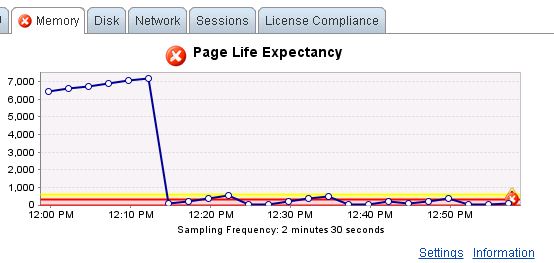
Page Life Expectancy sudden drop
It's ben a while now since we experience these sudden PLE drops on our production servers. Usually the value is normal, over 4K, but several times a day it suddenly drops and stays like that for minutes until grows back again. When these drops happen they are accompanied by spikes in the waiting time for that period of time and obviously by lag experience by users. The waiting time is caused by I/O high activity due to storage-memory transfer.
We know that we can rule out index missing or fragmentation, poor queries, we know how to deal with those problems. I understand that a high usage by our users at times can cause this but it doesn't seem to necessarily follow that pattern. It can happen while regular usage or even due to lunch period when normally there are less users active, or even at night.
One thing that we found on the net is that this may be a known SQL 2012 SP1 issue, which is supposed to be fixed by teh SP1 CU4 :
http://dba.stackexchange.com/questions/65280/sql-server-2012-page-life-expectancy-resets-to-0-after-about-50-days
only that in our case it happens multiple times a day. We already scheduled to apply the upgrade to SP2 but I thought I should ask here as well maybe someone can give us a light in this matter.
Thank you.
Some pictures here:
PLE drop:
Waiting time spike at 10min interval(sometimes the grow can be dramatic, to over 20K):
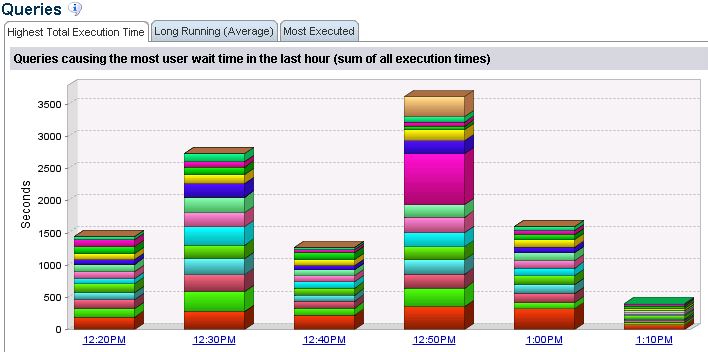 Waiting_spikes.JPG
Waiting_spikes.JPG
We know that we can rule out index missing or fragmentation, poor queries, we know how to deal with those problems. I understand that a high usage by our users at times can cause this but it doesn't seem to necessarily follow that pattern. It can happen while regular usage or even due to lunch period when normally there are less users active, or even at night.
One thing that we found on the net is that this may be a known SQL 2012 SP1 issue, which is supposed to be fixed by teh SP1 CU4 :
http://dba.stackexchange.com/questions/65280/sql-server-2012-page-life-expectancy-resets-to-0-after-about-50-days
only that in our case it happens multiple times a day. We already scheduled to apply the upgrade to SP2 but I thought I should ask here as well maybe someone can give us a light in this matter.
Thank you.
Some pictures here:
PLE drop:
Waiting time spike at 10min interval(sometimes the grow can be dramatic, to over 20K):
Waiting_spikes.JPG
ASKER
Thanks, Rich!
One thing I forgot to mention is that we have a Windows Fail Over Cluster configuration with with 2 SQL server nodes with AlwayOn. The 2 nodes are actually virtual machines on different hosts. We use VMWare for virtualization.
One thing I forgot to mention is that we have a Windows Fail Over Cluster configuration with with 2 SQL server nodes with AlwayOn. The 2 nodes are actually virtual machines on different hosts. We use VMWare for virtualization.
*nod* Those considerations add two more quick 'confirming assumptions':
I'm assuming a failover isn't occuring. (I assume not, 'cause that would produce lots of other red flags.)
I'm assuming the servers aren't getting into a ballon memory condition when the problem occurs. (That's easy enough to confirm in VCenter.)
I'm also assuming there aren't any messages in the SQL ERRORLOG when the cache is turned over?
I'm assuming a failover isn't occuring. (I assume not, 'cause that would produce lots of other red flags.)
I'm assuming the servers aren't getting into a ballon memory condition when the problem occurs. (That's easy enough to confirm in VCenter.)
I'm also assuming there aren't any messages in the SQL ERRORLOG when the cache is turned over?
ASKER
Your assumptions are correct. :)
ASKER
Actually there is something, messages that say:
"AppDomain 1637 (db_name.dbo[runtime].2034
They happen quite often.
The SQL nodes have 64GB of memory of which 55 alocated to SQL server.
"AppDomain 1637 (db_name.dbo[runtime].2034
They happen quite often.
The SQL nodes have 64GB of memory of which 55 alocated to SQL server.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
1. Check for queries which have high IO rather than long run times, after an occurrence. (I don't have particularly high hopes for that though... I wouldn't expect to drop to PLE of 0 though.)
2. You don't have any reindex or statistics jobs running during production times do you?
3. You don't have any developers or junior DBAs on your production system which would dump your cache to 'test something.'?
4. (I haven't admit though... we abandoned SP1 on SQL 2012 as quick as we could because of the registry bloat problem... so I can't say for certain if it's a flaw in the older service pack version...)