Oracle 11g Table A Column Select based on Table B Rows
Hello Experts-
I am trying to combine two tables together to return 1 final result set.
My 1st Table labeled as Table A gives a Data Field Layout with its name:

My 2nd Table labeled as Table B gives a full field Layout per unique record:

What I would like to do is to take the Column "REPORTING_DATA_FIELDS" from Table A and only pull the associated Columns in Table B and replace the Column Labels in Table B with the "DATA_FIELD_NAME" from Table A.
The final result set would look like Table C:

Table A contains a different amount of data fields per PROJECT_NAME but the count can be selected to figure out how many columns would be needed.
Any help would be much appreciated!
Thanks-
Luke
I am trying to combine two tables together to return 1 final result set.
My 1st Table labeled as Table A gives a Data Field Layout with its name:

My 2nd Table labeled as Table B gives a full field Layout per unique record:

What I would like to do is to take the Column "REPORTING_DATA_FIELDS" from Table A and only pull the associated Columns in Table B and replace the Column Labels in Table B with the "DATA_FIELD_NAME" from Table A.
The final result set would look like Table C:
Table A contains a different amount of data fields per PROJECT_NAME but the count can be selected to figure out how many columns would be needed.
Any help would be much appreciated!
Thanks-
Luke
To supply a resolved name for each column requires "dynamic sql"
(a query that builds another query, then that built query gets executed)
What is the final "presentation layer"? (e.g. html, xml, csv file)
--------
notes.
While the images a great for describing your question, data in a reusable text form would enable us t0 build sample queries. Hen's teeth are more common than data that we type out from images.
Similarly, in my experience using the actual table names helps everyone in the end.
(a query that builds another query, then that built query gets executed)
What is the final "presentation layer"? (e.g. html, xml, csv file)
--------
notes.
While the images a great for describing your question, data in a reusable text form would enable us t0 build sample queries. Hen's teeth are more common than data that we type out from images.
Similarly, in my experience using the actual table names helps everyone in the end.
ASKER
Hi Mike and Paul-
Thanks for looking into this for me. Mike, I was trying to use the Pivot function as the Unpivot function puts Table B into row format and I'm looking more for Pivoting Table A and putting it into Column Format.
Paul, I was also looking at possibly using "WITH" and do a cross join but the pivoting was tripping me up.
Table A is SYK_PROJECT_DATA_FIELDS_MV
GROUP_CATEGORY PROJECT_NAME DATA_FIELD_ID REPORTING_DATA_FIELDS DATA_FIELD_NAME
Full Permission Action 0 DF_0 Title
Full Permission Action 1 DF_1 Originator
Full Permission Action 100 DF_100 Responsible Manager
Full Permission Action 105 DF_105 CAPA Specialist
Full Permission Action 128 DF_128 DF_128
Full Permission Action 1354 DF_1354 ERP Source Site Search
Full Permission Action 1355 DF_1355 ERP Source ID Search
Full Permission Action 14 DF_14 Parent ID
Full Permission Action 147 DF_147 Attachment-Miscellaneous
Full Permission Action 148 DF_148 Reference-Miscellaneous
Table B is RDS_PR_1 with the following first few rows and columns (as there is approximately 2000 columns) of data (The last few columns of data are blank as the corresponding data fields do not line up with the Action Project):
ID PROJECT_ID DATE_CREATED DF_3 DATE_CLOSED DATE_UPDATED RDS_DATE_UPDATED STATUS_TYPE DF_0 DF_4 DF_5 DF_9 DF_10 DF_11 DF_12 DF_14 DF_16 DF_17
1030 Action 8/6/2012 7:12:14 AM 8/6/2012 7:12:00 AM 12/5/2013 9:25:38 PM 12/5/2013 9:30:05 PM 4/27/2015 2:15:35 PM 30 Test1
1077 Action 8/16/2012 12:17:31 PM 8/16/2012 12:17:00 PM 7/3/2013 2:14:44 PM 7/3/2013 2:15:18 PM 4/27/2015 2:15:35 PM 30 Test2
1092 Action 8/22/2012 4:07:09 PM 8/22/2012 4:07:00 PM 12/5/2013 9:25:48 PM 12/5/2013 9:30:08 PM 4/27/2015 2:15:35 PM 30 Test3
1071 Action 8/15/2012 7:48:57 PM 8/15/2012 7:48:00 PM 12/5/2013 9:25:42 PM 12/5/2013 9:30:07 PM 4/27/2015 2:15:35 PM 30 Test4
1120 Action 8/28/2012 2:14:47 PM 8/28/2012 1:57:00 PM 8/8/2013 9:17:00 AM 8/8/2013 9:35:05 AM 4/27/2015 2:15:35 PM 30 Test5
1150 Action 8/30/2012 8:28:30 AM 12/21/2011 5:00:00 AM 10/14/2013 6:59:30 PM 10/14/2013 7:00:28 PM 4/27/2015 2:15:35 PM 30 Test6
1188 Action 8/31/2012 11:42:37 AM 8/31/2012 11:42:00 AM 7/3/2013 2:15:51 PM 7/3/2013 2:20:48 PM 4/27/2015 2:15:35 PM 30 Test7
1703 Action 10/26/2012 10:12:42 AM 10/26/2012 10:12:00 AM 7/3/2013 2:20:53 PM 7/3/2013 2:25:28 PM 4/27/2015 2:15:35 PM 30 Test8
1708 Action 10/29/2012 9:14:07 AM 10/29/2012 9:14:00 AM 7/3/2013 2:20:56 PM 7/3/2013 2:25:28 PM 4/27/2015 2:15:35 PM 30 Test9
Thanks-
Luke
Thanks for looking into this for me. Mike, I was trying to use the Pivot function as the Unpivot function puts Table B into row format and I'm looking more for Pivoting Table A and putting it into Column Format.
Paul, I was also looking at possibly using "WITH" and do a cross join but the pivoting was tripping me up.
Table A is SYK_PROJECT_DATA_FIELDS_MV
GROUP_CATEGORY PROJECT_NAME DATA_FIELD_ID REPORTING_DATA_FIELDS DATA_FIELD_NAME
Full Permission Action 0 DF_0 Title
Full Permission Action 1 DF_1 Originator
Full Permission Action 100 DF_100 Responsible Manager
Full Permission Action 105 DF_105 CAPA Specialist
Full Permission Action 128 DF_128 DF_128
Full Permission Action 1354 DF_1354 ERP Source Site Search
Full Permission Action 1355 DF_1355 ERP Source ID Search
Full Permission Action 14 DF_14 Parent ID
Full Permission Action 147 DF_147 Attachment-Miscellaneous
Full Permission Action 148 DF_148 Reference-Miscellaneous
Table B is RDS_PR_1 with the following first few rows and columns (as there is approximately 2000 columns) of data (The last few columns of data are blank as the corresponding data fields do not line up with the Action Project):
ID PROJECT_ID DATE_CREATED DF_3 DATE_CLOSED DATE_UPDATED RDS_DATE_UPDATED STATUS_TYPE DF_0 DF_4 DF_5 DF_9 DF_10 DF_11 DF_12 DF_14 DF_16 DF_17
1030 Action 8/6/2012 7:12:14 AM 8/6/2012 7:12:00 AM 12/5/2013 9:25:38 PM 12/5/2013 9:30:05 PM 4/27/2015 2:15:35 PM 30 Test1
1077 Action 8/16/2012 12:17:31 PM 8/16/2012 12:17:00 PM 7/3/2013 2:14:44 PM 7/3/2013 2:15:18 PM 4/27/2015 2:15:35 PM 30 Test2
1092 Action 8/22/2012 4:07:09 PM 8/22/2012 4:07:00 PM 12/5/2013 9:25:48 PM 12/5/2013 9:30:08 PM 4/27/2015 2:15:35 PM 30 Test3
1071 Action 8/15/2012 7:48:57 PM 8/15/2012 7:48:00 PM 12/5/2013 9:25:42 PM 12/5/2013 9:30:07 PM 4/27/2015 2:15:35 PM 30 Test4
1120 Action 8/28/2012 2:14:47 PM 8/28/2012 1:57:00 PM 8/8/2013 9:17:00 AM 8/8/2013 9:35:05 AM 4/27/2015 2:15:35 PM 30 Test5
1150 Action 8/30/2012 8:28:30 AM 12/21/2011 5:00:00 AM 10/14/2013 6:59:30 PM 10/14/2013 7:00:28 PM 4/27/2015 2:15:35 PM 30 Test6
1188 Action 8/31/2012 11:42:37 AM 8/31/2012 11:42:00 AM 7/3/2013 2:15:51 PM 7/3/2013 2:20:48 PM 4/27/2015 2:15:35 PM 30 Test7
1703 Action 10/26/2012 10:12:42 AM 10/26/2012 10:12:00 AM 7/3/2013 2:20:53 PM 7/3/2013 2:25:28 PM 4/27/2015 2:15:35 PM 30 Test8
1708 Action 10/29/2012 9:14:07 AM 10/29/2012 9:14:00 AM 7/3/2013 2:20:56 PM 7/3/2013 2:25:28 PM 4/27/2015 2:15:35 PM 30 Test9
Thanks-
Luke
ASKER
Hi Paul-
I forgot to answer your first question as well. The final Presentation layer for the "Dynamic" SQL is essentially Table SYK_PROJECT_DATA_FIELDS_MV
Thanks-
Luke
I forgot to answer your first question as well. The final Presentation layer for the "Dynamic" SQL is essentially Table SYK_PROJECT_DATA_FIELDS_MV
Thanks-
Luke
This procedure should produce the sql to get what you want - Note, with 2,000+ columns, you very well may exceed the varchar2 size limit.
declare
v_sql varchar2(32767);
v_columns varchar2(32767);
begin
for c in
(select UPPER(a.reporting_data_fie
from tablea a, user_tab_columns u
where UPPER(a.reporting_data_fie
and u.table_name = 'TABLEB')
loop
v_columns := v_columns||','||c.rdf||' as '||c.dfn;
dbms_output.put_line(v_col
end loop;
v_sql := 'select id,project_name'||v_column
dbms_output.put_line(v_sql
end;
/
declare
v_sql varchar2(32767);
v_columns varchar2(32767);
begin
for c in
(select UPPER(a.reporting_data_fie
from tablea a, user_tab_columns u
where UPPER(a.reporting_data_fie
and u.table_name = 'TABLEB')
loop
v_columns := v_columns||','||c.rdf||' as '||c.dfn;
dbms_output.put_line(v_col
end loop;
v_sql := 'select id,project_name'||v_column
dbms_output.put_line(v_sql
end;
/
ASKER
Hi awking-
Yes you are correct, it did start to produce the sql that would be needed but ran into a buffer overflow error:
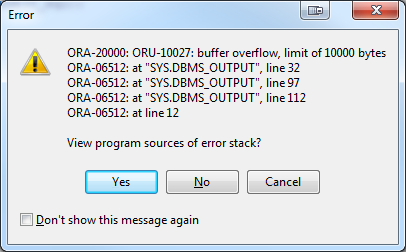
That is where I was thinking, would it be possible to feed the values directly from the table into the "WITH" statement.
Thanks-
Luke
Yes you are correct, it did start to produce the sql that would be needed but ran into a buffer overflow error:
That is where I was thinking, would it be possible to feed the values directly from the table into the "WITH" statement.
Thanks-
Luke
The error that you are posting is a buffer limit of DBMS_OUTPUT. You should be able to get around that with this call:
DBMS_OUTPUT.ENABLE(null);
If you are using SQL*Plus (or a tool that takes the same commands), you can accomplish the same thing with:
set serveroutput on size 1000000
That will get you past the limitation of DBMS_OUTPUT buffer, but not out of the limitation of the PL/SQL buffer (32767).
DBMS_OUTPUT.ENABLE(null);
If you are using SQL*Plus (or a tool that takes the same commands), you can accomplish the same thing with:
set serveroutput on size 1000000
That will get you past the limitation of DBMS_OUTPUT buffer, but not out of the limitation of the PL/SQL buffer (32767).
It appears that it was not the varchar2 size but the dbms_output function exceeded its size. It looks like your size was set to 10000. Try entering set serveroutput on size 1000000. plus I would also eliminate the printing of v_columns entirely since it was just there for testing purposes. You may still run into an issue with so many columns.
ASKER
Thank you both. I am still running into an overstack flow error so I'm thinking I might go back to the way Mike originally said and do the unpivot to make everything into rows instead of columns. If I unpivot, will that allow multiple rows per ID if I do the group by ID?
Try the unpivot:
code.
SELECT *
FROM Table_B
UNPIVOT
(Rdf_Date
FOR Rdf
IN (Df_0, Df_1, Df_14, Df_100, Df_105, Df_128, Df_147, Df_148, Df_1354, Df_1355)))code.
ASKER
Hi Mike-
Sure, here is a sample of the tables with the final result set in a table once the command would be complete.
CREATE TABLE XTR_TABLE_A (DATA_FIELD_ID NUMBER, REPORTING_DATA_FIELDS VARCHAR(30), DATA_FIELD_NAME VARCHAR(30));
INSERT INTO XTR_TABLE_A VALUES (0,'DF_0','Title');
INSERT INTO XTR_TABLE_A VALUES (2,'DF_2','Description');
INSERT INTO XTR_TABLE_A VALUES (4,'DF_4','Hobby');
select * from xtr_table_a
CREATE TABLE XTR_TABLE_B (PR_ID NUMBER, PROJECT VARCHAR(30), DF_0 VARCHAR(30), DF_1 VARCHAR(30), DF_2 VARCHAR(30), DF_3 VARCHAR(30), DF_4 VARCHAR(30));
INSERT INTO XTR_TABLE_B VALUES(1001,'Action','Lawn
INSERT INTO XTR_TABLE_B VALUES(1002,'Action','Oil'
INSERT INTO XTR_TABLE_B VALUES(1003,'Action','Gas'
INSERT INTO XTR_TABLE_B VALUES(1004,'Action','Tire
INSERT INTO XTR_TABLE_B VALUES(1005,'Action','Glue
select * from xtr_table_b
CREATE TABLE XTR_TABLE_C_FINAL_RESULT (PR_ID NUMBER, PROJECT VARCHAR(30), Title VARCHAR(30), Description VARCHAR(30), Hobby VARCHAR(30));
INSERT INTO XTR_TABLE_C_FINAL_RESULT VALUES(1001,'Action','Lawn
INSERT INTO XTR_TABLE_C_FINAL_RESULT VALUES(1002,'Action','Oil'
INSERT INTO XTR_TABLE_C_FINAL_RESULT VALUES(1003,'Action','Gas'
INSERT INTO XTR_TABLE_C_FINAL_RESULT VALUES(1004,'Action','Tire
INSERT INTO XTR_TABLE_C_FINAL_RESULT VALUES(1005,'Action','Glue
select * from xtr_table_c_final_result
Table A contains the List of Fields. Table B contains the columns that should align with the list of fields from Table A. Table C would be how the final result set would look. 2 columns would get removed because they don't exist in Table A and the Data Field Names in Table A are now the column headers to Table B.
Thanks-
Luke
Sure, here is a sample of the tables with the final result set in a table once the command would be complete.
CREATE TABLE XTR_TABLE_A (DATA_FIELD_ID NUMBER, REPORTING_DATA_FIELDS VARCHAR(30), DATA_FIELD_NAME VARCHAR(30));
INSERT INTO XTR_TABLE_A VALUES (0,'DF_0','Title');
INSERT INTO XTR_TABLE_A VALUES (2,'DF_2','Description');
INSERT INTO XTR_TABLE_A VALUES (4,'DF_4','Hobby');
select * from xtr_table_a
CREATE TABLE XTR_TABLE_B (PR_ID NUMBER, PROJECT VARCHAR(30), DF_0 VARCHAR(30), DF_1 VARCHAR(30), DF_2 VARCHAR(30), DF_3 VARCHAR(30), DF_4 VARCHAR(30));
INSERT INTO XTR_TABLE_B VALUES(1001,'Action','Lawn
INSERT INTO XTR_TABLE_B VALUES(1002,'Action','Oil'
INSERT INTO XTR_TABLE_B VALUES(1003,'Action','Gas'
INSERT INTO XTR_TABLE_B VALUES(1004,'Action','Tire
INSERT INTO XTR_TABLE_B VALUES(1005,'Action','Glue
select * from xtr_table_b
CREATE TABLE XTR_TABLE_C_FINAL_RESULT (PR_ID NUMBER, PROJECT VARCHAR(30), Title VARCHAR(30), Description VARCHAR(30), Hobby VARCHAR(30));
INSERT INTO XTR_TABLE_C_FINAL_RESULT VALUES(1001,'Action','Lawn
INSERT INTO XTR_TABLE_C_FINAL_RESULT VALUES(1002,'Action','Oil'
INSERT INTO XTR_TABLE_C_FINAL_RESULT VALUES(1003,'Action','Gas'
INSERT INTO XTR_TABLE_C_FINAL_RESULT VALUES(1004,'Action','Tire
INSERT INTO XTR_TABLE_C_FINAL_RESULT VALUES(1005,'Action','Glue
select * from xtr_table_c_final_result
Table A contains the List of Fields. Table B contains the columns that should align with the list of fields from Table A. Table C would be how the final result set would look. 2 columns would get removed because they don't exist in Table A and the Data Field Names in Table A are now the column headers to Table B.
Thanks-
Luke
Here is as far as I got with single query:
SELECT B.*, A.Data_Field_Name
FROM ( SELECT *
FROM Xtr_Table_B
UNPIVOT
(Rdf_Desc FOR Rdf IN (Df_0, Df_1, Df_2, Df_3, Df_4)) ) B
JOIN Xtr_Table_A A ON A.Reporting_Data_Fields = B.Rdf
ORDER BY B.Pr_Id, A.Data_Field_Id;ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Hi Paul-
Thank you for your response. I have taken what you did and advanced it into what I needed; however, I cannot get the execute immediate to work. I'm trying to feed the select into a cursor and execute that cursor which is failing, do I have the syntax wrong?
Thanks-
Luke
Thank you for your response. I have taken what you did and advanced it into what I needed; however, I cannot get the execute immediate to work. I'm trying to feed the select into a cursor and execute that cursor which is failing, do I have the syntax wrong?
DECLARE
CURSOR SYK_ACTION IS
select 'SELECT ' as dynaquery from dual
union all
select
' ' || comma || column_name || ' as ' || '"' || data_field_name || '"'
from (
select '' as comma, 'A.ID' as column_name, 'ID' as data_field_name from dual
union all
select ',', 'A.PROJECT_ID', 'PROJECT_ID' from dual
union all
select ',', 'A.DATE_CURRENT_STATE', 'DATE_CURRENT_STATE' from dual
union all
select
(CASE WHEN C.TABLE_NAME = 'RDS_PR_1' THEN ', A.'
WHEN C.TABLE_NAME = 'RDS_PR_2' THEN ', B.'
END)
, c.column_name, N.DATA_FIELD_NAME
from user_tab_columns c
inner join SYK_PROJECT_DATA_FIELDS_MV N on c.column_name = N.REPORTING_DATA_FIELDS
inner join PROJECT P on N.PROJECT_NAME = P.NAME
where c.table_name IN ('RDS_PR_1','RDS_PR_2')
AND P.NAME = 'Action'
)
union all
select ' FROM RDS_PR_1 A, RDS_PR_2 B, PROJECT C' from dual
union all
select ' WHERE A.PROJECT_ID = C.ID' from dual
union all
select ' AND A.ID = B.ID' from dual
union all
select ' AND A.ID = 1001;' from dual
union all
select ' AND C.NAME = ' || '''Action''' || ';' from dual;
EXECUTE IMMEDIATE
SYK_ACTION;
END;Thanks-
Luke
I don't believe you can pass a cursor to execute immediate but may be wrong the PL side of PL/SQL isn't one of my strengths. You need to get query into a single string I think.
by the way, you should use more modern join syntax. What you are using is ancient., and it will be easier too because the join logic is self contained and not spread into the where clause.
by the way, you should use more modern join syntax. What you are using is ancient., and it will be easier too because the join logic is self contained and not spread into the where clause.
select ' FROM RDS_PR_1 A' from dual
union all
select ' INNER JOIN RDS_PR_2 B ON A.ID = B.ID' from dual
union all
select ' INNER JOIN PROJECT C ON A.PROJECT_ID = C.ID' from dual
union all
select ' WHERE A.ID = 1001;' from dual
I'll try to read this better tomorrow when I have time to try and get the requirements but Paul is correct. You cannot execute immediate a cursor.
If you need dynamic SQL using a generated string, what you can do is open a cursor using a string:
If you need dynamic SQL using a generated string, what you can do is open a cursor using a string:
declare
mycur sys_refcursor;
mydate date;
begin
open mycur for 'select sysdate from dual';
fetch mycur into mydate;
dbms_output.put_line('Got: ' || mydate);
close mycur;
end;
/
>>The final Presentation layer for the "Dynamic" SQL is essentially Table SYK_PROJECT_DATA_FIELDS_MV
Are you wanting to dynamically create a Materialized View based on the columns/data in the other tables?
If so, keep what you have and add the following before the SELECT in the generated SQL:
'create materialized view SYK_PROJECT_DATA_FIELDS_MV
Then execute immediate will work since the SQL string is a DDL statement.
If you are wanting something different, please clarify what I am missing.
Are you wanting to dynamically create a Materialized View based on the columns/data in the other tables?
If so, keep what you have and add the following before the SELECT in the generated SQL:
'create materialized view SYK_PROJECT_DATA_FIELDS_MV
Then execute immediate will work since the SQL string is a DDL statement.
If you are wanting something different, please clarify what I am missing.
ASKER
Hello both-
Paul helped me generate a dynamic sql code so it appears in the result set. Essentially I want that to immediately fire instead of being in a result set.
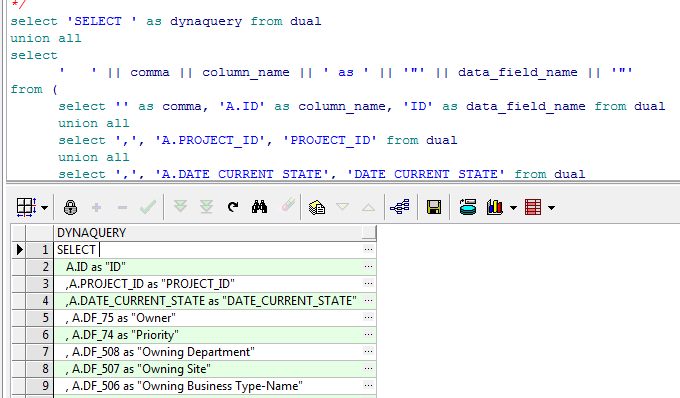
The DYNAQUERY is what I want to execute immediately.
Thanks-
Luke
Paul helped me generate a dynamic sql code so it appears in the result set. Essentially I want that to immediately fire instead of being in a result set.
The DYNAQUERY is what I want to execute immediately.
Thanks-
Luke
But, where do you want the results of that query to go? You cannot run a SELECT in a PL/SQL block without having the results go somewhere.
To me, the easiest is into a temporary table. Have your first select from DUAL be:
SELECT 'CREATE BOGUS_TABLE AS SELECT ' FROM DUAL
That can be used in an EXECUTE IMMEDIATE and a table called BOGUS_TABLE would be created. Then you can do with that whatever you want.
To me, the easiest is into a temporary table. Have your first select from DUAL be:
SELECT 'CREATE BOGUS_TABLE AS SELECT ' FROM DUAL
That can be used in an EXECUTE IMMEDIATE and a table called BOGUS_TABLE would be created. Then you can do with that whatever you want.
ASKER
Hi Johnsone-
The ideal solution would be to put it into a view since there is a lot of data that will always be changing. I was thinking a materialized view but I didn't want to because thousands of records change everyday.
The view would at least always run the SQL but the view needs to be based on the result set that is generated from the first SQL.
Does that make sense?
Thanks-
Luke
The ideal solution would be to put it into a view since there is a lot of data that will always be changing. I was thinking a materialized view but I didn't want to because thousands of records change everyday.
The view would at least always run the SQL but the view needs to be based on the result set that is generated from the first SQL.
Does that make sense?
Thanks-
Luke
>>Does that make sense?
Yes and no.
What is the end-game? We realize you want the execute the generated select.
Easy: use sqlplus, spool out the select to a file then execute that file:
Execute that using sqplplus and you will have the file myresults.txt that contains the output from your dynamically built SQL.
Something tells me that isn't good enough...
What tool/program/??? will be executing it?
What is the end destination for the results from the query?
The actual results need to be used/received by something?
Yes and no.
What is the end-game? We realize you want the execute the generated select.
Easy: use sqlplus, spool out the select to a file then execute that file:
set pages 0
set lines 1000000
set timing off
set trimspool on
set feedback off
spool myfile.sql
prompt set pages 0
prompt set lines 32767
prompt set timing off
prompt set trimspool on
prompt set feedback off
prompt spool myresults.txt
select 'select ''Hello World'' from dual;' from dual;
prompt spool off
spool off
@myfileExecute that using sqplplus and you will have the file myresults.txt that contains the output from your dynamically built SQL.
Something tells me that isn't good enough...
What tool/program/??? will be executing it?
What is the end destination for the results from the query?
The actual results need to be used/received by something?
A dynamic query like that and a materialized view (or even a regular view) don't make sense to me. Why do you need to create a dynamic table driven statement for a one time create? Makes no sense to me.
A materialized view (or regular view) would be created once. If you created the materialized view and the contents of the table changed how would the view get changed?
A materialized view (or regular view) would be created once. If you created the materialized view and the contents of the table changed how would the view get changed?
>>If you created the materialized view and the contents of the table changed
I think it is the contents of the 'layout' tables they are talking about. You add/remove a row to tableA and/or tableB and that would add/remove a column to the final result set.
Basically the other tables are storing the design of the result set.
I think it is the contents of the 'layout' tables they are talking about. You add/remove a row to tableA and/or tableB and that would add/remove a column to the final result set.
Basically the other tables are storing the design of the result set.
ASKER
Hi all-
I'm essentially constructing a per Project "PROJECT_NAME" view. All the projects are co-mingled in Table B "RDS_PR_1". What I'm trying to do is pull out the columns that are associated to each Project. That is where Table A "SYK_PROJECT_DATA_FIELDS_M
That means, if I pull the "Action" Project, it might only consist of 40 columns in Table B. By marrying Table A against Table B, I will know the columns that need to be pulled and then rename the column headings to the actual data field names.
That essentially brings me back to my first question of, is there a way to combine the two tables together to get the associated columns per project and rename the column headings.
I'm sorry for the run-around on this but you all have helped me out drastically thus far.
Thanks-
Luke
I'm essentially constructing a per Project "PROJECT_NAME" view. All the projects are co-mingled in Table B "RDS_PR_1". What I'm trying to do is pull out the columns that are associated to each Project. That is where Table A "SYK_PROJECT_DATA_FIELDS_M
That means, if I pull the "Action" Project, it might only consist of 40 columns in Table B. By marrying Table A against Table B, I will know the columns that need to be pulled and then rename the column headings to the actual data field names.
That essentially brings me back to my first question of, is there a way to combine the two tables together to get the associated columns per project and rename the column headings.
I'm sorry for the run-around on this but you all have helped me out drastically thus far.
Thanks-
Luke
>>"is there a way to combine the two tables together to get the associated columns per project and rename the column headings."
We have answered that:
No, not without some form of dynamic SQL.
You cannot have dynamic SQL and create some sort of dynamic view.
What you might be able to do is create triggers on tableA and tableB that when rows are inserted or updated, the views get recreated automatically.
I would be very concerned about this approach because you can break applications that use these views if the apps aren't coded correctly or if someone does a 'bad' insert or update which causes the views to become invalid.
Basically:
It is a bad idea to store pieces of objects in tables and have the objects built from tables. I would rethink your design...
We have answered that:
No, not without some form of dynamic SQL.
You cannot have dynamic SQL and create some sort of dynamic view.
What you might be able to do is create triggers on tableA and tableB that when rows are inserted or updated, the views get recreated automatically.
I would be very concerned about this approach because you can break applications that use these views if the apps aren't coded correctly or if someone does a 'bad' insert or update which causes the views to become invalid.
Basically:
It is a bad idea to store pieces of objects in tables and have the objects built from tables. I would rethink your design...
>>"That essentially brings me back to my first question of, is there a way to combine the two tables together to get the associated columns per project and rename the column headings."
That is inherent in the query I provided an it involves using the data dictionary (user_tab_columns).
Instead, the current weakness is not knowing what the generic columns are (e.g. id and project).
I think the debate morphed into a discussion on using materialized views.
Personally I don't see how these are appropriate given that the number of columns can change. Your requirements lead you to needing "dynamic sql" but I cannot see how it would lead to views let alone materialized views.
That is inherent in the query I provided an it involves using the data dictionary (user_tab_columns).
Instead, the current weakness is not knowing what the generic columns are (e.g. id and project).
I think the debate morphed into a discussion on using materialized views.
Personally I don't see how these are appropriate given that the number of columns can change. Your requirements lead you to needing "dynamic sql" but I cannot see how it would lead to views let alone materialized views.
ASKER
Hi all-
I agree. The terrible problem is all this stuff is vendor driven so I'm not allowed to touch how the database structure hence why I was trying to get that information into a Materialized View or View. I believe at this point in time there really isn't a way to get what I need on just one call. I'll probably write a procedure the statement that was created and constantly re-create the views once a week or something but this at least got me to the point where I can pull the columns appropriately for each Project. Thank you all for your help on this!
-Luke
I agree. The terrible problem is all this stuff is vendor driven so I'm not allowed to touch how the database structure hence why I was trying to get that information into a Materialized View or View. I believe at this point in time there really isn't a way to get what I need on just one call. I'll probably write a procedure the statement that was created and constantly re-create the views once a week or something but this at least got me to the point where I can pull the columns appropriately for each Project. Thank you all for your help on this!
-Luke
:p