with the UserID forming part of the table name.
However this has led to me using a lot of dynamic SQL to reference the correct tables.
It is not possible to drop the tables and recreate them to avoid deletions altogether since I only ever delete 1 set of data at a time.
Equally temporary tables have offered little advantage since a users search results need to be preserved between stored procedures.
Are there any subject areas worthy of my study to either a) allow me to avoid dynamic SQL but retain my seperate table per user concept or b) which may steer me towards something where performance is likely to be less affected by a heavily populated table with 100k inserts and deletes than some of these past experiences have suggested.
Thanks in advance!
The records are generated by calling a stored procedure, each call using a new setID.
The most cost is observed during insertion and deletion. I found in the end having no indexes at all gives the best performance for what I am doing. Each user activity generates about 100k records and the delete handles about the same amount.
Initially I had a userID on the row as well but found the insert/deletions were far more time consuming the larger the table became. Since there is no scope to ever need to query across Users on this table, one of the ways I found I got better performance was to remove the UserID and create the table dynamically with the UserID forming part of the table name.
However this has led to me using a lot of dynamic SQL to reference the correct tables.
It is not possible to drop the tables and recreate them to avoid deletions altogether since I only ever delete 1 set of data at a time.
Equally temporary tables have offered little advantage since a users search results need to be preserved between stored procedures.
Are there any subject areas worthy of my study to either a) allow me to avoid dynamic SQL but retain my seperate table per user concept or b) which may steer me towards something where performance is likely to be less affected by a heavily populated table with 100k inserts and deletes than some of these past experiences have suggested.
Thanks in advance!
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
dsacker
Can you add a field that logically separates each user concept? Perhaps a UserConcept (or similar) field. Make that part of a composite key?
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Thank you so much guys for your feedback. I will go over each of your posts.
Jim :
Thank you for providing a conclusive answer to my question about dynamic SQL being unavoidable with dynamically named tables.
I apologize if it wasn't as clear as it could have been, it is a hard one to convey. I have attached a screenshot of the end solution to help illustrate the end goal.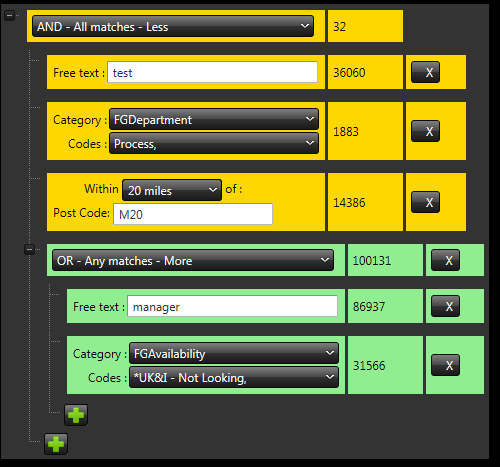 I have a tree that is designed by the user. Each node is a question upon the database, with the parent nodes being logical operators AND/OR/NOT AND/NOT OR of the child nodes.
I have a tree that is designed by the user. Each node is a question upon the database, with the parent nodes being logical operators AND/OR/NOT AND/NOT OR of the child nodes.
It allows unlimited depth. By storing a set of matches for each node I can calculate the parent nodes without having to research upon all the child nodes. Only the updated/new node is worked, the operator node and its parents merely join upon the results. My end solution also displays counts of hits at each and every level capture all the criteria whilst collecting this information is not very easy to do.
Therefore if one node is added with 80k hits, I have to store those hits. It may seem excessive, but it is certainly faster to manage the parent nodes than re-calculating the combination of its children and breaks up the workload softening the user experience.
As for this being home work, well I am working at home alot on this but no there is an actual business requirement for this :). My question merely admits there are massive gaps in my knowledge as to how you attack a problem like this and I have been stuck on SQL 2000 until very recently and like all good generals I don't expect to fight my wars the same ways I fought the last ones! I hope you can take some insight from my problem too.
Dsacker : I originally did use a user column as you and Scott suggest, but I tested the performance with an auwful lot of simulated load and found that when it came to the insertion and deletion which formed the largest part of the delay, keys added even more overhead, doubling the cost nearly. I tried removing/reapplying keys before deletion and after insertion but this didn't yield improvement.
Scott : You have exposed a glaring gap in my knowledge despite all my googling on avoiding logging I have never seen TempDB mentioned anywhere and whilst it is on the same disk system as the rest in my evironment, if it carries less logging weight this is a avenue I have not explored and am keen to try. Thank you!
Jim :
Thank you for providing a conclusive answer to my question about dynamic SQL being unavoidable with dynamically named tables.
I apologize if it wasn't as clear as it could have been, it is a hard one to convey. I have attached a screenshot of the end solution to help illustrate the end goal.
I have a tree that is designed by the user. Each node is a question upon the database, with the parent nodes being logical operators AND/OR/NOT AND/NOT OR of the child nodes.It allows unlimited depth. By storing a set of matches for each node I can calculate the parent nodes without having to research upon all the child nodes. Only the updated/new node is worked, the operator node and its parents merely join upon the results. My end solution also displays counts of hits at each and every level capture all the criteria whilst collecting this information is not very easy to do.
Therefore if one node is added with 80k hits, I have to store those hits. It may seem excessive, but it is certainly faster to manage the parent nodes than re-calculating the combination of its children and breaks up the workload softening the user experience.
As for this being home work, well I am working at home alot on this but no there is an actual business requirement for this :). My question merely admits there are massive gaps in my knowledge as to how you attack a problem like this and I have been stuck on SQL 2000 until very recently and like all good generals I don't expect to fight my wars the same ways I fought the last ones! I hope you can take some insight from my problem too.
Dsacker : I originally did use a user column as you and Scott suggest, but I tested the performance with an auwful lot of simulated load and found that when it came to the insertion and deletion which formed the largest part of the delay, keys added even more overhead, doubling the cost nearly. I tried removing/reapplying keys before deletion and after insertion but this didn't yield improvement.
Scott : You have exposed a glaring gap in my knowledge despite all my googling on avoiding logging I have never seen TempDB mentioned anywhere and whilst it is on the same disk system as the rest in my evironment, if it carries less logging weight this is a avenue I have not explored and am keen to try. Thank you!
I thought the user column might yield that weakness while I was suggesting it. Did you compute statistics at any key points?
ASKER
I did do user the execution timer and test different scenarios for their timing.
I put a lot of effort into trying to avoid separate tables but got worse performance.
I've gone with the Node/Hit tables in the end.
I put a lot of effort into trying to avoid separate tables but got worse performance.
I've gone with the Node/Hit tables in the end.
ASKER
I've requested that this question be closed as follows:
Accepted answer: 0 points for dgloveruk's comment #a40865248
for the following reason:
More or less concluded that the approach in use was about as good as could be expected.
Accepted answer: 0 points for dgloveruk's comment #a40865248
for the following reason:
More or less concluded that the approach in use was about as good as could be expected.
I believe the experts provided very useful, knowledgeable information, even if the OP decided to stay with her current approach.