Could you point what could cause a PDF file corruption generation depending on the server (CPU and PHP) is used ?
Hi Experts
Could you point what could cause a PDF file corruption generation depending on the server (CPU and PHP) is used ?
When using this PHP library PDF generator:
I'm facing an amazing issue, the PDF is correctly generated in Development Server and in Homologation Server.
But unfortunatelly in Prodution Server this error arises:
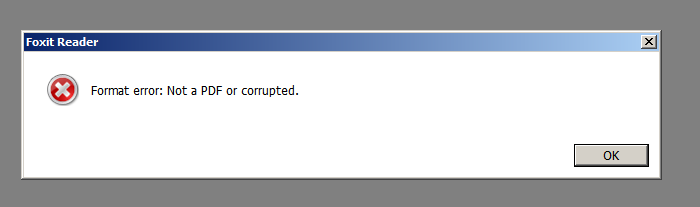
If it's beein generated in another server, the same code, everything goes fine....
To complicate a little more, some PDF(s) are perfectly generated in the Prodution Server, just this not...
PHP Version => Prodution => 5.4.35
PHP Version => Development => 5.6.28
Thanks in advance!
Could you point what could cause a PDF file corruption generation depending on the server (CPU and PHP) is used ?
When using this PHP library PDF generator:
// Software: mPDF, Unicode-HTML Free PDF generator *
// Version: 6.0 based on *
// FPDF by Olivier PLATHEY *
// HTML2FPDF by Renato Coelho *
// Date: 2014-11-24 *
// Author: Ian Back <ianb@bpm1.com> *
// License: GPL I'm facing an amazing issue, the PDF is correctly generated in Development Server and in Homologation Server.
But unfortunatelly in Prodution Server this error arises:
If it's beein generated in another server, the same code, everything goes fine....
To complicate a little more, some PDF(s) are perfectly generated in the Prodution Server, just this not...
PHP Version => Prodution => 5.4.35
PHP Version => Development => 5.6.28
Thanks in advance!
A BOM is not valid at the front a PDF file. A PDF is a binary file format so a BOM wouldn't actually make sense. But maybe if we can see a "good" copy and a corresponding corrupted copy we might be able to find something.
Some questions that might lead in the right direction...
I see "Foxit Reader." Can you open the files with Acrobat?
Have you tried making a byte-by-byte comparison?
What is different about this file from the files that are generated correctly by the same software?
And an observation that should be obvious - the PHP versions are different between Development and Production (not a good idea). Have you read the PHP change logs for any differences that might be in play? Have you compared phpinfo()?
Some questions that might lead in the right direction...
I see "Foxit Reader." Can you open the files with Acrobat?
Have you tried making a byte-by-byte comparison?
What is different about this file from the files that are generated correctly by the same software?
And an observation that should be obvious - the PHP versions are different between Development and Production (not a good idea). Have you read the PHP change logs for any differences that might be in play? Have you compared phpinfo()?
ASKER
Hi
An apparently "corrupted" file in the production server when using Foxit could be openned by TWinUI (Windows 8)
Unfortunatelly the Production Server doesn't allow to install "Adobe Acrobat"...
An apparently "corrupted" file in the production server when using Foxit could be openned by TWinUI (Windows 8)
Unfortunatelly the Production Server doesn't allow to install "Adobe Acrobat"...
Can we see samples of corrupt and non-corrupt PDF?
Production Server doesn't allow to install "Adobe Acrobat"...I can't tell anyone what to do, but here's a thought. Acrobat Reader (its current name) is free, well-supported, and installed in literally millions of computers world-wide. In other words, it's THE mainstream solution for reading PDF documents. I think it is usually installed on a desktop and can access PDF documents on a server via hyperlinks. Might be worth testing!
ASKER
Ray
I completelly agree with you. The problem is not especifically to Adobe Reader...
Since during instalation the Adobe site is accessed and the link is listed as denied.
I completelly agree with you. The problem is not especifically to Adobe Reader...
Since during instalation the Adobe site is accessed and the link is listed as denied.
some PDF(s) are perfectly generated in the Prodution Server, just this not..
This sounds like a data issue. Development / testing environments often have great-quality data, which is a bad thing because you're not testing your code through bad data. Real people put bad data into production environments all the time, which can explain why sometimes you see PDFs generate correctly and other times not.
You should try to specifically identify the entire data set being used for input that results in a bad PDF. Then take that IDENTICAL data set and bring it over to your development environment (you should use a script to copy the data without modifications - do NOT copy and paste the data since that could modify/fix the data), and try to reproduce the same issue in your test environment with that dataset.
For example, you might have end users putting RTF characters or other special characters that might be acceptable, and the PDF library might just dump them into the PDF without proper handling. Some readers would be able to handle the special characters and display the PDF correctly while other readers might choke.
@Eduardo, at the risk of belabouring the point - can we see examples of the PDF's? Can you post them here. By examining the contents of the PDF we can gain some insight as to what might be causing the "corruption"
ASKER
Hi
The file is opened in PDF-XChanged Editor - one that I could install in the Production Server, with this warning:
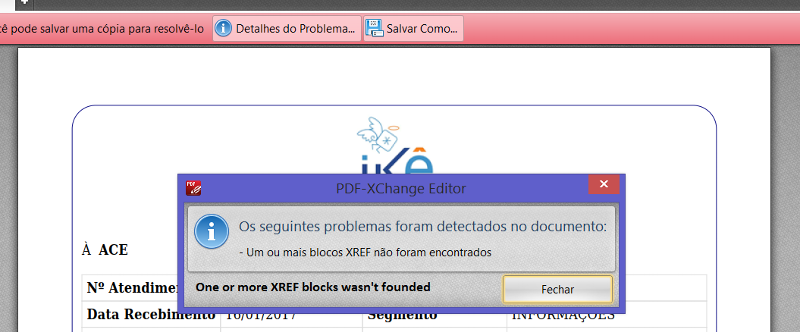
Foxit couldn't open it - the error above posted occurs.
I'm doing other tests in Production Server.
The file is opened in PDF-XChanged Editor - one that I could install in the Production Server, with this warning:
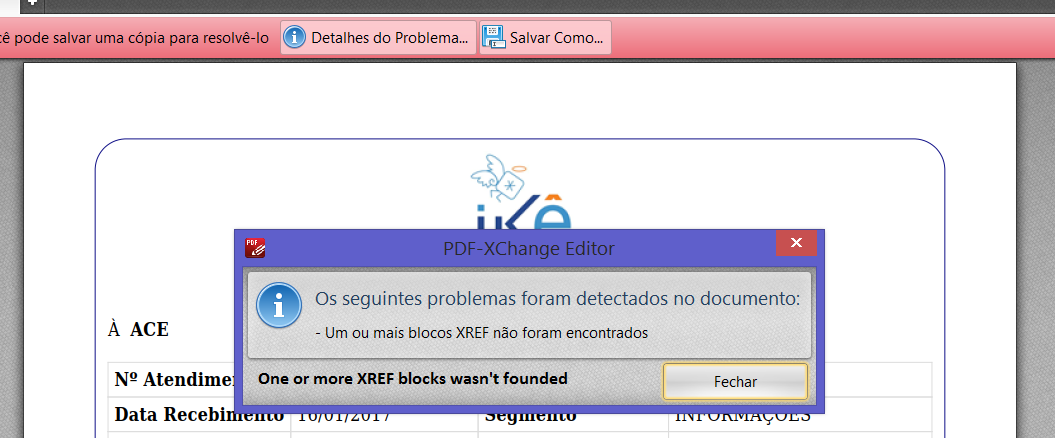
Foxit couldn't open it - the error above posted occurs.
I'm doing other tests in Production Server.
ASKER
During the Production Server tests
The PDF is generated... but
If opened directly in the browser after it's been generated...
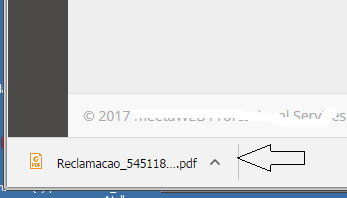
an error occurs:
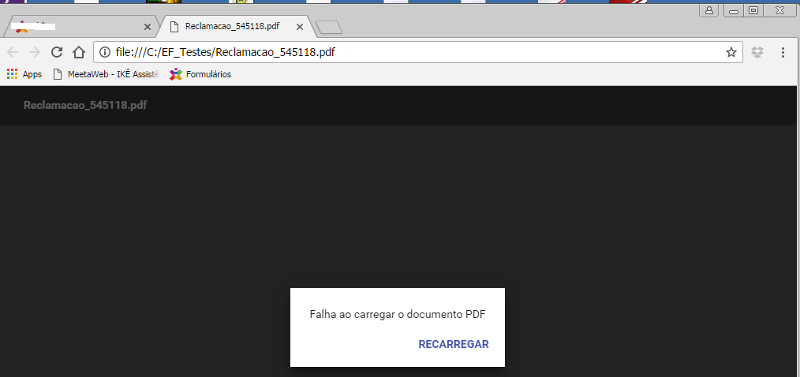
But if opened in the folder, ok with warnings:
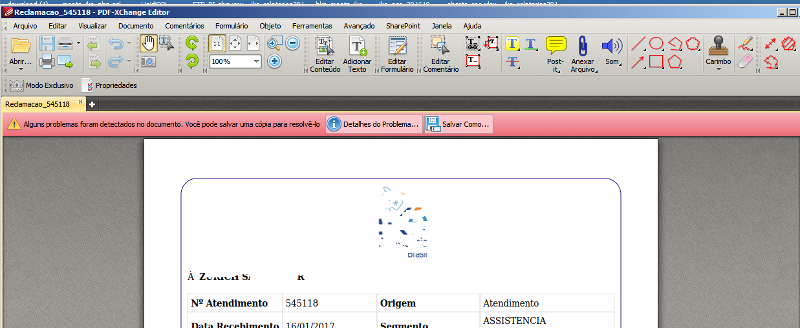
The PDF is generated... but
If opened directly in the browser after it's been generated...
an error occurs:
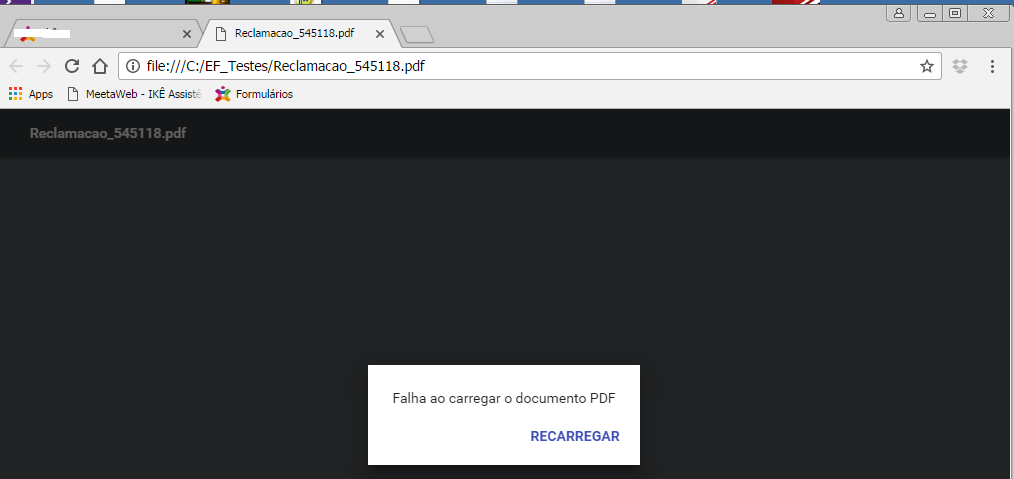
But if opened in the folder, ok with warnings:
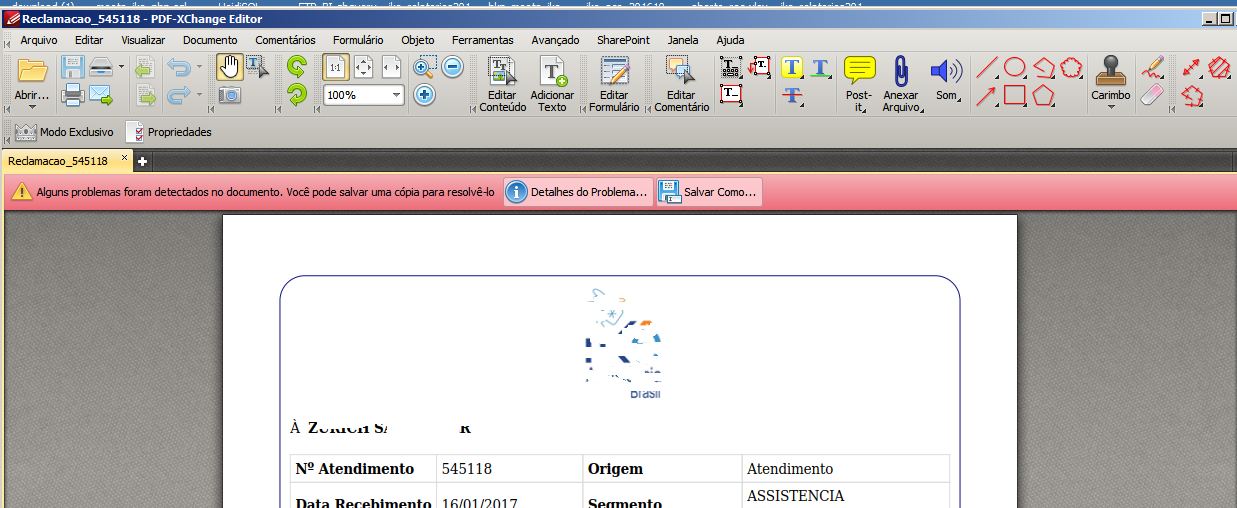
ASKER
So.. what I did is to make it opens just with the "System viewer"...
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Of course....
Here it is the PDF attatched....
It opens with warnings in PDF-XChanged Editor.
Is considered corrupted in Foxit Reader.
Reclamacao_541363--7-.pdf
Here it is the PDF attatched....
It opens with warnings in PDF-XChanged Editor.
Is considered corrupted in Foxit Reader.
Reclamacao_541363--7-.pdf
ASKER
and thanks for every one participation until now!
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
The problem appears to be you have some debug code that is happening at the start of the file.
Here is what the file looks like (the first bit)
That bit at the beginning looks like the output from print_r - find that and remove it.
Here is what the file looks like (the first bit)
stdClass Object
(
[n_atendimento] => 16
[sise] => 541363
[nome_seguradora] => ACE
[cliente] => ROMARIO SILVA
[origem] => Atendimento
[data_recebimento] => 16/01/2017
[segmento] => INFORMAÇÕES
[data_resposta] => 17/01/2017
[data_evento] => 19/01/2017
[cidade_uf] => FOZ DO IGUAÇU/PR
[motivo] => Condições Gerais
[classificacao] => Improcedente
[servico_solicitado] => INFORMAÇÃO DE PRODUTO
[reclamacao_cliente] => Gentileza verificar se houve contato deste segurado junto à Central de Atendimento 24, pois o mesmo alega que houve alagamento em sua residência no dia 30/12 e que não conseguiu atendimento na assistência
[analise_qualidade_conslusao] => Referente a este titular, verificamos que o Sr. Romário entrou em contato com a central em 02/01/2017 informando sobre o ocorrido em sua residência. Na ocasião do contato, a atendente explicou ao titular, que o mesmo estava falando com a assistência 24 h
[atendimento] => 02/01/2017
[area_acoes] =>
[responsavel] => Leliane Costa Evangelista
)
%PDF-1.4
%㤏ӊ3 0 obj
<</Type /PageThat bit at the beginning looks like the output from print_r - find that and remove it.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Oh....
Perfectly right!
A lost print_r(...)
Now everything is ok!
Thank you very much.
Perfectly right!
A lost print_r(...)
Now everything is ok!
Thank you very much.
ASKER
The amazing part is that the print_r(...) always is fired and in some cases it doesn't deny the file to be opened....
ASKER
Thank you for the help!
You saved me a lot!!!
You saved me a lot!!!
You are welcome
https://en.wikipedia.org/wiki/Byte_order_mark
http://unicode.org/faq/utf_bom.html
Can you upload a sample of the PDF that is corrupted?