marrowyung
asked on
MySQL InnoDB cluster installation guide
hi,
any clear to understand and follow installation guide to quickly setup MySQL InnoDB cluster? 3 x DB node and 1 x nodes for MySQL router and MySQL Shell ?
we are told to use InnoDB cluster but not NDB cluster.
test guide are also good.
any clear to understand and follow installation guide to quickly setup MySQL InnoDB cluster? 3 x DB node and 1 x nodes for MySQL router and MySQL Shell ?
we are told to use InnoDB cluster but not NDB cluster.
test guide are also good.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
Likely good to mention a couple more considerations also.
1) Use a Kernel 4.15+ for fastest + most stable network stack, so Ubuntu Bionic provides a good OS starting point. Using common CentOS offerings provide old Kernels (3.10.x last I checked).
2) Use latest MariaDB packages directly from the MariaDB stable repository. Many Linux Distros have plans to completely remove MySQL from their repositories, as MariaDB is faster, more stable, adding in new storage engines as soon as they become stable.
This will avoid you hitting problems hitting old Kernel bugs + slowness. Using latest MariaDB tends to provide a different experience than trying to get MySQL to work.
1) Use a Kernel 4.15+ for fastest + most stable network stack, so Ubuntu Bionic provides a good OS starting point. Using common CentOS offerings provide old Kernels (3.10.x last I checked).
2) Use latest MariaDB packages directly from the MariaDB stable repository. Many Linux Distros have plans to completely remove MySQL from their repositories, as MariaDB is faster, more stable, adding in new storage engines as soon as they become stable.
This will avoid you hitting problems hitting old Kernel bugs + slowness. Using latest MariaDB tends to provide a different experience than trying to get MySQL to work.
mysql does not provide an actual cluster. mariadb does.
mariadb debian packages do not contain the galera cluster part so cannot be used without lots of pain
mariadb provides ppas for ubuntu : http://mariadb.mirrors.ovh.net/MariaDB/repo/...
mariadb is faster and more stable on native bsd than in any out-of-the-box linux ( from my personal experience )
--
the best doc is online on the mariadb site, but basically :
configure all hosts using the same config. here is an example
you are expected to understand `hostname -s` is to be replaced with the hostname, $sqld_cluster_name is a variable ( pick anything as long as all members agree ), and the mess after gcomm:// simply produces a comma-separated list of hosts. it is not required but best practice to configure all hosts in every member's config.
... and bootstrap the cluster. on ubuntu, use the "galera_new_cluster" command which circumvents idiocies made in systemd. on other oses there is usually a flag ( --newcluster or --bootstrap or --wsrep_cluster_address=gc
mariadb debian packages do not contain the galera cluster part so cannot be used without lots of pain
mariadb provides ppas for ubuntu : http://mariadb.mirrors.ovh.net/MariaDB/repo/...
mariadb is faster and more stable on native bsd than in any out-of-the-box linux ( from my personal experience )
--
the best doc is online on the mariadb site, but basically :
configure all hosts using the same config. here is an example
binlog_format=ROW
default_storage_engine=innodb
innodb_autoinc_lock_mode=2
innodb_doublewrite=1
wsrep_on = on
wsrep_provider=/usr/lib/galera/libgalera_smm.so
wsrep_sst_method=rsync # not compatible with ssl if required
wsrep_cluster_address=gcomm://`printf "$sqld_cluster_members" | tr "[:space:]" ,`
wsrep_cluster_name=$sqld_cluster_name
wsrep_node_address=`hostname -s`
wsrep_node_name=`hostname -s`you are expected to understand `hostname -s` is to be replaced with the hostname, $sqld_cluster_name is a variable ( pick anything as long as all members agree ), and the mess after gcomm:// simply produces a comma-separated list of hosts. it is not required but best practice to configure all hosts in every member's config.
... and bootstrap the cluster. on ubuntu, use the "galera_new_cluster" command which circumvents idiocies made in systemd. on other oses there is usually a flag ( --newcluster or --bootstrap or --wsrep_cluster_address=gc
Hello Marrow,
Apart from my previous comment I have a non-technical tip here.
Consider sticking to the question here and not to get diverted to other topics, that will change the course of this question. If you're interested for comparison, raise a separate question for mysql vs mariadb.
Thanks.
Apart from my previous comment I have a non-technical tip here.
Consider sticking to the question here and not to get diverted to other topics, that will change the course of this question. If you're interested for comparison, raise a separate question for mysql vs mariadb.
Thanks.
ASKER
David Favor,
"https://www.digitalocean.com/community/tutorials/how-to-set-up-master-slave-replication-in-mysql provides one simple guide. The also have a master-master setup guide."
tks. but I am more on need a guide to install MySQL InnoDB from the nothing, not just replication.
or you are talking about MySQL innoDB cluster is just MySQL DB with replication between DB servers? but it is more on group replication.
"And, when I run replicated servers I target doing a failover once ever month, just to make sure the entire system is working."
sth like DR drill.
"If this is your first time working with replication,"
no. I am not the first time, I setup MySQL replication on 2 ways or 3 x nodes chain replication before in order to compare with MS SQL 2016 Always on! I don't like replication, but this InnoDB cluster - group replication seems better, right?
Seems no need to setup the direction of replication in group replication, right ?
the link you send me seems a bit complicate on simple replication in one direction.
"2) Use latest MariaDB packages directly from the MariaDB stable repository. Many Linux Distros have plans to completely remove MySQL from their repositories, as MariaDB is faster, more stable, adding in new storage engines as soon as they become stable.
"
I am referring to InnoDB cluster but not MariaDB, I have setup the MariaDB myself with the help from MariaDB.com, they offer good help even BEFORE I pay them. they just lack local support here.
Oracle don't even try to help much ! so if there are no special reason I really want to go for MariaDB, easy to setup , just 2 x cnf file to configure. I even configure Maxscale, one cnf file to configure only !
4x nodes only for MariaDB to run to simulate the production situtation.
theGhost_k8,
seems I need to focus on :
MySQL InnoDB Cluster – Preparing a Linux VM for a Real-World Cluster and
MySQL InnoDB Cluster – Real-World Cluster Tutorial for OEL, Fedora, RHEL and CentOS
?
"Consider sticking to the question here and not to get diverted to other topics, that will change the course of this question. "
I am sorry, where you see I diverting question? this topic is about any guide to install MySQL InnoDB cluster.
skullnobrains,
"mysql does not provide an actual cluster. mariadb does."
what actual cluster means ? no auto failover at all? only group replication ?
how about their very good NDB cluster ?
"mariadb is faster and more stable on native bsd than in any out-of-the-box linux ( from my personal experience )"
I knew it is but MysQL.com come and say they can't support MySQL as MariaDB is from MySQL.
however I don't think it is true ! now really waiting for MariaDB.com to have a local support here !
"the best doc is online on the mariadb site, but basically : "
but I am referring to MySQL innoDB, as I said above here, My MariaDB is up and running well. do you know mysQL workbench doesn't work with MariaDB ? MariaDB support guy shows me database workbench ! that one is good ! the heidi is not good on managing MariaDB.com, heidi is bundled with Maria5.5 on LInux repo! I don't like that one.
"and the mess after gcomm:// simply produces a comma-separated list of hosts. it is not required"
I don't hear that from MariaDB.com, my gcomm:// has 3 x server's IP addresses, that list make sense as all members has to know WHO other members is.
" and bootstrap the cluster. on ubuntu, use the "galera_new_cluster" command which circumvents idiocies made in systemd"
yeah, this is for MariaDB, but there is sth I don't like. In a 3 x nodes cluster, if only 1 nodes remain the whole cluster will down! if we have 2 x nodes on primary and one node on DR site ! this characters already dead !
"https://www.digitalocean.com/community/tutorials/how-to-set-up-master-slave-replication-in-mysql provides one simple guide. The also have a master-master setup guide."
tks. but I am more on need a guide to install MySQL InnoDB from the nothing, not just replication.
or you are talking about MySQL innoDB cluster is just MySQL DB with replication between DB servers? but it is more on group replication.
"And, when I run replicated servers I target doing a failover once ever month, just to make sure the entire system is working."
sth like DR drill.
"If this is your first time working with replication,"
no. I am not the first time, I setup MySQL replication on 2 ways or 3 x nodes chain replication before in order to compare with MS SQL 2016 Always on! I don't like replication, but this InnoDB cluster - group replication seems better, right?
Seems no need to setup the direction of replication in group replication, right ?
the link you send me seems a bit complicate on simple replication in one direction.
"2) Use latest MariaDB packages directly from the MariaDB stable repository. Many Linux Distros have plans to completely remove MySQL from their repositories, as MariaDB is faster, more stable, adding in new storage engines as soon as they become stable.
"
I am referring to InnoDB cluster but not MariaDB, I have setup the MariaDB myself with the help from MariaDB.com, they offer good help even BEFORE I pay them. they just lack local support here.
Oracle don't even try to help much ! so if there are no special reason I really want to go for MariaDB, easy to setup , just 2 x cnf file to configure. I even configure Maxscale, one cnf file to configure only !
4x nodes only for MariaDB to run to simulate the production situtation.
theGhost_k8,
seems I need to focus on :
MySQL InnoDB Cluster – Preparing a Linux VM for a Real-World Cluster and
MySQL InnoDB Cluster – Real-World Cluster Tutorial for OEL, Fedora, RHEL and CentOS
?
"Consider sticking to the question here and not to get diverted to other topics, that will change the course of this question. "
I am sorry, where you see I diverting question? this topic is about any guide to install MySQL InnoDB cluster.
skullnobrains,
"mysql does not provide an actual cluster. mariadb does."
what actual cluster means ? no auto failover at all? only group replication ?
how about their very good NDB cluster ?
"mariadb is faster and more stable on native bsd than in any out-of-the-box linux ( from my personal experience )"
I knew it is but MysQL.com come and say they can't support MySQL as MariaDB is from MySQL.
however I don't think it is true ! now really waiting for MariaDB.com to have a local support here !
"the best doc is online on the mariadb site, but basically : "
but I am referring to MySQL innoDB, as I said above here, My MariaDB is up and running well. do you know mysQL workbench doesn't work with MariaDB ? MariaDB support guy shows me database workbench ! that one is good ! the heidi is not good on managing MariaDB.com, heidi is bundled with Maria5.5 on LInux repo! I don't like that one.
"and the mess after gcomm:// simply produces a comma-separated list of hosts. it is not required"
I don't hear that from MariaDB.com, my gcomm:// has 3 x server's IP addresses, that list make sense as all members has to know WHO other members is.
" and bootstrap the cluster. on ubuntu, use the "galera_new_cluster" command which circumvents idiocies made in systemd"
yeah, this is for MariaDB, but there is sth I don't like. In a 3 x nodes cluster, if only 1 nodes remain the whole cluster will down! if we have 2 x nodes on primary and one node on DR site ! this characters already dead !
ASKER
now I downloaded the tar.gz file and get the binary, any guide on using this binary to setup the InnodB cluster?
Hi Marrow,
That link is sort of master-link from where you can go through and choose your setup.
" MySQL InnoDB Cluster – Real-World Cluster Tutorial for OEL, Fedora, RHEL and CentOS " looks right for you.
Regarding "diverting" you anyways raised many-many questions on the comments that were not directly answering the question.
That link is sort of master-link from where you can go through and choose your setup.
" MySQL InnoDB Cluster – Real-World Cluster Tutorial for OEL, Fedora, RHEL and CentOS " looks right for you.
Regarding "diverting" you anyways raised many-many questions on the comments that were not directly answering the question.
ASKER
"That link is sort of master-link from where you can go through and choose your setup."
tks. actually I setup multi master replication in MySQL before and it works very bad !!
I setup chain replication, the only replication mode word like multi master ! Once a node dead and during this time a lot of change to other member, chained replication will have to be setup again ! it can't resume ! very dump !
It intend to design in this way so that someone still has to buy Oracle RAC !! but Oracle RAC STILL single WRITE at a time.
yeah, single write is good ! no need many write at all ! easy to crash!
that's why we keep seeing things like scale-able READ ! the good thing for report service and it is really a big thing to do !
tks. actually I setup multi master replication in MySQL before and it works very bad !!
I setup chain replication, the only replication mode word like multi master ! Once a node dead and during this time a lot of change to other member, chained replication will have to be setup again ! it can't resume ! very dump !
It intend to design in this way so that someone still has to buy Oracle RAC !! but Oracle RAC STILL single WRITE at a time.
yeah, single write is good ! no need many write at all ! easy to crash!
that's why we keep seeing things like scale-able READ ! the good thing for report service and it is really a big thing to do !
ASKER
i am now reading this :
https://mysqlserverteam.com/mysql-innodb-cluster-real-world-cluster-tutorial-for-oel-fedora-rhel-and-centos/
why should I install the MySQL YUM repository ?
https://mysqlserverteam.com/mysql-innodb-cluster-real-world-cluster-tutorial-for-oel-fedora-rhel-and-centos/
why should I install the MySQL YUM repository ?
You asked, "why should I install the MySQL YUM repository"...
So you can install latest MySQL code.
Better to use MariaDB though, as many Distros are completely retiring MySQL, due to many long running problems which will likely never be fixed.
So you can install latest MySQL code.
Better to use MariaDB though, as many Distros are completely retiring MySQL, due to many long running problems which will likely never be fixed.
ASKER
"So you can install latest MySQL code."
I thought Yum is going to download and install it together at the same time, why need install repository first ?
what I knew is, can setup local repository and then using the rpm downloaded to install the MySQL, right?
I install MariaDB good enough by using this but not for MySQL. today has to learn how to setup MySQL using binary unzip from tar ball.
"due to many long running problems which will likely never be fixed."
what i know about MySQL is:
1) can't do sketched cluster and is the best for single site only ! for Primary and DR site we need 2x InnoDB cluster and setup replication between them. WTF ? ???? replication is one of the most not stable replication method and it has log laging problem. can introduce log latency !
2) MariaDB support very good except on site service, not all country has local on site service.
3) on NDB cluster design, one data group fall can make the whole cluster down! then why we need a cluster if ONLY one data group dead ? this is not a HA solution any more !
4) MySQL do not have OLAP (any suggestion on OLAP solution for MySQL ?) and MariaDB has !
However this kind of open source do not have build in ETL solution, I am sad on this.
I thought Yum is going to download and install it together at the same time, why need install repository first ?
what I knew is, can setup local repository and then using the rpm downloaded to install the MySQL, right?
I install MariaDB good enough by using this but not for MySQL. today has to learn how to setup MySQL using binary unzip from tar ball.
"due to many long running problems which will likely never be fixed."
what i know about MySQL is:
1) can't do sketched cluster and is the best for single site only ! for Primary and DR site we need 2x InnoDB cluster and setup replication between them. WTF ? ???? replication is one of the most not stable replication method and it has log laging problem. can introduce log latency !
2) MariaDB support very good except on site service, not all country has local on site service.
3) on NDB cluster design, one data group fall can make the whole cluster down! then why we need a cluster if ONLY one data group dead ? this is not a HA solution any more !
4) MySQL do not have OLAP (any suggestion on OLAP solution for MySQL ?) and MariaDB has !
However this kind of open source do not have build in ETL solution, I am sad on this.
ASKER
any update for me ?
what actual cluster means ? no auto failover at all? only group replication ?
how about their very good NDB cluster ?
you mentionned innodb cluster. NDB is not related or backed by innodb.
actual cluster basics are at least : all members active at the same time and either masterless or transparent master election + self healing when nodes fail and go up again.
... so yes a bidirectional replication mildly qualifies as a 2 node rather dysfunctional cluster
I don't hear that from MariaDB.com, my gcomm:// has 3 x server's IP addresses, that list make sense as all members has to know WHO other members is.
as i stated, it is best practice. but any member will do : the setting is used while connecting to the cluster the first time. afterwards, the host automatically tracks cluster members by itself. in real life, many admins pull one cluster member from the pool and use it as the gcomm address while adding new members so the initial transfer does not impact other cluster members.
" and bootstrap the cluster. on ubuntu, use the "galera_new_cluster" command which circumvents idiocies made in systemd"
yeah, this is for MariaDB, but there is sth I don't like. In a 3 x nodes cluster, if only 1 nodes remain the whole cluster will down! if we have 2 x nodes on primary and one node on DR site ! this characters already dead ! - please stop posting unrelated comments together. every post from you is a pain to read.
- the 1 node assertion is not quite true. read the docs, there are options to prevent this and the doc even states the options are recommended for 2 nodes clusters.
- 2x nodes on primary and 1 node on dr is a foolish setup which you as an architect are responsible for NOT setting up. again, read the docs and setup as many nodes you want in both locations + weight the nodes so both locations have the same weight + setup a garbd in a third location ( your office, a cloud machine, whatever )
ASKER
"you mentionned innodb cluster. NDB is not related or backed by innodb."
I didn't say they are related. I want to know the diff,
this is for mariaDB, right?
"so both locations have the same weight + setup a garbd in a third location ( your office, a cloud machine, whatever )"
Sure.
I didn't say they are related. I want to know the diff,
binlog_format=ROW
default_storage_engine=innodb
innodb_autoinc_lock_mode=2
innodb_doublewrite=1
wsrep_on = on
wsrep_provider=/usr/lib/galera/libgalera_smm.so
wsrep_sst_method=rsync # not compatible with ssl if required
wsrep_cluster_address=gcomm://`printf "$sqld_cluster_members" | tr "[:space:]" ,`
wsrep_cluster_name=$sqld_cluster_name
wsrep_node_address=`hostname -s`
wsrep_node_name=`hostname -s`this is for mariaDB, right?
"so both locations have the same weight + setup a garbd in a third location ( your office, a cloud machine, whatever )"
Sure.
I want to know the diff
there are many more differences, but in a nutshell...
NDB
- runs entirely in memory ( but the data is still backed on disk )
- uses sharded data ( so each machine has only part of the data with a configurable redundancy factor )
- uses a 2-layer approach : you run queries against front servers which use a custom protocol to interact with the back end servers ( but you can run the front soft on the backend nodes if you wish )
- has a dedicated master server that acts as a cluster orchestrator. ( it is not needed for regular operation so the cluster won't fail if the machine is down, but it won't be able to properly handle changes in it's topology including node failures )
MARIADB+GALERA
- is backed by xtradb ( innodb forked ) so data is on-disk. but if the buffer cache is big enough, you run from ram as well. ( and you can sometimes run different queries on different servers to use the caches more efficiently for huge datasets )
- each server has a complete copy of the data ( except obviously for garbd if you use any )
- uses a single-layer approach. actually you are running a regular mariadb+xtradb with a custom middle layer that produces row-based replication with some additional transaction-locking mechanisms and statement based replication for statements that modify the users or data structures
- has no master : the cluster merely performs quorum calculations in order to prevent split-head scenaris ( which is why a 2 nodes cluster will stop by default when one node fails or the nodes cannot communicate with each-other )
yes, that is for maria
configuring NDB is MUCH more complicated, and configuring it properly requires knowlege regarding the workflow and lots of tests that need to be run on premises. some/many applications simply do not qualify. note that i'm not an NDB expert and have always tried to steer away from NDB. my personal belief is NDB was becoming a dead-end technology even before oracle bought sun, and there are little chances it evolves now.
regards
ASKER
"configuring NDB is MUCH more complicated, and configuring it properly requires knowlege regarding the workflow and lots of tests that need to be run on premises. some/many applications simply do not qualify. note that i'm not an NDB expert and have always tried to steer away from NDB. my personal belief is NDB was becoming a dead-end technology even before oracle bought sun,"
agree on that NDB is much diff, but what MysQL officer come here is saying NDB is for some application can't be slow down, like apple pay.
but the network requirement of it is very sensitive, little network problem can make NDB cluster down, so now we consider only InnoDB cluster OR mariaDB.
"- uses a 2-layer approach : you run queries against front servers which use a custom protocol to interact with the back end servers ( but you can run the front soft on the backend nodes if you wish )"
API node you mean ? usually I recommend connect through SQL node, can't directly connect to data node using API, not that safe from my point of view.
"- has no master : the cluster merely performs quorum calculations in order to prevent split-head scenaris ( which is why a 2 nodes cluster will stop by default when one node fails or the nodes cannot communicate with each-other )"
they recommended 3 x node.
"- uses a single-layer approach. "
don't understand, is that mean SQL layer and data layer on the same box ?
agree on that NDB is much diff, but what MysQL officer come here is saying NDB is for some application can't be slow down, like apple pay.
but the network requirement of it is very sensitive, little network problem can make NDB cluster down, so now we consider only InnoDB cluster OR mariaDB.
"- uses a 2-layer approach : you run queries against front servers which use a custom protocol to interact with the back end servers ( but you can run the front soft on the backend nodes if you wish )"
API node you mean ? usually I recommend connect through SQL node, can't directly connect to data node using API, not that safe from my point of view.
"- has no master : the cluster merely performs quorum calculations in order to prevent split-head scenaris ( which is why a 2 nodes cluster will stop by default when one node fails or the nodes cannot communicate with each-other )"
they recommended 3 x node.
"- uses a single-layer approach. "
don't understand, is that mean SQL layer and data layer on the same box ?
we consider only InnoDB cluster OR mariaDB.
i have no idea what an "innodb cluster" is supposed to be.
mariadb is most likely your best bet.
API node you mean
i meant you are allowed to configure the same hosts as both sql and data nodes. not that i recommend doing so. anyway, let's not discuss this since you won't be using NDB anyway.
is that mean SQL layer and data layer on the same box
there is no such thing as data nodes and sql nodes in mariadb, hence the "single layer approach".
__
... i'm wondering maybe my wording is very poor ? or you just like to make me rephrase over and over ? i have little time so please refrain.
please DO NOT answer to every little sentence unless you have an actual extra question. you're also mixing questions regarding mysql and maria all over the place so it makes the thread really uselessly hard to follow. i've suggested a 3 node mariadb setup like half a dozen times and explained the differences between dbs over and over. my 2 cents advice : pick a solution and get to work.
ASKER
"anyway, let's not discuss this since you won't be using NDB anyway."
yeah, NDB not suggest to use in a cross site situation, primary and DR. nor InnoDB.
seems MySQL do not want to fix it or no one buy Oracle anymore.
"mariadb is most likely your best bet."
at this moment I;d like to say yes but there can be political reason on not using MariaDB, e.g. local support is very less! not locally here!
MariaDB will come here on Friday and explain their support !
"i meant you are allowed to configure the same hosts as both sql and data nodes. not that i recommend doing so."
yes I knew, not recommended but for testing, it is ok ! but I hate the API node concept ! should go thought the SQL node for ACL checking, e.g. !
" i'm wondering maybe my wording is very poor ?
"
oh, you saying sth in the way make people think you are talking about sth else.
I have another question about MysQL enterprise 8 setup and I think you can help. I can't see why my initialization doesn't work ! no output message for me.
https://www.experts-exchange.com/questions/29114405/MySQL-Enterprise-8-installation-procedure.html
"in mariadb, hence the "single layer approach"."
of course.
yeah, NDB not suggest to use in a cross site situation, primary and DR. nor InnoDB.
seems MySQL do not want to fix it or no one buy Oracle anymore.
"mariadb is most likely your best bet."
at this moment I;d like to say yes but there can be political reason on not using MariaDB, e.g. local support is very less! not locally here!
MariaDB will come here on Friday and explain their support !
"i meant you are allowed to configure the same hosts as both sql and data nodes. not that i recommend doing so."
yes I knew, not recommended but for testing, it is ok ! but I hate the API node concept ! should go thought the SQL node for ACL checking, e.g. !
" i'm wondering maybe my wording is very poor ?
"
oh, you saying sth in the way make people think you are talking about sth else.
I have another question about MysQL enterprise 8 setup and I think you can help. I can't see why my initialization doesn't work ! no output message for me.
https://www.experts-exchange.com/questions/29114405/MySQL-Enterprise-8-installation-procedure.html
"in mariadb, hence the "single layer approach"."
of course.
sorry. this is yet another lump of hardly formatted text and the first line you wrote is 2 phrases lumped together in a non-sentence with no verb. i cannot afford to spend 10 minutes trying to figure out what you mean. i'm ready to help if you make things easy for me. format your posts. use your best english. include necessary information. do not ask 10 questions at a time...
ASKER
hi,
I am not sure if you still remember how to install InnodB cluster any more and I am installing it, the output and the behavior is not what I can understand.
Now 3 x MySQL Enterprise trial edition has been setup and they are running good, so now need to configure the cluster.
I am reading this :
https://mysqlserverteam.com/mysql-innodb-cluster-real-world-cluster-tutorial-for-oel-fedora-rhel-and-centos/
and
https://dev.mysql.com/doc/refman/8.0/en/mysql-innodb-cluster-production-deployment.html
They don't say where I should install the MySQL router ? in a node other than 3 x MySQL server nodes?
MUST I install the MySQL router BEFORE creating the cluster?
I am not sure if you still remember how to install InnodB cluster any more and I am installing it, the output and the behavior is not what I can understand.
Now 3 x MySQL Enterprise trial edition has been setup and they are running good, so now need to configure the cluster.
I am reading this :
https://mysqlserverteam.com/mysql-innodb-cluster-real-world-cluster-tutorial-for-oel-fedora-rhel-and-centos/
and
https://dev.mysql.com/doc/refman/8.0/en/mysql-innodb-cluster-production-deployment.html
They don't say where I should install the MySQL router ? in a node other than 3 x MySQL server nodes?
MUST I install the MySQL router BEFORE creating the cluster?
simple answer is for once i'd concur with oracle and suggest you install it on the same machine that runs the app aka the mysql CLIENT.
--
longer answer is you need to understand that the so-called innodb cluster is merely a replication setup. this means that if you dispatch queries on all members, you end up with unpredicable results : statement-based replication will ensure counters will converge at some point. row-based will ensure pretty much nothing ( since innodb does not feature row versionning ). at best you end up with a transaction isolation level worse that read-uncommitted. in real life, there is no control over replication latencies so you end up with something much more error prone.
the router basically selects one member for writing and dispatches reads on other members. this ensures convergence will occur at some point when there is no node failure. this setup is very similar to what we used in good ol' mysql 4 like 15 years ago. i'd assume they at least tackled the autoincrement column issue. other than that, it's simply not feasible. but note that some apps can actually work with such a setup.
so 3 choices :
1/ run the router on the same node as the app
this will provide desired results if and only if your app runs on a single node at a time. multiple instances of the app will write to different members (unless you get lucky) so you have no isolation of any kind and it is actually likely the app will break pretty soon if you do.
2/ run separate middleware hosts : this works if you have multiple application nodes and a single router. if you have multiple routers and load balance between them, it will not : each router might select a different master with foreseeable bad consequences.
3/ run the routers on the mysql nodes : this produces the same results and problems as the above setup, and is less efficient that 1/ in terms of network flows.
bottom line is oracle is simply pushing the spof ( single point of failure ) to a separate layer rather than actually handling it. which is the exact same problem as the so-called oracle-HA that pushes the spof/sharing issues to the storage layer. actually i've never seen oracle getting even close to any kind of real clusterization technique
so if your app runs from a single node, stick the router on that same node and you're good to go. if your app is expected to run from multiple nodes in parallel, you need to handle failover yourself in your own app rather than expect that "cluster" setup to work properly. but you'll be able to run a demonstration easily since things will only break when the app gets busy.
regards
--
longer answer is you need to understand that the so-called innodb cluster is merely a replication setup. this means that if you dispatch queries on all members, you end up with unpredicable results : statement-based replication will ensure counters will converge at some point. row-based will ensure pretty much nothing ( since innodb does not feature row versionning ). at best you end up with a transaction isolation level worse that read-uncommitted. in real life, there is no control over replication latencies so you end up with something much more error prone.
the router basically selects one member for writing and dispatches reads on other members. this ensures convergence will occur at some point when there is no node failure. this setup is very similar to what we used in good ol' mysql 4 like 15 years ago. i'd assume they at least tackled the autoincrement column issue. other than that, it's simply not feasible. but note that some apps can actually work with such a setup.
so 3 choices :
1/ run the router on the same node as the app
this will provide desired results if and only if your app runs on a single node at a time. multiple instances of the app will write to different members (unless you get lucky) so you have no isolation of any kind and it is actually likely the app will break pretty soon if you do.
2/ run separate middleware hosts : this works if you have multiple application nodes and a single router. if you have multiple routers and load balance between them, it will not : each router might select a different master with foreseeable bad consequences.
3/ run the routers on the mysql nodes : this produces the same results and problems as the above setup, and is less efficient that 1/ in terms of network flows.
bottom line is oracle is simply pushing the spof ( single point of failure ) to a separate layer rather than actually handling it. which is the exact same problem as the so-called oracle-HA that pushes the spof/sharing issues to the storage layer. actually i've never seen oracle getting even close to any kind of real clusterization technique
so if your app runs from a single node, stick the router on that same node and you're good to go. if your app is expected to run from multiple nodes in parallel, you need to handle failover yourself in your own app rather than expect that "cluster" setup to work properly. but you'll be able to run a demonstration easily since things will only break when the app gets busy.
regards
ASKER
"simple answer is for once i'd concur with oracle and suggest you install it on the same machine that runs the app aka the mysql CLIENT."
sorry can't understand what it means.
" in real life, there is no control over replication latencies so you end up with something much more error prone."
log lagging you mean ?
" this means that if you dispatch queries on all members, you end up with unpredicable results "
Write on diff node nearly at the same time you mean ? data conflict then ...
"i'd assume they at least tackled the autoincrement column issue"
I think they don't or the my.cnf will show this out! MySQL replication will use that option in my.cnf but no need for InnodB cluster!
It seems that parameter in my.cnf on diff MySQL version can have quite diff parameter, some parameter for MySQL 5.7.19 community and MySQL enterprise 8.0 already quite diff. e.g. server-id= n is working on 5.7.19 but not MysQL 8.0 enterprise, that one is server_id=n !
when you are setting up InnoDB cluster the error message will show you, but we have to find it out carefully by reading the message.
"other than that, it's simply not feasible. but note that some apps can actually work with such a setup."
the connect string will make this happen, MS SQL 2016 Always on also like that.
"so 3 choices :"
MySQL replies that should be on separate node than MySQL node, I agree on that but I also agree that install on MysQL node do not have any problem, MS SQL AOG listener also installed on top of SQL node.
"which is the exact same problem as the so-called oracle-HA that pushes the spof/sharing issues to the storage layer.
the RAC is , but if it is not single share storage, RAC doesn't works, agree? everyone talking about horizontal scale out they still on RAC.
share storage, usually SAN, expensive!
" multiple instances of the app will write to different members (unless you get lucky) so you have no isolation of any kind and it is actually likely the app will break pretty soon if you do."
multi write you mean ?
it seems mulit app and a single router is good to go!
sorry can't understand what it means.
" in real life, there is no control over replication latencies so you end up with something much more error prone."
log lagging you mean ?
" this means that if you dispatch queries on all members, you end up with unpredicable results "
Write on diff node nearly at the same time you mean ? data conflict then ...
"i'd assume they at least tackled the autoincrement column issue"
I think they don't or the my.cnf will show this out! MySQL replication will use that option in my.cnf but no need for InnodB cluster!
It seems that parameter in my.cnf on diff MySQL version can have quite diff parameter, some parameter for MySQL 5.7.19 community and MySQL enterprise 8.0 already quite diff. e.g. server-id= n is working on 5.7.19 but not MysQL 8.0 enterprise, that one is server_id=n !
when you are setting up InnoDB cluster the error message will show you, but we have to find it out carefully by reading the message.
"other than that, it's simply not feasible. but note that some apps can actually work with such a setup."
the connect string will make this happen, MS SQL 2016 Always on also like that.
"so 3 choices :"
MySQL replies that should be on separate node than MySQL node, I agree on that but I also agree that install on MysQL node do not have any problem, MS SQL AOG listener also installed on top of SQL node.
"which is the exact same problem as the so-called oracle-HA that pushes the spof/sharing issues to the storage layer.
the RAC is , but if it is not single share storage, RAC doesn't works, agree? everyone talking about horizontal scale out they still on RAC.
share storage, usually SAN, expensive!
" multiple instances of the app will write to different members (unless you get lucky) so you have no isolation of any kind and it is actually likely the app will break pretty soon if you do."
multi write you mean ?
it seems mulit app and a single router is good to go!
ASKER
for the installation now we have a problem , dba.createcluster is working good but when adding instance it say can't find cluster. any problem you can see ?
you can see that dba.getCluster() return the cluster name
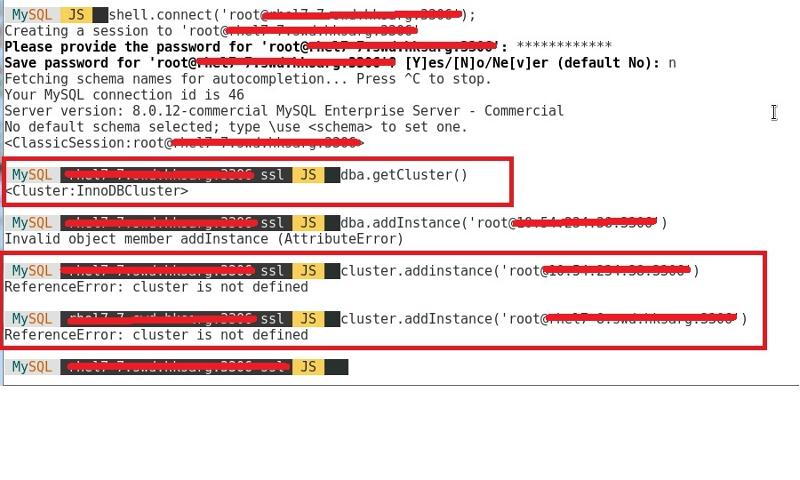
you can see that dba.getCluster() return the cluster name

sorry can't understand what it means.
the client is the side of the connection that issues the queries : in this case the application that will run sql queries against your cluster
log lagging you mean ?
no : unpredictable data conflict as you seem to have guessed later on.
MySQL replication will use that option in my.cnf
not sure we're talking about the same thing. i meant using different conflictless autoincrement values on each host to minimise the consequences of inserting on multiple hosts at the same time. trade off is you'll end up with gaps and no guarantee that each id is bigger than all of the previous ones.
I also agree that install on MysQL node do not have any problem
if you load balance queries on all nodes, you do have a problem. if you do not, you don't have a cluster. the former results in a broken setup ( data conflicts ) and the latter requires manual intervention for failover and does not balance the load.
but if it is not single share storage, RAC doesn't works, agree
yes. which is why it does not scale and additionally does not solve the SPOF issue : the sql server is not the spof any more but the shared storage becomes a new one. so the whole thing is basically a useless scam.
it seems mulit app and a single router is good to go!
yes. but then your router becomes the spof.
and you can end up with data conflicts each time the write server is changed.
--
again, oracle is merely selling as a cluster what we used to setup as a poor man's alternative many years ago. it can work reasonably well with some apps but comes with many limitations. ( and additionally can be setup manually much more easily than by going through messy automated configuration managers and proxies : all you need is bidirectionnal replication and set failover in your app or load balancer. )
on the other hand, you can load balance both reads and writes on all members of a mariadb cluster and it will basically work. there is no comparison between the 2 in terms of feature.
ASKER
Yesterday I figure out why that error message shows my cluster is not defined, we have to assign the the cluster var a value using sth like getcluster() as a object to return to the variable before we can do the addInstance.
Can't see why a DB installation need sth like this, it just like programming ! I really like MariaDB, installation is easy and only 2 x file to work with, maxscale.cnf for maxscale and server.cnf for each mariaDB, that's it.
"different conflictless autoincrement values on each host to minimise the consequences of inserting on multiple hosts at the same time. trade off is you'll end up with gaps and no guarantee that each id is bigger than all of the previous ones."
what I got before is there are 2 x parameter:
auto-increment-offset
auto-increment-increment
so this 2 x value + server-id govern the whole operation of multi-master, safe enough?
"yes. but then your router becomes the spof.
and you can end up with data conflicts each time the write server is changed."
agree! usually a DB should have more than one listener/router! their best practice usually say it.
"and you can end up with data conflicts each time the write server is changed."
can't understand this! you mean write server changing too fast and which make it looks like multi master?
"all you need is bidirectionnal replication and set failover in your app or load balancer"
agree! no need RAC at all, MS SQL long time again user merge replication as multi master but no one know it is already multi master mode, but data conflict also happen, but of course !
AND this solution is very cheap ! however log lagging if system is busy ! all product has this kind of problem if they relies on the log to replication transaction to the other side.
Can't see why a DB installation need sth like this, it just like programming ! I really like MariaDB, installation is easy and only 2 x file to work with, maxscale.cnf for maxscale and server.cnf for each mariaDB, that's it.
"different conflictless autoincrement values on each host to minimise the consequences of inserting on multiple hosts at the same time. trade off is you'll end up with gaps and no guarantee that each id is bigger than all of the previous ones."
what I got before is there are 2 x parameter:
auto-increment-offset
auto-increment-increment
so this 2 x value + server-id govern the whole operation of multi-master, safe enough?
"yes. but then your router becomes the spof.
and you can end up with data conflicts each time the write server is changed."
agree! usually a DB should have more than one listener/router! their best practice usually say it.
"and you can end up with data conflicts each time the write server is changed."
can't understand this! you mean write server changing too fast and which make it looks like multi master?
"all you need is bidirectionnal replication and set failover in your app or load balancer"
agree! no need RAC at all, MS SQL long time again user merge replication as multi master but no one know it is already multi master mode, but data conflict also happen, but of course !
AND this solution is very cheap ! however log lagging if system is busy ! all product has this kind of problem if they relies on the log to replication transaction to the other side.
ASKER
please also help on this question if you have time:
https://www.experts-exchange.com/questions/29104704/OLAP-solution-for-MySQL.html
https://www.experts-exchange.com/questions/29104704/OLAP-solution-for-MySQL.html
Can't see why a DB installation need sth like this
it does not. you can do the same setup manually without relying on the oracle tools. but then you'd be much more likely to realize how poor the design is.
so this 2 x value + server-id govern the whole operation of multi-master, safe enough?
most definitely not. it merely prevents the replications from breaking on the first try because of an id conflict. more complex operations than inserting new values into a single indexed table will still break as expected if you run queries against all members.
can't understand this! you mean write server changing too fast and which make it looks like multi master?
more or less : it is broken by design : when the write server changes, or worse dies a few queries might be temporarily postponed and played at random times when it goes up again. but it actually is usable in many realworld scenaris as long as the proxy does not switch unless it really has to : flapping will actually break something, just switching will usually produce minimal impact. i would not use this for banking, though.
agree! no need RAC at all, MS SQL long time again user merge replication as multi master but no one know it is already multi master mode, but data conflict also happen, but of course !
i cannot answer to that. write actual sentences, PLEASE.
i cannot answer your other question : much too vague and there is no actual problem to solve. google it for much better results.
you also need to realize that half of your posts are almost impossible to read. spend a little time on formatting ; read the whole post you're answering to before you start writing ; read your own post again before submitting ; don't waste time stating you agree on a buch of little things unless you actually have a followup question
you also need to realize that half of your posts are almost impossible to read. spend a little time on formatting ; read the whole post you're answering to before you start writing ; read your own post again before submitting ; don't waste time stating you agree on a buch of little things unless you actually have a followup question
ASKER
I want to go back to my initial question but asking what 's wrong with my installation, right now I am going to install the router but it doesn't works.
I read this :
https://mysqlserverteam.com/mysql-innodb-cluster-real-world-cluster-tutorial-for-oel-fedora-rhel-and-centos/
https://dev.mysql.com/doc/refman/8.0/en/mysql-innodb-cluster-using-router.html
bootstrap the router:
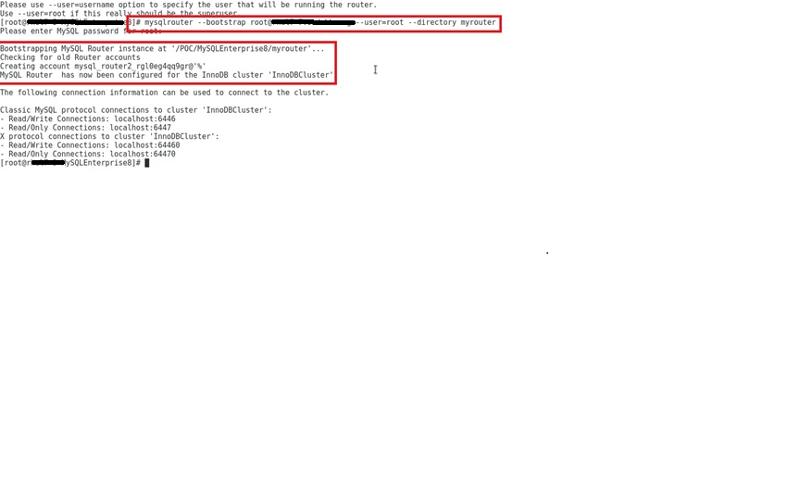
and I do myrouter/start.sh and it create a pid files under the myrouter folder:
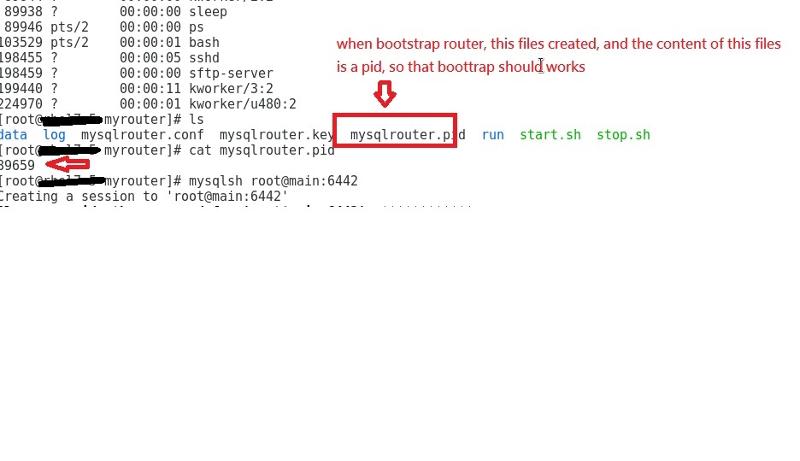
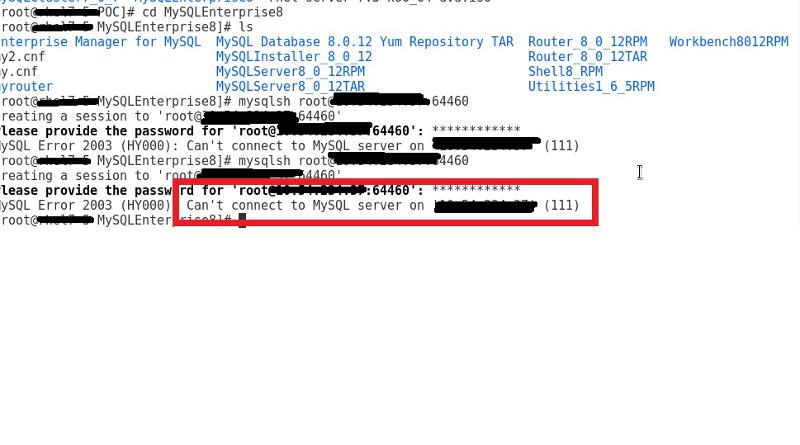
however it still doesn't work.
I read this :
https://mysqlserverteam.com/mysql-innodb-cluster-real-world-cluster-tutorial-for-oel-fedora-rhel-and-centos/
https://dev.mysql.com/doc/refman/8.0/en/mysql-innodb-cluster-using-router.html
bootstrap the router:
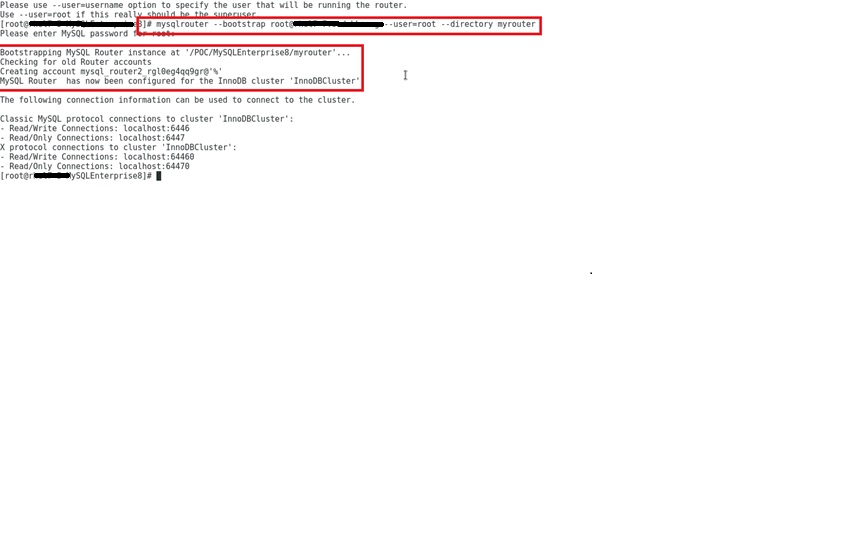
and I do myrouter/start.sh and it create a pid files under the myrouter folder:
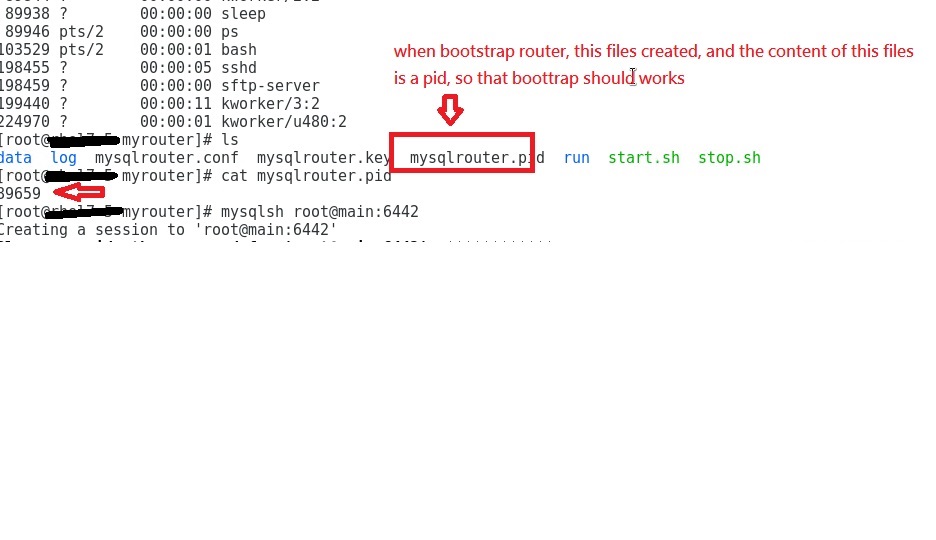
however it still doesn't work.
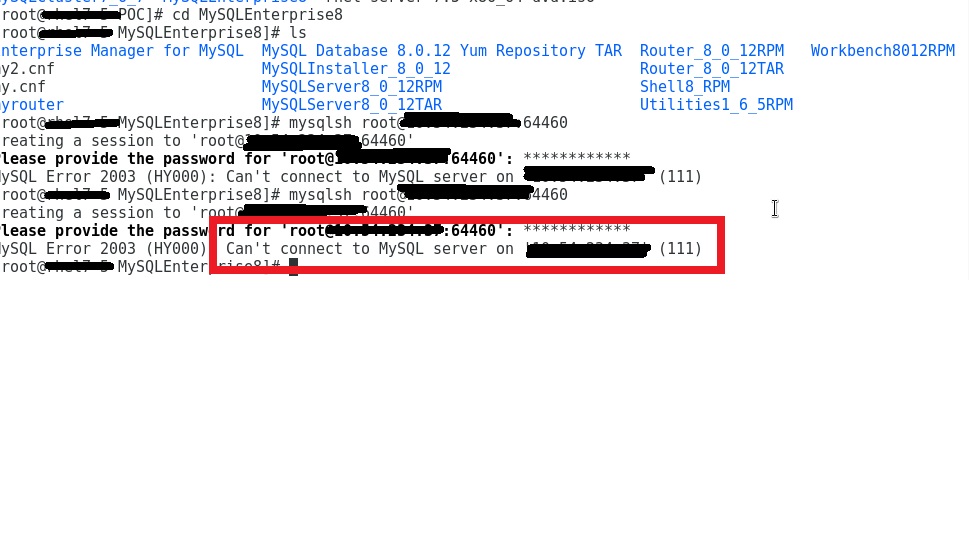
ASKER
hi man,
today I am happy again, open source always like this ! you have to read a lot of information but finally you will found out that a lot of thing is wrong!
I read this:
https://mysqlserverteam.com/mysql-innodb-cluster-real-world-cluster-tutorial-for-oel-fedora-rhel-and-centos/
this link is good except the MySQL router section! it waste me some times.
and I read this :
https://dev.mysql.com/doc/refman/8.0/en/mysql-innodb-cluster-using-router.html
and this one:
and this one:
works!
This one :
even it create mysqlrouter.conf and everything looks good, it is not working well!!
very dangerous thing! in MS SQL world, 99.999% of doc from web works fine !
today I am happy again, open source always like this ! you have to read a lot of information but finally you will found out that a lot of thing is wrong!
I read this:
https://mysqlserverteam.com/mysql-innodb-cluster-real-world-cluster-tutorial-for-oel-fedora-rhel-and-centos/
this link is good except the MySQL router section! it waste me some times.
and I read this :
https://dev.mysql.com/doc/refman/8.0/en/mysql-innodb-cluster-using-router.html
and this one:
shell> mysqlrouter --bootstrap ic@ic-1:3306 --user=mysqlrouterand this one:
shell> mysqlrouter &works!
This one :
$ mysqlrouter --bootstrap ic@ic-1:3306 --directory myroutereven it create mysqlrouter.conf and everything looks good, it is not working well!!
very dangerous thing! in MS SQL world, 99.999% of doc from web works fine !
ASKER
tks all, it is finally running good !
Setup is simple.
Getting your setup to work initially + when ever one instance fails, will require a good bit of time.
And, when I run replicated servers I target doing a failover once ever month, just to make sure the entire system is working.
Rarely is replication actually required, for load balancing or for backup integrity.
If this is your first time working with replication, likely good to hire someone to assist you with setup + ongoing, daily tuning/maintenance.