isames
asked on
SQL Query Delete
I have a SQL job that runs every night at 10PM. It has three tasks. The first task runs a query against my Canada db populating a table called ToolsOnRent with Canada tools with a status of R.
The second task does the same thing for US.
The third task validates.
When the job ran on 8-11-15, it failed after the 1st task. So i re-ran the job after receiving the failure email. The job ran successfully.
However, when I got into the office this morning, i noticed that Canada rows were duplicated for any tools that has a Rent status on 8-11-15.
Below is a screenshot. I just chose a couple of the serial numbers i knew belong to tools that were rented by a Canadian store. The Canadian store numbers all begin with 07. The embedded screenshot also shows how the table is structured.
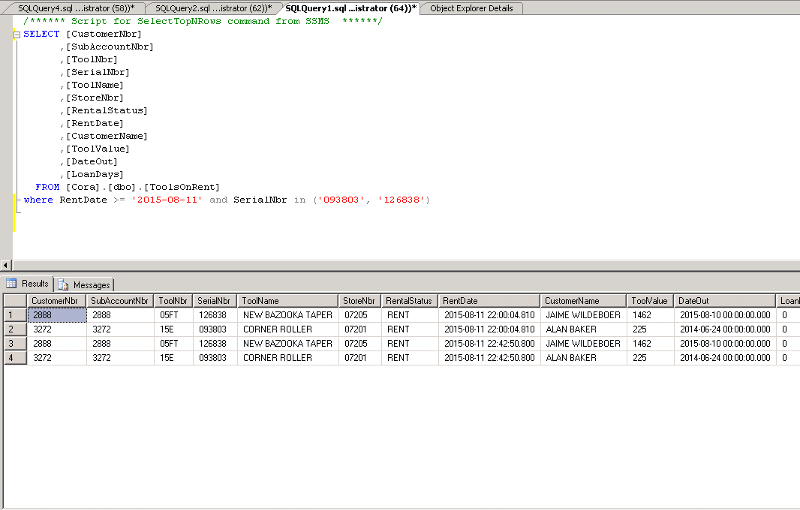
How do I delete all of the duplicated rows for just the Canadian stores that begin with 07 for 8-11-15?
The second task does the same thing for US.
The third task validates.
When the job ran on 8-11-15, it failed after the 1st task. So i re-ran the job after receiving the failure email. The job ran successfully.
However, when I got into the office this morning, i noticed that Canada rows were duplicated for any tools that has a Rent status on 8-11-15.
Below is a screenshot. I just chose a couple of the serial numbers i knew belong to tools that were rented by a Canadian store. The Canadian store numbers all begin with 07. The embedded screenshot also shows how the table is structured.

How do I delete all of the duplicated rows for just the Canadian stores that begin with 07 for 8-11-15?
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
And use an appropriate primary key and additional unique constraints..
Anyway, if you want to delete the duplicate rows, which one should be kept and which one should be deleted?