25112
asked on
sql server combine multiple row columns into 1 (SQL 2012)
if there is a query result and only in one column the result gets duplicated, is there a way to combine just that column details by seperated by commas
example:
1,2,3,4,5,'CODE1','Pennsyv
1,2,3,4,5,'CODE1','Ohio'
1,2,3,4,5,'CODE1','Califor
18,0,3,4,5,'CODE12,'Nev'
2,11,3,4,5,'CODE3','CO'
4,22,6,4,5,'CODE4','Florid
11,2,3,5,'CODE5','MN'
result to be:
1,2,3,4,5,'CODE1','Pennsyv
18,0,3,4,5,'CODE2','Nev'
2,11,3,4,5,'CODE3','CO'
4,22,6,4,5,'CODE4','Florid
11,2,3,5,'CODE5','MN'
the query format is
SELECT <8 columns>
from
4 InnerJoins
WHERE 3 Conditions
can you guide how to just concatenate the specific column if there are more than one row for a specific code?
example:
1,2,3,4,5,'CODE1','Pennsyv
1,2,3,4,5,'CODE1','Ohio'
1,2,3,4,5,'CODE1','Califor
18,0,3,4,5,'CODE12,'Nev'
2,11,3,4,5,'CODE3','CO'
4,22,6,4,5,'CODE4','Florid
11,2,3,5,'CODE5','MN'
result to be:
1,2,3,4,5,'CODE1','Pennsyv
18,0,3,4,5,'CODE2','Nev'
2,11,3,4,5,'CODE3','CO'
4,22,6,4,5,'CODE4','Florid
11,2,3,5,'CODE5','MN'
the query format is
SELECT <8 columns>
from
4 InnerJoins
WHERE 3 Conditions
can you guide how to just concatenate the specific column if there are more than one row for a specific code?
You need to use the XML data type and to unpack it explicitly:
Otherwise the output for <> would be lt;gt;.
DECLARE @Sample TABLE
(
A INT ,
B INT ,
C INT ,
D INT ,
E INT ,
Code NVARCHAR(255) ,
[State] NVARCHAR(255)
);
INSERT INTO @Sample
VALUES ( 1, 2, 3, 4, 5, 'CODE1', 'Pennsyvania' ) ,
( 1, 2, 3, 4, 5, 'CODE1', 'Ohio' ) ,
( 1, 2, 3, 4, 5, 'CODE1', 'California' ) ,
( 18, 0, 3, 4, 5, 'CODE12', 'Nev' ) ,
( 2, 11, 3, 4, 5, 'CODE3', 'CO' ) ,
( 4, 22, 6, 4, 5, 'CODE4', 'Florida' ) ,
( 3, 11, 2, 3, 5, 'CODE5', '<>' );
SELECT S.A ,
S.B ,
S.C ,
S.D ,
S.E ,
S.Code ,
STUFF(( SELECT ', ' + I.State
FROM @Sample I
WHERE I.A = S.A
AND I.A = S.A
AND I.B = S.B
AND I.C = S.C
AND I.D = S.D
AND I.E = S.E
AND I.Code = S.Code
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)') , 1 , 2 , ''
) AS States
FROM @Sample S
GROUP BY S.A ,
S.B ,
S.C ,
S.D ,
S.E ,
S.Code;Otherwise the output for <> would be lt;gt;.
ASKER
thanks.
is the XML PATH('')), 1, 1, '') [Sharath]
and
XML PATH(''), TYPE).value [ste5an]
syntax difference two totally different concepts?
is the XML PATH('')), 1, 1, '') [Sharath]
and
XML PATH(''), TYPE).value [ste5an]
syntax difference two totally different concepts?
Have you tested it?
No, they are not different concepts, cause both use the same approach to concatenate rows into columns. But Sharat's solution ignored the fact, that the domain can under some circumstances contain special characters, which require different handling.
Same data, but different output:
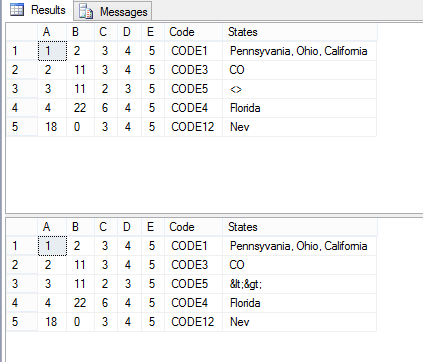
No, they are not different concepts, cause both use the same approach to concatenate rows into columns. But Sharat's solution ignored the fact, that the domain can under some circumstances contain special characters, which require different handling.
Same data, but different output:
DECLARE @Sample TABLE
(
A INT ,
B INT ,
C INT ,
D INT ,
E INT ,
Code NVARCHAR(255) ,
[State] NVARCHAR(255)
);
INSERT INTO @Sample
VALUES ( 1, 2, 3, 4, 5, 'CODE1', 'Pennsyvania' ) ,
( 1, 2, 3, 4, 5, 'CODE1', 'Ohio' ) ,
( 1, 2, 3, 4, 5, 'CODE1', 'California' ) ,
( 18, 0, 3, 4, 5, 'CODE12', 'Nev' ) ,
( 2, 11, 3, 4, 5, 'CODE3', 'CO' ) ,
( 4, 22, 6, 4, 5, 'CODE4', 'Florida' ) ,
( 3, 11, 2, 3, 5, 'CODE5', '<>' );
SELECT S.A ,
S.B ,
S.C ,
S.D ,
S.E ,
S.Code ,
STUFF(( SELECT ', ' + I.State
FROM @Sample I
WHERE I.A = S.A
AND I.A = S.A
AND I.B = S.B
AND I.C = S.C
AND I.D = S.D
AND I.E = S.E
AND I.Code = S.Code
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)') , 1 , 2 , '' ) AS States
FROM @Sample S
GROUP BY S.A ,
S.B ,
S.C ,
S.D ,
S.E ,
S.Code;
SELECT S.A ,
S.B ,
S.C ,
S.D ,
S.E ,
S.Code ,
STUFF(( SELECT ', ' + I.State
FROM @Sample I
WHERE I.A = S.A
AND I.A = S.A
AND I.B = S.B
AND I.C = S.C
AND I.D = S.D
AND I.E = S.E
AND I.Code = S.Code
FOR XML PATH('')
) , 1 , 2 , '' ) AS States
FROM @Sample S
GROUP BY S.A ,
S.B ,
S.C ,
S.D ,
S.E ,
S.Code;ASKER
thank you. that helps to know to watch for those kind of characters.. I tested it and it works beautiful..
pl consider this scenario:
INSERT INTO @Sample
VALUES ( 1, 2, 3, 4, 5, 'CODE1', 'Pennsyvania' ) ,
( 1, 2, 3, 4, 5, 'CODE1', 'Ohio' ) ,
( 1, 2, 3, 4, 5, 'CODE1', 'Ohio' ) ,
( 1, 2, 3, 4, 5, 'CODE1', '' ) ,
( 1, 2, 3, 4, 5, 'CODE1', 'California' ) ,
( 18, 0, 3, 4, 5, 'CODE12', 'Nev' ) ,
( 2, 11, 3, 4, 5, 'CODE3', 'CO' ) ,
( 4, 22, 6, 4, 5, 'CODE4', 'Florida' ) ,
( 3, 11, 2, 3, 5, 'CODE5', '<>' );
is there a way to avoid duplicates or blanks?
this will give
Pennsyvania, Ohio, Ohio, , California
can it still be constrained to the original and more meaningful
Pennsyvania, Ohio, California
data output?
pl consider this scenario:
INSERT INTO @Sample
VALUES ( 1, 2, 3, 4, 5, 'CODE1', 'Pennsyvania' ) ,
( 1, 2, 3, 4, 5, 'CODE1', 'Ohio' ) ,
( 1, 2, 3, 4, 5, 'CODE1', 'Ohio' ) ,
( 1, 2, 3, 4, 5, 'CODE1', '' ) ,
( 1, 2, 3, 4, 5, 'CODE1', 'California' ) ,
( 18, 0, 3, 4, 5, 'CODE12', 'Nev' ) ,
( 2, 11, 3, 4, 5, 'CODE3', 'CO' ) ,
( 4, 22, 6, 4, 5, 'CODE4', 'Florida' ) ,
( 3, 11, 2, 3, 5, 'CODE5', '<>' );
is there a way to avoid duplicates or blanks?
this will give
Pennsyvania, Ohio, Ohio, , California
can it still be constrained to the original and more meaningful
Pennsyvania, Ohio, California
data output?
Better: Just do a GROUP BY over all columns before concatenating in your original query.
Or not that good: Do it in the concat itself.
Or not that good: Do it in the concat itself.
DECLARE @Sample TABLE
(
A INT ,
B INT ,
C INT ,
D INT ,
E INT ,
Code NVARCHAR(255) ,
[State] NVARCHAR(255)
);
INSERT INTO @Sample
VALUES ( 1, 2, 3, 4, 5, 'CODE1', 'Pennsyvania' ) ,
( 1, 2, 3, 4, 5, 'CODE1', 'Ohio' ) ,
( 1, 2, 3, 4, 5, 'CODE1', 'Ohio' ) ,
( 1, 2, 3, 4, 5, 'CODE1', 'California' ) ,
( 18, 0, 3, 4, 5, 'CODE12', 'Nev' ) ,
( 2, 11, 3, 4, 5, 'CODE3', 'CO' ) ,
( 4, 22, 6, 4, 5, 'CODE4', 'Florida' ) ,
( 3, 11, 2, 3, 5, 'CODE5', '<>' );
SELECT S.A ,
S.B ,
S.C ,
S.D ,
S.E ,
S.Code ,
STUFF(( SELECT ', ' + I.State
FROM @Sample I
WHERE I.A = S.A
AND I.A = S.A
AND I.B = S.B
AND I.C = S.C
AND I.D = S.D
AND I.E = S.E
AND I.Code = S.Code
GROUP BY I.State
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)') ,
1 ,
2 ,
''
) AS States
FROM @Sample S
GROUP BY S.A ,
S.B ,
S.C ,
S.D ,
S.E ,
S.Code;
@ste5an
You don't need to GROUP BY, remove it and use DISTINCT in the select list:
You don't need to GROUP BY, remove it and use DISTINCT in the select list:
SELECT DISTINCT
S.A ,
S.B ,
S.C ,
S.D ,
S.E ,
S.Code ,
STUFF(( SELECT ', ' + I.State
FROM @Sample I
WHERE I.A = S.A
AND I.A = S.A
AND I.B = S.B
AND I.C = S.C
AND I.D = S.D
AND I.E = S.E
AND I.Code = S.Code
GROUP BY I.State
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)') ,
1 ,
2 ,
''
) AS States
FROM @Sample S
Search for T-SQL GROUP BY vs DISTINCT.. e.g.
Performance Surprises and Assumptions : GROUP BY vs. DISTINCT
GROUP BY v DISTINCT (group by wins!)
And it must either be in the query supporting the data or the FOR XML query. But not in the outer select.
Performance Surprises and Assumptions : GROUP BY vs. DISTINCT
GROUP BY v DISTINCT (group by wins!)
And it must either be in the query supporting the data or the FOR XML query. But not in the outer select.
Doesn't apply in this case. I bet the plan is the same! The article actually says: "Well, in this simple case, it's a coin"
I say to stick ti simple and intuitive.
I say to stick ti simple and intuitive.
ASKER
works as intended..
any thoughts on how to remove the first comma (when there is a blank field)
any thoughts on how to remove the first comma (when there is a blank field)
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
thanks for the additional perspective(s) and the warning to watch the data model.
appreciated..
appreciated..
I don't think is fair that I even get any points, let alone to be split in half with ste5an. He gave the solution, I only made a remark... Please give ste5an all the points, if possible.
ASKER
you are a gentleman..
I wish the older system where you can assign points..
ste5an' shared artlcle on Performance Surprises and Assumptions was eye-opening
I wish the older system where you can assign points..
ste5an' shared artlcle on Performance Surprises and Assumptions was eye-opening
Open in new window