Kissel-B
asked on
CSV assignment for Storage Spaces Direct (S2D)
Over the last few weeks I have been building and testing a two node S2D cluster I am just about finished with it but I have a question about CSV disk ownership when you run the VM fleet each node is assigned a CSV for the VMFleet storage if you reboot a node that nodes CSV moves ownership to the other node when the VM Fleet is run again the node with all the disk ownership runs at a higher load then other. My question is two fold the CSV ownership does not move back when I unpause the node is this correct will I have to move the disk manually back to the correct owner every reboot? Second part is the assignment of the CSV previously I only had one due to the storage being provided by a 3rd server to the two nodes. So If I want the best performance I should evenly split the storage and give each node a CSV and just put half of the VM's on one disk and the other half on the second CSV?
ASKER
I am far from an expert in S2D but it seems like it fills the need we are a small company its simple all flash setup servers are old though. It's on a 10gb switch each node has 4 1.6 TB Intel DC P3600 cards. As you can see in the attached screen shots when both CSV's are owned by one node the IOPS on the second drop drastically when they both own their CSV the IOPS are much more balanced is this supposed to be that way?
Each server has 25VM's running for this test.

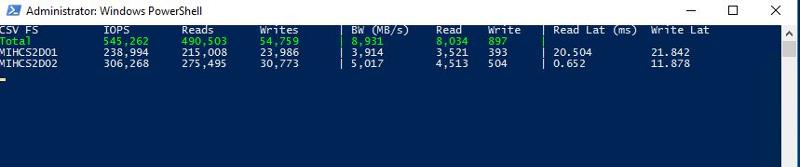
Each server has 25VM's running for this test.

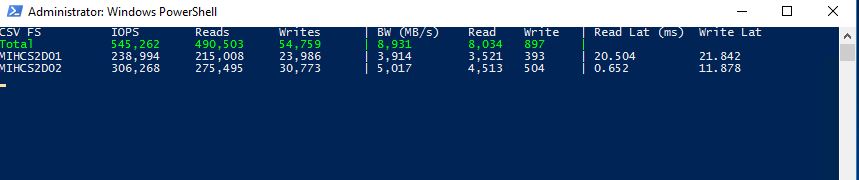
Well, those seem to be point in time snapshots and the second was clearly under higher load overall...by double, regardless of ownership. That is going to change things a bit. I also assert that it really depends on your setup. Dynamic expanding VHDs, especially on a new install with high churn, or on systems that could cause consistent growth (SQL, Exchange, etc) expanding the VHD causes metadata writes. Fixed disks would be preferred in that scenario. Thus my caveat of "a properly designed system." In a cluster, you want to take extra steps to minimize metadata writes. Even if you balance the CSVs, you should be taking those steps.
We tend to coordinate CSV and VM ownership to the same node for snapshot backup to reduce the redirected I/O.
Check the following:
1: CSV owner = VM owner
2: CSV =/= VM owner
I suspect that the lower IOPS are associated with scenario 2.
Also, make sure the NVMe drives have the February firmware update as there is an issue with earlier firmware in S2D.
https://support.microsoft.com/en-us/help/4052341/slow-performance-or-lost-communication-io-error-detached-or-no-redunda
Check the following:
1: CSV owner = VM owner
2: CSV =/= VM owner
I suspect that the lower IOPS are associated with scenario 2.
Also, make sure the NVMe drives have the February firmware update as there is an issue with earlier firmware in S2D.
https://support.microsoft.com/en-us/help/4052341/slow-performance-or-lost-communication-io-error-detached-or-no-redunda
ASKER
So what do you think is the best option one csv or create two one for each node and split the vm distribution between the two CSV's
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
With that said, the major point of CSV is that as the name implies, it is a "shared" volume. Nodes will be writing directly to the CSV a vast majority of the time. Which with S2D on a hyper-converged structure, would be local writes. So if the VMs are balanced, the CSV "ownership" doesn't need to be.
The only time writes need to happen to the orchestrator node (the ownership node if you prefer) is when metadata changes. That includes things like a VM starting, stopping, or a VHDX being expanded, shrunk. Those should be rare events, and if a ton are happening and loading down an orchestrator node, you probably have bigger issues.
There are edge cases where the above isn't true, but in those cases, it usually wouldn't be a two-node hyper-converged cluster either. Those edge cases usually have enough other needs that you'd have dedicated storage clusters, or more than two nodes, or both.