Extracting a CSV from a PDF
I need my website to extract the data from a PDF and generate a CSV file. And I hope to do this on the front end, inside the client browser. But, if required, I could to this extraction on the back-end.
The PDF would be a month merchant credit card statement. The data I would extract to a CSV would be the numerous transactions.
What web technology can do this? And without human intervention.
Thanks.
The PDF would be a month merchant credit card statement. The data I would extract to a CSV would be the numerous transactions.
What web technology can do this? And without human intervention.
Thanks.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
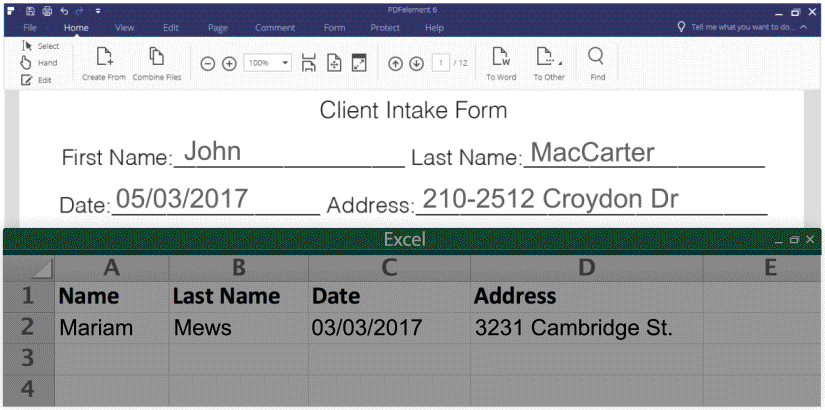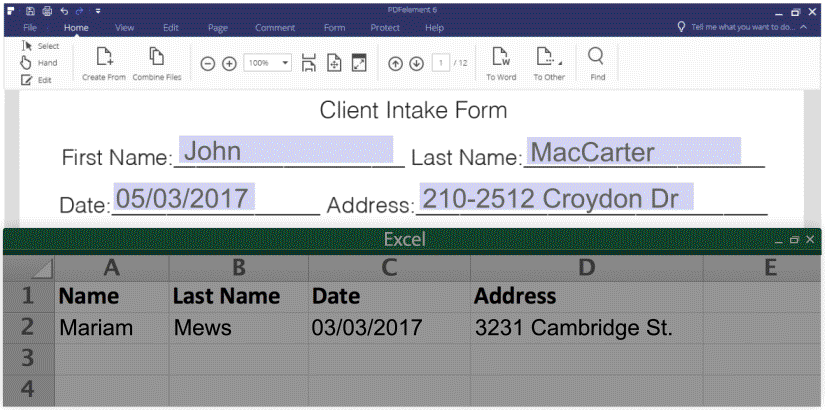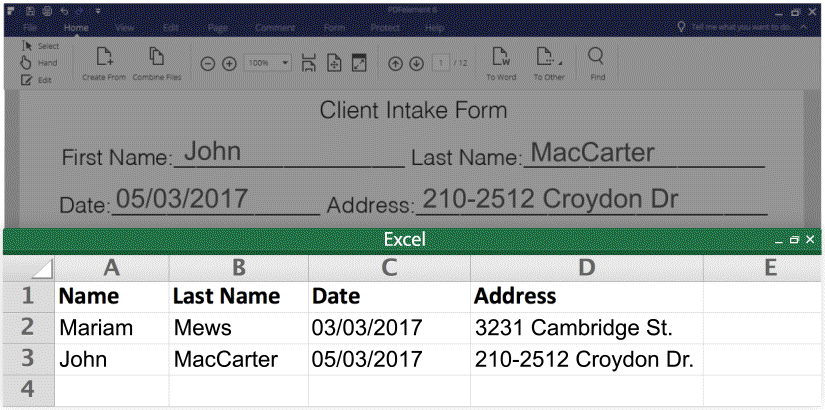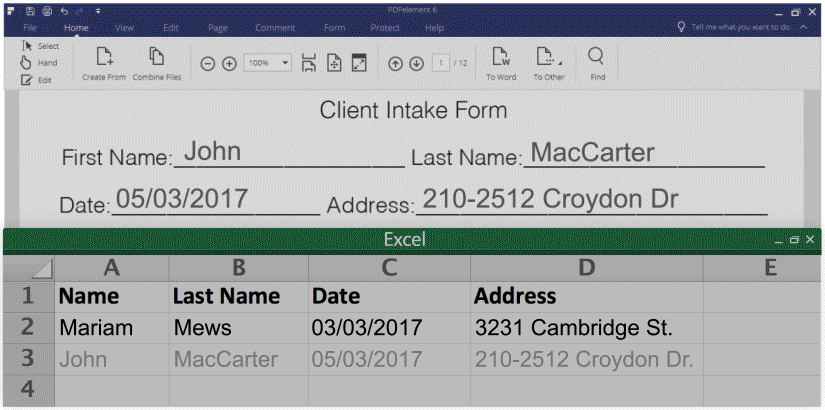
You can actually extract data or information from PDF form when you have the right PDF tools. Here are two samples.
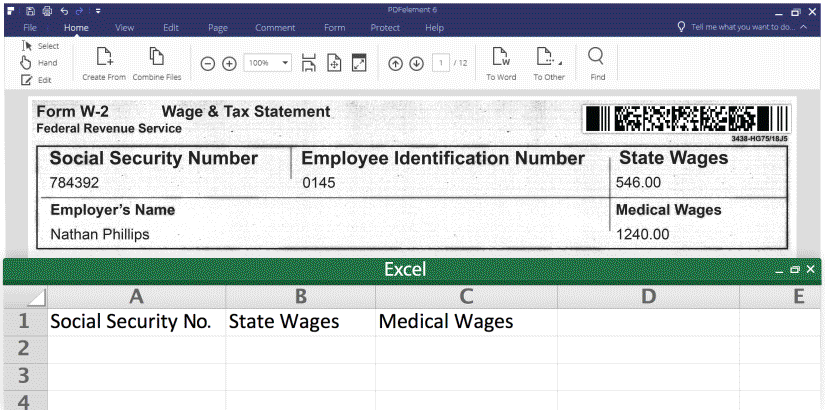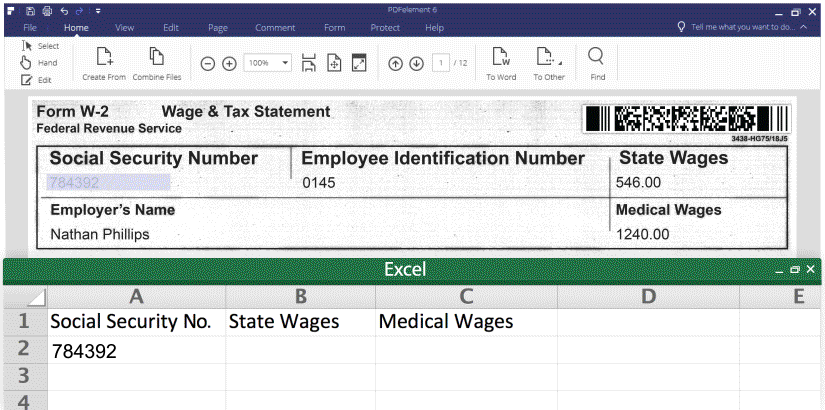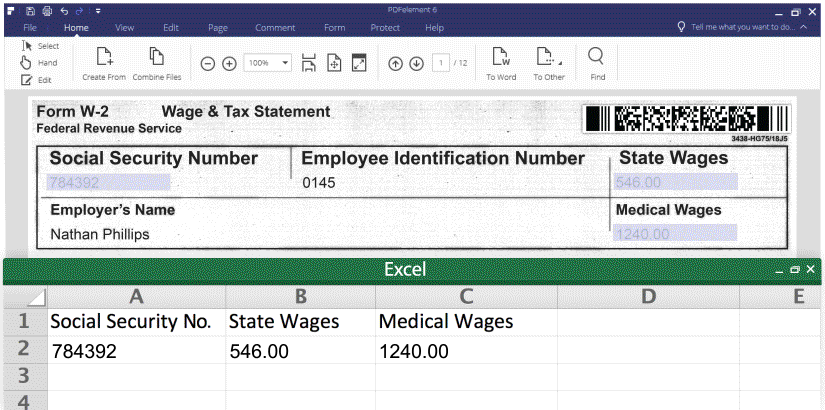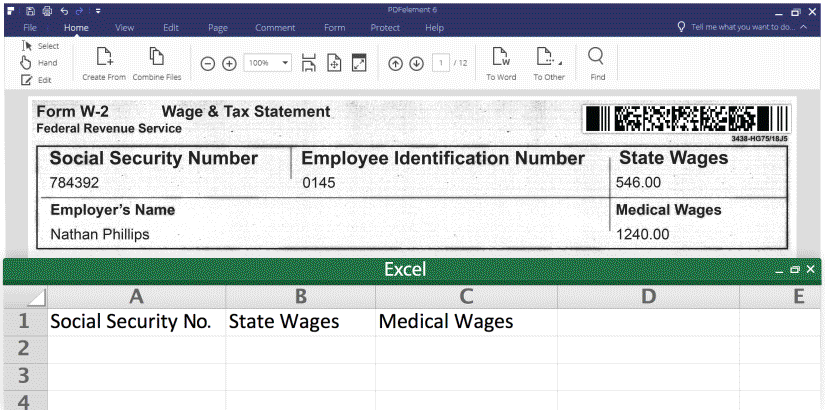
1. Export form data into excel (CSV.), please see the screenshot:
https://pdfimages.wondershare.com/images/vis-2016/form-field-extraction.gif
2. Export data from scanned PDFs, please see the screenshot:
https://pdfimages.wondershare.com/images/vis-2016/Scanned-document.gif
Then you can extra PDF form data from from hundreds of identical forms into a single, accessible Excel sheet within seconds.
If your files are scanned PDFs, then see the second screenshot, OCR technology can converts piles of paper documents into Office files, then apply the same data extraction rules to hundreds of scanned PDFs with the identical layout, and export all the data into one single spreadsheet.
Here is the full guide:
extract data
1. Export form data into excel (CSV.), please see the screenshot:
https://pdfimages.wondershare.com/images/vis-2016/form-field-extraction.gif
{kind=link}
2. Export data from scanned PDFs, please see the screenshot:
https://pdfimages.wondershare.com/images/vis-2016/Scanned-document.gif
{kind=link}
Then you can extra PDF form data from from hundreds of identical forms into a single, accessible Excel sheet within seconds.
If your files are scanned PDFs, then see the second screenshot, OCR technology can converts piles of paper documents into Office files, then apply the same data extraction rules to hundreds of scanned PDFs with the identical layout, and export all the data into one single spreadsheet.
Here is the full guide:
extract data
ASKER