How to filter efficiently a poorly designed DB?
Hi Experts,
I have a table named Employeestbl and it entails information of almost everything belonging to the employee, including for example all health documents expiration dates .
In other words any information that an employee can only have one (one to one relationship) is part of the table..
Now I got the request to list all employees that have some documents expiring in given date range.
Was planning to create a Union query of all documents and then filter for the date range, wondering if this is the best way regarding efficiency to deal with this situation (Besides of remodeling the DB of course..which I'm not up to at this point:)?
Attached screenshot to show how the table looks like.
untitled.png
I have a table named Employeestbl and it entails information of almost everything belonging to the employee, including for example all health documents expiration dates .
In other words any information that an employee can only have one (one to one relationship) is part of the table..
Now I got the request to list all employees that have some documents expiring in given date range.
Was planning to create a Union query of all documents and then filter for the date range, wondering if this is the best way regarding efficiency to deal with this situation (Besides of remodeling the DB of course..which I'm not up to at this point:)?
Attached screenshot to show how the table looks like.
untitled.png
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
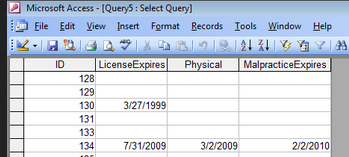 You display just 4 columns via a query (query5 in fact) but are asking us about a table called employees.
You display just 4 columns via a query (query5 in fact) but are asking us about a table called employees.Are you saying that the table is not normalized and that (for example) you have MANY ID's for a single person? or that an "employee id" is repeated over many rows (along with name etc.)
It is hard to answer precisely if the problem is vague
ASKER
@Paul,
I was just trying to give an example of the table structure, however attached you can see the screenshot of create script in more detail.
FYI- All those date fields are needed to be filtered in this query in question.
The ID is the PK of the table that each employee has one (You would call it EmployeeID).
Thanks,
Ben
Untitled.png
I was just trying to give an example of the table structure, however attached you can see the screenshot of create script in more detail.
FYI- All those date fields are needed to be filtered in this query in question.
The ID is the PK of the table that each employee has one (You would call it EmployeeID).
Thanks,
Ben
Untitled.png
Many employees means many thousands of employees. If we are talking about 10000 employees than it means nothing.
Of course, if the query would be called frequently then you may create some optimized table which will contain just ID, DocName, ExpDate and populate it daily or more often.
Of course, if the query would be called frequently then you may create some optimized table which will contain just ID, DocName, ExpDate and populate it daily or more often.
ASKER
@pcelba,
We are talking about 200K.
Not sure how often this will be used, however wanted to start with something workable, I guess will first design the way you have proposed and see how it performs and users feedback..
Thanks,
Ben
We are talking about 200K.
Not sure how often this will be used, however wanted to start with something workable, I guess will first design the way you have proposed and see how it performs and users feedback..
then you may create some optimized table which will contain just ID, DocName, ExpDate and populate it daily or more often.Is there a way to schedule this in SSMS or I need to do it FE App?
Thanks,
Ben
Yes, periodic call of stored procedure which recreates the optimized table is possible to setup as a job in SSMS (in SQL Server Agent).
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
@pcelba,
Good to know I can rely on SSMS to do this kind of tasks.
Regarding the current issue, I guess will wait to see what is the difference in performance between your select version and what Paul is coming up with.
@Paul,
I got the following error when testing your code in SSMS (SQL Express 2005)
Incorrect syntax near 'UNPIVOT'. You may need to set the compatibility level of the current database to a higher value to enable this feature. See help for the stored procedure sp_dbcmptlevel.
1- Does it mean I need to change the DB compatibility or I can call this from my FE application w/o modifying?
2- In case I do need to modify, what kind of impact can this have to the entire database/application?
Thanks,
Ben
Good to know I can rely on SSMS to do this kind of tasks.
Regarding the current issue, I guess will wait to see what is the difference in performance between your select version and what Paul is coming up with.
@Paul,
I got the following error when testing your code in SSMS (SQL Express 2005)
Incorrect syntax near 'UNPIVOT'. You may need to set the compatibility level of the current database to a higher value to enable this feature. See help for the stored procedure sp_dbcmptlevel.
1- Does it mean I need to change the DB compatibility or I can call this from my FE application w/o modifying?
2- In case I do need to modify, what kind of impact can this have to the entire database/application?
Thanks,
Ben
The view is more sophisticated solution, the table will behave faster.
The higher compatibility level should not cause problems in your case. You could even upgrade the SQL engine to higher version.
More about PIVOT-UNPIVOT: https://technet.microsoft.com/en-us/library/ms177410(v=sql.105).aspx
The higher compatibility level should not cause problems in your case. You could even upgrade the SQL engine to higher version.
More about PIVOT-UNPIVOT: https://technet.microsoft.com/en-us/library/ms177410(v=sql.105).aspx
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
You are right Paul, the compatibility level is not enough for the UNPIVOT operation. And SQL 2005 becomes obsolete...
The upgrade also brings higher db size than 2 GB allowed in SQL Express 2005. OTOH no one Express version supports more concurrent users than let say 5. More users means significant speed degradation.
The upgrade also brings higher db size than 2 GB allowed in SQL Express 2005. OTOH no one Express version supports more concurrent users than let say 5. More users means significant speed degradation.
You can't do anything efficiently with a poorly designed table. Unless you can normalize the table, then I would simply go with an enormous where clause. A full table scan of 200,000 rows shouldn't take very long.
PS - when you attempted to normalize into a temp table, did you only insert rows for populated dates? There is no reason to insert a row for each potential date. Based on the data you posted, the table should be pretty sparse and need only three columns EmployeeID, DateType, Date;
PS - when you attempted to normalize into a temp table, did you only insert rows for populated dates? There is no reason to insert a row for each potential date. Based on the data you posted, the table should be pretty sparse and need only three columns EmployeeID, DateType, Date;
ASKER
Hi Experts,
I will do my testing compare Pauls latest suggestion with pcelba first suggestion (or how Pat calls it "enormous where clause") see what works best in our case & keep you posted.
Regarding schedule a SP I feel uncomfortable as data is constantly changing.
@Pat,
Thanks,
Ben
I will do my testing compare Pauls latest suggestion with pcelba first suggestion (or how Pat calls it "enormous where clause") see what works best in our case & keep you posted.
Regarding schedule a SP I feel uncomfortable as data is constantly changing.
@Pat,
You can't do anything efficiently with a poorly designed table.The issue here is that a lot of programming would need to be redesigned in order to fix that, at the moment I dont have the approval-:(
Thanks,
Ben
I understand. Apparently the repeating group doesn't grow or there would have been sufficient pain to cause a redesign. As it is, it is simply expensive to work with. Documenting how much time you spend doing new things might start the justification process.
ASKER
@Paul,
I got following error
"Incorrect syntax near the keyword 'VALUES'."
@Pat,
I am not trying to justify the current design model, however wondering if you have an easy way to present users with such a screen for input data (see attached) when the tables are properly structured with a one to many relationship and 3 columns as you described ?
PS. in that case I will open a new question and you take it from there..
Thanks,
Ben
Untitled.png
I got following error
"Incorrect syntax near the keyword 'VALUES'."
@Pat,
I am not trying to justify the current design model, however wondering if you have an easy way to present users with such a screen for input data (see attached) when the tables are properly structured with a one to many relationship and 3 columns as you described ?
PS. in that case I will open a new question and you take it from there..
Thanks,
Ben
Untitled.png
Can you please identify the exact version of SQL Server you are using please?
Not sure I can offer much else except a very old fashioned UNION ALL approach (which is not wonderful for performance.)
Not sure I can offer much else except a very old fashioned UNION ALL approach (which is not wonderful for performance.)
SELECT ID , 'BclsLetterDate' as ColumnName , BclsLetterDate as DatetimeValue FROM Employees UNION ALL
SELECT ID , 'AclsLetterDate' as ColumnName , AclsLetterDate as DatetimeValue FROM Employees UNION ALL
SELECT ID , 'NalsLetterDate' as ColumnName , NalsLetterDate as DatetimeValue FROM Employees UNION ALL
SELECT ID , 'PalsLetterDate' as ColumnName , PalsLetterDate as DatetimeValue FROM EmployeesSOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
@Paul,
Here are additional info if they matters.
Microsoft SQL Server Management Studio 9.00.1399.00
Microsoft Analysis Services Client Tools 2005.090.1399.00
Microsoft Data Access Components (MDAC) 2000.086.3959.00 (srv03_sp2_rtm.070216-1710
Microsoft MSXML 2.6 3.0 4.0 5.0 6.0
Microsoft Internet Explorer 6.0.3790.3959
Microsoft .NET Framework 2.0.50727.3643
Operating System 5.2.3790
Thanks,
Ben
Can you please identify the exact version of SQL Server you are using please?SQL 2005 (sorry for not specifying it at first place)
Here are additional info if they matters.
Microsoft SQL Server Management Studio 9.00.1399.00
Microsoft Analysis Services Client Tools 2005.090.1399.00
Microsoft Data Access Components (MDAC) 2000.086.3959.00 (srv03_sp2_rtm.070216-1710
Microsoft MSXML 2.6 3.0 4.0 5.0 6.0
Microsoft Internet Explorer 6.0.3790.3959
Microsoft .NET Framework 2.0.50727.3643
Operating System 5.2.3790
Thanks,
Ben
ASKER
@Pat,
First thanks for your deep analization of our data contents.
In general I was referring to your comment above
However I see you also agreed to this, its just that you're suggesting it should still be split in different tables according to type of info.
But in this case for example where I have to collect data from all date fields, I dont see this being anything of advantage, perhaps the other way as I would be looking into multiple tables using left/right outer joins instead of looking only at one table, (especially if I decide to go with pcelba/your route of filtering).
Again, perhaps you're right in case I would be re-designing it now, but at the moment I can only focus on what needs to be done in order to accomplish the query in question.
Thanks,
Ben
First thanks for your deep analization of our data contents.
In general I was referring to your comment above
Based on the data you posted, the table should be pretty sparse and need only three columns EmployeeID, DateType, Date;which this is quite difficult if I need to present users with pre-defined fields for data entry like form shown.
However I see you also agreed to this, its just that you're suggesting it should still be split in different tables according to type of info.
But in this case for example where I have to collect data from all date fields, I dont see this being anything of advantage, perhaps the other way as I would be looking into multiple tables using left/right outer joins instead of looking only at one table, (especially if I decide to go with pcelba/your route of filtering).
Again, perhaps you're right in case I would be re-designing it now, but at the moment I can only focus on what needs to be done in order to accomplish the query in question.
Thanks,
Ben
ASKER
Hi Experts,
So far by comparing the following two methods I dont see significant difference.
#1
#2
Thanks,
Ben
So far by comparing the following two methods I dont see significant difference.
#1
select * from dbo.MyView
where ID in (
select ID from (
SELECT ID , 'BclsLetterDate' as ColumnName , BclsLetterDate as DatetimeValue FROM Employeestbl UNION ALL
SELECT ID , 'AclsLetterDate' as ColumnName , AclsLetterDate as DatetimeValue FROM Employeestbl UNION ALL
SELECT ID , 'NalsLetterDate' as ColumnName , NalsLetterDate as DatetimeValue FROM Employeestbl UNION ALL
SELECT ID , 'PalsLetterDate' as ColumnName , PalsLetterDate as DatetimeValue FROM Employeestbl
) as U
where DateTimeValue <getdate()
)#2
select * from dbo.MyView
where ID in (
select ID from Employeestbl where BclsLetterDate < getdate()
or AclsLetterDate < getdate()
or NalsLetterDate < getdate()
or PalsLetterDate < getdate()
)Thanks,
Ben
Agreed, I don't recommend the UNION ALL approach - apologies if you thought I was doing that
As you cannot use UNPIVOT (or CROSS APPLY with VALUES) you are "stuck" the options you just tested, but using lots of unions just adds many scans of the table and that isn't great for performance.
So the "massive" query (#2) is probably the winner.
(until you re-design and/or upgrade)
As you cannot use UNPIVOT (or CROSS APPLY with VALUES) you are "stuck" the options you just tested, but using lots of unions just adds many scans of the table and that isn't great for performance.
So the "massive" query (#2) is probably the winner.
(until you re-design and/or upgrade)
I didn't recommend different tables by type. I just mentioned it as an option. Without knowing more about how you will use the tables and how many unique data fields you have, I can't make a decision. On the surface of it and based on using both types of schemas, I would probably go with the single table with fields that are used only for certain test types. But don't choose without going through the ramifications of the interface and reporting.
ASKER
Thanks to all participants!
@pcelba
um.
OTOH no one Express version supports more concurrent users than let say 5. More users means significant speed degradation.
I'm not sure where you got that idea from.
There's never been a limitation on the number of concurrent users.
See for yourself
https://msdn.microsoft.com/en-us/library/cc645993.aspx
You don't get the SQL Profiler, you can't use the cluster/high availability stuff, and you are limited to using (for the SQL Server software, not the server hardware) 1 socket with up to 4 cores and 1 GB of RAM. As a backend to Access, you are going to hit Access's unhappiness with lots of concurrent users long before the server is the issue.
I've got 20 users. Pretty much steady as she goes.
um.
OTOH no one Express version supports more concurrent users than let say 5. More users means significant speed degradation.
I'm not sure where you got that idea from.
There's never been a limitation on the number of concurrent users.
See for yourself
https://msdn.microsoft.com/en-us/library/cc645993.aspx
You don't get the SQL Profiler, you can't use the cluster/high availability stuff, and you are limited to using (for the SQL Server software, not the server hardware) 1 socket with up to 4 cores and 1 GB of RAM. As a backend to Access, you are going to hit Access's unhappiness with lots of concurrent users long before the server is the issue.
I've got 20 users. Pretty much steady as she goes.
Hmmm ... and all these limitations make Express version unusable for more than let say 5 concurrent users... Did you ever tested 10 GB Express database with 20 simultaneously connected users?
More than let say 5 does not mean 5 is the maximum.
More than let say 5 does not mean 5 is the maximum.
Did you ever tested 10 GB Express database with 20 simultaneously connected users?
Nope.
1.7 GB and growing without problems, though.
10 GB is the upper limit for file size for the Express versions 2008 R2 and later.
SSEE 2005 had an upper limit on file size of 4 GB
(Access is limited to a file size of 2 GB)
https://technet.microsoft.com/en-us/library/ms345154(v=sql.90).aspx
Now, like all db's, your mileage varies depending on what you are doing with the data.
More than let say 5 does not mean 5 is the maximum.
Good enough. But depending upon usage scenario that number can be a lot bigger than 5.
Five is a small enough number to attract some comment :)
Nope.
1.7 GB and growing without problems, though.
10 GB is the upper limit for file size for the Express versions 2008 R2 and later.
SSEE 2005 had an upper limit on file size of 4 GB
(Access is limited to a file size of 2 GB)
https://technet.microsoft.com/en-us/library/ms345154(v=sql.90).aspx
Now, like all db's, your mileage varies depending on what you are doing with the data.
More than let say 5 does not mean 5 is the maximum.
Good enough. But depending upon usage scenario that number can be a lot bigger than 5.
Five is a small enough number to attract some comment :)
ASKER
Thats exactly the case here, there are many records in employees table, however there are plenty of documents fields as well (few dozens) therefore dont think creating an index is the proper thing to do.
Thanks,
Ben