chcp 65001 File encoding
public class ChessCharsTester {
public static void main(String[] args) {
char[] ch = { '\u2654','\u2655','\u2656','\u2657','\u2658','\u2659','\u265A','\u265B','\u265C','\u265D','\u265E', '\u265F' };
System.out.println(String.valueOf(ch));
}
}There should be 12 chars involved above, yielding the 12 black and white chess pieces rendered by the DejaVu Sans Mono truetype font.
However when you run this code, the output is 36 tokens long . . . the first 12 are correct and welcome - the black and white pieces, but then there are many repetitions (mostly white pieces) plus 4 seemingly random question marks in between.
Has anyone heard of an explanation for this at all? Thanks, k.
gheist
You must use Character.ToString to cast to 1-byte character array to unicode string.
Not sure what any of that means. You do know that's Java and not .NET don't you?
You must use Character.ToString to cast to 1-byte character array to unicode string.
ASKER
Thanks gheist, but do you mean as this:
Here is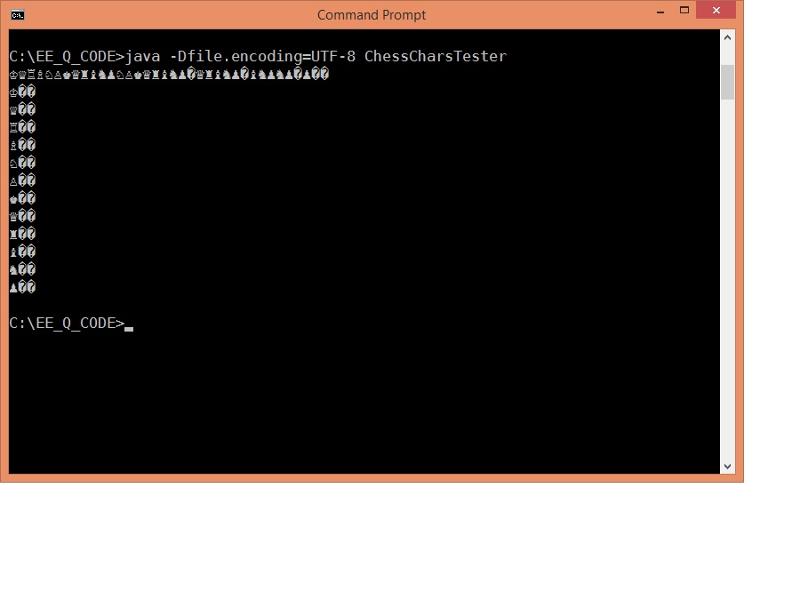 screenshot of the console output.
screenshot of the console output.
public class ChessCharsTester {
public static void main(String[] args) {
char[] ch = { '\u2654','\u2655','\u2656','\u2657','\u2658','\u2659','\u265A','\u265B','\u265C','\u265D','\u265E', '\u265F' };
System.out.println(String.valueOf(ch));
for(int a=0;a<ch.length;a++){
System.out.println(Character.toString(ch[a]));
}
}
}Here is
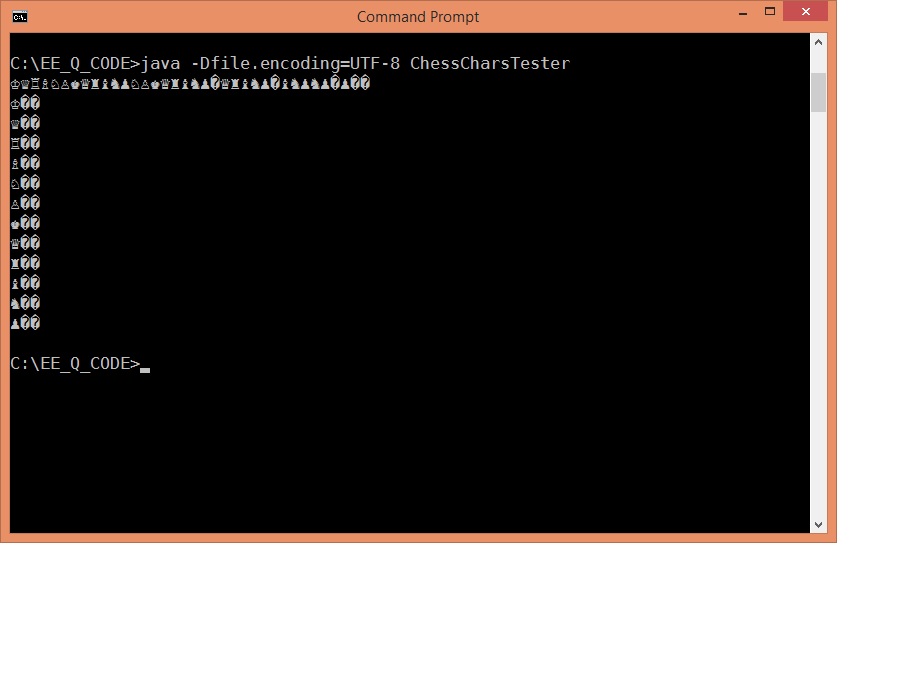 screenshot of the console output.
screenshot of the console output.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
It's almost as if . . .
Yes.
I've tried mixing up the assignment sequence of the chars to the array, for 'fun', and that makes no difference. When you take the length of the array, it's 12, and if you check loop counter 'a' after it's finished (make it static first of course), then that too is 12. Bizarre.
fwiw (and just to prove there's nothing wrong with the code)
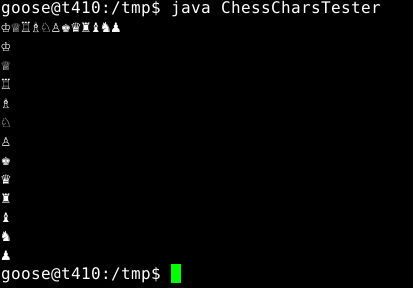
Use .NET shell or xterm or anything that supports unicode text output.
CMD.EXE does not support unicode (it does display question marks for backspaces)
CMD.EXE does not support unicode (it does display question marks for backspaces)
fyi my console screenshot above is Linux with my native UTF-8 locale
ASKER
CMD.EXE does not support unicode (it does display question marks for backspaces)
Well there is evidence the cmd.exe does support Unicode, because running this :
java -Dfile.encoding=UTF-8 ChessCharsTester >test.txt... you will obtain this from the test.txt file :
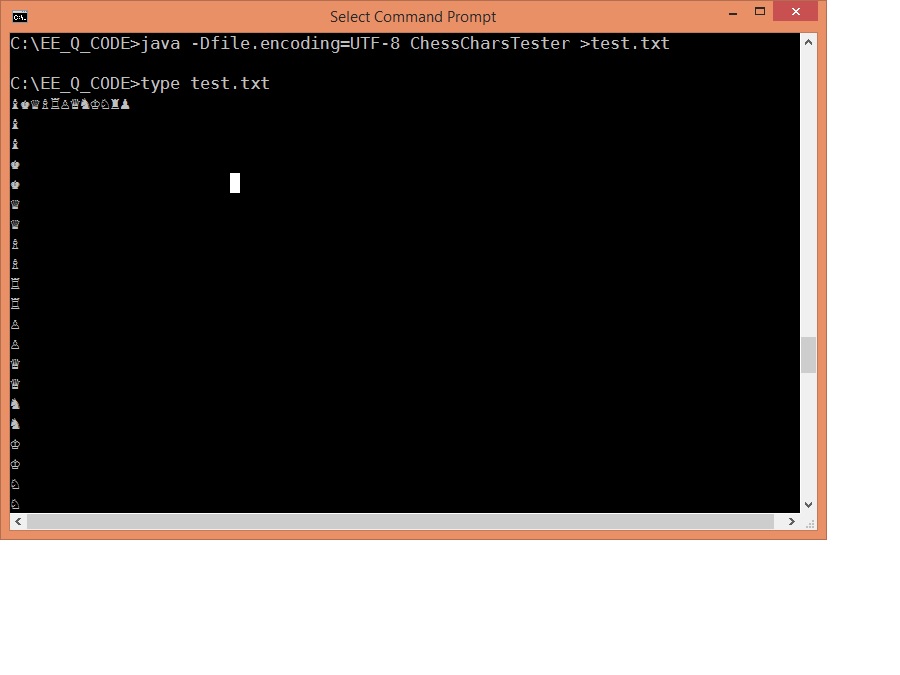
"It isn't clear why too many characters appear in the output. Maybe it is a JRE bug; maybe I'm just missing something. It looks like native calls are the best way to get Unicode from Java to the Windows console."
http://illegalargumentexception.blogspot.co.uk/2009/04/i18n-unicode-at-windows-command-prompt.html
I've just run the program through eclipse running on OS X .
I get 12 beautiful chess pieces printed out.
I get 12 beautiful chess pieces printed out.
Yes, it's a Java/Windows problem by the looks. It would have been more interesting had you run it directly in Console though ;)
ASKER
I get 12 beautiful chess pieces printed out.
Yeah . . very sadly, that's not my problem here. I can get them printed out in other software too.
works fine through a terminal too.
ASKER
works fine through a terminal too.
. . . on Windows ?
Sorry - i meant 'Terminal' ;)
ASKER
Well, historically, I for one have always known the black-backed command line window interface in Windows as the "Command Prompt", and it seems like that is still how it should be known.
https://en.wikipedia.org/wiki/Cmd.exe
. . . on Windows ?
No. on Mac OS X.
Windows = cmd.exe
Mac = Terminal
Linux = one of a range of possibilitites: xterm, xfce4-terminal (in my case) ...
Mac = Terminal
Linux = one of a range of possibilitites: xterm, xfce4-terminal (in my case) ...
ASKER
No. on Mac OS X
Yes, as said, we are Windows on this one.
Windows never supported unicode well.
Try powershell terminal which supports unicode.
Try powershell terminal which supports unicode.
ASKER
It cant be Windows as such, since it handles the Unicode fine, as you can see from the above screenshots, if it isn't piped directly from Java.
It isn't java, as the previous experts have been trying to explain. It's the Windows command line shell. It's still 8-bit. You also -- at a minimum -- have to set its encoding.
I'm not sure where your chess set characters are -- are they part of UTF-8? In that case, you might be able to print to a Windows cmd output if you set the encoding.
This is a nice easy explanation of how to set encoding on system.out for French:
http://www.java-tips.org/java-se-tips-100019/18-java-io/2344-output-french-characters-to-the-console.html
However, your chess set chars might not be available at all to encodings which can be used in the Windows cmd.exe (or command.exe) shell.
I'm not sure where your chess set characters are -- are they part of UTF-8? In that case, you might be able to print to a Windows cmd output if you set the encoding.
This is a nice easy explanation of how to set encoding on system.out for French:
http://www.java-tips.org/java-se-tips-100019/18-java-io/2344-output-french-characters-to-the-console.html
However, your chess set chars might not be available at all to encodings which can be used in the Windows cmd.exe (or command.exe) shell.
It's the Windows command line shell. It's still 8-bit.You're right that it's 8 bit by default. But it CAN support Unicode as this post clearly shows.
-- are they part of UTF-8?Your question contains a category error. UTF-8 is not a character set. It's a method of character encoding.
And the Unicode characters are clearly shown in the code in the very first post.
Not a single post has shown the non-ascii characters correctly in the command window output. Which was the question.
Not a single post has shown the non-ascii characters correctly in the command window output.You're mistaken. The screenshot in the one to which i just linked shows them entirely accurately
I don't have an explanation for the described symptoms, just a few comments and observations on my (Windows) system:
Attached is a file (ch_to_utf8_01.txt) which:
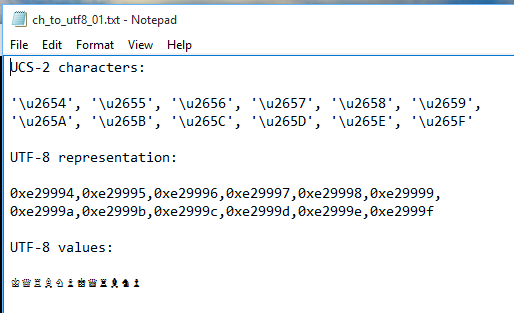
When viewed in NotePad, the file looks like this:
In a command-prompt session, with the font set to Consolas, setting the code-page to 65001, then viewing the file contents shows:
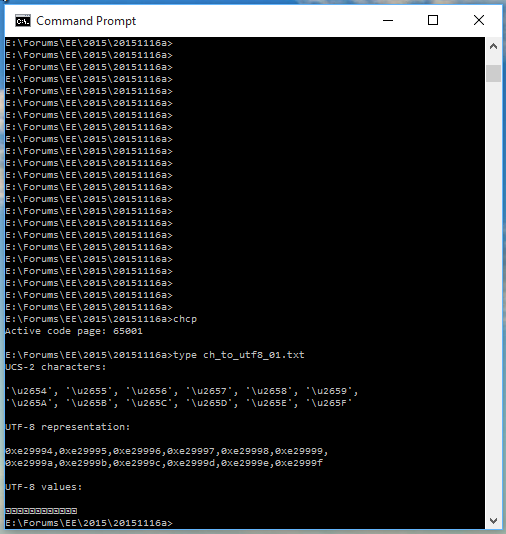
This does not show the required chess pieces (almost certainly because Consolas does not include the required glyphs), but nor does it print 36 different characters.
I've no idea how to set my command-prompt window to choose a different font (e.g. Arial Unicode MS) which might show the required glyphs; I only have a choice of Consolas.ttf, Lucida Console.ttf and 'raster fonts').
ch_to_utf8_01.txt
Attached is a file (ch_to_utf8_01.txt) which:
Shows the original Unicode code-point values, using UCS-2 representation.
Shows the equivalent UTF-8 representation of those code-points.
Contains a byte array of those actual UTF-8 values.
When viewed in NotePad, the file looks like this:
In a command-prompt session, with the font set to Consolas, setting the code-page to 65001, then viewing the file contents shows:
This does not show the required chess pieces (almost certainly because Consolas does not include the required glyphs), but nor does it print 36 different characters.
I've no idea how to set my command-prompt window to choose a different font (e.g. Arial Unicode MS) which might show the required glyphs; I only have a choice of Consolas.ttf, Lucida Console.ttf and 'raster fonts').
ch_to_utf8_01.txt
I've no idea how to set my command-prompt window to choose a different fontHave a look at http://technojeeves.com/index.php/aliasjava1/107-enabling-windows-console-for-unicode
(You can skip the step of installing a font and just fix it to use Arial Unicode MS in the registry)
As advised, set 'Arial Unicode MS' instead of 'Consolas' for the '00' entry in the referenced registry key.
But it didn't show up in the list of available fonts for the command-prompt window.
I suspect this is because this font is not a mono-spaced font, and is therefore ignored.
So I downloaded the DejaVu fonts from sourceforge, and installed the '_mono' ones, and set 'DejaVu Sans Mono' as the value assciated with the '00'' entry.
I could then select this font to use in the command-prompt window.
But the results are confusing (to say the least!):
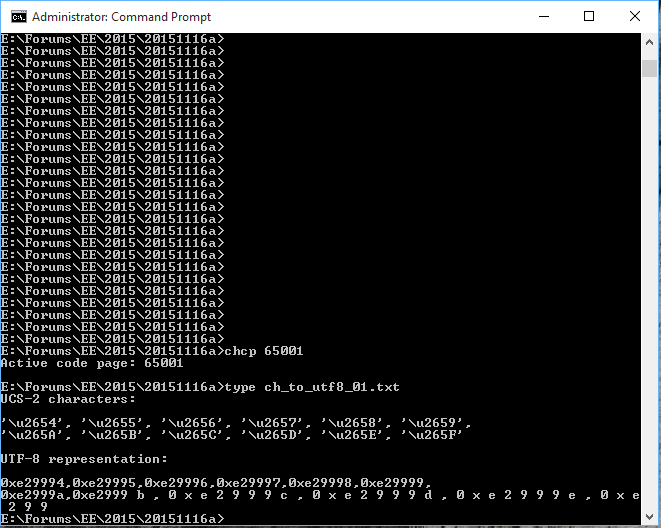
It doesn't even show all of the (non-UTF-8) explanatory text values.
Switching to use the other (TrueType) font in the list (Lucida Console) does print all the lines, although (as with the Consolas example I posted earlier), the UTF-8 encoded values only show as 'galley characters' (almost certainly because those glyphs are not in that font either).
But it didn't show up in the list of available fonts for the command-prompt window.
I suspect this is because this font is not a mono-spaced font, and is therefore ignored.
So I downloaded the DejaVu fonts from sourceforge, and installed the '_mono' ones, and set 'DejaVu Sans Mono' as the value assciated with the '00'' entry.
I could then select this font to use in the command-prompt window.
But the results are confusing (to say the least!):
It doesn't even show all of the (non-UTF-8) explanatory text values.
Switching to use the other (TrueType) font in the list (Lucida Console) does print all the lines, although (as with the Consolas example I posted earlier), the UTF-8 encoded values only show as 'galley characters' (almost certainly because those glyphs are not in that font either).
... and (to further confuse the issue):
My earlier post provided a screen-grab showing the test file being viewed with NotePad, and this showed the 'chess pieces' glyphs.
But the font being used with NotePad was Consolas (which does not contain the 'chess pieces' glyphs)!
... and they're also displayed OK if I change the NotePad font to other fonts which I know do not contain the 'chess pieces' glyphs (in fact, very few fonts do include these glyphs).
So I'm not sure how NotePad actually displays those glyphs - it would appear that some form of font substitution takes place to print them, but I've no idea if this is usual, nor which font would have been used.
ASKER
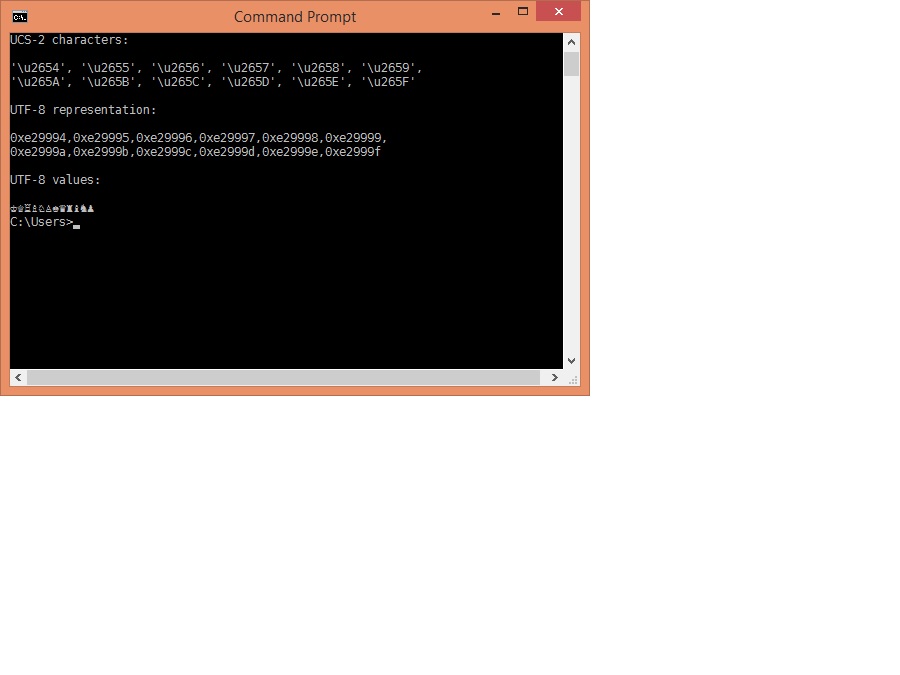
This is what I obtain from your above file when displayed in Win 8 Command Prompt using DejaVu font, and codepage 65001
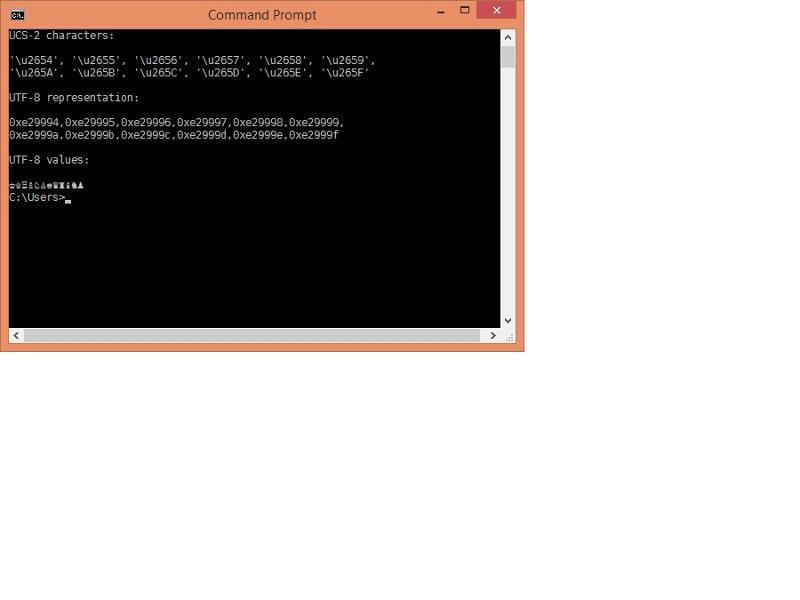
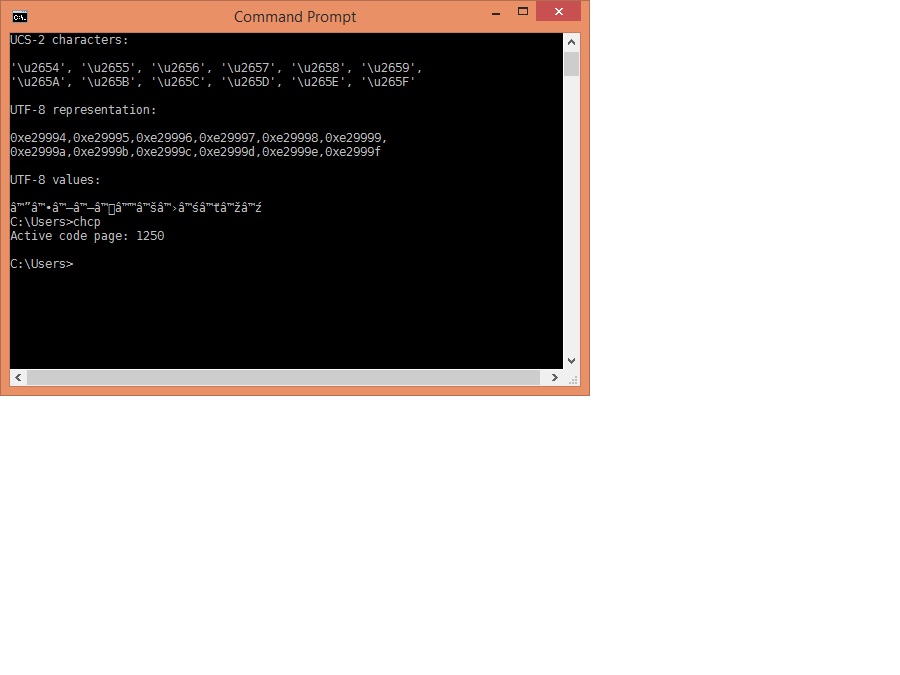
And this is what I get when using the same font, but codepage 1250 :
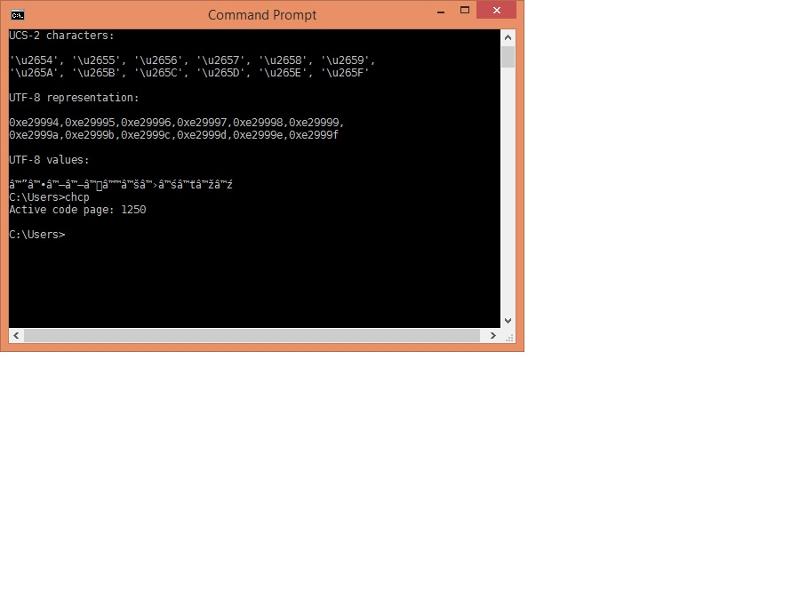
And this is what I get when using the same font, but codepage 1250 :
Your first output is what should be expected where the font (DejaVu Sans Mono) contains the required glyphs, and the byte stream is being parsed (presumably courtesy of selecting code page 65001) as UTF-8 format.
The second output is also as expected; with code page 1250, the byte stream is just parsed as separate bytes, so each (in this case) 3-byte UTF-8 sequence for each chess character is interpreted as three separate single-byte characters.
My output (on Windows 10) was different - no idea why.
... and as someone has already pointed out, the code page defines the character set (I.e. the mapping of code-0points to glyphs), whereas the encoding (in this case UTF-8) defined how the text is parsed (single-byte, or (with UTF-8) a particular multi-byte format).
It must be the case that selection of code page 65001 also sets the 'parsing mode'.
The second output is also as expected; with code page 1250, the byte stream is just parsed as separate bytes, so each (in this case) 3-byte UTF-8 sequence for each chess character is interpreted as three separate single-byte characters.
My output (on Windows 10) was different - no idea why.
... and as someone has already pointed out, the code page defines the character set (I.e. the mapping of code-0points to glyphs), whereas the encoding (in this case UTF-8) defined how the text is parsed (single-byte, or (with UTF-8) a particular multi-byte format).
It must be the case that selection of code page 65001 also sets the 'parsing mode'.
ASKER
@DansDadUK
This much we have established already. But the situation on the ground so to speak is that when the output comes directly from Java, then even with cp65001, DejaVu and java -Dfile.encoding=UTF-8 on board, the output obtained is not a single set of chess pieces - there are other chars mixed up in it and there are duplicates of some pieces. Please see my near-original post(s).
This much we have established already. But the situation on the ground so to speak is that when the output comes directly from Java, then even with cp65001, DejaVu and java -Dfile.encoding=UTF-8 on board, the output obtained is not a single set of chess pieces - there are other chars mixed up in it and there are duplicates of some pieces. Please see my near-original post(s).
if using utf-8 you have to use a byte array since utf-8 is a multibyte character set where the characters may have different number of bytes . it cannot work with using two-byte char type for each symbol.
so you either should use a "stream" of bytes where you have one for each utf-8 symbol or use utf-16 encoding. such streams need to be created with an utf-8 creator or by converting from an utf-16 code representing the same symbol. utf-16 is different to utf-8 a two-byte encoding and the chess symbols don't make an exception.
for example the chess white king has "\u2654" in c++ and java what is utf-16 encoding. the utf-8 sequence for the symbol is 3 bytes 0xE2 0x99 0x94 (short notation e29994).
see http://www.fileformat.info/info/unicode/char/2654/index.htm for more information on this special symbol.
Sara
so you either should use a "stream" of bytes where you have one for each utf-8 symbol or use utf-16 encoding. such streams need to be created with an utf-8 creator or by converting from an utf-16 code representing the same symbol. utf-16 is different to utf-8 a two-byte encoding and the chess symbols don't make an exception.
for example the chess white king has "\u2654" in c++ and java what is utf-16 encoding. the utf-8 sequence for the symbol is 3 bytes 0xE2 0x99 0x94 (short notation e29994).
see http://www.fileformat.info/info/unicode/char/2654/index.htm for more information on this special symbol.
Sara
The windows command prompt is notorious for not displaying characters correctly. I am using java 1.8.0_65 and if I output the result into a file I can see the characters correctly.
http://prntscr.com/93osxn
http://prntscr.com/93osxn
for example the chess white king has "\u2654" in c++ and java what is utf-16 encoding.I'm not sure if the above contains a question but for general information, Java stores character information in memory in what is essentially UTF-16 form. When, however, it comes to streaming them somwhere, Java relies on the System property 'file.encoding'. This will ensure (if UTF-8 is set - as it demonstrably has been above) that the correct 3 byte triplets are written to file.
I'm guessing there's some kind of miscommunication between Java and the Windows console/OS about the meaning of the encoded characters.
some kind of miscommunication between Java and the Windows console/OSi wonder how the java stdout should know of the current encoding set and the current font used in the command window. i woudn't call it a miscommuniction but a non-communication. stdout is a stream that can be redirected and therefore is independent of the current output device. so, if 'file.encoding' is the property which needs to be set properly, this setting rarely could be done by changing properties of the current console window.
i would try to convert manually from utf-16 to utf-8 which easily could be done for 32 symbols by using an appropriate mapping table.
anther approach that might work is to using utf-16 code page and unicode font in the console.
Sara
i wonder how the java stdout should know of the current encoding setWell, of course, it's the JVM that knows of it. An example of setting it explicitly is given HERE
... and the current font used in the command window.Java neither knows nor cares about the font (unless it's using GUI classes - not the case with the code in question). It simply writes to stdout with the encoding it's been told to use.
anther approach that might work is to using utf-16 code page and unicode font in the console.Good idea. I would start with cp1201 and if that fails, try cp1200
i wonder how the java stdout should know of the current encoding set
it's the JVM that knows of it.sorry, badly formulated. i meant the encoding set in the console, where we both agree on that the JVM doesn't care for.
Sara
Krakatoa, could you please try this and tell us what happens?
java -Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8 ChessCharsTester
I'm confused (even more than usual for my advanced years).
So what is the difference between the data I've generated, and what he has generated?
Can you attach a 'send to file' capture of the Java generated data, to allow comparison with my equivalent?
The author shows that the UTF-8 sequences in my test file display the chess piece characters correctly, within his (Windows 8) command-prompt session, when the code page is set to 65001
But his Java output (ostensibly generating the same UTF-8 sequences) does not appear to display the characters correctly, in the same circumstances.
So what is the difference between the data I've generated, and what he has generated?
Can you attach a 'send to file' capture of the Java generated data, to allow comparison with my equivalent?
But his Java output (ostensibly generating the same UTF-8 sequences) does not appear to display the characters correctly, in the same circumstances.But they're not the same circumstances - Java is involved where there are errors. ;)
ASKER
But they're not the same circumstances - Java is involved where there are errors. ;)
Yes, dansdad - the pathology of the problem is what's material here - the errors only occur in the interfacing of the JVM to the Windows Command Prompt. Use of the command prompt to display Unicode characters (even when written to a file BY Java) but *after the event* are not subject to these anomalies.
i meant the "same circumstances" in terms of the same font and character sets selected in the (same) Windows command-prompt session.
Just what (if anything) is different (in terms of the byte data) in what the Java code is generating from what I've generated and saved in the file I attached?
If the author uses his existing Java code, but captures the output to a file instead of effectively sending it to StdOut, then uses 'type' to display the contents of the captured file in the same command-prompt circumstances, what happens? Is it different to what happens if the output is sent directly?
Exactly what is in the captured file (a copy of the file, or a hexadecimal display, should show this to us).
Just what (if anything) is different (in terms of the byte data) in what the Java code is generating from what I've generated and saved in the file I attached?
If the author uses his existing Java code, but captures the output to a file instead of effectively sending it to StdOut, then uses 'type' to display the contents of the captured file in the same command-prompt circumstances, what happens? Is it different to what happens if the output is sent directly?
Exactly what is in the captured file (a copy of the file, or a hexadecimal display, should show this to us).
Sorry, krakatoa, you've already answered my latest question (our posts must have crossed).
The wrong display only occurs if the Java output is sent to StdOut, but if sent to a file instead and then displayed using 'type', the characters are correct.
The wrong display only occurs if the Java output is sent to StdOut, but if sent to a file instead and then displayed using 'type', the characters are correct.
ASKER
Is it different to what happens if the output is sent directly?
Exactly what is in the captured file (a copy of the file, or a hexadecimal display, should show this to us).
Yes it *is* different - we have covered that point many times now.
It doesn't really matter here what is in the "captured" file - we know that MS will parse the Unicode correctly *after the event as I already said* - but we are talking here about running a Java programme that sends its output to the stream.
ASKER
CEHJ - I ran your code, and the result is exactly the same as with the original directive - which is that 36 tokens are delivered, interspersed with question marks, plus duplicate sets of pieces.
>> ... 36 tokens are delivered ...
Not sure what you mean by tokens (I don't know Java at all), but 36 bytes is exactly what you'd expect with the UTF-8 encoding of those 12 Unicode characters.
Not sure what you mean by tokens (I don't know Java at all), but 36 bytes is exactly what you'd expect with the UTF-8 encoding of those 12 Unicode characters.
ASKER
Not sure what you mean by tokens . . .
A token is an artefact that stands for or represents something other than itself . . . here we have such tokens . . . marks on the screen which represent chess pieces.
But it looks like several contributors here are determined to believe that the way the characters have been interpreted - represented - in the code snippets and examples above, are either normal, excusable or perhaps explicable. I see none of those grounds as being valid.
The Windows Command Prompt is able to display, from a text file originating from Java output, the chess pieces correctly, yet it cannot do that when the output is delivered directly from Java in a stream. This behaviour does not seem to be mitigated or modifiable by any configuration settings that can be thrown at the Command Prompt, nor at the methods of output used in the Java code itself. So here, hidden somewhere in the mists of the native interface between Java and the MS Command Prompt, lurks a bug of significant proportions which cannot be reproduced using the very same Java code running under Unix or Mac OS. But we are no nearer to an explanation.
>> ... The Windows Command Prompt is able to display, from a text file originating from Java output, the chess pieces correctly, yet it cannot do that when the output is delivered directly from Java in a stream ...
That's not quite accurate.
When you view a text file within a command-prompt session, you are almost certainly using the 'type' command to do so.
So perhaps this command understands & supports parsing multi-byte Unicode/UTF-8 data, but 'StdIn' does not, treating everything as a single-byte data stream.
... and even if there is a bug, I can't see that fixing it in the old command-prompt interface (carried forward and hacked about from old 7-bit ASCIII DOS days) will have much priority.
That's not quite accurate.
When you view a text file within a command-prompt session, you are almost certainly using the 'type' command to do so.
So perhaps this command understands & supports parsing multi-byte Unicode/UTF-8 data, but 'StdIn' does not, treating everything as a single-byte data stream.
... and even if there is a bug, I can't see that fixing it in the old command-prompt interface (carried forward and hacked about from old 7-bit ASCIII DOS days) will have much priority.
ASKER
you are almost certainly using the 'type' command to do so.
Ham and eggs argument to me . . . the chicken was involved, the pig, committed.
and even if there is a bug, I can't see that fixing it in the old command-prompt interface (carried forward and hacked about from old 7-bit ASCIII DOS days) will have much priority.
. . . then they should not bundle it with the expensive software we are "all" practically forced to buy with a Win machine.
I'll rely on such spuriousness to shield me from the flack I'll get, the next time I post or write any code which screws up badly. :)
But whatever . . . no-one has actually put their finger on a reason for this behaviour that can be proven. And it's regretful that there is source code out there to which one has no access in order to corroborate any of the theories.
And it's regretful that there is source code out there to which one has no access in order to corroborate any of the theories.Yes, there' s certainly no Windows VM/native library source that i can find, which means that 'Java is open source' is only true in a very limited way.
Sun did release the source for much -- perhaps all? -- of java late in its tenure. Googling can often find it. It's a big job, though, reading through the OS-specific code in the JVM.
Well i've had a pretty good look and haven't been able to find it. Of course, we can't talk about bugs in versions other than the one krakatoa is running, so the source of that version would need to be consulted.
ASKER
Wondering if anyone is loading up their magic bullets, or whether the question should now be closed . . .?
CEHJ: a lot of it has been uploaded to github . Usually if you know the class you want (because you're getting exceptions) you can find the source online. For example:
https://java.net/projects/jna/sources/svn/show/trunk/jnalib/src/com/sun/jna?rev=1212
krakatoa: I think we've answered this one. It looks to me as if you haven't implemented all the suggestions, so you still feel you don't have a solution? Spend more time on your code, post actual problems, and we'll see if it can work the way you want.
Nice discussion of this problem:
http://hints.macworld.com/article.php?story=20050208053951714
https://java.net/projects/jna/sources/svn/show/trunk/jnalib/src/com/sun/jna?rev=1212
krakatoa: I think we've answered this one. It looks to me as if you haven't implemented all the suggestions, so you still feel you don't have a solution? Spend more time on your code, post actual problems, and we'll see if it can work the way you want.
Nice discussion of this problem:
http://hints.macworld.com/article.php?story=20050208053951714
ASKER
Not yet answered as far as I am concerned - but if you think you know something that I have missed from the question, then I'd be happy to hear it.
Your link is interesting. Inter alia :
"Alternatively, just run the original program like this:
java -Dfile.encoding=UTF8 Test
and it'll work fine.
Substitute UTF8 with whatever is appropriate for your current terminal/needs."
This is not a novel suggestion, as can be seen from the comments above, wherein you can see that that switch has already been fruitlessly applied.
Another commenter in the link adds :
"Second is the encoding in your source code; you set this in the same way with the -D option when compiling. This will affect extended characters in string literals &c"
. . . which is partly correct but the syntax is actually "javac -encoding UTF-8 someclass.java".
Having said all that, neither of the suggested tweaks has any positive impact. I am not completely sure what you had in mind when saying I should keep working on my code, as the only work left to do as far as I can see, is to find the correct encoding and character sets that can display the correct 12 chars.
Your link is interesting. Inter alia :
"Alternatively, just run the original program like this:
java -Dfile.encoding=UTF8 Test
and it'll work fine.
Substitute UTF8 with whatever is appropriate for your current terminal/needs."
This is not a novel suggestion, as can be seen from the comments above, wherein you can see that that switch has already been fruitlessly applied.
Another commenter in the link adds :
"Second is the encoding in your source code; you set this in the same way with the -D option when compiling. This will affect extended characters in string literals &c"
. . . which is partly correct but the syntax is actually "javac -encoding UTF-8 someclass.java".
Having said all that, neither of the suggested tweaks has any positive impact. I am not completely sure what you had in mind when saying I should keep working on my code, as the only work left to do as far as I can see, is to find the correct encoding and character sets that can display the correct 12 chars.
For example:That's something quite different - an external library
https://java.net/projects/jna/sources/svn/show/trunk/jnalib/src/com/sun/jna?rev=1212
Not all articles are fully debugged. The statement in the article about just using -D encoding is not always sufficient as you've found. However, I don't see evidence that you've tried what others suggested here and is documented in the article -- try making a printstream and setting encoding correctly.
CEHJ: That was an example of sun code (as you can see) where the source is posted. Come up with a sun native class you're interested in, and try googling. If you work with CORBA, this is posted:
http://grepcode.com/file/repository.jboss.org/nexus/content/repositories/releases/org.jboss.openjdk-orb/openjdk-orb/8.0.2.Beta3/com/sun/corba/se/impl/javax/rmi/CORBA/Util.java
I don't have the Sun classes memorized -- if you know the one being used for printing to stdout, then krakatoa could look for that one online.
CEHJ: That was an example of sun code (as you can see) where the source is posted. Come up with a sun native class you're interested in, and try googling. If you work with CORBA, this is posted:
http://grepcode.com/file/repository.jboss.org/nexus/content/repositories/releases/org.jboss.openjdk-orb/openjdk-orb/8.0.2.Beta3/com/sun/corba/se/impl/javax/rmi/CORBA/Util.java
I don't have the Sun classes memorized -- if you know the one being used for printing to stdout, then krakatoa could look for that one online.
There's a lot of talk about 'classes'. It's most likely to be around the source of the JVM for Windows itself.
Ham and eggs argument to me . . . the chicken was involved, the pig, committed.
I've no idea what point you are are trying to make, or refute, here.
. . . then they should not bundle it with the expensive software we are "all" practically forced to buy with a Win machine
With such criteria, we'd still be waiting until a stable & secure version of Java was available before it could be released.
I'm sure that there are lots of dark corners of *n*x and Java systems which still have plenty of bugs for which resolutions are very low down in the list of priorities.
ASKER
One might be tempted to think that a responsible house might be minded to crush the old bugs before it pressed on creating new ones.
Well it's probably not a big priority for them. It's difficult to even find this exact bug described, though this looks related:
http://bugs.java.com/bugdatabase/view_bug.do?bug_id=8124977
http://bugs.java.com/bugdatabase/view_bug.do?bug_id=8124977
In an ideal world!
I'm retired now, but in my working life I've had access to the source code of a quite sophisticated mainframe operating system, and of (an SVR4 version of) Unix.
Both had plenty of unresolved bugs for which it was (much) more cost-effective (and timely) to advise on circumventions (in some cases, detailed instructions, in others (especially for older utilities or sub-systems) to advise use of a more modern replacement), than to attempt to fix the bug.
I'm retired now, but in my working life I've had access to the source code of a quite sophisticated mainframe operating system, and of (an SVR4 version of) Unix.
Both had plenty of unresolved bugs for which it was (much) more cost-effective (and timely) to advise on circumventions (in some cases, detailed instructions, in others (especially for older utilities or sub-systems) to advise use of a more modern replacement), than to attempt to fix the bug.
ASKER
Funny . . . I once worked for a company with the same problems. One day, a customer with nothing better to do found those vulnerabilities.
You can maybe work out the rest. If not, let me know. ;)
The irony here is that this might not be a bug . . . there is a chance that, since this does not evidently manifest itself in other environments, it could be, to coin a phase, a mere "slip of the finger". ;)
--------------
It's quite a pity it has defeated the teams in providing an explanation, rather than an "excuse". I'm not saying that a fix should suddenly be forthcoming just on the strength of a question from me. But it does show that it might be beyond anything that can be done here, and so to avoid endless circling, I'll close.
You can maybe work out the rest. If not, let me know. ;)
The irony here is that this might not be a bug . . . there is a chance that, since this does not evidently manifest itself in other environments, it could be, to coin a phase, a mere "slip of the finger". ;)
--------------
It's quite a pity it has defeated the teams in providing an explanation, rather than an "excuse". I'm not saying that a fix should suddenly be forthcoming just on the strength of a question from me. But it does show that it might be beyond anything that can be done here, and so to avoid endless circling, I'll close.
ASKER
At this point, without this answer delivering what one might call a full avoidance strategy, or tangible explanation, it does underline the concern itself . . . which, at the moment, seems all that can be done.