rwallacej
asked on
Big data 2 million records per hour
I have data source generating 2 million inputs per hour ( then there are inputs too )
How do I manage this ?
I'm used to SQL Server
Data has time stamp and value
Thanks
How do I manage this ?
I'm used to SQL Server
Data has time stamp and value
Thanks
How are the records being inputed?
There's a purge mechanism? If affirmative, how often it runs and how late data is permitted to be stored?
Which edition and SQL Server version are you using?
How much resource the server has?
There's a purge mechanism? If affirmative, how often it runs and how late data is permitted to be stored?
Which edition and SQL Server version are you using?
How much resource the server has?
I guess it strongly depends on your requirements..
How long you need to store those values? This means you need an estimated 1TB per week. So you need engouh storage.
Do you need to store the native values or would be storing aggregates by interval, e.g. 1 second, enough? Then maybe Stream Insight is an option.
Do you need to do this on prem or is cloud an alternative?
2,000,000 rows per hour are <1000 rows per second, which can be handled, but requires already a good design avoiding locking.
How long you need to store those values? This means you need an estimated 1TB per week. So you need engouh storage.
Do you need to store the native values or would be storing aggregates by interval, e.g. 1 second, enough? Then maybe Stream Insight is an option.
Do you need to do this on prem or is cloud an alternative?
2,000,000 rows per hour are <1000 rows per second, which can be handled, but requires already a good design avoiding locking.
ASKER
Server has many, many terabytes of space
Data held for few years then could archive
Time stamp would be date time second.
I don't quite know how data arrives, via a web service I think.
SQL server enterprise
Purge mechanism - what is this
Cloud would perhaps be option - but pretty sure it would need to be on existing server
Aggregates by interval - what is this ?
Data held for few years then could archive
Time stamp would be date time second.
I don't quite know how data arrives, via a web service I think.
SQL server enterprise
Purge mechanism - what is this
Cloud would perhaps be option - but pretty sure it would need to be on existing server
Aggregates by interval - what is this ?
"Purge mechanism - what is this" --> It's this: "Data held for few years then could archive"
"SQL server enterprise" --> That's the edition. How about the version (2012, 2014,...)?
"SQL server enterprise" --> That's the edition. How about the version (2012, 2014,...)?
I don't quite know how data arrives,You should because the solution depends on that. How can you know the transfer rate if you don't know how it arrives ("I have data source generating 2 million inputs per hour")?
ASKER
Purge mechanism - yes
2014
I only know 2 million per hour. It's storage of this I'm interested in, actual process of arrival unknown at moment , only they are 2 million
2014
I only know 2 million per hour. It's storage of this I'm interested in, actual process of arrival unknown at moment , only they are 2 million
Seems that my first estimate was wrong. A row consists of a date and a value. What kind of value?
Data alone see sheet. Then you need the index overhead. Evaluate the space for partitioning.
Could this be correct?
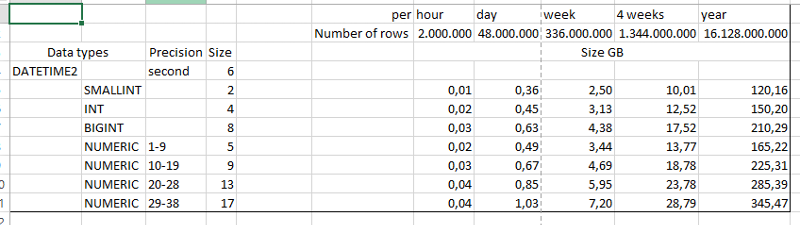
Data alone see sheet. Then you need the index overhead. Evaluate the space for partitioning.
Could this be correct?
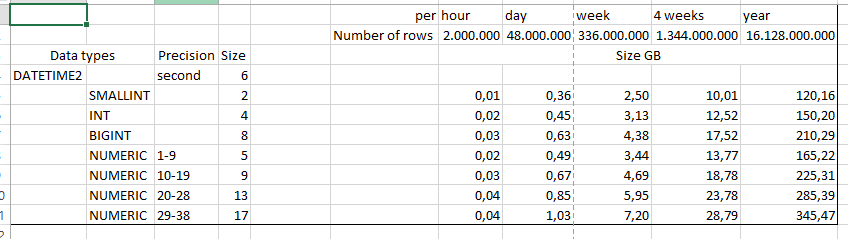
It's storage of this I'm interestedWell, you already told that "Server has many, many terabytes of space" so without knowing the load mechanism there's not much to say. SQL Server engine is very able to manage 2M of rows by hour and you have storage enough so for now can't see any issue unless you can provide more information.
1 TB per week seems to be wrong when you don't know the record size...
1 TB / (2mio*24*7) = 3000 B per record approx.
Are 3000 bytes enough for the tag, value, and timestamp? I would say the record could consume 30 bytes at most which is 100 times less than 1 TB per week so SQL Server should be OK with sufficient disk array and backup/archive plan.
Of course, answers to questions placed by other experts are highly important to finalize this planning stage.
Next steps:
Read something about Big data, e.g. here: https://www.mssqltips.com/sql-server-tip-category/208/big-data/
SQL Server supports File streams: https://msdn.microsoft.com/en-us/library/gg471497.aspx
Your case does not seem to belong into one of the above two categories so one big SQL table should be OK for your data but you have to say what are your plans with these data which then help to create indexes or partitioning etc.
1 TB / (2mio*24*7) = 3000 B per record approx.
Are 3000 bytes enough for the tag, value, and timestamp? I would say the record could consume 30 bytes at most which is 100 times less than 1 TB per week so SQL Server should be OK with sufficient disk array and backup/archive plan.
Of course, answers to questions placed by other experts are highly important to finalize this planning stage.
Next steps:
Read something about Big data, e.g. here: https://www.mssqltips.com/sql-server-tip-category/208/big-data/
SQL Server supports File streams: https://msdn.microsoft.com/en-us/library/gg471497.aspx
Your case does not seem to belong into one of the above two categories so one big SQL table should be OK for your data but you have to say what are your plans with these data which then help to create indexes or partitioning etc.
ASKER
Tag would be int, 0 to 2million (very max)
Date a date time with d,m,y, h,m,sec
Value a double , say -1 million to +1m, with decimals
Date a date time with d,m,y, h,m,sec
Value a double , say -1 million to +1m, with decimals
ASKER
Data for calculations, charts, max /min ,averages
I would also recommend storing this table in its own file group depending on what else is in the database. I don't expect you want to be backing up and restoring this database on any staging (non-production) environments and it is easier to exclude if it is in a different file group.
Hi!
You say 2 million records/hour. That is 48 million records every 24 hours and 336 million records / week. Almost 17,5 billion records/year. That is quite large. ;)
Is the table holding that data partitioned using the timestamp field ?
If not then I strongly suggest you consider to partition the table in that way for easy data-management and archiving of old data.
And at least have the partition every week (52 partitions with 336 million records per partition) or even per day (365 partitions each with 48 million records)
This will also drastically speed up sql-queries and inserts/updates/deletes and data load.
https://msdn.microsoft.com/en-us/library/ms188730.aspx
https://msdn.microsoft.com/en-us/library/ms190787.aspx
http://www.brentozar.com/sql/table-partitioning-resources/
Regards,
Tomas Helgi
You say 2 million records/hour. That is 48 million records every 24 hours and 336 million records / week. Almost 17,5 billion records/year. That is quite large. ;)
Is the table holding that data partitioned using the timestamp field ?
If not then I strongly suggest you consider to partition the table in that way for easy data-management and archiving of old data.
And at least have the partition every week (52 partitions with 336 million records per partition) or even per day (365 partitions each with 48 million records)
This will also drastically speed up sql-queries and inserts/updates/deletes and data load.
https://msdn.microsoft.com/en-us/library/ms188730.aspx
https://msdn.microsoft.com/en-us/library/ms190787.aspx
http://www.brentozar.com/sql/table-partitioning-resources/
Regards,
Tomas Helgi
Quick question not already handled buy the above experts: Do you really need to ETL all rows?
I had an interview process with a solar energy company where there they had a TON of devices (think Internet of Things IOT) that created rows every second. The strategy was to ETL every minute the most recent row, and not the 60 rows from the previous ETL. That would end up in their data warehouse / decision management system. If anything died / blew up / went off the chart / was sabotaged by crazy environmentalist wackos, there was a side ETL job that could be executed that would extract every row from the problem device.
I had an interview process with a solar energy company where there they had a TON of devices (think Internet of Things IOT) that created rows every second. The strategy was to ETL every minute the most recent row, and not the 60 rows from the previous ETL. That would end up in their data warehouse / decision management system. If anything died / blew up / went off the chart / was sabotaged by crazy environmentalist wackos, there was a side ETL job that could be executed that would extract every row from the problem device.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
Given the very limited info in the original q, I'm not sure what more you wanted in the answer, but hopefully what I provided did help out at least a little bit.
ASKER