Table locked in super exclusive after a failed REORG, how to exit ?
I had this question after viewing How to remove table from super exclusive lock in db2.
ASKER
Hello, i already read this topic before posting my question.
There is no solution or explanation in it.
Only people asking him more information, and the guy say he foud a solution without explaining anything.
(As many people, who when they have their problem solved, don't really care to share it).
It is Monday, and we are still in the same shit, after having restart the Database and db2 server.
Everything was fine yesterday, but today, the table is again in EXCLUSIVE LOCK mode, and unreachable.
We can not even do as SELECT ... WITH UR in it...
There is no solution or explanation in it.
Only people asking him more information, and the guy say he foud a solution without explaining anything.
(As many people, who when they have their problem solved, don't really care to share it).
It is Monday, and we are still in the same shit, after having restart the Database and db2 server.
Everything was fine yesterday, but today, the table is again in EXCLUSIVE LOCK mode, and unreachable.
We can not even do as SELECT ... WITH UR in it...
The Z lock is absolute. It allows DB2 to perform operations faster than user transactions by performing them in a way that temporarily leaves the table inconsistent. For example, the REORG process often moves rows within a table. When it does move rows, the indexes aren't necessarily updated in real time, so user queries would return incorrect results (or an error) because the index points to the old location of the data. If another row now occupies that slot, the wrong results could be returned. That's a really, really bad thing. If that slot is empty, an error occurs because the index and data are inconsistent. Many of these system level operations bypass the normal logging done by user statements so there's little or no chance to know exactly what the data should look like. (If a row is being moved, is the normal flow to copy it to the new location then remove it from the old? If so, the data temporarily exists in two locations. If the normal flow is to delete it from the old location, keeping it in memory, then inserting it in the new location, the data temporarily exists nowhere in the database.) In either of these scenarios it may be impossible to tell what the data should look like.
There is no "release a Z lock" command. That would leave the table in an unusable state as the table would be inconsistent, as would the table indexes. The normal approach to dealing with an inconsistent table is to delete it and restore it. It sounds like you want to avoid that. But since there is no command to release the lock and you don't want to delete the table, you'll need to follow the steps shown in the other thread. Once we know more details on the offending task we may be able to help get you over this.
Tracking through the DB2 listings (as suggested in the other thread) should get us to the offending task. It may be impossible for us to correct. Some of the IBM super tools may be able to patch the data and clear the lock, but that's pretty severe.
There is no "release a Z lock" command. That would leave the table in an unusable state as the table would be inconsistent, as would the table indexes. The normal approach to dealing with an inconsistent table is to delete it and restore it. It sounds like you want to avoid that. But since there is no command to release the lock and you don't want to delete the table, you'll need to follow the steps shown in the other thread. Once we know more details on the offending task we may be able to help get you over this.
Tracking through the DB2 listings (as suggested in the other thread) should get us to the offending task. It may be impossible for us to correct. Some of the IBM super tools may be able to patch the data and clear the lock, but that's pretty severe.
ASKER
That was a dbreorg who failed, letting the table in this 'super exclusive lock' state.
For now :
Restart of db2 instance
Restart of server
Launch again a reorg on table
Failed immediately with error -668
So launch of a reorg with command 'inplace stop'
"Reorg table schema.table inplace stop"
U
Reorg is in progress...
I'll let you know...
For now :
Restart of db2 instance
Restart of server
Launch again a reorg on table
Failed immediately with error -668
So launch of a reorg with command 'inplace stop'
"Reorg table schema.table inplace stop"
U
Reorg is in progress...
I'll let you know...
Good Luck! (I've never had to do this on any of my production systems.)
The inconsistency is really strange and suggests perhaps a DB2 or hardware error. Have you checked your server logs to see if an event was recorded about the time the hang occurred?
The "Reorg table schema.table inplace stop" stood a better chance of succeeding before the restarts. :( I hope recovery is possible!!!
The inconsistency is really strange and suggests perhaps a DB2 or hardware error. Have you checked your server logs to see if an event was recorded about the time the hang occurred?
The "Reorg table schema.table inplace stop" stood a better chance of succeeding before the restarts. :( I hope recovery is possible!!!
A few notes that might help you avoid this problem in the future.
1) The need for a REORG suggests that the data in that table is rather dynamic -- there are a significant number of UPDATE and/or DELETE statements that result in data being moved or deleted and "holes" in the table. Is the REORG being run to improve performance or to reduce the size of the table? There are trade-offs that you need to keep in mind. If the data is sparse throughout the table pages, performance can be an issue as the pages in the bufferpool will be sparsely populated, reducing its efficiency. If a significant number of pages become empty, DB2 will just ignore them and they won't affect performance but they will continue to occupy space on disk.
2) The inplace REORG does not automatically put a Z lock on the entire table. It starts with more granular locking so user access to the table is enabled while the REORG is running. The Z lock is normally put on the table toward the end of the REORG for cleanup activities like dropping empty pages.
3) REORG does not care about LOCKTIMEOUT. It will wait forever for user locks to clear so if user updates to the table set 1 or more locks that the REORG also needs, the REORG waits. If DB2 detects a lock conflict, the REORG continues to wait until the user program rolls back. User code should COMMIT frequently to avoid this problem. Problems can also arise if the user code locks the entire table (either explicitly or through lock escalation).
4) Do you run index based REORG? If so, they will be considerably slower than a normal REORG. The restructured data may be considerably faster than a normal index, but at the expense of REORG overhead and time.
4) How often do you run a REORG? You may benefit from running them more often or less often, depending on your data, its usage, and your environment.
Kent
1) The need for a REORG suggests that the data in that table is rather dynamic -- there are a significant number of UPDATE and/or DELETE statements that result in data being moved or deleted and "holes" in the table. Is the REORG being run to improve performance or to reduce the size of the table? There are trade-offs that you need to keep in mind. If the data is sparse throughout the table pages, performance can be an issue as the pages in the bufferpool will be sparsely populated, reducing its efficiency. If a significant number of pages become empty, DB2 will just ignore them and they won't affect performance but they will continue to occupy space on disk.
2) The inplace REORG does not automatically put a Z lock on the entire table. It starts with more granular locking so user access to the table is enabled while the REORG is running. The Z lock is normally put on the table toward the end of the REORG for cleanup activities like dropping empty pages.
3) REORG does not care about LOCKTIMEOUT. It will wait forever for user locks to clear so if user updates to the table set 1 or more locks that the REORG also needs, the REORG waits. If DB2 detects a lock conflict, the REORG continues to wait until the user program rolls back. User code should COMMIT frequently to avoid this problem. Problems can also arise if the user code locks the entire table (either explicitly or through lock escalation).
4) Do you run index based REORG? If so, they will be considerably slower than a normal REORG. The restructured data may be considerably faster than a normal index, but at the expense of REORG overhead and time.
4) How often do you run a REORG? You may benefit from running them more often or less often, depending on your data, its usage, and your environment.
Kent
ASKER
We had no choice to restart the instance, because a process was in 'Rollback to savepoint' indefinitely since 24 hours (had nothing to rollback by the way), and was locking any other opération on the table , even a dbreorg.
The dbreorg encountered a -968 error, because the file system (Db2SMS) was full.
That's the reason why the Reorg crashed two days ago, and let the table locked in Super exclusive.
Our dba would have seen that more quickly, but he is in holidays, unreachable.
The solution now :
We extended the DB2SMS file from 60Go to 150Go, and restarted the DBREORG, using the option INPLACE RESUME.
It's In progress, if this solution does not work and doesn't unlock the table, maybe Beers would help ;)
The dbreorg encountered a -968 error, because the file system (Db2SMS) was full.
That's the reason why the Reorg crashed two days ago, and let the table locked in Super exclusive.
Our dba would have seen that more quickly, but he is in holidays, unreachable.
The solution now :
We extended the DB2SMS file from 60Go to 150Go, and restarted the DBREORG, using the option INPLACE RESUME.
It's In progress, if this solution does not work and doesn't unlock the table, maybe Beers would help ;)
I generally find beers, or a good bourbon, help more than they hurt. Especially when dealing with extraordinary events like this.
What's the underlying O/S? Linux, Windows, or an IBM platform? Most DBAs and/or sys admins run alert tasks that warn of low disk space.
What's the underlying O/S? Linux, Windows, or an IBM platform? Most DBAs and/or sys admins run alert tasks that warn of low disk space.
ASKER
under linux, there is admin alerts, but that was during weekend, and we had not tools of our dbadmin, now we have...
DbRerog is running since 4 hours now, seems to do several passes on rows (2.5 more reads than rows in table for now), probably for indexes...
I'll trade the bourbon for a Lussac saint Emilion when finish, French taste obligation....
DbRerog is running since 4 hours now, seems to do several passes on rows (2.5 more reads than rows in table for now), probably for indexes...
I'll trade the bourbon for a Lussac saint Emilion when finish, French taste obligation....
Since the REORG is an ONLINE type DB2 should be compacting the table by moving rows from higher numbered blocks to the lower numbered ones and eliminating empty space. When a row is moved (i.e. From block 100, slot 1 to block 52 slot 3) the old database key becomes void and the indexes that reference the old key must be updated with the new database key. If the database has a lot of indexes, this could take a while. The good news is that the entry in the index table is updated in place. (The value that is being indexed doesn't change, just the location of the row data.) But each update is overhead involving several logical reads and at least 1 logical write per index.
If you've got plenty of memory on the server, most of the I/O will be logical reads/writes, not physical.
If you've got plenty of memory on the server, most of the I/O will be logical reads/writes, not physical.
Oh, and good taste on the Lussac saint Emilion. :)
ASKER
Hi,
The Dbreorg runs for 20 hours now.
Having :
- 6.800.000.000 rows read
- 3.600.000.000 rows write (is it logical write ? more physical write no ?)
- 467.000.000 Buffer pool data logical reads
- 15.854.038 Buffer pool data physical reads
For a total of 555.000.000 rows in table, 11 indexes (the primary key and 10 indexes)
A simple calcul, for exemple 1 pass per index plus one pass 'free' give me : 555.000.000 * 12 = 6.660.000.000 of (rows to write ?)
But maybe this is a stupid calcul.
Is there not SQL requests on systables who can give a visibility on steps of Reorg ?
The Dbreorg runs for 20 hours now.
Having :
- 6.800.000.000 rows read
- 3.600.000.000 rows write (is it logical write ? more physical write no ?)
- 467.000.000 Buffer pool data logical reads
- 15.854.038 Buffer pool data physical reads
For a total of 555.000.000 rows in table, 11 indexes (the primary key and 10 indexes)
A simple calcul, for exemple 1 pass per index plus one pass 'free' give me : 555.000.000 * 12 = 6.660.000.000 of (rows to write ?)
But maybe this is a stupid calcul.
Is there not SQL requests on systables who can give a visibility on steps of Reorg ?
20 hours on the reorganization of a half billion rows. That's disappointing, but not surprising. I wish that I could tell you how long this will run, but I just have no way to know.
The 3.6B rows written is a logical count. The row is written to a block in the buffer pool. The buffer pool is later written (or rewritten) back to disk as a physical write. The greater the difference between the logical and physical counts, the more efficient the process.
IBM provides this SQL to query information about the REORG.
select
substr(tabname, 1, 15) as tab_name,
substr(tabschema, 1, 15) as tab_schema,
reorg_phase,
substr(reorg_type, 1, 20) as reorg_type,
reorg_status,
reorg_completion,
dbpartitionnum
from sysibmadm.snaptab_reorg
order by dbpartitionnum
GET SNAPSHOT FOR TABLES will get more information than you want, but it will also contain information about the REORG.
The 3.6B rows written is a logical count. The row is written to a block in the buffer pool. The buffer pool is later written (or rewritten) back to disk as a physical write. The greater the difference between the logical and physical counts, the more efficient the process.
IBM provides this SQL to query information about the REORG.
select
substr(tabname, 1, 15) as tab_name,
substr(tabschema, 1, 15) as tab_schema,
reorg_phase,
substr(reorg_type, 1, 20) as reorg_type,
reorg_status,
reorg_completion,
dbpartitionnum
from sysibmadm.snaptab_reorg
order by dbpartitionnum
GET SNAPSHOT FOR TABLES will get more information than you want, but it will also contain information about the REORG.
What version of DB2 are you running?
ASKER
9.07.0011
ASKER
select
substr(tabname, 1, 15) as tab_name,
substr(tabschema, 1, 15) as tab_schema,
reorg_phase,
substr(reorg_type, 1, 20) as reorg_type,
reorg_status,
reorg_completion,
dbpartitionnum
from sysibmadm.snaptab_reorg
order by dbpartitionnum
Returns 0 Rows, the table is empty... something must have a bad or missing parameter in database...
substr(tabname, 1, 15) as tab_name,
substr(tabschema, 1, 15) as tab_schema,
reorg_phase,
substr(reorg_type, 1, 20) as reorg_type,
reorg_status,
reorg_completion,
dbpartitionnum
from sysibmadm.snaptab_reorg
order by dbpartitionnum
Returns 0 Rows, the table is empty... something must have a bad or missing parameter in database...
ASKER
Thanks for your interest by the way
The next (obvious) question is, how old is your most recent backup? Followed by, at what point are you willing to abandon the REORG and revert to the backup?
ASKER
yeah, we have a confcall in 2 hours for that :)
We have fresh backup, but 'fresh' in the sector and the customer involved means a lot of lost datas anyway.
This is the main and most accessed table who is locked since 3 days, but other things have been inserted and done on database.
Anyway i just asked to put the last backup on another server, and we could act only on this specified table, if things go wrong on Production.
We have fresh backup, but 'fresh' in the sector and the customer involved means a lot of lost datas anyway.
This is the main and most accessed table who is locked since 3 days, but other things have been inserted and done on database.
Anyway i just asked to put the last backup on another server, and we could act only on this specified table, if things go wrong on Production.
What is the table in question, and what does it contain?
Do you have a database model that you can inspect? You'll want to make sure that restoring just the one table won't cause referential integrity issues. If not, you can query that restored database to find them.
SELECT * FROM SYSCAT.REFERENCES
Do you have a database model that you can inspect? You'll want to make sure that restoring just the one table won't cause referential integrity issues. If not, you can query that restored database to find them.
SELECT * FROM SYSCAT.REFERENCES
ASKER
Oh yes, no there is no foreign keys on this table (not yet anyway).
It contains accounting of our customer (Press editor) (accounting of each of his customers by contracts, it's entire real time life of press subscriptions)
It contains accounting of our customer (Press editor) (accounting of each of his customers by contracts, it's entire real time life of press subscriptions)
Some things to take into your meeting.
- The lack of a shown status for the REORG is troubling. The REORG process works in phases and the REORG and its status should be recorded and viewable.
- The command that you're running is a REORG ... STOP. I don't know how long it will run, or if it will ever stop gracefully. Nor can we tell if the database will be usable when/if it does stop. (We hope so, but the interruption by the DISK FULL condition and reboot may have left corruption in the table.)
- 24 hours for a STOP suggests something to be very wrong. Some cleanup activity is to be expected, but this is extreme.
- Review the scenarios of trying to restore just this one table, especially from a business perspective. What happens if other tables contain items that are missing from this table?
- The lack of a shown status for the REORG is troubling. The REORG process works in phases and the REORG and its status should be recorded and viewable.
- The command that you're running is a REORG ... STOP. I don't know how long it will run, or if it will ever stop gracefully. Nor can we tell if the database will be usable when/if it does stop. (We hope so, but the interruption by the DISK FULL condition and reboot may have left corruption in the table.)
- 24 hours for a STOP suggests something to be very wrong. Some cleanup activity is to be expected, but this is extreme.
- Review the scenarios of trying to restore just this one table, especially from a business perspective. What happens if other tables contain items that are missing from this table?
ASKER
The command was finally REORG INSTOP RESUME (not STOP)
And the files (DB2SMS and others) are no longer really solicited, the file was filled only in the first step of Reorg.
There is no problem for datas who could be inserted in this table after others, this is already the case sometimes.
Accounting engine who insert in this table is the last step, and can be done when we want, all what he needs is stored somewhere else, in another table, which is safe.
By the way, i'm just the conceptor of this accounting 'Engine', and have to manage everyday with this huge table, but after that maybe i will assist our beloved Dba, as i always have been interested in the efficiency of databases, and of what i can call 'my' table on each database :)
And the files (DB2SMS and others) are no longer really solicited, the file was filled only in the first step of Reorg.
There is no problem for datas who could be inserted in this table after others, this is already the case sometimes.
Accounting engine who insert in this table is the last step, and can be done when we want, all what he needs is stored somewhere else, in another table, which is safe.
By the way, i'm just the conceptor of this accounting 'Engine', and have to manage everyday with this huge table, but after that maybe i will assist our beloved Dba, as i always have been interested in the efficiency of databases, and of what i can call 'my' table on each database :)
I'm assuming that you meant INPLACE, not INSTOP. :)
Early in the discussion you'd posted:
"Reorg table schema.table inplace stop"
So I thought DB2 had been working for a full day trying to terminate the REORG.
But your comment suggests that REORG ... RESUME has been running for 24 hours. You can try REORG ... STOP to terminate the REORG. If the table is intact, the REORG should end gracefully and remove the Z lock. Note that you'll want to leave the current task running, and execute the REORG ... STOP from another connection.
Early in the discussion you'd posted:
"Reorg table schema.table inplace stop"
So I thought DB2 had been working for a full day trying to terminate the REORG.
But your comment suggests that REORG ... RESUME has been running for 24 hours. You can try REORG ... STOP to terminate the REORG. If the table is intact, the REORG should end gracefully and remove the Z lock. Note that you'll want to leave the current task running, and execute the REORG ... STOP from another connection.
ASKER
The REORG INPLACE STOP was ouf first attempt, who failed (again) when the DB2SMS was 100% full, that was the cause of the first crash but we didn't know at this time.
The command STOP didn't stop anything, but was reading reading reading...
After extending the DB2SMS file, we launched REORG INPLACE RESUME, still in progress.
For now, we don't want to stop the RESUME.
You suggest to do a REORG INPLACE STOP anyway from another connection ?
I'm a little bit afraid of that...
The command STOP didn't stop anything, but was reading reading reading...
After extending the DB2SMS file, we launched REORG INPLACE RESUME, still in progress.
For now, we don't want to stop the RESUME.
You suggest to do a REORG INPLACE STOP anyway from another connection ?
I'm a little bit afraid of that...
If the STOP is successful, the REORG ends gracefully with its work left in a stable state. The table and indexes may not be 100% packed, but they will be better than they were before the REORG and usable. You can always initiate another REORG at any time.
But I'm still concerned that running out of space may have left corruption that REORG will not correct. Your down time is now measured in days and there's no way to tell when or if the current REORG will end.
But I'm still concerned that running out of space may have left corruption that REORG will not correct. Your down time is now measured in days and there's no way to tell when or if the current REORG will end.
ASKER
Well, it could be a good option, definitely, as i'm starting to think it will never end.
I'm gonna talk about that to my fellows.
it Seems i can trust you my friend, as you're not a rookie.
Anyway, no tries, no fails , but neither no success ;)
I'm gonna talk about that to my fellows.
it Seems i can trust you my friend, as you're not a rookie.
Anyway, no tries, no fails , but neither no success ;)
>> you're not a rookie.
Well, the politically incorrect term is "gray beard". :) But the reality is that I've been in the business longer than SQL has been a thing.
Well, the politically incorrect term is "gray beard". :) But the reality is that I've been in the business longer than SQL has been a thing.
ASKER
Haha, i'm gonna name you OBI-WAN KENOBI
Once you're back online, your organization might want to rethink its strategy on running REORG.
From what little I know about this table, it sounds like rows are added frequently. They are probably never (or seldomly) removed nor are they updated in a way that affects indexed columns.
If that's correct, the only reason to run REORG on the table would be to restructure the data into the order of a specific key column.
Some of the indexes will likely need to have REORG run on them. An indexed identity or (current) time stamp always store values that are greater than any existing item in the column. The index b-tree tends to skew with lookups for more recent items requiring searching through more index pages. A REORG on that index will balance the b-tree and result in approximately the same search time regardless of the value. Data with a certain randomness to it (names, addresses, etc.) will often (usually) require their indexes to be rebalanced less frequently than columns that store increasing values.
Run REORGCHK occasionally to see if any items need to be reorganized.
From what little I know about this table, it sounds like rows are added frequently. They are probably never (or seldomly) removed nor are they updated in a way that affects indexed columns.
If that's correct, the only reason to run REORG on the table would be to restructure the data into the order of a specific key column.
Some of the indexes will likely need to have REORG run on them. An indexed identity or (current) time stamp always store values that are greater than any existing item in the column. The index b-tree tends to skew with lookups for more recent items requiring searching through more index pages. A REORG on that index will balance the b-tree and result in approximately the same search time regardless of the value. Data with a certain randomness to it (names, addresses, etc.) will often (usually) require their indexes to be rebalanced less frequently than columns that store increasing values.
Run REORGCHK occasionally to see if any items need to be reorganized.
ASKER
Hi,
The REORG INPLACE RESUME finally ended during the night, so it lasted something between 33 and 38 hours, i'll try to know exactly.
It ended with an error -668, but i think he had finished everything , then tried to change the state of the table.
I ran a SET INTEGRITY IMMEDIATE CHECKED command, and it worked instantly, making table accessible.
Everything works fine, very fast.
I'll update this topic later, with all elements, in a synthesis.
Many thanks Kdo for your advices and explanations, you have been much better than the IBM support (really awful), and made me feel less alone :)
I'll come back later
(And sorry for my approximate English sometimes)
The REORG INPLACE RESUME finally ended during the night, so it lasted something between 33 and 38 hours, i'll try to know exactly.
It ended with an error -668, but i think he had finished everything , then tried to change the state of the table.
I ran a SET INTEGRITY IMMEDIATE CHECKED command, and it worked instantly, making table accessible.
Everything works fine, very fast.
I'll update this topic later, with all elements, in a synthesis.
Many thanks Kdo for your advices and explanations, you have been much better than the IBM support (really awful), and made me feel less alone :)
I'll come back later
(And sorry for my approximate English sometimes)
Hey! Congratulations!!!! I really expected the worst here, and when you said the REORG ended with an error -668 my heart sank a little bit.
And your English is fine. I wouldn't know it's your second language except for the spelling of your name! :)
Kent
And your English is fine. I wouldn't know it's your second language except for the spelling of your name! :)
Kent
ASKER
Yes, i'm definitely french :)
The table is very fast now (Fortunately), and after the results i collected, i know now what to read in DB2Mon to know when a Reorg will finish (at least what is the particular value expected).
I'll post that tomorrow, for now i'm exhausted, and i taste finally my bottle of wine (the very good one ;)
The table is very fast now (Fortunately), and after the results i collected, i know now what to read in DB2Mon to know when a Reorg will finish (at least what is the particular value expected).
I'll post that tomorrow, for now i'm exhausted, and i taste finally my bottle of wine (the very good one ;)
I'm too far away to join you, so I'll toast your success in my own way here. :)
ASKER
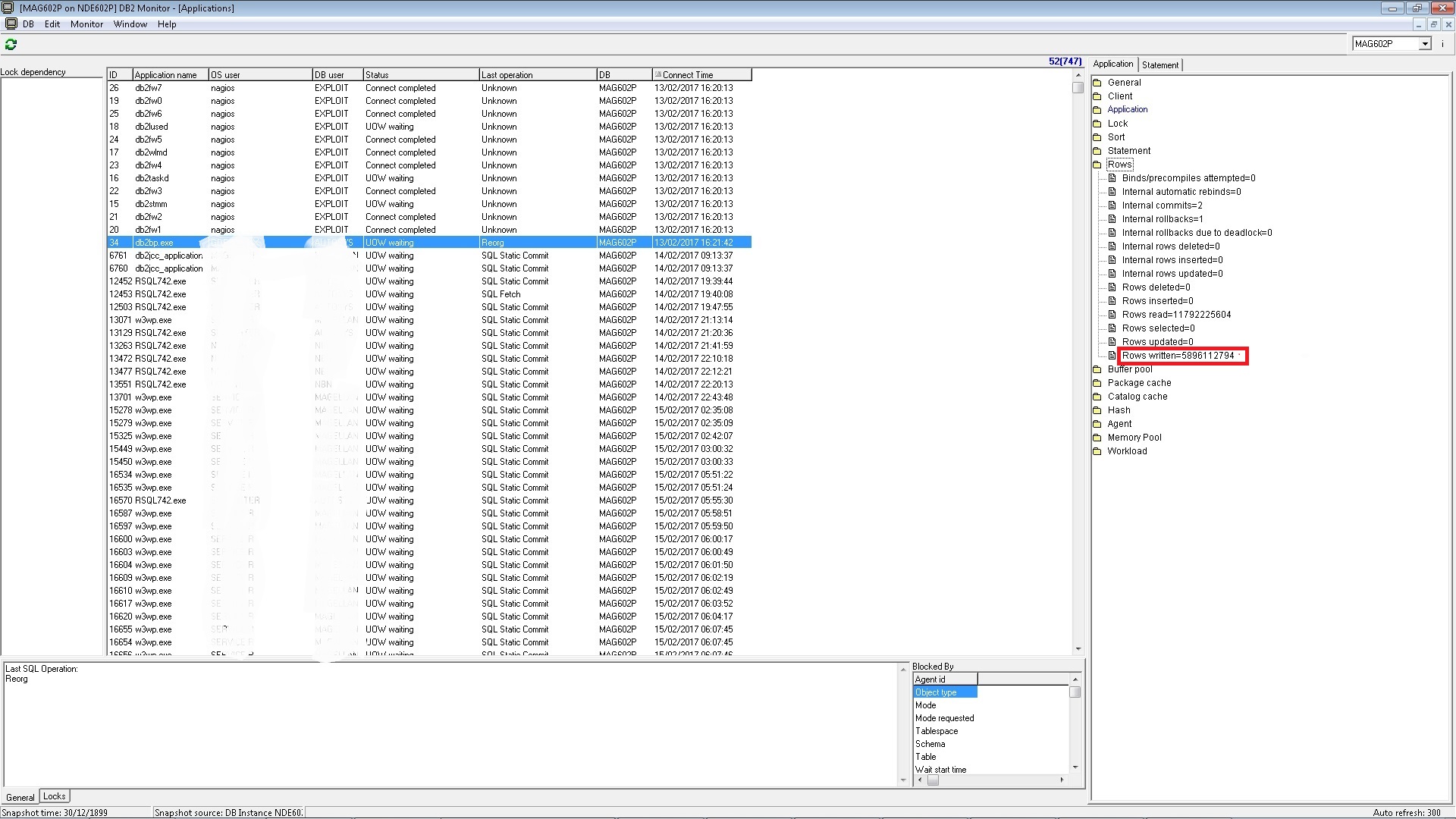
So the value to read in db2mon, in the 'rows' tab, is the number of 'Row written', the last one.
My table had 536billions rows, and 11 indexes (The primary key and 10 indexes)
The final number of 'Rows written' was : 536.000.000 x 11 = 5.896.000.000 rows written.
That is what to expect for the Reorg operation on a table.
I'll post the screenshot tomorrow...
My table had 536billions rows, and 11 indexes (The primary key and 10 indexes)
The final number of 'Rows written' was : 536.000.000 x 11 = 5.896.000.000 rows written.
That is what to expect for the Reorg operation on a table.
I'll post the screenshot tomorrow...
ASKER
And the Buffer Pool Tab, just for information, but i have no deduction about it

The buffer pool is where all the magic happens. :) It's just a bunch of memory that DB2 uses to hold the things it's working on.
Right out of the box, most database engines default to 4K blocks, DB2 included. (I don't know of any vendor that defaults to any other size, but it's possible.) I've never seen a database where 4K blocks perform better than 8, 16, or 32K blocks, but that's a discussion for another time... Anyway, if DB2 has 1GB reserved for the buffer pool there are 250,000 4K blocks in the pool. (If there are multiple databases in the instance with different block sizes, there will be buffer pools for each size block. DB2 won't share blocks to databases using a different block size.) When data is read from any of the tables it is put in the buffer pool where DB2 uses it to satisfy a query, or a step in a query. It usually remains in the buffer pool for an extended period of time and if another query needs that same block DB2 reuses the data from the buffer pool instead of re-reading the block from disk. (All database engines use this same general technique.)
The top 2 lines of the buffer pool statistics show that DB2 performed 764 million data reads (from the buffer pool). It placed data in the buffer pool by doing 27 million reads from disk. On average, data in the buffer pool was used 28 times for each read from disk.
The buffer pool numbers for index usage don't seem reasonable to me. I'm wondering if your version of DB2MON is a 32-bit application and the counters have overflowed?
The buffer pool temp space usage looks great. 123 million logical reads on only 13,000 physical reads. That's nearly 10,000 logical reads per physical read. Ideally, you don't want physical reads to/from temp, but I won't complain about a 10,000 to 1 usage rate on a database that I don't know!
Now that this is behind you, you probably won't do a full REORG in the foreseeable future. :) Was the REORG moving the data to organize it by one of the indexes (e.g. the PRIMARY key or a clustering key)? If so, that calls into question the database structure. Is the defined primary key really a primary key (in logical terms) or is a unique index more appropriate? The tables in an OLTP are usually organized for the most efficient writes, not reads. Even if this restructuring gives you better reporting time, watch closely for write issues. You could see user complaints of application timeout or hangs while making updates.
You can also run REORG in smaller chunks. Run an online REORG during off hours and let it run for a while, then do a REORG STOP to end it gracefully. If you need to again run a full REORG on the table, you'll probably see much better performance by dropping all of the indexes (except on the primary key) before the REORG. Then rebuild the indexes when the REORG completes. With a half-billion rows in the table you've clearly got a lot more data than buffer pool size. The index rebuild will do a full table scan to read the row data for each key column and build the index.
Here's a little trick to help. Run all 11 CREATE INDEX statements simultaneously. By running them simultaneously, the rows will be read into the buffer pool once and all 11 index build tasks will share the data in the buffer pool. Even if these tasks bypass the buffer pool and does direct I/O you'll gain as the data will be cached along the way. Either the O/S or the SAN/disk controller cache will contain the just-read data and reuse it without a physical read from disk. If the tasks are run serially, DB2 may read the entire table from disk 11 times.
Ah. I'm rambling.... But it's for a good cause. :)
Right out of the box, most database engines default to 4K blocks, DB2 included. (I don't know of any vendor that defaults to any other size, but it's possible.) I've never seen a database where 4K blocks perform better than 8, 16, or 32K blocks, but that's a discussion for another time... Anyway, if DB2 has 1GB reserved for the buffer pool there are 250,000 4K blocks in the pool. (If there are multiple databases in the instance with different block sizes, there will be buffer pools for each size block. DB2 won't share blocks to databases using a different block size.) When data is read from any of the tables it is put in the buffer pool where DB2 uses it to satisfy a query, or a step in a query. It usually remains in the buffer pool for an extended period of time and if another query needs that same block DB2 reuses the data from the buffer pool instead of re-reading the block from disk. (All database engines use this same general technique.)
The top 2 lines of the buffer pool statistics show that DB2 performed 764 million data reads (from the buffer pool). It placed data in the buffer pool by doing 27 million reads from disk. On average, data in the buffer pool was used 28 times for each read from disk.
The buffer pool numbers for index usage don't seem reasonable to me. I'm wondering if your version of DB2MON is a 32-bit application and the counters have overflowed?
The buffer pool temp space usage looks great. 123 million logical reads on only 13,000 physical reads. That's nearly 10,000 logical reads per physical read. Ideally, you don't want physical reads to/from temp, but I won't complain about a 10,000 to 1 usage rate on a database that I don't know!
Now that this is behind you, you probably won't do a full REORG in the foreseeable future. :) Was the REORG moving the data to organize it by one of the indexes (e.g. the PRIMARY key or a clustering key)? If so, that calls into question the database structure. Is the defined primary key really a primary key (in logical terms) or is a unique index more appropriate? The tables in an OLTP are usually organized for the most efficient writes, not reads. Even if this restructuring gives you better reporting time, watch closely for write issues. You could see user complaints of application timeout or hangs while making updates.
You can also run REORG in smaller chunks. Run an online REORG during off hours and let it run for a while, then do a REORG STOP to end it gracefully. If you need to again run a full REORG on the table, you'll probably see much better performance by dropping all of the indexes (except on the primary key) before the REORG. Then rebuild the indexes when the REORG completes. With a half-billion rows in the table you've clearly got a lot more data than buffer pool size. The index rebuild will do a full table scan to read the row data for each key column and build the index.
Here's a little trick to help. Run all 11 CREATE INDEX statements simultaneously. By running them simultaneously, the rows will be read into the buffer pool once and all 11 index build tasks will share the data in the buffer pool. Even if these tasks bypass the buffer pool and does direct I/O you'll gain as the data will be cached along the way. Either the O/S or the SAN/disk controller cache will contain the just-read data and reuse it without a physical read from disk. If the tasks are run serially, DB2 may read the entire table from disk 11 times.
Ah. I'm rambling.... But it's for a good cause. :)
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Kent Olsen had good answers and advices,
Thanks to him
Thanks to him
Luckily, this question has already been answered here at Experts Exchange. The explanation is a bit long so I'll refer you to the original question and answer.
https://www.experts-exchange.com/questions/26449737/How-to-remove-table-from-super-exclusive-lock-in-db2.html?anchorAnswerId=33597854#a33597854
Good Luck!
Kent