kcatnip9
asked on
Batch Script needed to parse through a data file and find any missing data and correct it.
We have an internal process that downloads a text file from our vendor. The format of the information of this file is as follows – followed by a comma.
Name of data file = TEST.IDX
Field names contained in TEST.IDX:
ID Number = 5 numbers
Loan Type = 2 Characters
Full Name= varies up to 60 Characters
SSN = 9 numbers
App Number = 4 numbers
Collateral Code = 3 numbers
Loan Type = 4 numbers
Document name = Varies up to 60 characters
Internal ID = 1 number
Date = 10 characters
Download Path = varies up to 100 characters
The issue is that the file TEST.IDX - could contain a data line for the document name called { Full Name + Credit Report } – that does not contain data in the COLLATERAL CODE field. The script would need to parse through the data file – TEST.IDX and then look for the data line that contains the document name { Full Name + Credit Report }. Once found it looks for a matching ID number listed in the TEST.IDX file. Once found – it would need to find the COLLATERAL CODE field. The collateral code that is found – would need to be copied onto the Collateral Code Filed for the data line that contains the document name { Full Name + Credit Report }.
For Example. The second line below – contains the Credit Report document name called “ JOHNATHAN WILLIAMS Credit Report”. The 6th Field in that line – does not contain a COLLATERAL CODE. It is listed as zero. The script would look for the ID Number “55555” and look at the 6th field to find the COLLATERAL CODE – which in this data line – is 021. Once found it would update 2nd line with this COLLATERAL CODE. The updated Data file – could be called TEST.UPDATE.idx
55555,VL,JOHNATHAN WILLIAMS,111111111,4444,02
55555,VL,JOHNATHAN WILLIAMS,111111111,4444,0,
Name of data file = TEST.IDX
Field names contained in TEST.IDX:
ID Number = 5 numbers
Loan Type = 2 Characters
Full Name= varies up to 60 Characters
SSN = 9 numbers
App Number = 4 numbers
Collateral Code = 3 numbers
Loan Type = 4 numbers
Document name = Varies up to 60 characters
Internal ID = 1 number
Date = 10 characters
Download Path = varies up to 100 characters
The issue is that the file TEST.IDX - could contain a data line for the document name called { Full Name + Credit Report } – that does not contain data in the COLLATERAL CODE field. The script would need to parse through the data file – TEST.IDX and then look for the data line that contains the document name { Full Name + Credit Report }. Once found it looks for a matching ID number listed in the TEST.IDX file. Once found – it would need to find the COLLATERAL CODE field. The collateral code that is found – would need to be copied onto the Collateral Code Filed for the data line that contains the document name { Full Name + Credit Report }.
For Example. The second line below – contains the Credit Report document name called “ JOHNATHAN WILLIAMS Credit Report”. The 6th Field in that line – does not contain a COLLATERAL CODE. It is listed as zero. The script would look for the ID Number “55555” and look at the 6th field to find the COLLATERAL CODE – which in this data line – is 021. Once found it would update 2nd line with this COLLATERAL CODE. The updated Data file – could be called TEST.UPDATE.idx
55555,VL,JOHNATHAN WILLIAMS,111111111,4444,02
55555,VL,JOHNATHAN WILLIAMS,111111111,4444,0,
ASKER
I uploaded a sample test file w/ 3 accounts that I modified the data for security purposes. Data files normally contain about 20 to 30 accounts. There are no headers in the first record of this file.
Your logic is correct. There is no need to look at the doc name - but rather search for the line that has the zero COLLATERAL CODE and find the matching ID number that has a non-zero COLLATERAL CODE.
Thank you Bill!
TEST.TXT
Your logic is correct. There is no need to look at the doc name - but rather search for the line that has the zero COLLATERAL CODE and find the matching ID number that has a non-zero COLLATERAL CODE.
Thank you Bill!
TEST.TXT
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Amazing! Worked perfectly. Thank you Bill!!!
ASKER
Appreciate the prompt response and the accuracy of obtaining the objective on the first try. Thank you very much! ~k
Very welcome, glad that worked for you, and thanks for the feedback.
»bp
»bp
ASKER
Hi Bill -
I think I closed this prematurely. The issue I have now is that I need to run this as a scheduled task. The job fails b/c it is looking for the VBS script in the System32 folder. Of course I can place it there - but the other data files would need to go in that directory which I do not want. Can you show me where I would do the SET PATH variable in the VBS script to point to where the data file is ( TEXT.TXT)?
Thank you again for your assistance!
~Kirk
I think I closed this prematurely. The issue I have now is that I need to run this as a scheduled task. The job fails b/c it is looking for the VBS script in the System32 folder. Of course I can place it there - but the other data files would need to go in that directory which I do not want. Can you show me where I would do the SET PATH variable in the VBS script to point to where the data file is ( TEXT.TXT)?
Thank you again for your assistance!
~Kirk
When you create (or modify) the scheduled task you can change the working directory that the job process in to the directory where the script and the files exist. That's the easiest way.
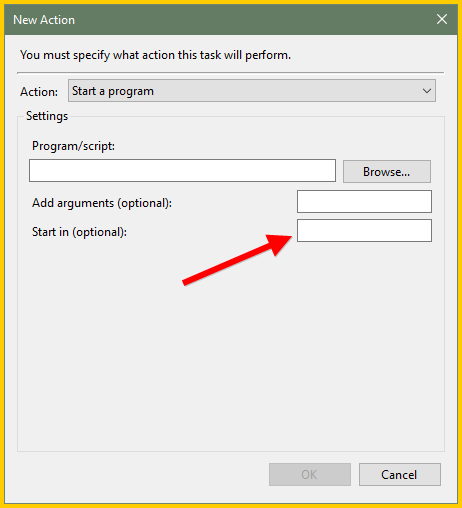
The other alternative is just to fully qualify all the file names involved, like:
»bp
The other alternative is just to fully qualify all the file names involved, like:
cscript "C:\ScriptFolder\EE29068178.vbs" "C:\DataFolder\test.txt" C:\DataFolder\new.txt"»bp
ASKER
Yes - that fixed it. Thanks again Bill!
Welcome.
»bp
»bp
ASKER
Hi again Bill!
One last request. If I need to open a new ticket for this - please let me know.
Using the same VBS script that you wrote - I also need it to look for the data line that has NO DATA in the first field. When found delete that data line.
For example - below is an example of a valid data line:
55555,VL,JOHNATHAN WILLIAMS,111111111,4444,02
Here is an example of a bad data line that needs to be deleted b/c the first field contains no data.
,VL,JOHNATHAN WILLIAMS,111111111,4444,02
Thank you again for assistance. Much appreciated! ~k
One last request. If I need to open a new ticket for this - please let me know.
Using the same VBS script that you wrote - I also need it to look for the data line that has NO DATA in the first field. When found delete that data line.
For example - below is an example of a valid data line:
55555,VL,JOHNATHAN WILLIAMS,111111111,4444,02
Here is an example of a bad data line that needs to be deleted b/c the first field contains no data.
,VL,JOHNATHAN WILLIAMS,111111111,4444,02
Thank you again for assistance. Much appreciated! ~k
Offline for a week, will check back later.
ASKER
Hi Bill. Posting this again. If I need to open a new ticket for this - please let me know. Thank you!
>>>>>
Using the same VBS script that you wrote - I also need it to look for the data line that has NO DATA in the first field. When found delete that data line.
For example - below is an example of a valid data line:
55555,VL,JOHNATHAN WILLIAMS,111111111,4444,02
Here is an example of a bad data line that needs to be deleted b/c the first field contains no data.
,VL,JOHNATHAN WILLIAMS,111111111,4444,02
Thank you again for assistance. Much appreciated! ~k
>>>>>
Using the same VBS script that you wrote - I also need it to look for the data line that has NO DATA in the first field. When found delete that data line.
For example - below is an example of a valid data line:
55555,VL,JOHNATHAN WILLIAMS,111111111,4444,02
Here is an example of a bad data line that needs to be deleted b/c the first field contains no data.
,VL,JOHNATHAN WILLIAMS,111111111,4444,02
Thank you again for assistance. Much appreciated! ~k
I haven't tested this, but give it a try there and see if it meets your need.
»bp
Option Explicit
' Define needed constants
Const ForReading = 1
Const ForWriting = 2
Const TriStateUseDefault = -2
Const Delim = ","
Dim strInFile, strOutFIle
Dim objFSO, objFile, dicCode
Dim arrLine, arrField, i
' Create filesystem object
Set objFSO = CreateObject("Scripting.FileSystemObject")
' Get input and output file names from command line
If (WScript.Arguments.Count < 2) Then
WScript.Echo "Usage: " & Wscript.ScriptName & " <input-file1> <output-file>"
WScript.Quit
Else
strInFile = objFSO.GetAbsolutePathname(WScript.Arguments(0))
strOutFile = objFSO.GetAbsolutePathname(WScript.Arguments(1))
End If
' Make sure input file exists
If Not objFSO.FileExists(strInFile) Then
Wscript.Echo "Error: " & Wscript.ScriptName & " - input file not found """ & strInFile & """."
Wscript.Quit
End If
' Create dictionary object to locate matches
Set dicCode = CreateObject("Scripting.Dictionary")
' Read input file into an array
Set objFile = objFSO.OpenTextFile(strInFile, ForReading, False, TriStateUseDefault)
arrLine = Split(objFile.ReadAll, VbCrLf)
objFile.Close
' Loop through all lines of the file, load into a dictionary
For i = 0 To UBound(arrLine)
If arrLine(i) <> "" Then
arrField = Split(arrLine(i), Delim)
If Not dicCode.Exists(arrField(0)) Then
dicCode.Add arrField(0), arrField(5)
End If
End If
Next
' Output file adding code where missing
Set objFile = objFSO.OpenTextFile(strOutFile, ForWriting, True)
' Loop through all lines of input file, output with changes
for i = 0 To UBound(arrLine)
If arrLine(i) <> "" Then
arrField = Split(arrLine(i), Delim)
If arrField(0) <> "" Then
If arrField(5) = "0" Then
If dicCode.Exists(arrField(0)) Then
arrField(5) = dicCode.Item(arrField(0))
End If
End If
objFile.WriteLine Join(arrField, Delim)
End If
End If
Next
' Close output file
objFile.Close»bp
ASKER
Yes- worked perfect. Thank you very much for your help! Really appreciate it!
Welcome.
»bp
»bp
Is there a header row as the first record of the file, or does it start with data?
Do we really need to look at the Name, or would it also work to look at all lines, and if a line has a zero COLLATERAL CODE, find the line with matching ID NUMBER that has a non-zero COLLATERAL CODE, and use that?
»bp