Performance Issue with SQL Update Query
Problem Statement : I have a performance issue with the Update query , I am able to update the data (100 Million rows) for one calendar day , but unable to update the data for 5 or 10 calendar days (1 Billion Rows ) , because the data volume in the tables is so huge.
Please Note : All the indexes are in place , have enough I/O , RAM and CPU including the TEMPDB space
So please fine tune this query(attached) and this statement is causing the issue . Will appreciate your quick reply in this regard.
Thanks,
SRK
Please Note : All the indexes are in place , have enough I/O , RAM and CPU including the TEMPDB space
So please fine tune this query(attached) and this statement is causing the issue . Will appreciate your quick reply in this regard.
Thanks,
SRK
Jim Horn
The attachment is missing, and please post T-SQL inside a CODE block (toolbar, third button from the right) and not as an attached file.
We know that you said all indexes and resources are in place but we don't know how you've confirmed that.
So please attach the query plan and tell us about the server configuration and resources.
So please attach the query plan and tell us about the server configuration and resources.
When it comes to update the indexes actually make the operation slower because beside the table itself the indexes containing any of the updated columns have to be maintained as well, which means page update, split and writing on the disk. If the table is large and a lot of rows are affected it cold mean a long big transaction that will affect any other table interactions so it is preferable to write a script that will run in a loop that will work with a smaller number of rows at a time.
<Was originally thinking this but didn't verbalize it in my first comment>
- Are you really certain you want to run an UPDATE on a billion rows??
- Can this process be redesigned so you don't have 100 million rows for every day?
- Will running this update block any other important processes?
- Do you have your resume updated if this fails and causes unintended consequences?
ASKER
Hi Experts ,
Here is the update query attached having the performance issue and also the execution plan also attached.
Please optimize the query for better performance and help me with the solution.
At the moment , there are no partitions defined on any of the tables used in the update query , so can I use daily partitions on all the tables and that will minimize the result set of the update query , please provide me the performance pointers and also walk me through the solution on how to optimize the query to update in small chunks .
Note : Update is happening on millions of rows and I want to minimize that result set for better performance , does partitioned tables help here , please suggest me the best solution and send me the optimized query ?
Thanks,
SRK>
Update_query.sql
ds_update_mba_related_metrics_3_.sqlplan
Here is the update query attached having the performance issue and also the execution plan also attached.
Please optimize the query for better performance and help me with the solution.
At the moment , there are no partitions defined on any of the tables used in the update query , so can I use daily partitions on all the tables and that will minimize the result set of the update query , please provide me the performance pointers and also walk me through the solution on how to optimize the query to update in small chunks .
Note : Update is happening on millions of rows and I want to minimize that result set for better performance , does partitioned tables help here , please suggest me the best solution and send me the optimized query ?
Thanks,
SRK>
Update_query.sql
ds_update_mba_related_metrics_3_.sqlplan
Try this query but then break it in a loop to work on a subset of rows at a time. I made 2 corrections, one to simplify and one that I thought it was what you actually intended.:
update related
set related_transactions_number_day =
(
Select count(distinct trans_sequence_number)
from mba_base_sales aa
where aa.calendar_day = related.calendar_day
and aa.Business_Unit_ID = related.business_unit_id
and aa.sales_item_level_id
-- ### we remove this, NOT IN being a less optimal condition but we will tweak the IN condition to accomopdate the same results
--not in
-- (
-- select c.child_sales_item_level_id
-- from mba_sales_item_desc c
-- where
-- c.sales_item_level_id = related.sales_item_id
-- and c.sales_item_level_number = related.sales_item_hierarchy_level
-- and c.child_sales_item_level_number = 6
-- )
and aa.sales_item_level_id
in
(
select c.child_sales_item_level_id
from mba_sales_item_desc c
where c.sales_item_level_id = related.related_sales_item_id
-- ### adding these 2 conditions here will replace the whole subquery needed for the NOT IN condition; all the tables and conditions being the same; you rather use one IN than an IN combined with NOT IN on the same values coming from the same tables!
and c.sales_item_level_id <> related.sales_item_id
and c.sales_item_level_number <> related.sales_item_hierarchy_level
and c.sales_item_level_number = related.related_sales_item_hierarchy_level
and c.child_sales_item_level_number = 6
)
and aa.sales_item_level_number = 6
and aa.datasource_id = related.datasource_id
and trans_sequence_number
in
(
Select distinct trans_sequence_number
from mba_base_sales aa1
where aa1.calendar_day = related.calendar_day
and aa1.Business_Unit_ID = aa.business_unit_id
and aa1.sales_item_level_id in
(
select c.child_sales_item_level_id
from mba_sales_item_desc c
where c.sales_item_level_id = related.sales_item_id
and c.sales_item_level_number = related.sales_item_hierarchy_level
and c.child_sales_item_level_number = 6
)
and aa1.sales_item_level_number = 6
-- ### I think here you need aa1 and not just aa; why using a filter here for 2 tables that are outside this subquery
--and aa.datasource_id =related.datasource_id
and aa1.datasource_id =related.datasource_id
)
)
from mba_related_sales_by_day related
where
related.related_sales_item_hierarchy_level < related.sales_item_hierarchy_level
and related.calendar_day between @v_begin_date and @v_end_date
and related.related_sales_item_id
in
(
select c.sales_item_level_id
from mba_sales_item_desc c
where c.child_sales_item_level_id = related.sales_item_id
and c.Child_sales_item_level_number = related.sales_item_hierarchy_level
)ASKER
Thanks Zberteoc for your immediate reply .
I will try the query.
I didn't get your comment (but then break it in a loop to work on a subset of rows at a time).
Instead of 10 days , I can run for each single day and then auto increment subsequently for the next 9 days in a loop .
The lowest granular data what I have is the calendar day , how I can split further and get subset of rows at a time ?
Note : the result set of the Update statement is generating millions of rows for one calendar day , how can I minimize the data in the reult set and further split the data in to subset of rows at a time ?
I will try the query.
I didn't get your comment (but then break it in a loop to work on a subset of rows at a time).
Instead of 10 days , I can run for each single day and then auto increment subsequently for the next 9 days in a loop .
The lowest granular data what I have is the calendar day , how I can split further and get subset of rows at a time ?
Note : the result set of the Update statement is generating millions of rows for one calendar day , how can I minimize the data in the reult set and further split the data in to subset of rows at a time ?
Bases on the PK table that you are updating, in your case the mba_related_sales_by_day table. What you do first step is to isolate in a temp table all the PKs that are used in your table. I will give you an example.
ASKER
Thanks Zberteoc for immediate reply with the optimized query.
Here are the details on the volume of the data in various tables for various calendar days and also listed the primary keys , this is for your reference.
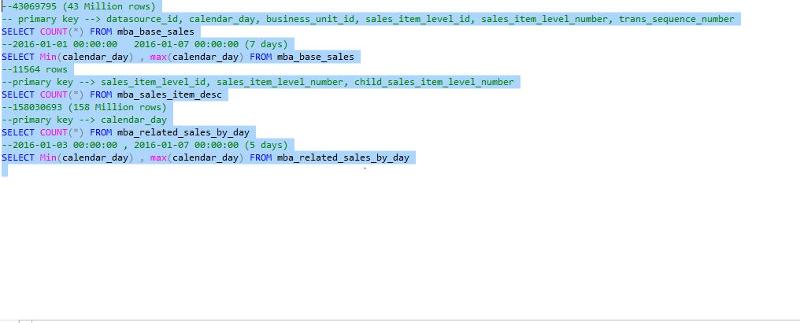
Also please advise if it is a good idea to use partitioned tables (daily partition as data volume is very high) , at the moment no partitions are defined . Will partitions help to optimize the performance and fast retrieval and hence forth update runs fast. Please correct me if I am wrong ?
Here are the details on the volume of the data in various tables for various calendar days and also listed the primary keys , this is for your reference.
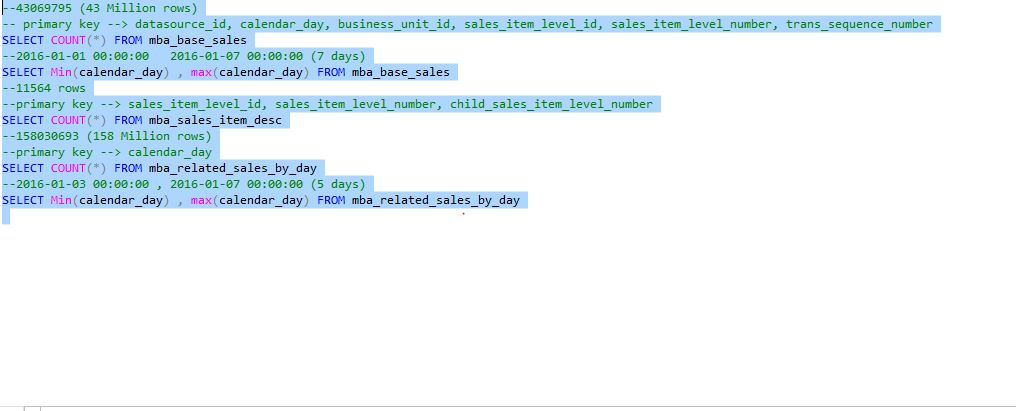
Also please advise if it is a good idea to use partitioned tables (daily partition as data volume is very high) , at the moment no partitions are defined . Will partitions help to optimize the performance and fast retrieval and hence forth update runs fast. Please correct me if I am wrong ?
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Thanks Zberteoc for immediate reply with the optimized query.
mba_related_sales_by_day table is having only calenar_day as the primary key (as mentioned in screen shot) above.
Can I create partitions(daily) on this table and also all the related tables , will it improve performance ? I have a requirement to actually run a historical load of 12 months , with 10 days in each single load (i.e run etl 37 times for complete 1 year) . Need your input on how to go forward for this please ?
mba_related_sales_by_day table is having only calenar_day as the primary key (as mentioned in screen shot) above.
Can I create partitions(daily) on this table and also all the related tables , will it improve performance ? I have a requirement to actually run a historical load of 12 months , with 10 days in each single load (i.e run etl 37 times for complete 1 year) . Need your input on how to go forward for this please ?
Creating a daily partition should boost your query.
I've worked out on it and came with this version:
I've worked out on it and came with this version:
;with cte_sales_item as
(
select sales_item_level_id, sales_item_level_number, child_sales_item_level_id
from mba_sales_item_desc
where child_sales_item_level_number = 6
)
update related
set related_transactions_number_day =
(
Select count(distinct trans_sequence_number)
from mba_base_sales aa
inner join cte_sales_item cte on cte.sales_item_level_id = related.sales_item_id
and cte.sales_item_level_number = related.related_sales_item_hierarchy_level
and cte.child_sales_item_level_id = aa.sales_item_level_id
inner join cte_sales_item cte3 on cte3.sales_item_level_id = related.sales_item_id
and cte3.sales_item_level_number = related.sales_item_hierarchy_level
and cte3.child_sales_item_level_id = aa1.sales_item_level_id
where aa.calendar_day = related.calendar_day
and aa.Business_Unit_ID = related.business_unit_id
and aa.sales_item_level_id not in
(
select c.child_sales_item_level_id
from cte_sales_item cte2
where cte2.sales_item_level_id = related.sales_item_id
and cte2.sales_item_level_number = related.sales_item_hierarchy_level
)
and aa.sales_item_level_number = 6
and aa.datasource_id = related.datasource_id
)
from mba_related_sales_by_day related
inner join mba_sales_item_desc c on c.child_sales_item_level_id = related.sales_item_id
and c.Child_sales_item_level_number = related.sales_item_hierarchy_level
and c.sales_item_level_id = related.related_sales_item_id
where related.related_sales_item_hierarchy_level < related.sales_item_hierarchy_level
and related.calendar_day between @v_begin_date and @v_end_dateASKER
Thanks vitor for immediate reply , related_transactions_numbe
What about this version?
;with cte_sales_item as
(
select sales_item_level_id, sales_item_level_number, child_sales_item_level_id
from mba_sales_item_desc
where child_sales_item_level_number = 6
)
update related
set related_transactions_number_day =
(
Select count(distinct trans_sequence_number)
from mba_base_sales aa
inner join cte_sales_item cte on cte.sales_item_level_id = related.sales_item_id
and cte.sales_item_level_number = related.related_sales_item_hierarchy_level
and cte.child_sales_item_level_id = aa.sales_item_level_id
where aa.calendar_day = related.calendar_day
and aa.Business_Unit_ID = related.business_unit_id
and aa.sales_item_level_id not in
(
select c.child_sales_item_level_id
from cte_sales_item cte2
where cte2.sales_item_level_id = related.sales_item_id
and cte2.sales_item_level_number = related.sales_item_hierarchy_level
)
and aa.sales_item_level_number = 6
and aa.datasource_id = related.datasource_id
and trans_sequence_number in
(
Select distinct trans_sequence_number
from mba_base_sales aa1
inner join cte_sales_item cte3 on cte3.child_sales_item_level_id = aa1.sales_item_level_id
where cte3.sales_item_level_id = related.sales_item_id
and cte3.sales_item_level_number = related.sales_item_hierarchy_level
and aa1.calendar_day = aa.calendar_day
and aa1.Business_Unit_ID = aa.business_unit_id
and aa1.sales_item_level_number = 6
)
)
from mba_related_sales_by_day related
inner join mba_sales_item_desc c on c.child_sales_item_level_id = related.sales_item_id
and c.Child_sales_item_level_number = related.sales_item_hierarchy_level
and c.sales_item_level_id = related.related_sales_item_id
where related.related_sales_item_hierarchy_level < related.sales_item_hierarchy_level
and related.calendar_day between @v_begin_date and @v_end_dateASKER
No luck vitor , returning the same zeros for all the rows.
Ok, let's go one step at a time, then.
By your query execution plan it's clearly loosing time in the SORT operation. That's because you're using DISTINCT. I just replace it with a GROUP BY and expecting this will boost the query:
By your query execution plan it's clearly loosing time in the SORT operation. That's because you're using DISTINCT. I just replace it with a GROUP BY and expecting this will boost the query:
update related
set related_transactions_number_day =
(
Select count(distinct trans_sequence_number)
from mba_base_sales aa
where aa.calendar_day = related.calendar_day
and aa.Business_Unit_ID = related.business_unit_id
and aa.sales_item_level_id not in
(
select c.child_sales_item_level_id
from mba_sales_item_desc c
where c.sales_item_level_id = related.sales_item_id
and c.sales_item_level_number = related.sales_item_hierarchy_level
and c.child_sales_item_level_number = 6
)
and aa.sales_item_level_id in
(
select c.child_sales_item_level_id
from mba_sales_item_desc c
where c.sales_item_level_id = related.related_sales_item_id
and c.sales_item_level_number = related.related_sales_item_hierarchy_level
and c.child_sales_item_level_number = 6
)
and aa.sales_item_level_number = 6
and aa.datasource_id = related.datasource_id
and trans_sequence_number in
(
Select trans_sequence_number
from mba_base_sales aa1
where aa1.calendar_day = related.calendar_day
and aa1.Business_Unit_ID = aa.business_unit_id
and aa1.sales_item_level_id in
(
select c.child_sales_item_level_id
from mba_sales_item_desc c
where c.sales_item_level_id = related.sales_item_id
and c.sales_item_level_number = related.sales_item_hierarchy_level
and c.child_sales_item_level_number = 6
)
and aa1.sales_item_level_number = 6
and aa.datasource_id =related.datasource_id
group by trans_sequence_number
)
)
from mba_related_sales_by_day related
where related.related_sales_item_hierarchy_level < related.sales_item_hierarchy_level
and related.calendar_day between @v_begin_date and @v_end_date
and related.related_sales_item_id in
(
select c.sales_item_level_id
from mba_sales_item_desc c
where c.child_sales_item_level_id = related.sales_item_id
and c.Child_sales_item_level_number = related.sales_item_hierarchy_level
)ASKER
Already tried this Vitor , but no performance gain , can you please help me with the Common Table Expression you have used earlier ?
Can you please provide the Estimated Query Execution Plan for my last query so I can compare it with the one you provided?
ASKER
Vitor, here is the execution plan with group by
[embed=file 1172001]
It's seems better to me. The two 24% spent in the SORT operation gone.
Anyway, next step is to transform the IN operator in INNER JOIN:
Anyway, next step is to transform the IN operator in INNER JOIN:
update related
set related_transactions_number_day =
(
Select count(distinct trans_sequence_number)
from mba_base_sales aa
where aa.calendar_day = related.calendar_day
and aa.Business_Unit_ID = related.business_unit_id
and aa.sales_item_level_id not in
(
select c.child_sales_item_level_id
from mba_sales_item_desc c
where c.sales_item_level_id = related.sales_item_id
and c.sales_item_level_number = related.sales_item_hierarchy_level
and c.child_sales_item_level_number = 6
)
and aa.sales_item_level_id in
(
select c.child_sales_item_level_id
from mba_sales_item_desc c
where c.sales_item_level_id = related.related_sales_item_id
and c.sales_item_level_number = related.related_sales_item_hierarchy_level
and c.child_sales_item_level_number = 6
)
and aa.sales_item_level_number = 6
and aa.datasource_id = related.datasource_id
and trans_sequence_number in
(
Select trans_sequence_number
from mba_base_sales aa1
where aa1.calendar_day = related.calendar_day
and aa1.Business_Unit_ID = aa.business_unit_id
and aa1.sales_item_level_id in
(
select c.child_sales_item_level_id
from mba_sales_item_desc c
where c.sales_item_level_id = related.sales_item_id
and c.sales_item_level_number = related.sales_item_hierarchy_level
and c.child_sales_item_level_number = 6
)
and aa1.sales_item_level_number = 6
and aa.datasource_id =related.datasource_id
group by trans_sequence_number
)
)
from mba_related_sales_by_day related
inner join mba_sales_item_desc c on c.child_sales_item_level_id = related.sales_item_id
and c.Child_sales_item_level_number = related.sales_item_hierarchy_level
and c.sales_item_level_id = related.related_sales_item_id
where related.related_sales_item_hierarchy_level < related.sales_item_hierarchy_level
and related.calendar_day between @v_begin_date and @v_end_dateASKER
Here is the new estimated execution pan of the query
with_group_by_new.sqlplan
[embed=file 1172081]with_group_by_new.sqlplan
That's the count(distinct) sort.
Check if this version is better:
Check if this version is better:
update related
set related_transactions_number_day =
(select count(t.trans_sequence_number)
from (
Select trans_sequence_number
from mba_base_sales aa
where aa.calendar_day = related.calendar_day
and aa.Business_Unit_ID = related.business_unit_id
and aa.sales_item_level_id not in
(
select c.child_sales_item_level_id
from mba_sales_item_desc c
where c.sales_item_level_id = related.sales_item_id
and c.sales_item_level_number = related.sales_item_hierarchy_level
and c.child_sales_item_level_number = 6
)
and aa.sales_item_level_id in
(
select c.child_sales_item_level_id
from mba_sales_item_desc c
where c.sales_item_level_id = related.related_sales_item_id
and c.sales_item_level_number = related.related_sales_item_hierarchy_level
and c.child_sales_item_level_number = 6
)
and aa.sales_item_level_number = 6
and aa.datasource_id = related.datasource_id
and trans_sequence_number in
(
Select trans_sequence_number
from mba_base_sales aa1
where aa1.calendar_day = related.calendar_day
and aa1.Business_Unit_ID = aa.business_unit_id
and aa1.sales_item_level_id in
(
select c.child_sales_item_level_id
from mba_sales_item_desc c
where c.sales_item_level_id = related.sales_item_id
and c.sales_item_level_number = related.sales_item_hierarchy_level
and c.child_sales_item_level_number = 6
)
and aa1.sales_item_level_number = 6
and aa.datasource_id =related.datasource_id
group by trans_sequence_number
)
group by trans_sequence_number) t
)
from mba_related_sales_by_day related
inner join mba_sales_item_desc c on c.child_sales_item_level_id = related.sales_item_id
and c.Child_sales_item_level_number = related.sales_item_hierarchy_level
and c.sales_item_level_id = related.related_sales_item_id
where related.related_sales_item_hierarchy_level < related.sales_item_hierarchy_level
and related.calendar_day between @v_begin_date and @v_end_date
A PK column value in a row has to be UNIQUE per table, Is it a unique date time value? If yes, you can still use the loop script like the one I posted. The issue here is to break the update into manageable smaller parts.
n_srikanth4, a feedback will be appreciated.
ASKER
Thanks Sir you are the star and it is working .
But sometimes , it takes time when I increase the load to 1 million in a batch for faster execution as I need to process billions of rows .
I have another question , I will ask in another question . Could I please request you to be my mentor for any sql related questions ? Greatly appreciated.
But sometimes , it takes time when I increase the load to 1 million in a batch for faster execution as I need to process billions of rows .
I have another question , I will ask in another question . Could I please request you to be my mentor for any sql related questions ? Greatly appreciated.